python实现十大经典排序算法
- 2020 年 4 月 4 日
- 筆記
Python实现十大经典排序算法
代码最后面会给出完整版,或者可以从我的Githubfork,想看动图的同学可以去这里看看;
小结:
- 运行方式,将最后面的代码copy出去,直接python sort.py运行即可;
- 代码中的健壮性没有太多处理,直接使用的同学还要检查检查;
- 对于希尔排序,gap的选择至关重要,需要结合实际情况更改;
- 在我的测试中,由于待排序数组很小,长度仅为10,且最大值为10,因此计数排序是最快的,实际情况中往往不是这样;
- 堆排序没来得及实现,是的,就是懒了;
- 关键在于理解算法的思路,至于实现只是将思路以合理的方式落地而已;
- 推荐大家到上面那个链接去看动图,确实更好理解,不过读读代码也不错,是吧;
- 分治法被使用的很多,事实上我不太清楚它背后的数学原理是什么,以及为什么分治法可以降低时间复杂度,有同学直到麻烦评论区告诉我一下哈,多谢;
运行图
由于数组小,且范围在1到10之间,这其实对于计数排序这种非比较类算法是比较友好的,因为没有多大的空间压力,因此计数排序速度第一很容易理解,而之所以选择、插入比希尔归并要快,主要还是因为问题规模本身太小,而我的分治法的实现是基于递归,因此看不出分治法的优势,事实上如果对超大的数组进行排序的话,这个区别会体现出来;
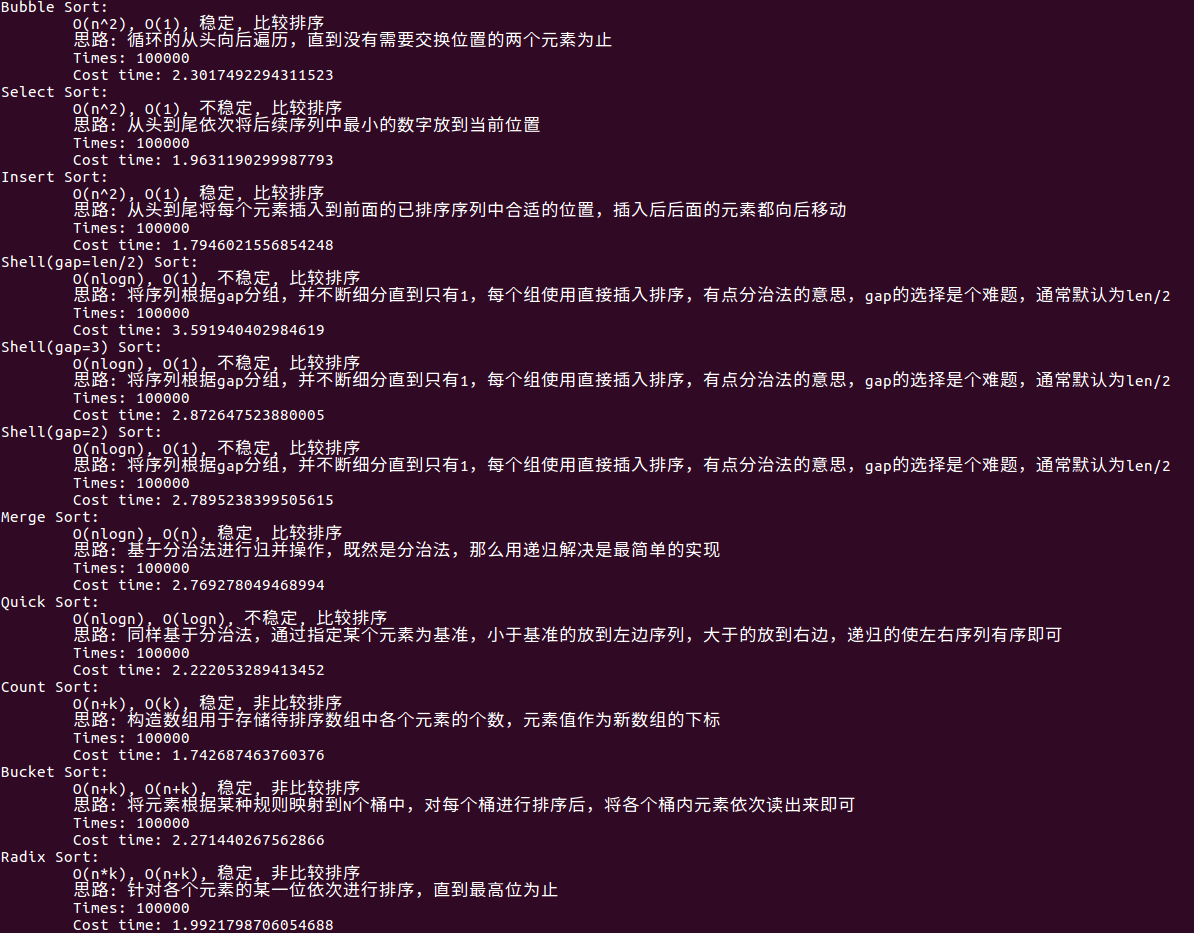
完整代码
可以看到,全部代码不包括测试代码总共才170行,这还包括了空行和函数名等等,所以本身算法实现是很简单的,大家还是要把注意力放在思路上;
import sys,random,time def bubble(list_): running = True while running: have_change = False for i in range(len(list_)-1): if list_[i]>list_[i+1]: list_[i],list_[i+1] = list_[i+1],list_[i] have_change = True if not have_change: break return list_ def select(list_): for i in range(len(list_)-1): min_idx = i for j in range(i,len(list_)): if list_[min_idx]>list_[j]: min_idx = j list_[i],list_[min_idx] = list_[min_idx],list_[i] return list_ def insert(list_): for i in range(1,len(list_)): idx = i for j in range(i): if list_[j]>list_[idx]: idx = j break if idx != i: tmp = list_[i] list_[idx+1:i+1] = list_[idx:i] list_[idx] = tmp return list_ def shell(list_,gap=None): ''' gap的选择对结果影响很大,是个难题,希尔本人推荐是len/2 这个gap其实是间隙,也就是间隔多少个元素取一组的元素 例如对于[1,2,3,4,5,6,7,8,9,10] 当gap为len/2也就是5时,每一组的元素都是间隔5个的元素组成,也就是1和6,2和7,3和8等等 ''' len_ = len(list_) gap = int(len_/2) if not gap else gap while gap >= 1: for i in range(gap): list_[i:len_:gap] = insert(list_[i:len_:gap]) gap = int(gap/2) return list_ def merge(list_): ''' 归并排序的递归实现 思路:将数据划分到每两个为一组为止,将这两个排序后范围,2个包含2个元素的组继续排序为1个4个元素的组, 直到回溯到整个序列,此时其实是由两个有序子序列组成的,典型的递归问题 ''' if len(list_)<=1: return list_ if len(list_)==2: return list_ if list_[0]<=list_[1] else list_[::-1] len_ = len(list_) left = merge(list_[:int(len_/2)]) right = merge(list_[int(len_/2):]) tmp = [] left_idx,right_idx = 0,0 while len(tmp)<len(list_): if left[left_idx]<=right[right_idx]: tmp.append(left[left_idx]) left_idx+=1 if left_idx==len(left): tmp += right[right_idx:] break else: tmp.append(right[right_idx]) right_idx+=1 if right_idx==len(right): tmp += left[left_idx:] break return tmp def quick(list_): ''' 快速排序:基于分治法,选定某个元素为基准,对剩余元素放置到基准的左侧和右侧,递归这个过程 ''' if len(list_)<=1: return list_ if len(list_)==2: return list_ if list_[0]<=list_[1] else list_[::-1] base_idx = int(len(list_)/2) base = list_[base_idx] left = [] right = [] for i in range(len(list_)): if i != base_idx: if list_[i] <= base: left.append(list_[i]) else: right.append(list_[i]) return quick(left)+[base]+quick(right) def count(list_): ''' 需要元素都是整型 ''' min_,max_ = list_[0],list_[0] for i in range(1,len(list_)): if list_[i]<min_: min_ = list_[i] if list_[i]>max_: max_ = list_[i] count_list = [0]*(max_-min_+1) for item in list_: count_list[item-min_] += 1 list_ = [] for i in range(len(count_list)): for j in range(count_list[i]): list_.append(i+min_) return list_ def heap(list_): ''' ''' pass def bucket(list_): ''' 每个桶使用选择排序,分桶方式为最大值除以5,也就是分为5个桶 桶排序的速度取决于分桶的方式 ''' bucket = [[],[],[],[],[]] # 注意长度为5 max_ = list_[0] for item in list_[1:]: if item > max_: max_ = item gap = max_/5 # 对应bucket的长度 for item in list_: bucket[int((item-1)/gap)].append(item) for i in range(len(bucket)): bucket[i] = select(bucket[i]) list_ = [] for item in bucket: list_ += item return list_ def radix(list_): ''' 基数排序:对数值的不同位数分别进行排序,比如先从个位开始,然后十位,百位,以此类推; 注意此处代码是假设待排序数值都是整型 ''' max_ = list_[0] for item in list_[1:]: if item > max_: max_ = item max_radix = len(str(max_)) radix_list = [[],[],[],[],[],[],[],[],[],[]] # 对应每个位上可能的9个数字 cur_radix = 0 while cur_radix<max_radix: base = 10**cur_radix for item in list_: radix_list[int(item/base)%10].append(item) list_ = [] for item in radix_list: list_ += item radix_list = [[],[],[],[],[],[],[],[],[]] # 对应每个位上可能的9个数字 cur_radix += 1 return list_ def test(name,sort_func,times,info,idea,*param): list_ = [1,2,3,4,5,6,7,8,9,10] print(name+' Sort:') print('t'+info) print('t'+idea) print('tTimes: '+str(times)) start_time = time.time() for i in range(times): random.shuffle(list_) #print('tInput: '+str(list_)) list_ = sort_func(list_) if len(param)<=0 else sort_func(list_,param[0]) #print('tOutput: '+str(list_)) #print('t'+str(list_)) print('tCost time: '+str(time.time()-start_time)) if __name__ == "__main__": test('Bubble',bubble,100000,'O(n^2), O(1), 稳定, 比较排序','思路: 循环的从头向后遍历,直到没有需要交换位置的两个元素为止') test('Select',select,100000,'O(n^2), O(1), 不稳定, 比较排序','思路: 从头到尾依次将后续序列中最小的数字放到当前位置') test('Insert',insert,100000,'O(n^2), O(1), 稳定, 比较排序','思路: 从头到尾将每个元素插入到前面的已排序序列中合适的位置,插入后后面的元素都向后移动') test('Shell(gap=len/2)',shell,100000,'O(nlogn), O(1), 不稳定, 比较排序','思路: 将序列根据gap分组,并不断细分直到只有1,每个组使用直接插入排序,有点分治法的意思,gap的选择是个难题,通常默认为len/2') test('Shell(gap=3)',shell,100000,'O(nlogn), O(1), 不稳定, 比较排序','思路: 将序列根据gap分组,并不断细分直到只有1,每个组使用直接插入排序,有点分治法的意思,gap的选择是个难题,通常默认为len/2',3) test('Shell(gap=2)',shell,100000,'O(nlogn), O(1), 不稳定, 比较排序','思路: 将序列根据gap分组,并不断细分直到只有1,每个组使用直接插入排序,有点分治法的意思,gap的选择是个难题,通常默认为len/2',2) test('Merge',merge,100000,'O(nlogn), O(n), 稳定, 比较排序','思路: 基于分治法进行归并操作,既然是分治法,那么用递归解决是最简单的实现') test('Quick',quick,100000,'O(nlogn), O(logn), 不稳定, 比较排序','思路: 同样基于分治法,通过指定某个元素为基准,小于基准的放到左边序列,大于的放到右边,递归的使左右序列有序即可') # test('Heap',heap,100000,'O(nlogn), O(1), 不稳定, 比较排序','思路: 利用堆的性质构建完全二叉树') test('Count',count,100000,'O(n+k), O(k), 稳定, 非比较排序','思路: 构造数组用于存储待排序数组中各个元素的个数,元素值作为新数组的下标') test('Bucket',bucket,100000,'O(n+k), O(n+k), 稳定, 非比较排序','思路: 将元素根据某种规则映射到N个桶中,对每个桶进行排序后,将各个桶内元素依次读出来即可') test('Radix',radix,100000,'O(n*k), O(n+k), 稳定, 非比较排序','思路: 针对各个元素的某一位依次进行排序,直到最高位为止') # print(heap([4,6,8,3,5,10,9,2,1,7])) 最后
大家可以到我的Github上看看有没有其他需要的东西,目前主要是自己做的机器学习项目、Python各种脚本工具、有意思的小项目以及Follow的大佬、Fork的项目等:
https://github.com/NemoHoHaloAi
