长短时记忆神经网络(LSTM)介绍以及简单应用分析
- 2019 年 10 月 5 日
- 筆記
本文分为四个部分,第一部分简要介绍LSTM的应用现状;第二部分介绍LSTM的发展历史,并引出了受众多学者关注的LSTM变体——门控递归单元(GRU);第三部分介绍LSTM的基本结构,由基本循环神经网络结构引出LSTM的具体结构。第四部分,应用Keras框架提供的API,比较和分析简单循环神经网络(SRN)、LSTM和GRU在手写数字minist数据集上的表现。
应用现状
长短期记忆神经网络(LSTM)是一种特殊的循环神经网络(RNN)。原始的RNN在训练中,随着训练时间的加长以及网络层数的增多,很容易出现梯度爆炸或者梯度消失的问题,导致无法处理较长序列数据,从而无法获取长距离数据的信息。
LSTM应用的领域包括:文本生成、机器翻译、语音识别、生成图像描述和视频标记等。
2009年, 应用LSTM搭建的神经网络模型赢得了ICDAR手写识别比赛冠军。
2015年以来,在机械故障诊断和预测领域,相关学者应用LSTM来处理机械设备的振动信号。
2016年, 谷歌公司应用LSTM来做语音识别和文字翻译,其中Google翻译用的就是一个7-8层的LSTM模型。
2016年, 苹果公司使用LSTM来优化Siri应用。
发展历史
1997年,Sepp Hochreiter 和 Jürgen Schmidhuber[1]提出了长短期记忆神经网络(LSTM),有效解决了RNN难以解决的人为延长时间任务的问题,并解决了RNN容易出现梯度消失的问题。
1999年,Felix A. Gers等人[2]发现[1]中提出的LSTM在处理连续输入数据时,如果没有重置网络内部的状态,最终会导致网络崩溃。因此,他们在文献[1]基础上引入了遗忘门机制,使得LSTM能够重置自己的状态。
2000年,Felix A. Gers和Jiirgen Schmidhuber[3]发现,通过在LSTM内部状态单元内添加窥视孔(Peephole)连接,可以增强网络对输入序列之间细微特征的区分能力。
2005年,Alex Graves和Jürgen Schmidhuber[4]在文献[1] [2] [3]的基础上提出了一种双向长短期记忆神经网络(BLSTM),也称为vanilla LSTM,是当前应用最广泛的一种LSTM模型。
2005年-2015年期间,相关学者提出了多种LSTM变体模型,此处不多做描述。
2016年,Klaus Greff 等人[5]回顾了LSTM的发展历程,并比较分析了八种LSTM变体在语音识别、手写识别和弦音乐建模方面的能力,实验结果表明这些变体不能显著改进标准LSTM体系结构,并证明了遗忘门和输出激活功能是LSTM的关键组成部分。在这八种变体中,vanilla LSTM的综合表现能力最佳。另外,还探索了LSTM相关超参数的设定影响,实验结果表明学习率是最关键的超参数,其次是网络规模(网络层数和隐藏层单元数),而动量梯度等设置对最终结果影响不大。
下图展示了Simple RNN(图左)和vanilla LSTM(图右,图中蓝色线条表示窥视孔连接)的基本单元结构图[5]:
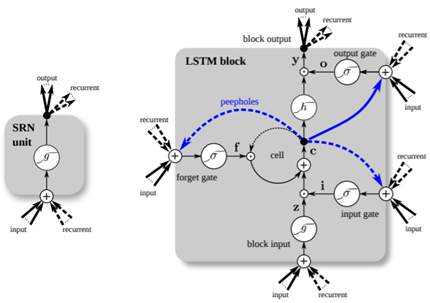
在众多LSTM变体中,2014年Kyunghyun Cho等人[6]提出的变体引起了众多学者的关注。Kyunghyun Cho等人简化了LSTM架构,称为门控递归单元(GRU)。GRU摆脱了单元状态,基本结构由重置门和更新门组成。LSTM和GRU的基本结构单元如下图(具体可参考:Illustrated Guide to LSTM’s and GRU’s: A step by step explanation)。
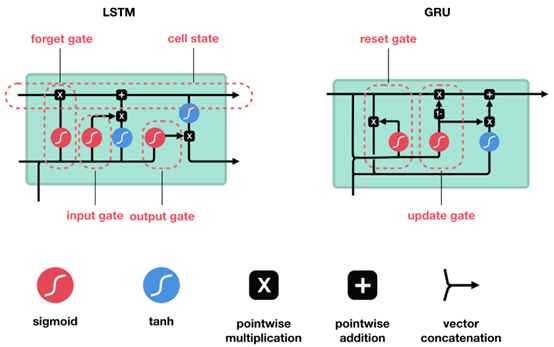
在GRU被提出后,Junyoung Chung等人[7]比较了LSTM和GRU在复音音乐和语音信号建模方面的能力,实验结果表明GRU和LSTM表现相当。
GRU被提出至今(2019年),也只有几年时间,关于它的一些应用利弊到目前还未探索清楚。不过,相对于LSTM架构,GRU的的参数较少,在数据量较大的情况下,其训练速度更快。
LSTM是深度学习技术中的一员,其基本结构比较复杂,计算复杂度较高,导致较难进行较深层次的学习,例如谷歌翻译也只是应用7-8层的LSTM网络结构。另外,在训练学习过程中有可能会出现过拟合,可以通过应用dropout来解决过拟合问题(这在Keras等框架中均有实现,具体可参考:LSTM原理与实践,原来如此简单)。
LSTM在当前应用比较的结构是双向LSTM或者多层堆叠LSTM,这两种结构的实现在Keras等框架中均有对应的API可以调用。
下图展示一个堆叠两层的LSTM结构图(来源:运用TensorFlow处理简单的NLP问题):

下图展示了一个双向LSTM的结构图(来源:双向LSTM)

基本原理
本节首先讲解一下RNN的基本结构,然后说明LSTM的具体原理(下面要介绍的LSTM即为vanilla LSTM)。
原始的RNN基本结构图如下图所示(原图来源:Understanding LSTM Networks)。
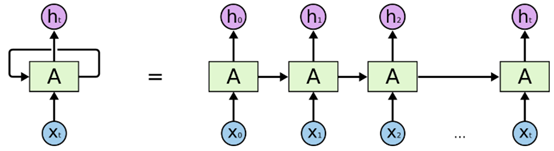
由上图可知,RNN展开后由多个相同的单元连续连接。但是,RNN的实际结构确和上图左边的结构所示,是一个自我不断循环的结构。即随着输入数据的不断增加,上述自我循环的结构把上一次的状态传递给当前输入,一起作为新的输入数据进行当前轮次的训练和学习,一直到输入或者训练结束,最终得到的输出即为最终的预测结果。
LSTM是一种特殊的RNN,两者的区别在于普通的RNN单个循环结构内部只有一个状态。而LSTM的单个循环结构(又称为细胞)内部有四个状态。相比于RNN,LSTM循环结构之间保持一个持久的单元状态不断传递下去,用于决定哪些信息要遗忘或者继续传递下去。
包含三个连续循环结构的RNN如下图,每个循环结构只有一个输出:
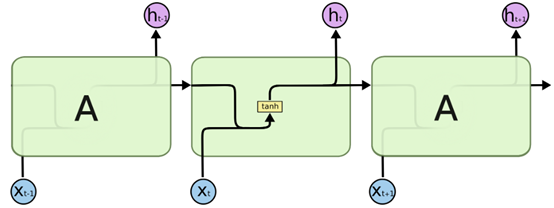
包含三个连续循环结构的LSTM如下图,每个循环结构有两个输出,其中一个即为单元状态:
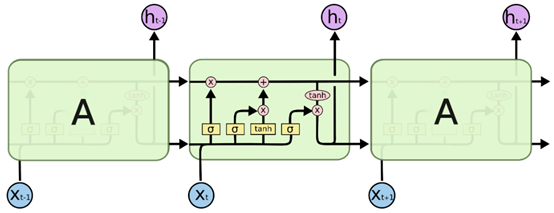
一层LSTM是由单个循环结构结构组成,既由输入数据的维度和循环次数决定单个循环结构需要自我更新几次,而不是多个单个循环结构连接组成(此处关于这段描述,在实际操作的理解详述请参考:Keras关于LSTM的units参数,还是不理解? ),即当前层LSTM的参数总个数只需计算一个循环单元就行,而不是计算多个连续单元的总个数。
下面将由一组图来详细结构LSTM细胞的基本组成和实现原理。LSTM细胞由输入门、遗忘门、输出门和单元状态组成。
- 输入门:决定当前时刻网络的输入数据有多少需要保存到单元状态。
- 遗忘门:决定上一时刻的单元状态有多少需要保留到当前时刻。
- 输出门:控制当前单元状态有多少需要输出到当前的输出值。
下图展示了应用上一个时刻的输出h_t-1和当前的数据输入x_t,通过遗忘门得到f_t的过程。(下面的一组原图来源:Understanding LSTM Networks)
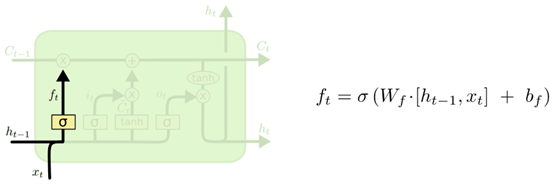
下图展示了应用上一个时刻的输出h_t-1和当前的数据输入x_t,通过输入门得到i_t,以及通过单元状态得到当前时刻暂时状态C~t的过程。
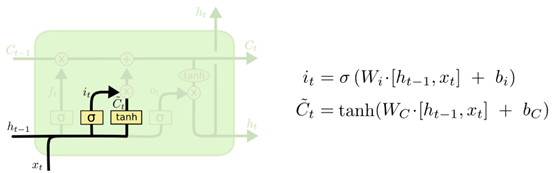
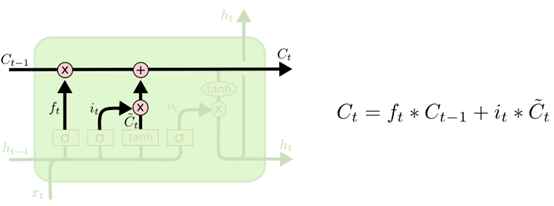
下图展示了应用上一个细胞结构的单元状态C_t-1、遗忘门输出f_t、输入门输出i_t以及单元状态的输出C~t,得到当前细胞的状态C_t的过程。
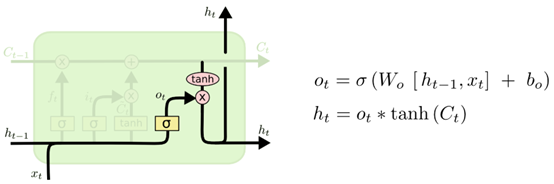
下图展示了应用上一个时刻的输出h_t-1和当前的数据输入x_t,通过输出门得到o_t的过程,以及结合当前细胞的单元状态C_t和o_t得到最终的输出h_t的过程。
基于Keras框架的手写数字识别实验
本节应用Keras提供的API,比较和分析Simple RNN、LSTM和GRU在手写数字minist数据集上的预测准确率。
应用Simple RNN进行手写数字预测训练的代码如下:
import keras from keras.layers import LSTM , SimpleRNN, GRU from keras.layers import Dense, Activation from keras.datasets import mnist from keras.models import Sequential from keras.optimizers import Adam learning_rate = 0.001 training_iters = 20 batch_size = 128 display_step = 10 n_input = 28 n_step = 28 n_hidden = 128 n_classes = 10 (x_train, y_train), (x_test, y_test) = mnist.load_data() x_train = x_train.reshape(-1, n_step, n_input) x_test = x_test.reshape(-1, n_step, n_input) x_train = x_train.astype('float32') x_test = x_test.astype('float32') x_train /= 255 x_test /= 255 y_train = keras.utils.to_categorical(y_train, n_classes) y_test = keras.utils.to_categorical(y_test, n_classes) model = Sequential() model.add(SimpleRNN(n_hidden, batch_input_shape=(None, n_step, n_input), unroll=True)) model.add(Dense(n_classes)) model.add(Activation('softmax')) adam = Adam(lr=learning_rate) model.summary() model.compile(optimizer=adam, loss='categorical_crossentropy', metrics=['accuracy']) history = model.fit(x_train, y_train, batch_size=batch_size, epochs=training_iters, verbose=1, validation_data=(x_test, y_test)) scores = model.evaluate(x_test, y_test, verbose=0) print('Simple RNN test score(loss value):', scores[0]) print('Simple RNN test accuracy:', scores[1])
训练结果:
_________________________________________________________________ Layer (type) Output Shape Param # ================================================================= simple_rnn_1 (SimpleRNN) (None, 128) 20096 _________________________________________________________________ dense_1 (Dense) (None, 10) 1290 _________________________________________________________________ activation_1 (Activation) (None, 10) 0 ================================================================= Total params: 21,386 Trainable params: 21,386 Non-trainable params: 0 _________________________________________________________________ Train on 60000 samples, validate on 10000 samples Epoch 1/20 60000/60000 [==============================] - 3s 51us/step - loss: 0.4584 - acc: 0.8615 - val_loss: 0.2459 - val_acc: 0.9308 Epoch 2/20 60000/60000 [==============================] - 3s 47us/step - loss: 0.1923 - acc: 0.9440 - val_loss: 0.1457 - val_acc: 0.9578 Epoch 3/20 60000/60000 [==============================] - 3s 47us/step - loss: 0.1506 - acc: 0.9555 - val_loss: 0.1553 - val_acc: 0.9552 Epoch 4/20 60000/60000 [==============================] - 3s 47us/step - loss: 0.1326 - acc: 0.9604 - val_loss: 0.1219 - val_acc: 0.9642 Epoch 5/20 60000/60000 [==============================] - 3s 47us/step - loss: 0.1184 - acc: 0.9651 - val_loss: 0.1014 - val_acc: 0.9696 Epoch 6/20 60000/60000 [==============================] - 3s 47us/step - loss: 0.1021 - acc: 0.9707 - val_loss: 0.1254 - val_acc: 0.9651 Epoch 7/20 60000/60000 [==============================] - 3s 47us/step - loss: 0.0987 - acc: 0.9708 - val_loss: 0.0946 - val_acc: 0.9733 Epoch 8/20 60000/60000 [==============================] - 3s 47us/step - loss: 0.0959 - acc: 0.9722 - val_loss: 0.1163 - val_acc: 0.9678 Epoch 9/20 60000/60000 [==============================] - 3s 47us/step - loss: 0.0888 - acc: 0.9742 - val_loss: 0.0983 - val_acc: 0.9718 Epoch 10/20 60000/60000 [==============================] - 3s 47us/step - loss: 0.0833 - acc: 0.9750 - val_loss: 0.1199 - val_acc: 0.9651 Epoch 11/20 60000/60000 [==============================] - 3s 47us/step - loss: 0.0814 - acc: 0.9750 - val_loss: 0.0939 - val_acc: 0.9722 Epoch 12/20 60000/60000 [==============================] - 3s 47us/step - loss: 0.0767 - acc: 0.9773 - val_loss: 0.0865 - val_acc: 0.9761 Epoch 13/20 60000/60000 [==============================] - 3s 47us/step - loss: 0.0747 - acc: 0.9778 - val_loss: 0.1077 - val_acc: 0.9697 Epoch 14/20 60000/60000 [==============================] - 3s 47us/step - loss: 0.0746 - acc: 0.9779 - val_loss: 0.1098 - val_acc: 0.9693 Epoch 15/20 60000/60000 [==============================] - 3s 47us/step - loss: 0.0671 - acc: 0.9799 - val_loss: 0.0776 - val_acc: 0.9771 Epoch 16/20 60000/60000 [==============================] - 3s 47us/step - loss: 0.0639 - acc: 0.9810 - val_loss: 0.0961 - val_acc: 0.9730 Epoch 17/20 60000/60000 [==============================] - 3s 47us/step - loss: 0.0701 - acc: 0.9792 - val_loss: 0.1046 - val_acc: 0.9713 Epoch 18/20 60000/60000 [==============================] - 3s 47us/step - loss: 0.0600 - acc: 0.9822 - val_loss: 0.0865 - val_acc: 0.9767 Epoch 19/20 60000/60000 [==============================] - 3s 47us/step - loss: 0.0635 - acc: 0.9813 - val_loss: 0.0812 - val_acc: 0.9790 Epoch 20/20 60000/60000 [==============================] - 3s 47us/step - loss: 0.0579 - acc: 0.9827 - val_loss: 0.0981 - val_acc: 0.9733 Simple RNN test score(loss value): 0.09805978989955037 Simple RNN test accuracy: 0.9733
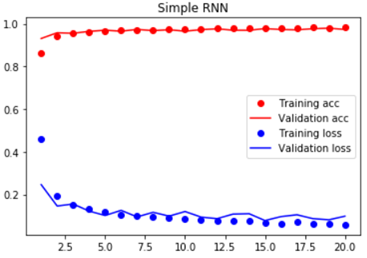
可知Simple RNN在测试集上的最终预测准确率为97.33%。
只需修改下方代码中Simple RNN为LSTM,即可调用LSTM进行模型训练:
model.add(SimpleRNN(n_hidden, batch_input_shape=(None, n_step, n_input), unroll=True))
改变为:
model.add(LSTM(n_hidden, batch_input_shape=(None, n_step, n_input), unroll=True))
训练结果:
_________________________________________________________________ Layer (type) Output Shape Param # ================================================================= lstm_1 (LSTM) (None, 128) 80384 _________________________________________________________________ dense_2 (Dense) (None, 10) 1290 _________________________________________________________________ activation_2 (Activation) (None, 10) 0 ================================================================= Total params: 81,674 Trainable params: 81,674 Non-trainable params: 0 _________________________________________________________________ Train on 60000 samples, validate on 10000 samples Epoch 1/20 60000/60000 [==============================] - 10s 172us/step - loss: 0.5226 - acc: 0.8277 - val_loss: 0.1751 - val_acc: 0.9451 Epoch 2/20 60000/60000 [==============================] - 8s 133us/step - loss: 0.1474 - acc: 0.9549 - val_loss: 0.1178 - val_acc: 0.9641 Epoch 3/20 60000/60000 [==============================] - 8s 133us/step - loss: 0.1017 - acc: 0.9690 - val_loss: 0.0836 - val_acc: 0.9748 Epoch 4/20 60000/60000 [==============================] - 8s 133us/step - loss: 0.0764 - acc: 0.9764 - val_loss: 0.0787 - val_acc: 0.9759 Epoch 5/20 60000/60000 [==============================] - 8s 133us/step - loss: 0.0607 - acc: 0.9811 - val_loss: 0.0646 - val_acc: 0.9813 Epoch 6/20 60000/60000 [==============================] - 8s 133us/step - loss: 0.0542 - acc: 0.9834 - val_loss: 0.0630 - val_acc: 0.9801 Epoch 7/20 60000/60000 [==============================] - 8s 133us/step - loss: 0.0452 - acc: 0.9859 - val_loss: 0.0603 - val_acc: 0.9803 Epoch 8/20 60000/60000 [==============================] - 8s 133us/step - loss: 0.0406 - acc: 0.9874 - val_loss: 0.0531 - val_acc: 0.9849 Epoch 9/20 60000/60000 [==============================] - 8s 133us/step - loss: 0.0345 - acc: 0.9888 - val_loss: 0.0540 - val_acc: 0.9834 Epoch 10/20 60000/60000 [==============================] - 8s 132us/step - loss: 0.0305 - acc: 0.9901 - val_loss: 0.0483 - val_acc: 0.9848 Epoch 11/20 60000/60000 [==============================] - 8s 133us/step - loss: 0.0281 - acc: 0.9913 - val_loss: 0.0517 - val_acc: 0.9843 Epoch 12/20 60000/60000 [==============================] - 8s 133us/step - loss: 0.0256 - acc: 0.9918 - val_loss: 0.0472 - val_acc: 0.9847 Epoch 13/20 60000/60000 [==============================] - 8s 133us/step - loss: 0.0229 - acc: 0.9929 - val_loss: 0.0441 - val_acc: 0.9874 Epoch 14/20 60000/60000 [==============================] - 8s 133us/step - loss: 0.0204 - acc: 0.9935 - val_loss: 0.0490 - val_acc: 0.9855 Epoch 15/20 60000/60000 [==============================] - 8s 133us/step - loss: 0.0192 - acc: 0.9938 - val_loss: 0.0486 - val_acc: 0.9851 Epoch 16/20 60000/60000 [==============================] - 8s 133us/step - loss: 0.0203 - acc: 0.9937 - val_loss: 0.0450 - val_acc: 0.9866 Epoch 17/20 60000/60000 [==============================] - 8s 133us/step - loss: 0.0160 - acc: 0.9948 - val_loss: 0.0391 - val_acc: 0.9882 Epoch 18/20 60000/60000 [==============================] - 8s 133us/step - loss: 0.0147 - acc: 0.9955 - val_loss: 0.0544 - val_acc: 0.9834 Epoch 19/20 60000/60000 [==============================] - 8s 133us/step - loss: 0.0147 - acc: 0.9953 - val_loss: 0.0456 - val_acc: 0.9880 Epoch 20/20 60000/60000 [==============================] - 8s 133us/step - loss: 0.0153 - acc: 0.9952 - val_loss: 0.0465 - val_acc: 0.9867 LSTM test score(loss value): 0.046479647984029725 LSTM test accuracy: 0.9867
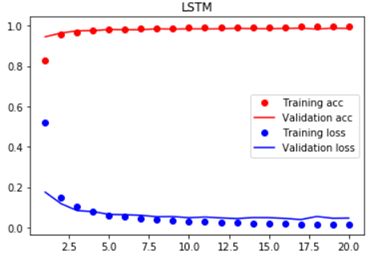
可知LSTM在测试集上的最终预测准确率为98.67%。
采用同样的思路,把Simple RNN改为GRU,即可调用GRU进行模型训练。
训练结果:
_________________________________________________________________ Layer (type) Output Shape Param # ================================================================= gru_1 (GRU) (None, 128) 60288 _________________________________________________________________ dense_3 (Dense) (None, 10) 1290 _________________________________________________________________ activation_3 (Activation) (None, 10) 0 ================================================================= Total params: 61,578 Trainable params: 61,578 Non-trainable params: 0 _________________________________________________________________ Train on 60000 samples, validate on 10000 samples Epoch 1/20 60000/60000 [==============================] - 10s 166us/step - loss: 0.6273 - acc: 0.7945 - val_loss: 0.2062 - val_acc: 0.9400 Epoch 2/20 60000/60000 [==============================] - 8s 130us/step - loss: 0.1656 - acc: 0.9501 - val_loss: 0.1261 - val_acc: 0.9606 Epoch 3/20 60000/60000 [==============================] - 8s 130us/step - loss: 0.1086 - acc: 0.9667 - val_loss: 0.0950 - val_acc: 0.9697 Epoch 4/20 60000/60000 [==============================] - 8s 130us/step - loss: 0.0824 - acc: 0.9745 - val_loss: 0.0761 - val_acc: 0.9769 Epoch 5/20 60000/60000 [==============================] - 8s 130us/step - loss: 0.0644 - acc: 0.9797 - val_loss: 0.0706 - val_acc: 0.9793 Epoch 6/20 60000/60000 [==============================] - 8s 130us/step - loss: 0.0540 - acc: 0.9829 - val_loss: 0.0678 - val_acc: 0.9799 Epoch 7/20 60000/60000 [==============================] - 8s 130us/step - loss: 0.0479 - acc: 0.9854 - val_loss: 0.0601 - val_acc: 0.9811 Epoch 8/20 60000/60000 [==============================] - 8s 130us/step - loss: 0.0402 - acc: 0.9877 - val_loss: 0.0495 - val_acc: 0.9848 Epoch 9/20 60000/60000 [==============================] - 8s 130us/step - loss: 0.0346 - acc: 0.9895 - val_loss: 0.0591 - val_acc: 0.9821 Epoch 10/20 60000/60000 [==============================] - 8s 130us/step - loss: 0.0306 - acc: 0.9901 - val_loss: 0.0560 - val_acc: 0.9836 Epoch 11/20 60000/60000 [==============================] - 8s 130us/step - loss: 0.0290 - acc: 0.9910 - val_loss: 0.0473 - val_acc: 0.9857 Epoch 12/20 60000/60000 [==============================] - 8s 130us/step - loss: 0.0249 - acc: 0.9922 - val_loss: 0.0516 - val_acc: 0.9852 Epoch 13/20 60000/60000 [==============================] - 8s 130us/step - loss: 0.0222 - acc: 0.9930 - val_loss: 0.0448 - val_acc: 0.9863 Epoch 14/20 60000/60000 [==============================] - 8s 130us/step - loss: 0.0206 - acc: 0.9934 - val_loss: 0.0453 - val_acc: 0.9872 Epoch 15/20 60000/60000 [==============================] - 8s 130us/step - loss: 0.0178 - acc: 0.9944 - val_loss: 0.0559 - val_acc: 0.9833 Epoch 16/20 60000/60000 [==============================] - 8s 130us/step - loss: 0.0173 - acc: 0.9947 - val_loss: 0.0502 - val_acc: 0.9854 Epoch 17/20 60000/60000 [==============================] - 8s 130us/step - loss: 0.0150 - acc: 0.9955 - val_loss: 0.0401 - val_acc: 0.9880 Epoch 18/20 60000/60000 [==============================] - 8s 130us/step - loss: 0.0164 - acc: 0.9949 - val_loss: 0.0486 - val_acc: 0.9872 Epoch 19/20 60000/60000 [==============================] - 8s 130us/step - loss: 0.0133 - acc: 0.9960 - val_loss: 0.0468 - val_acc: 0.9882 Epoch 20/20 60000/60000 [==============================] - 8s 130us/step - loss: 0.0107 - acc: 0.9965 - val_loss: 0.0470 - val_acc: 0.9879 GRU test score(loss value): 0.04698457587567973 GRU test accuracy: 0.9879
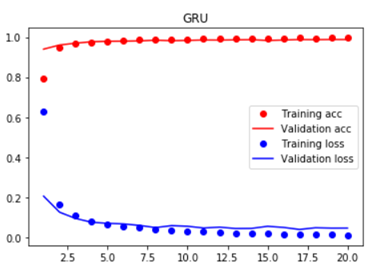
可知GRU在测试集上的最终预测准确率为98.79%。
由上述实验结果可知,LSTM和GRU的预测准确率要显著高于Simple RNN,而LSTM和GRU的预测准确率相差较小。
参考文献
[1] S. Hochreiter and J. Schmidhuber, “Long Short-Term Memory,” Neural Comput, vol. 9, no. 8, pp. 1735–1780, Nov. 1997.
[2] F. A. Gers, J. Schmidhuber, and F. A. Cummins, “Learning to Forget: Continual Prediction with LSTM,” Neural Comput., vol. 12, pp. 2451–2471, 2000.
[3] F. A. Gers and J. Schmidhuber, “Recurrent nets that time and count,” Proc. IEEE-INNS-ENNS Int. Jt. Conf. Neural Netw. IJCNN 2000 Neural Comput. New Chall. Perspect. New Millenn., vol. 3, pp. 189–194 vol.3, 2000.
[4] A. Graves and J. Schmidhuber, “Framewise phoneme classification with bidirectional LSTM and other neural network architectures,” Neural Netw., vol. 18, no. 5, pp. 602–610, Jul. 2005.
[5] K. Greff, R. K. Srivastava, J. Koutník, B. R. Steunebrink, and J. Schmidhuber, “LSTM: A Search Space Odyssey,” IEEE Trans. Neural Netw. Learn. Syst., vol. 28, no. 10, pp. 2222–2232, Oct. 2017.
[6] K. Cho et al., “Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation,” ArXiv14061078 Cs Stat, Jun. 2014.
[7] J. Chung, C. Gulcehre, K. Cho, and Y. Bengio, “Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling,” ArXiv14123555 Cs, Dec. 2014.
