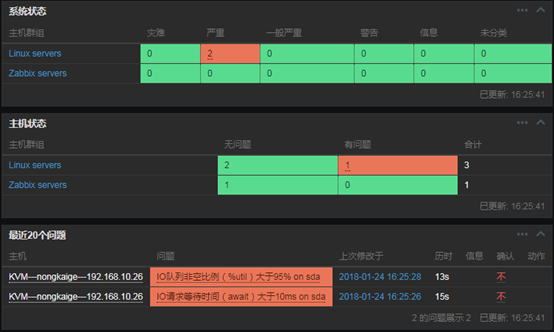
Zabbix自动发现并监控磁盘IO、报警
- 2020 年 3 月 6 日
- 筆記
本文转载自: https://www.93bok.com
引言
Zabbix并没有提供模板来监控磁盘的IO性能,所以我们需要自己来创建一个,由于一台服务器中磁盘众多,如果只有一两台可以手动添加,但服务集群达到几十那就非常麻烦,因此需要利用自动发现这个功能,自动发现后自动添加对服务器磁盘的监控,而且添加磁盘后也会自动添加到监控,实现自动化运维的效果,接下来我们就来看看怎么自动发现磁盘并自动监控磁盘的IO性能,再设置触发器,IO达到阈值后发出报警
iostat简介
iostat主要用于监控系统设备的IO负载情况,iostat首次运行时显示自系统启动开始的各项统计信息,之后运行iostat将显示自上次运行该命令以后的统计信息。用户可以通过指定统计的次数和时间来获得所需的统计信息。所以在使用iostat监控系统IO负载的时候,不要直接iostat取结果,而是iostat -dxkt 1 2取结果,否则得到的数据根本不正确
iostat安装
yum -y install sysstatiostat常用参数说明 -c #仅显示CPU统计信息.与-d选项互斥. -d #仅显示磁盘统计信息.与-c选项互斥. -k #以K为单位显示每秒的磁盘请求数,默认单位块. -t #在输出数据时,打印搜集数据的时间. -V #打印版本号和帮助信息. -x #输出扩展信息.iostat命令输出说明
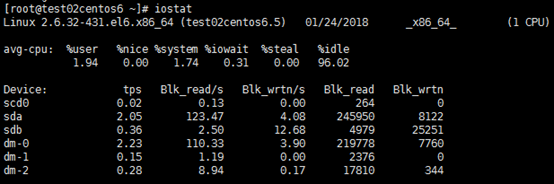
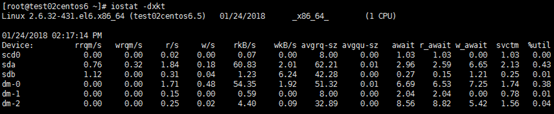
图一
avg-cpu段:
%user: 在用户级别运行所使用的CPU的百分比. %nice: nice操作所使用的CPU的百分比. %sys: 在系统级别(kernel)运行所使用CPU的百分比. %iowait: CPU等待硬件I/O时,所占用CPU百分比. %idle: CPU空闲时间的百分比.Device段:
tps: 每秒钟发送到的I/O请求数. Blk_read /s: 每秒读取的block数. Blk_wrtn/s: 每秒写入的block数. Blk_read: 读入的block总数. Blk_wrtn: 写入的block总数.图二
rrqm/s:每秒读请求被合并次数 wrqm/s:每秒写请求被合并次数 r/s:每秒完成的读次数 w/s:每秒完成的写次数 rkB/s:每秒读数据量(kb) wkB/s:每秒写数据量(kb) avgrq-sz:平均每次IO请求的扇区大小 avgqu-sz:平均每次IO请求的队列长度(越短越好) await:平均每次IO请求等待时间(毫秒),一般的系统IO等待时间应该低于5ms,如果大于10ms就比较大了。这个时间包括了队列时间和服务时间,也就是说,一般情况下,await大于svctm,它们的差值越小,则说明队列时间越短,反之差值越大,队列时间越长,说明系统出了问题。 r_await:读的平均耗时(毫秒) w_await:写入平均耗时(毫秒) svctm:平均每次IO请求处理时间(毫秒),如果svctm的值与await很接近,表示几乎没有I/O等待,磁盘性能很好,如果await的值远高于svctm的值,则表示I/O队列等待太长,系统上运行的应用程序将变慢。 %util:IO队列非空比例,该参数暗示了设备的繁忙程度。一般地,如果该参数是100%表示设备已经接近满负荷运行了一、在被监控端上编写自动发现和监控磁盘IO脚本
1、创建zabbix脚本存放目录
mkdir -p /etc/zabbix/scripts2、编写自动发现磁盘脚本
vim /etc/zabbix/scripts/disk_discovery.sh #!/bin/bash ############################################################ # $Name: disk_discovery.sh # $Function: DISK DISCOVERY # $Author: Mr.nong # $organization: nongziyi.xin # $Create Date: 2018/1/25 # $Description: Monitor DISK DISCOVERY ############################################################ disk_array=(`grep -E "(vd[a-z]$|sd[a-z]$)" /proc/partitions | awk '{print $4}'`) length=${#disk_array[@]} printf "{n" printf 't'""data":[" for ((i=0;i<$length;i++)) do printf 'ntt{' printf ""{#DISK_NAME}":"${disk_array[$i]}"}" if [ $i -lt $[$length-1] ];then printf ',' fi done printf "nt]n" printf "}n"3、编写监控磁盘IO脚本
vim /etc/zabbix/scripts/disk_io.sh #!/bin/bash ############################################################ # $Name: disk_io.sh # $Function: DISK IO # $Author: Mr.nong # $organization: nongziyi.xin # $Create Date: 2018/1/25 # $Description: Monitor DISK IO ############################################################ Device=$1 DISK=$2 case $DISK in #每秒读请求被合并次数 rrqm_s) iostat -dxkt 1 2 | grep "b$Deviceb" | awk 'NR==2{print $2}' ;; #每秒写请求被合并次数 wrqm_s) iostat -dxkt 1 2 | grep "b$Deviceb" | awk 'NR==2{print $3}' ;; #每秒完成的读次数 r_s) iostat -dxkt 1 2 | grep "b$Deviceb" | awk 'NR==2{print $4}' ;; #每秒完成的写次数 w_s) iostat -dxkt 1 2 | grep "b$Deviceb" | awk 'NR==2{print $5}' ;; #每秒读数据量(kb) rkb_s) iostat -dxkt 1 2 | grep "b$Deviceb" | awk 'NR==2{print $6}' ;; #每秒写数据量(kb) wkb_s) iostat -dxkt 1 2 | grep "b$Deviceb" | awk 'NR==2{print $7}' ;; #平均每次IO请求的扇区大小 avgrq_sz) iostat -dxkt 1 2 | grep "b$Deviceb" | awk 'NR==2{print $8}' ;; #平均每次IO请求的队列长度(越短越好) avgqu_sz) iostat -dxkt 1 2 | grep "b$Deviceb" | awk 'NR==2{print $9}' ;; #平均每次IO请求等待时间(毫秒) await) iostat -dxkt 1 2 | grep "b$Deviceb" | awk 'NR==2{print $10}' ;; #读的平均耗时(毫秒) r_await) iostat -dxkt 1 2 | grep "b$Deviceb" | awk 'NR==2{print $11}' ;; #写入平均耗时(毫秒) w_await) iostat -dxkt 1 2 | grep "b$Deviceb" | awk 'NR==2{print $12}' ;; #平均每次IO请求处理时间(毫秒) svctm) iostat -dxkt 1 2 | grep "b$Deviceb" | awk 'NR==2{print $13}' ;; #IO队列非空比例 util) iostat -dxkt 1 2 | grep "b$Deviceb" | awk 'NR==2{print $14}' ;; esac 4、给予脚本执行权限
chmod +x /etc/zabbix/scripts/disk_*5、编辑zabbix_agentd的配置文件支持自定义脚本
vim /etc/zabbix/zabbix_agentd.conf UnsafeUserParameters=16、编辑zabbix_agentd的配置文件添加zabbix配置文件目录
vim /etc/zabbix/zabbix_agentd.conf Include=/etc/zabbix/zabbix_agentd.conf.d/7、创建disk_io的key文件
vim /etc/zabbix/zabbix_agentd.conf.d/disk_status.conf UserParameter=disk.discovery[*],/etc/zabbix/scripts/disk_discovery.sh UserParameter=disk.io[*],/etc/zabbix/scripts/disk_io.sh $1 $2参数说明: 其中的格式为UserParameter=<key>,<command> <key>:就是在web端添加监控脚本时的key值 <command>:就是该key值对应的执行脚本,也就是脚本执行路径7、重启zabbix_agentd服务
service zabbix_agentd restart8、在zabbix server端进行测试
/a01/apps/zabbix/bin/zabbix_get -s 192.168.10.26 -k 'disk.discovery[*]'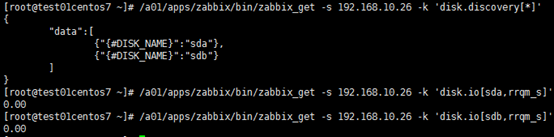
9、到zabbix web前端创建模板
- “配置”——“模板”——“创建模板”
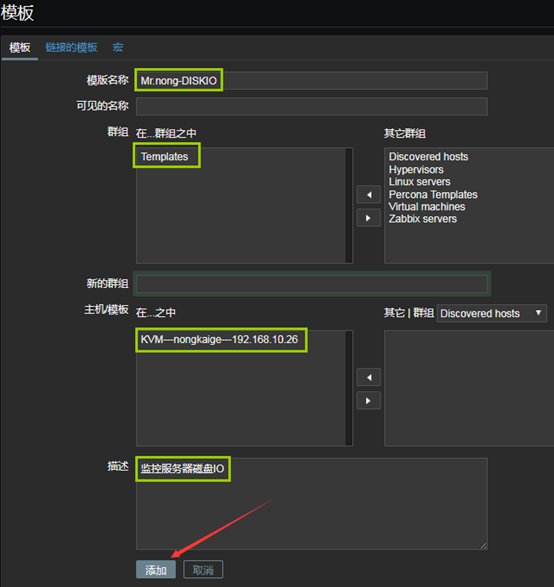
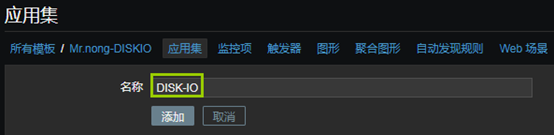
10、创建应用集
- “配置”——“模板”——“选中模板”——应用集”——“创建应用集”
11、创建自动发现规则
- “配置”——“模板”——“选中模板”——“自动发现规则”——“创建自动发现规则”
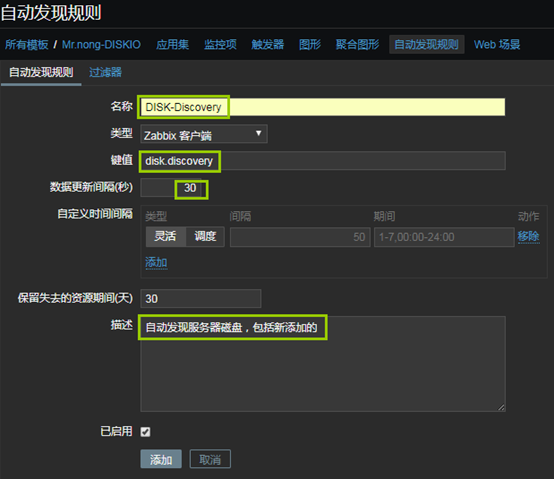
- 上图中的“数据更新间隔(秒)”可以调整为久一些,因为服务器添加硬盘不是每天都干的事,这里为了后边验证效果,我就不修改了
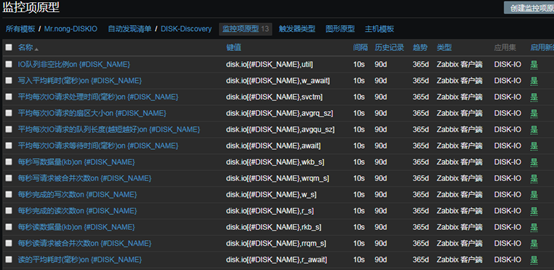
12、创建监控项原型(键值[]中的数值必须大写,否则会报错如下)
Cannot create item: item with the same key “diskio.x.[[xxxxxx]] already exists
- 一个一个创建即可,这里只截图一个作为参考
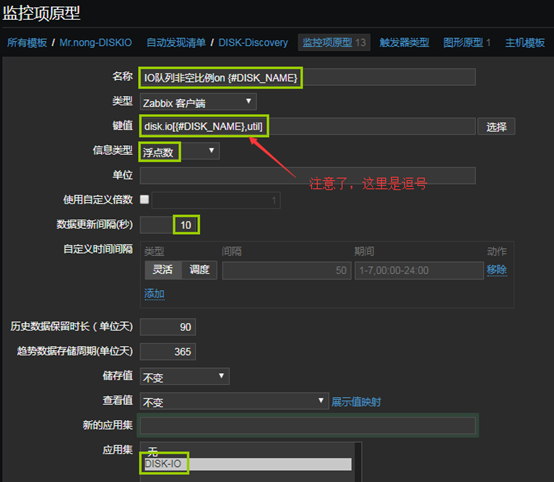
- 创建为完成
13、创建图形原型(名称后边要带哪个磁盘的动态名称,否则会报错如下)
zabbix3 Cannot create graph: graph with the same name "Disk IO" already exists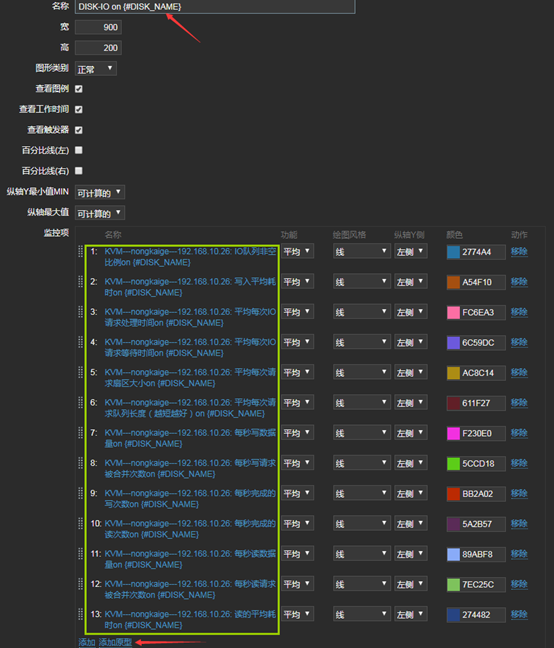
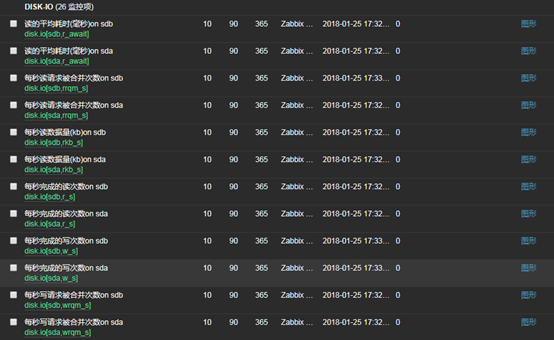
14、查看是否获取到数据(现在获取到的数据都是0,稍候我们会进行测试)
- 可以看到有sda和sdb两块磁盘被监控到数据了,因为我的这台服务器有两块磁盘
- “监测中”——“最新数据”——“过滤器”——“应用”
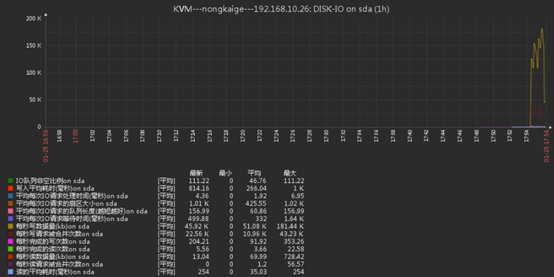
16、在被监控端上模拟磁盘写入进行测试
dd if=/dev/zero of=/a.txt bs=8k count=300000017、查看我们创建的图形
二、新添一块磁盘,看看是否能自动发现磁盘并监控
- 添加硬盘,分区,格式化过程省略,这里我添加了一块5G硬盘,分区格式化之后挂载在/mnt下,添加完之后直接上zabbix web页面查看是否自己生成图像
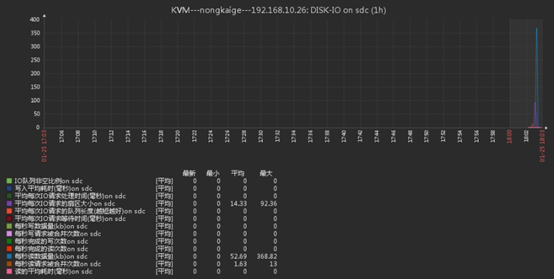
三、配置触发器,达到阈值报警
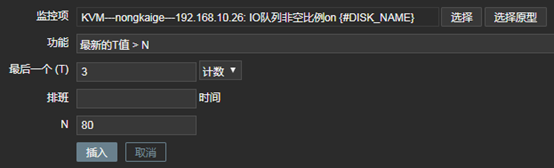
A、IO请求等待时间(await)大于10ms则报警
- “配置”——“选择主机”——“自动发现规则”——“触发器类型”——“创建触发器原型”
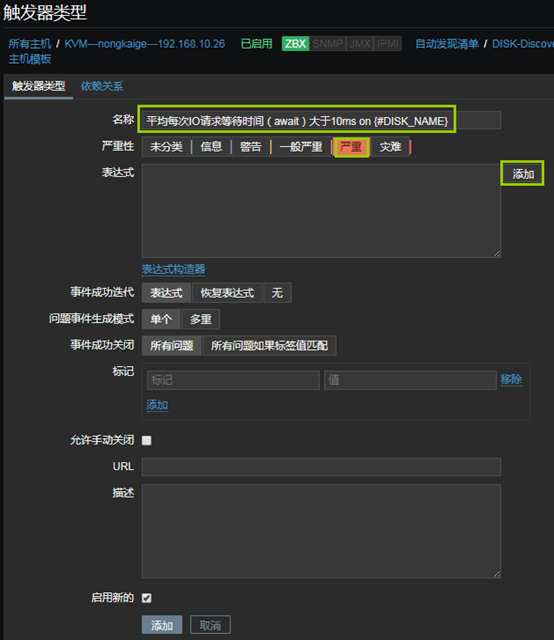
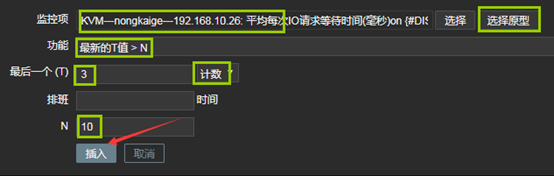
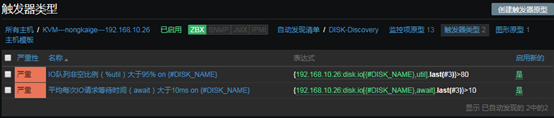
上图中的参数说明: 1、监控项:定义被监控项的阈值 2、功能:功能说起来比较麻烦,但是并不难理解,我举个例子,假如设定,一个养鸡场的温度不能低于30度,如果低于30度,则报警;那么我也可以设定,如果温度等于30度,我们就报警;或者说,如果温度高于30度就报警。那到底是低于,等于,还是高于,这得看我们自己怎么设定。还有就是,我们还可以设定,如果5分钟前的检测低于/等于/高于30度,报警;甚至还可以这样,如果连续10分钟内获取的温度值的平均值都低于/等于/高于30度,报警。那么在zabbix中,怎样实现这样灵活的设定呢,就是通过“功能”栏定义的,比如,最近T次监测或者T分钟内的监测,养鸡场的温度出现了小于N度的情况,在功能栏中可以选择“最新的T值<N”。 3、最后一个(T):我们在“功能”中,已经选择了某种定义,比如“最新的T值<N”,那么T是以时间为单位呢,还是以次数为单位呢,如果我们想定义“最近的第T次,养鸡场的温度小于30度”,那么此处需要选择“计数”。如果我们想要定义“最近T分钟内,养鸡场的温度小于30度”,那么此处需要选择“时间”。 4、排班:如果我们想要定义“最近T分钟内,养鸡场的温度小于30度”,则“最后一个(T)”需要选择“时间”,同时在此处指明时间长度,默认单位是秒。 5、N:此处用于设置N的值,比如“最近一次监测的养鸡场温度小于30度”,那么这里N就是30。 在本例中,我监控了await这个数值,整个触发器的意思就是:在最近的3次监测中,await的状态都大于10,则报警。 B、IO队列非空比例(%util)大于80%时报警
- “配置”——“选择主机”——“自动发现规则”——“触发器类型”——“创建触发器原型”
四、再次模拟磁盘写入,测试会不会触发到报警
dd if=/dev/zero of=/a.txt bs=8k count=3000000