CMDB_Agent版本
- 2020 年 3 月 26 日
- 筆記
目录
CMDB_Agent版本
CMDB概念
CMDB: Configure Manage DataBase 中文:配置管理数据库。 主要的作用是:收集服务器的基础信息(包括:服务器的主机名,ip,操作系统版本,磁盘,CPU等信息),将来提供给子系统(代码发布,工单系统等)数据 CMDB_Agent介绍

其本质上就是在各个服务器上执行subprocess.getoutput()命令,然后将每台机器上执行的结果,返回给主机API,然后主机API收到这些数据之后,放入到数据库中,最终通过web界面展现给用户 优点:速度快 缺点:需要为每台服务器步数一个Agent的程序 agent方案
将待采集的服务器看成一个agent,然后再服务器上使用python的subprocess模块执行linux相关的命令,然后分析得到的结果,将分析得到的结果通过requests模块发送给API,API获取到数据之后,进行二次比对数据,最后将比对的结果存入到数据库中,最后django起一个webserver从数据库中将数据获取出来,供用户查看 ssh类方案
在中控机服务器上安装一个模块叫paramiko模块,通过这个模块登录到带采集的服务器上,然后执行相关的linux命令,最后返回执行的结果,将分析得到的结果通过requests模块发送给API,API获取到数据之后,进行二次比对数据,最后将比对的结果存入到数据库中,最后django起一个webserver从数据库中将数据获取出来,供用户查看 相比较
agent方案 优点:不需要额外的增加中控机。 缺点:每新增一台服务器,就需要额外部署agent脚本。使用场景是:服务器多的情况 (1000台以上) ssh方案 优点:不需要额外的部署脚本。 缺点:速度比较慢。使用场景是:服务器少 (1000台往下) 架构目录
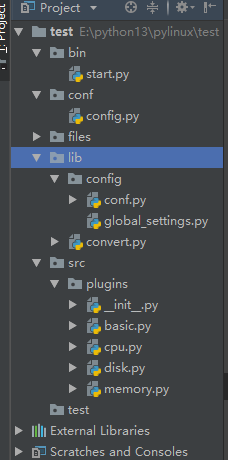
bin-start.py 启动文件
from src.plugins import PluginsManager if __name__ == '__main__': res = PluginsManager().execute() for k, v in res.items(): print(k, v) conf-config.py 自定义配置文件
模仿Django的setting,常用的配置写在这里面。不常用的写在global_settings.py中。
加载顺寻:先加载全局的。再加载局部的
USER = 'root' MODE = 'agent' DEBUG = True # True:代表是开发测试阶段 False:代表是上现阶段 import os BASEDIR = os.path.dirname(os.path.dirname(os.path.abspath(__file__))) # 模仿Django中间件,插拔式 PLUGINS_DICT = { 'basic': 'src.plugins.basic.Basic', 'cpu': 'src.plugins.cpu.Cpu', #'disk': 'src.plugins.disk.Disk', 'memory': 'src.plugins.memory.Memory', } files 开发测试的文件
DEBUT=True时为测试阶段,用files的测试数据
lib-config-global_settings.py 全局配置的文件
pass lib-config-conf.py 读取配置的文件
全局配置放在前面先加载,自定义配置的放在后面后加载。自定义配置了就用自定义的(覆盖),没有配置久用全局的
from conf import config from . import global_settings class mySettings(): def __init__(self): # print('aa:', dir(global_settings)) # print('bb:', dir(config)) # 全局配置 for k in dir(global_settings): if k.isupper(): v = getattr(global_settings, k) setattr(self, k, v) # 自定义配置 for k in dir(config): if k.isupper(): v = getattr(config, k) setattr(self, k, v) settings = mySettings() src-plugins-init.py 核心文件
from lib.config.conf import settings import importlib class PluginsManager(): def __init__(self): self.plugins_dict = settings.PLUGINS_DICT self.debug = settings.DEBUG # 1.采集数据 def execute(self): response = {} for k, v in self.plugins_dict.items(): ''' k: basic v: src.plugins.basic.Basic ''' # 2.循环导入(字符串路径) moudle_path, class_name = v.rsplit('.', 1) # ['src.plugins.basic','Basic'] # 用importlib.import_module()导入字符串路径 m = importlib.import_module(moudle_path) # 3.导入类 cls = getattr(m, class_name) # 循环执行鸭子类型的process方法,command_func函数的内存地址传过去,把debug传过去 ret = cls().process(self.command_func, self.debug) response[k] = ret return response # 真正的连接,执行命令,返回结果的函数。命令变成参数 def command_func(self, cmd): if settings.MODE == 'agent': import subprocess res = subprocess.getoutput(cmd) return res else: import paramiko # 创建SSH对象 ssh = paramiko.SSHClient() # 允许连接不再know_hosts文件中的主机 ssh.set_missing_host_key_policy(paramiko.AutoAddPolicy()) # 连接服务器 ssh.connect(hostname='10.0.0.200', port=22, username='root', password='123456') # 执行命令 stdin, stdout, stderr = ssh.exec_command(cmd) # 获取命令结果 result = stdout.read() # 关闭连接 ssh.close() return result src-plugins-basic.py 查看硬件信息
from conf import config class Basic(object): def process(self, command_func, debug): if debug: output = { 'os_platform': "linux", 'os_version': "CentOS release 6.6 (Final)nKernel r on an m", 'hostname': 'c1.com' } else: output = { 'os_platform': command_func("uname").strip(), 'os_version': command_func("cat /etc/issue").strip().split('n')[0], 'hostname': command_func("hostname").strip(), } return output src-plugins-cpu.py 查看cpu属性
import os from lib.config.conf import settings class Cpu(): def __init__(self): pass def process(self, command_func, debug): if debug: output = open(os.path.join(settings.BASEDIR, 'files/cpuinfo.out'), 'r', encoding='utf-8').read() else: output = command_func("cat /proc/cpuinfo") return self.parse(output) def parse(self, content): """ 解析shell命令返回结果 :param content: shell 命令结果 :return:解析后的结果 """ response = {'cpu_count': 0, 'cpu_physical_count': 0, 'cpu_model': ''} cpu_physical_set = set() content = content.strip() for item in content.split('nn'): for row_line in item.split('n'): key, value = row_line.split(':') key = key.strip() if key == 'processor': response['cpu_count'] += 1 elif key == 'physical id': cpu_physical_set.add(value) elif key == 'model name': if not response['cpu_model']: response['cpu_model'] = value response['cpu_physical_count'] = len(cpu_physical_set) return response src-plugins-disk.py 查看磁盘信息
# 采集磁盘信息 from lib.config.conf import settings import os import re class Disk(object): def __init__(self): pass def process(self, command_func, debug): if debug: output = open(os.path.join(settings.BASEDIR, 'files/disk.out'), 'r', encoding='utf-8').read() else: output = command_func('MegaCli -PDList -aALL') # radi 卡 磁盘阵列 return self.parse(output) # 调用过滤的函数 # 过滤函数,对字符串的处理过滤 def parse(self, content): """ 解析shell命令返回结果 :param content: shell 命令结果 :return:解析后的结果 """ response = {} result = [] for row_line in content.split("nnnn"): result.append(row_line) for item in result: temp_dict = {} for row in item.split('n'): if not row.strip(): continue if len(row.split(':')) != 2: continue key, value = row.split(':') name = self.mega_patter_match(key) if name: if key == 'Raw Size': raw_size = re.search('(d+.d+)', value.strip()) if raw_size: temp_dict[name] = raw_size.group() else: raw_size = '0' else: temp_dict[name] = value.strip() if temp_dict: response[temp_dict['slot']] = temp_dict return response @staticmethod def mega_patter_match(needle): grep_pattern = {'Slot': 'slot', 'Raw Size': 'capacity', 'Inquiry': 'model', 'PD Type': 'pd_type'} for key, value in grep_pattern.items(): if needle.startswith(key): return value return False 

