硬核!Apache Hudi Schema演变深度分析与应用
- 2022 年 11 月 20 日
- 筆記
1.场景需求
在医疗场景下,涉及到的业务库有几十个,可能有上万张表要做实时入湖,其中还有某些库的表结构修改操作是通过业务人员在网页手工实现,自由度较高,导致整体上存在非常多的新增列,删除列,改列名的情况。由于Apache Hudi 0.9.0 版本到 0.11.0 版本之间只支持有限的schema变更,即新增列到尾部的情况,且用户对数据质量要求较高,导致了非常高的维护成本。每次删除列和改列名都需要重新导入,这种情况极不利于长期发展,所以需要一种能够以较低成本支持完整schema演变的方案。
2.社区现状
在 //hudi.apache.org/docs/schema_evolution 中提到:schema演化允许用户轻松更改 Apache Hudi 表的当前 Schema,以适应随时间变化的数据。从 0.11.0 版本开始,已添加 Spark SQL(Spark 3.1.x、3.2.1 及更高版本)对 Schema 演化的 DDL 支持并处于试验阶段。
- 可以添加、删除、修改和移动列(包括嵌套列)
- 分区列不能进化
- 不能对 Array 类型的嵌套列进行添加、删除或操作
为此我们针对该功能进行了相关测试和调研工作。
2.1 Schema演变的版本迭代
回顾Apache Hudi 对schema演变的支持随着版本迭代的变化如下:
| 版本 | Schema演变支持 | 多引擎查询 |
|---|---|---|
| *<0.9 | 无 | 无 |
| 0.9<* | 在最后的根级别添加一个新的可为空列 | 是(全) |
| 向内部结构添加一个新的可为空列(最后) | 是(全) | |
| 添加具有默认值的新复杂类型字段(地图和数组) | 是(全) | |
添加自定义可为空的 Hudi 元列,例如_hoodie_meta_col |
是(全) | |
为根级别的字段改变数据类型从 int到long |
是(全) | |
将嵌套字段数据类型从int到long |
是(全) | |
将复杂类型(映射或数组的值)数据类型从int到long |
是(全) | |
| 0.11<* | 相比之前版本新增:改列名 | spark以外的引擎不支持 |
| 相比之前版本新增:删除列 | spark以外的引擎不支持 | |
| 相比之前版本新增:移动列 | spark以外的引擎不支持 |
Apache Hudi 0.11.0版本完整Schema演变支持的类型修改如下:
| Source\Target | long | float | double | string | decimal | date | int |
|---|---|---|---|---|---|---|---|
| int | Y | Y | Y | Y | Y | N | Y |
| long | Y | N | Y | Y | Y | N | N |
| float | N | Y | Y | Y | Y | N | N |
| double | N | N | Y | Y | Y | N | N |
| decimal | N | N | N | Y | Y | N | N |
| string | N | N | N | Y | Y | Y | N |
| date | N | N | N | Y | N | Y | N |
2.2 官网提供的方式
实践中0.9.0版本的新增列未发现问题,已在正式环境使用。每次写入前捕获是否存在新增列删除列的情况,新增列的情况及时补空数据和struct,新增列的数据及时写入Hudi中;删除列则数据补空,struct不变,删除列仍写入Hudi中;每天需要重导数据处理删除列和修改列的情况,有变化的表在Hive中的元数据也以天为单位重新注册。
0.11开始的方式,按照官网的步骤:
进入spark-sql
# Spark SQL for spark 3.1.x
spark-sql --packages org.apache.hudi:hudi-spark3.1.2-bundle_2.12:0.11.1 \
--conf 'spark.serializer=org.apache.spark.serializer.KryoSerializer' \
--conf 'spark.sql.extensions=org.apache.spark.sql.hudi.HoodieSparkSessionExtension'
# Spark SQL for spark 3.2.1 and above
spark-sql --packages org.apache.hudi:hudi-spark3-bundle_2.12:0.11.1 \
--conf 'spark.serializer=org.apache.spark.serializer.KryoSerializer' \
--conf 'spark.sql.extensions=org.apache.spark.sql.hudi.HoodieSparkSessionExtension' \
--conf 'spark.sql.catalog.spark_catalog=org.apache.spark.sql.hudi.catalog.HoodieCatalog'
设置参数,删列:
set hoodie.schema.on.read.enable=true;
---创建表---
create table test_schema_change (
id string,
f1 string,
f2 string,
ts bigint
) using hudi
tblproperties (
type = 'mor',
primaryKey = 'id',
preCombineField = 'ts'
);
---1.新增列---
alter table test_schema_change add columns (f3 string);
---2.删除列---
alter table test_schema_change drop column f2;
---3.改列名---
alter table test_schema_change rename column f1 to f1_new;
2.3 其他方式
由于spark-sql的支持只在spark3.1之后支持,寻找并尝试了 BaseHoodieWriteClient.java 中存在名为 addColumn renameColumn deleteColumns 的几个方法,通过主动调用这些方法,也能达到schema完整变更的目的。使用这种方式需要将DDL的sql解析为对应的方法和参数,另外由于该方式测试和使用的例子还比较少,存在一些细节问题需要解决。
val hsec = new HoodieSparkEngineContext(spark.sparkContext);
val hoodieCfg = HoodieWriteConfig.newBuilder().forTable(tableName).withEmbeddedTimelineServerEnabled(true).withPath(basePath).build()
val client = new SparkRDDWriteClient(hsec, hoodieCfg)
//增加列
client.addColumn("f3",Schema.create(Schema.Type.STRING))
//删除列
client.deleteColumns("f1")
//改列名
client.renameColumn("f2","f2_c1")
4. 完整Schema变更的写入
4.1 核心实现
其中核心的类为 org.apache.hudi.internal.schema.InternalSchema ,出自HUDI-2429,通过记录包括顺序的完整列信息,并且每次变更都保存历史记录,而非之前的只关注最新 org.apache.avro.Schema。
- 添加列:对于按顺序添加列类型的添加操作,添加列信息附加到 InternalSchema 的末尾并分配新的 ID。ID 值 +1
- 改列名 :直接更改 InternalSchema 中列对应的字段的名称、属性、类型ID
- 删除列:删除 InternalSchema 中列对应的字段
4.2 记录完整schema变更
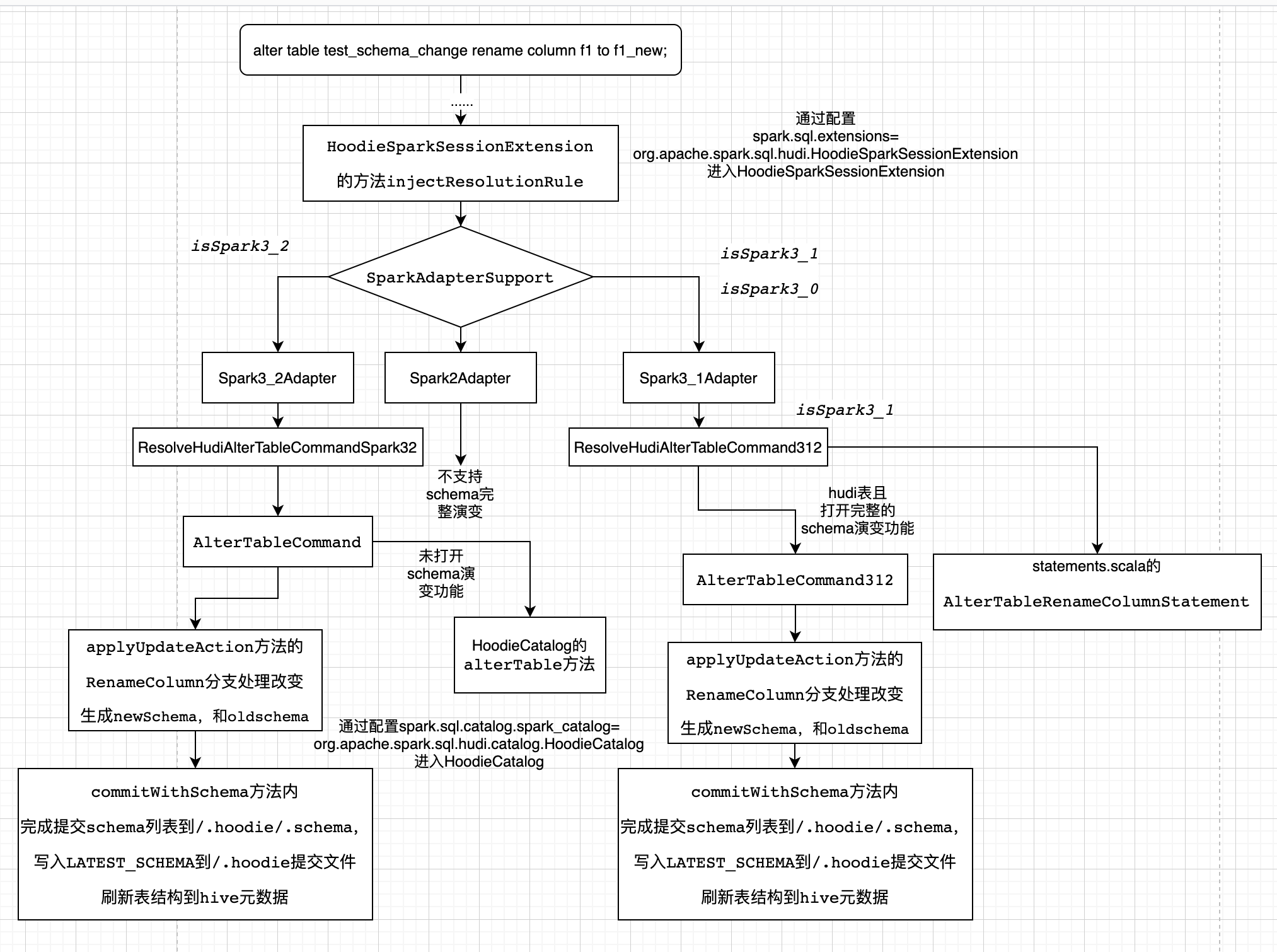
4.2.1 spark-sql方式
spark-sql的方式只支持Spark3.1、Spark3.2,分析如下:
4.2.2 HoodieWriteClient API方式
此处以BaseHoodieWriteClient.java 中具体修改方法的实现逻辑,分析完整schema演变在写入过程的支持。
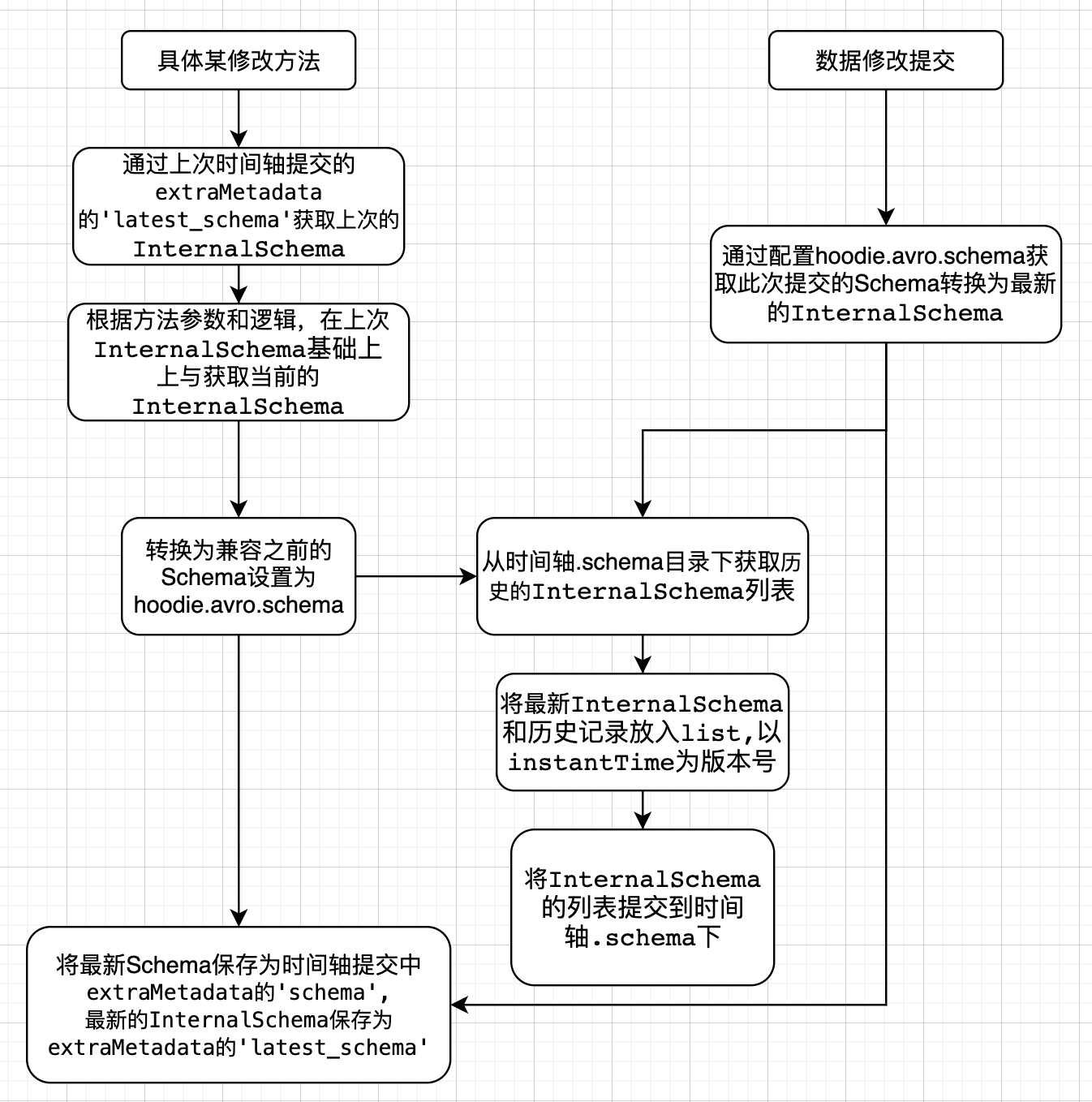
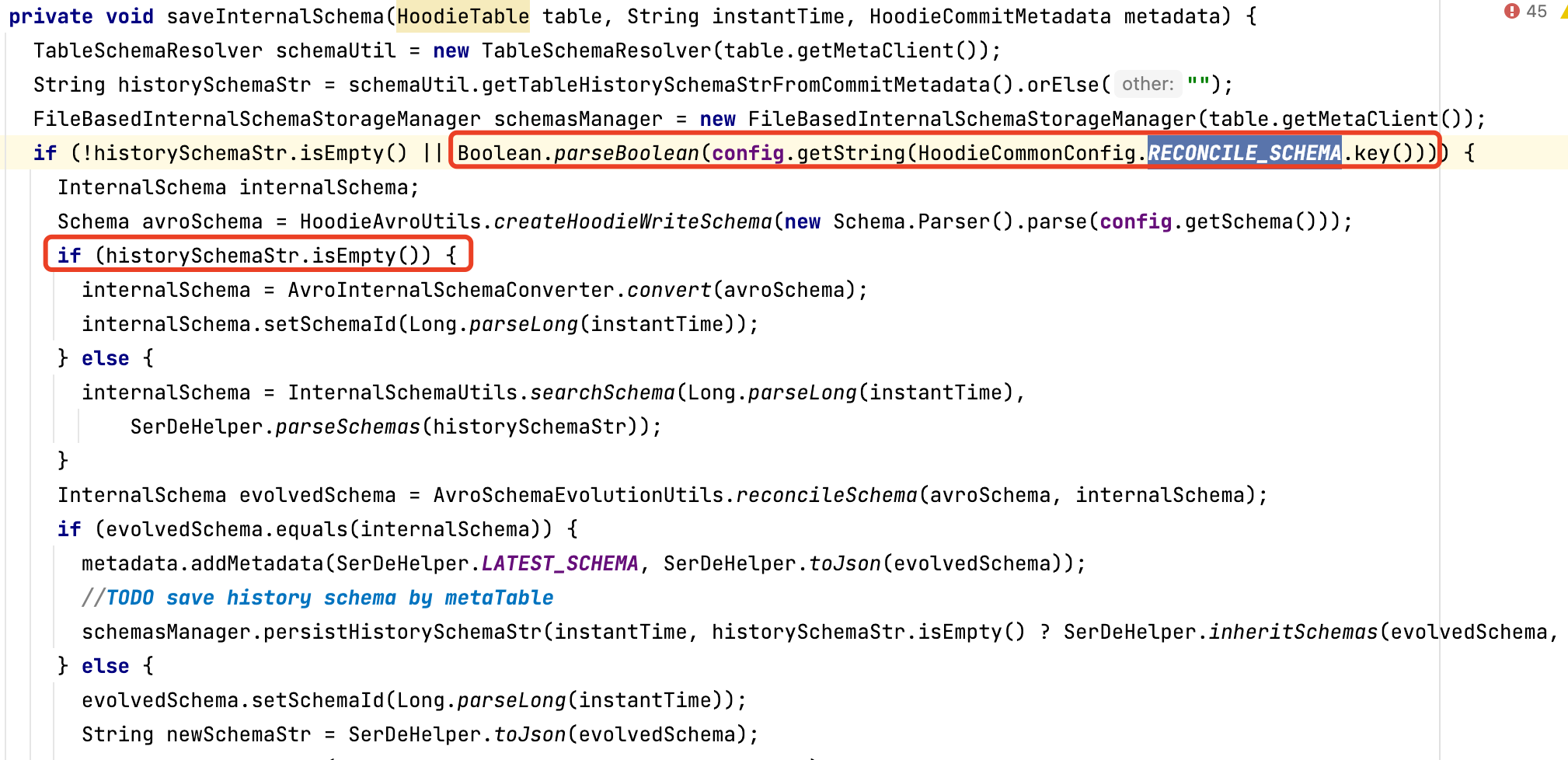
注意:在一次数据写入操作完成后的commit阶段,会根据条件判断,是否保存 InternalSchema,关键条件为参数 hoodie.schema.on.read.enable
主动修改列的操作前,需要先存在历史schema,否则会抛出异常 “cannot find schema for current table: ${basepath}”,因为metadata里不存在SerDeHelper.LATEST_SCHEMA(latest_schema)
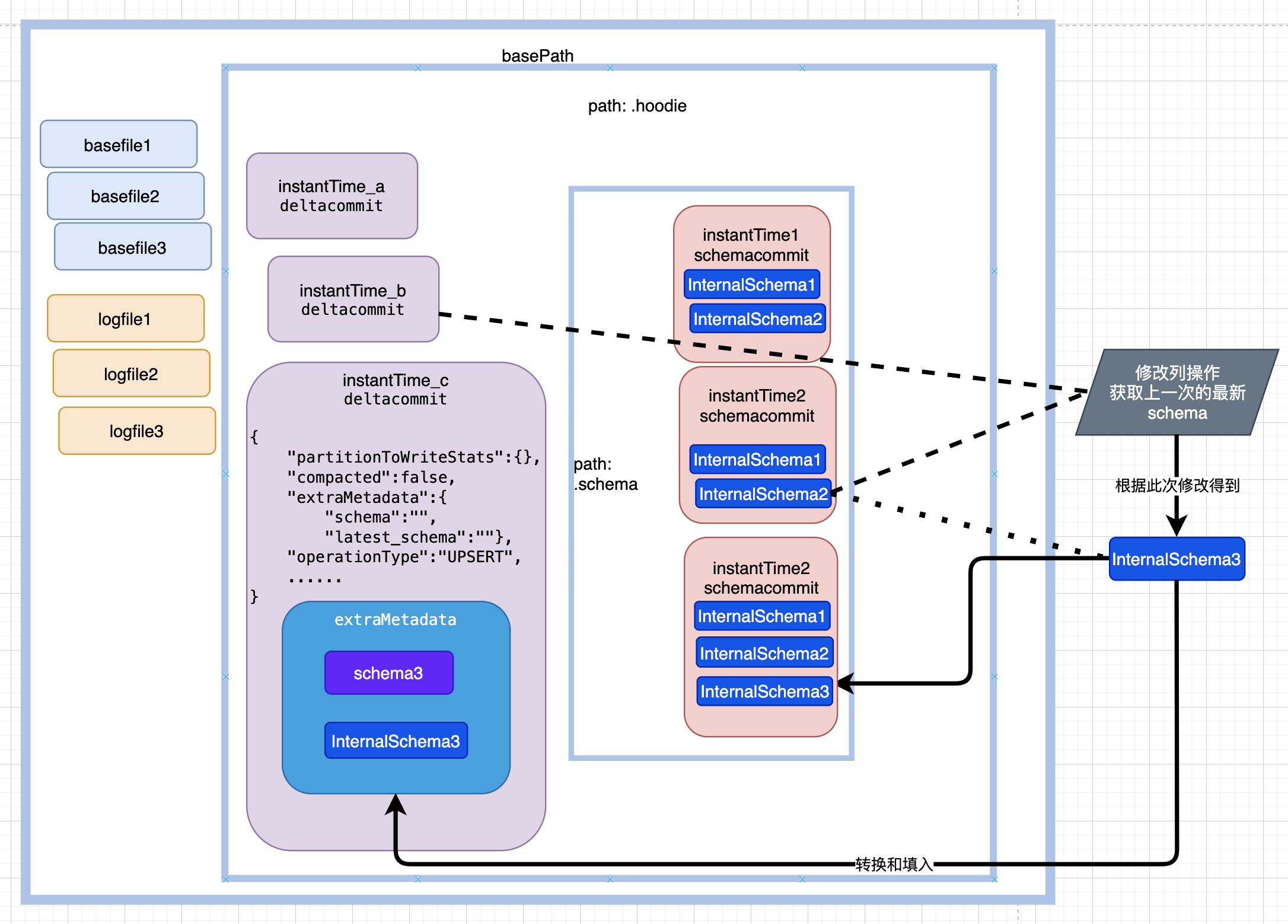
4.3 时间轴示例
如图所示,每次提交生成一份历史的schema,位于${basePath}/.hoodie/.schema目录下。
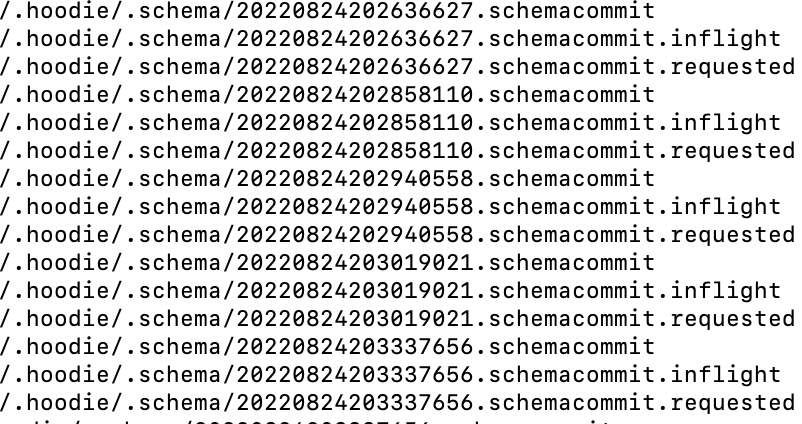
其中20220824202636627.schemacommit 内容:
{
"schemas": [
{
"max_column_id": 8,
"version_id": 20220824202636627,
"type": "record",
"fields": [
...
{
"id": 5,
"name": "id",
"optional": true,
"type": "string"
},
{
"id": 6,
"name": "f1",
"optional": true,
"type": "string"
},
{
"id": 7,
"name": "f2",
"optional": true,
"type": "string"
},
{
"id": 8,
"name": "ts",
"optional": true,
"type": "long"
}
]
}
]
}
期间新增了列f3后
20220824203337656.schemacommit 内容为:
{
"schemas": [
{
"max_column_id": 9,
"version_id": 20220824202940558,
"type": "record",
"fields": [
...
{
"id": 5,
"name": "id",
"optional": true,
"type": "string"
},
{
"id": 6,
"name": "f1",
"optional": true,
"type": "string"
},
{
"id": 7,
"name": "f2",
"optional": true,
"type": "string"
},
{
"id": 8,
"name": "ts",
"optional": true,
"type": "long"
},
{
"id": 9,
"name": "f3",
"optional": true,
"type": "string"
}
]
},
{
"max_column_id": 8,
"version_id": 20220824202636627,
"type": "record",
"fields": [
...
{
"id": 5,
"name": "id",
"optional": true,
"type": "string"
},
{
"id": 6,
"name": "f1",
"optional": true,
"type": "string"
},
{
"id": 7,
"name": "f2",
"optional": true,
"type": "string"
},
{
"id": 8,
"name": "ts",
"optional": true,
"type": "long"
}
]
}
]
}
其中max_column_id 为列id最大值,version_id 为版本号,也为instantTime。
存在 latest_schema 的情况如下所示:
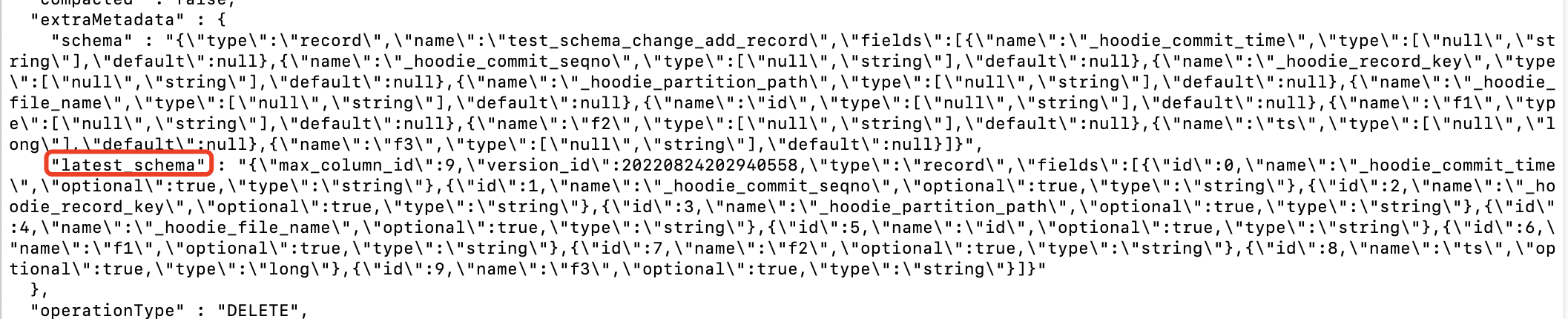
4.4 优化建议
主动调用 BaseHoodieWriteClient.java 类中相应方法的方式下,由于保存历史schema的逻辑上,a.打开该功能参数(hoodie.schema.on.read.enable) && b.存在历史schema的才能保存历史schema,在使用该功能之前或低于0.11版本的写入升级到该版本,已经正在更新的hudi表,无法使用该功能。建议把条件a为真,b为假的情况,根据当前schema直接生成历史schema

该处细节问题已经在HUDI-4276修复,0.12.0版本及以后不会有这个问题
hoodie.datasource.write.reconcile.schema 默认为false,如果要达到上述目的,改为true即可
5. 实现完整schema变更的查询
大体流程如下:
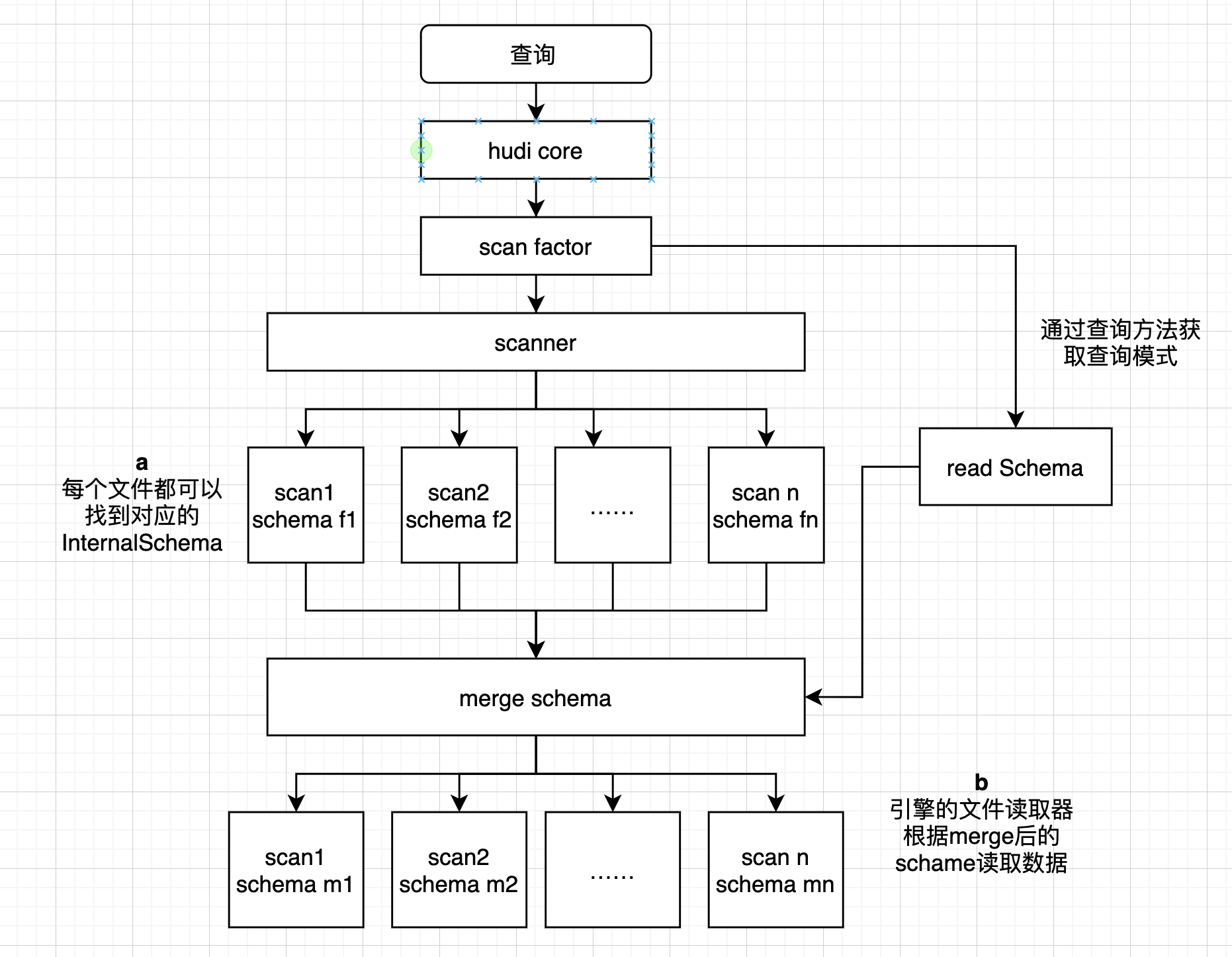
1.总体流程为某个查询进入dataSource中,选择具体的relacation,获取查询schema,获取scan
2.在scan中获取每个基础文件或日志的数据块对应的数据schema
3.在scan中获取数据schema后与查询schema进行merge,通过merge的schema来读取具体数据
5.1 获取数据schema
上图中流程 **a **大体流程如下:
5.1.1 基础文件获取流程
由于基础文件的命名方式和组织形式,基础文件的scan过程在HoodieParquetFileFormat中可以直接通过文件名获取InstantTime:
在用于读取和写入hudi表DefaultSource中,createRelation方法按照参数创建对应的BaseRelation扩展子类
HoodieBaseRelation#buildScan中调用 composeRDD 方法,该方法分别在子类BaseFileOnlyRelation,MergeOnReadSnapshotRelation,MergeOnReadIncrementalRelation 中实现,
以MergeOnReadSnapshotRelation 即mor表的快照读为例,在composeRDD 方法中调用父类createBaseFileReader的方法,其中val parquetReader = HoodieDataSourceHelper.buildHoodieParquetReader,以SparkAdapterSupport的createHoodieParquetFileFormat创建ParquetFileFormat,
SparkAdapterSupport的三个子类分别为Spark2Adapter,Spark3_1Adapter和Spark3_2Adapter,以Spark3_1Adapter实现的方法为例
创建Spark31HoodieParquetFileFormat,其中buildReaderWithPartitionValues方法中,会通过FSUtils.getCommitTime获取InstantTime
5.1.2 日志文件获取流程
log文件的文件名中的时间戳与提交 instantTime不一致,一个log文件对应多次时间轴 instantTime 提交。
日志文件的scan在AbstractHoodieLogRecordReader.java的的通过每个HoodieDataBlock的header中的 INSTANT_TIME 获取对应的 instantTime
以MergeOnReadSnapshotRelation为例,在composeRDD中创建HoodieMergeOnReadRDD
在HoodieMergeOnReadRDD的compute方法中使用的LogFileIterator类及其子类中使用HoodieMergeOnReadRDD的scanLog方法
scanLog中创建HoodieMergedLogRecordScanner,创建时执行performScan() -> 其父类AbstractHoodieLogRecordReader的scan(),
scan() -> scanInternal() -> processQueuedBlocksForInstant() 循环获取双端队列的logBlocks -> processDataBlock() -> getMergedSchema()
在getMergedSchema方法中通过HoodieDataBlock的getLogBlockHeader().get(INSTANT_TIME)获取InstantTime
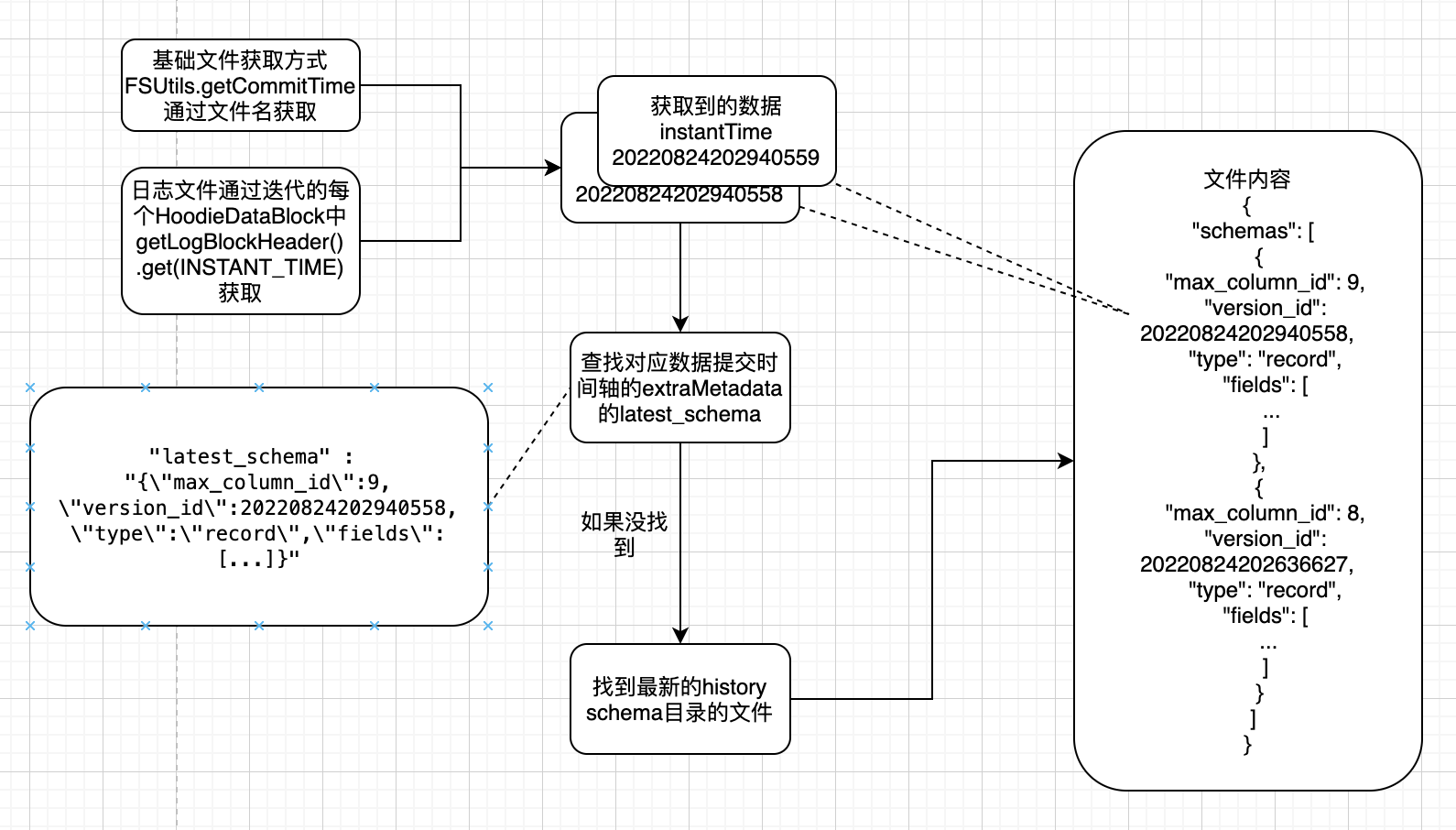
5.1.3 通过instantTime获取数据schema
根据InstantTime获取时间轴提交文件
如果能够获取,直接取其中extraMetadata中的latest_schema内容作为数据schema
如果不能获取,在获取最新的${basePath}/.hoodie/.schema/下的具体文件后,通过文件内容搜索具体 InternalSchema找到最新的history
如果有InstantTime对应的versino_id,直接获取
如果没有InstantTime对应的versino_id,说明那次写入无变化,从那次写入前的最新一次获取
5.2 合并查询schema与数据schema
5.2.1 merge方法解析
-
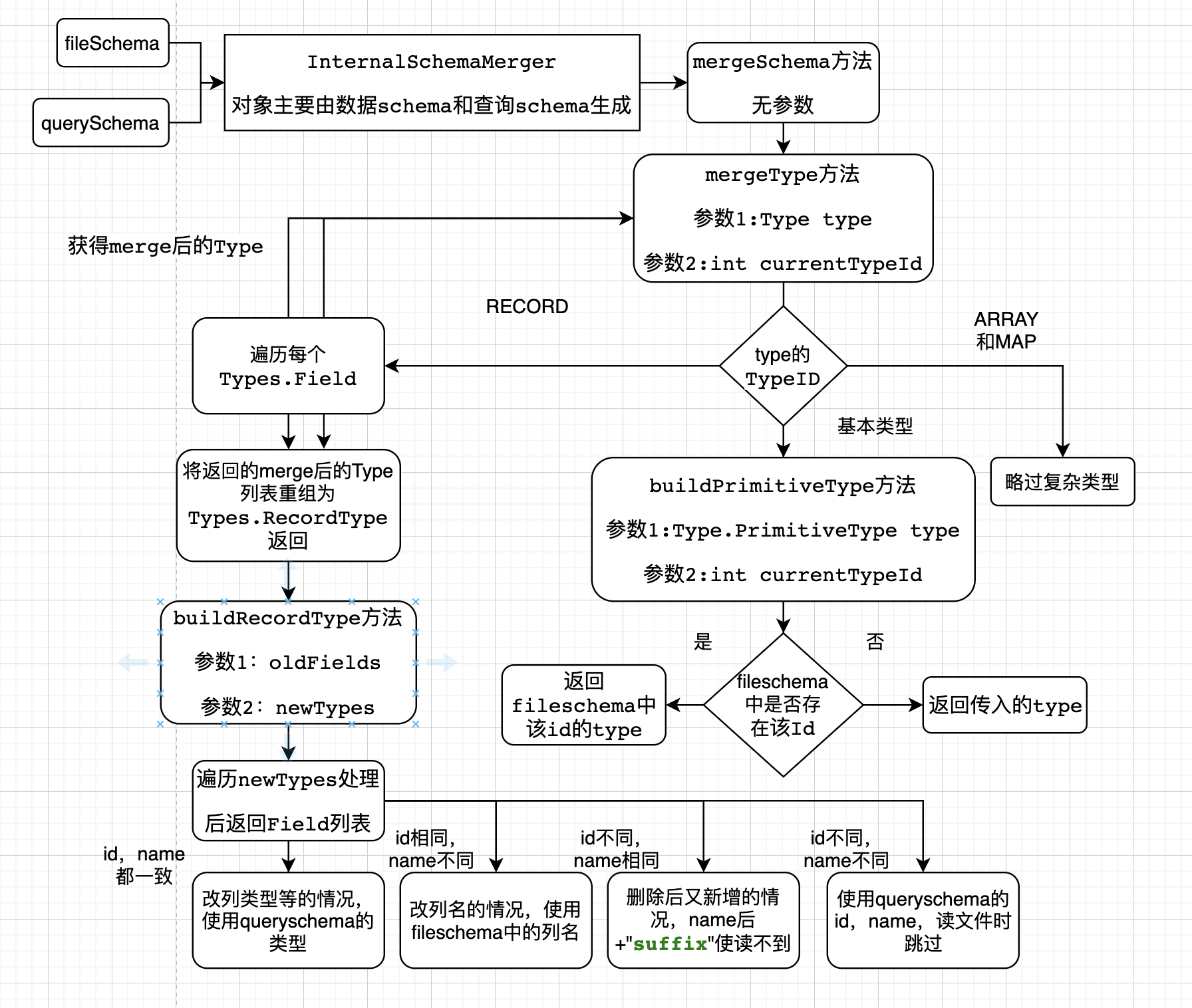
输入数据schema和查询schema,和几个布尔属性,获得InternalSchemaMerger对象
-
递归调用mergeType方法处理查询schema,首先进入RECORD,遍历每个列,mergeType方法处理
-
略过复杂类型
-
基本类型中会进入buildPrimitiveType方法
-
根据输入的id获取数据schena的Type,如果没有,就返回输入的Type
-
-
将返回的Type加入名为 newTypes的Type列表,把newTypes和查询schema的字段列表的输入buildRecordType方法
-
遍历查询schema的列,并用id和name获取数据schema的列
-
如果id和name都一致,为改列类型,使用数据schema的类型
-
如果id相同,name不同,改列名,使用数据schema的名字
-
如果id不同,name相同,先删后加,加后缀保证读不到文件内容
-
如果id不同,name不同,后来新增列
-
-
组装返回merge后的schema
5.2.2 merge示例
如下所示:
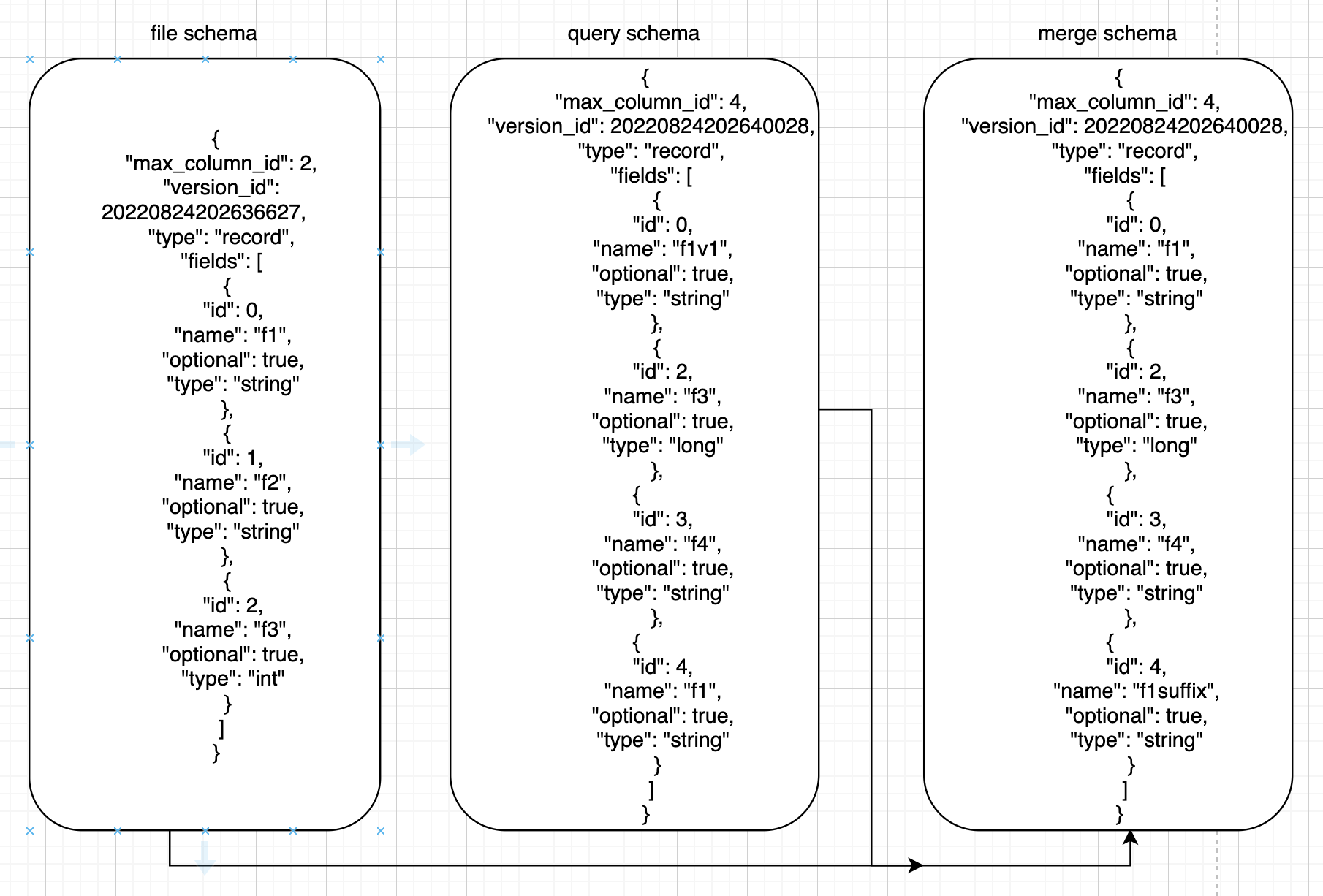
其中id为唯一标志性,
id=0的query里改名为f1v1,merge后为f1,
id=1的query里删除,merge里也没有,
id=2的query里为long型,files里为int型,merge里为long型
id=3的query里新增,返回query的字段
id=4的query里name为f1,对应file里的name为f1的id为0,所以merge里id为4,name为 (“f1″+”suffix”)
6. 各种引擎的支持
6.1 Spark测试结果
测试的Spark版本 > spark3.1且 hoodie.schema.on.read.enable=true
完全支持
否则测试结果如下:
| 操作类型 | 是否支持 | 原因 |
|---|---|---|
| 新增列 | 是 | 按列名查询,没有的列返回null |
| 删除列 | 是 | 按列名查询,原有的列跳过 |
| 改列名 | 否 | 按列名查询不到old_field值,能查询到new_field的值 |
6.2 Hive遇到的问题
Hive查询MOR的rt表有些问题,此处不再细述,此处修改列操作后都同步Hive元数据
| 操作类型 | 是否支持 | 原因 |
|---|---|---|
| 新增列 | 是 | 按列名查询基础文件,文件没有的列返回null |
| 删除列 | 是 | 按列名查询基础文件,文件原有列跳过 |
| 改列名 | 否 | 按列名查询不到old_field值,能查询到new_field的值 |
由于hive的查询依据的是hive metastore中的唯一版本的元数据,数据修改列后还需要同步到hive后才能查询到表的变更,该过程只读取时间轴中最新提交的schema,且查询使用的类 org.apache.hudi.hadoop.HoodieParquetInputFormat 中并不存在针对schema完整变更做出的改动,所以测试结果与 spark2.* 或hoodie.schema.on.read.enable=false 的情况相当。
重命名列的情况下,查询不到改名后的列名对应的数据。需要所有文件组都在改列名后产生新的基础文件后,数据才准确。
6.3 Presto遇到的问题
由于Presto同样使用hive的元数据,330的presto遇到的问题和hive遇到的问题一致,查询rt表仍为查询ro表
trino-360 和 presto275 使用某个patch支持查询rt表后,查询ro表问题如下:
| 操作类型 | 是否支持 | 原因 |
|---|---|---|
| 新增列 | 否 | 按顺序查询基础文件,导致串列,新增列在ts列之前可能抛出异常 |
| 删除列 | 否 | 按顺序查询基础文件,导致串列,因为ts类型很可能抛出异常 |
| 改列名 | 是 | 按顺序查询基础文件,名字不同,顺序相同 |
出现串列异常,除非所有文件组的最新基础文件都是修改列操作之后产生的,才能准确。
原因大致为:这些版本中查询hudi表,读取parquet文件中数据时按顺序和查询schema对应,而非使用parquet文件自身携带的schema去对应

查询rt表如下:
| 操作类型 | 是否支持 | 原因 |
|---|---|---|
| 新增列 | 是 | 按列名查询基础文件和日志文件,文件没有的列返回null |
| 删除列 | 是 | 按列名查询基础文件和日志文件,文件原有列跳过 |
| 改列名 | 否 | 按列名查询不到old_field值,能查询到new_field的值 |
可见查询rt表仍按parquet文件的schema对应,所以没有上述串列问题,等效于 spark2.* 或hoodie.schema.on.read.enable=false 的情况
7. 总结与展望
目前该方案在Spark引擎上支持完整schema演变, 降低生产环境下上游字段变更的处理成本。但该方案还比较粗糙,后续有以下方面可以继续改进
- 多引擎支持: 支持所有引擎的查询比如Hive,Presto,Trino等
- 降低小文件影响:由于历史schema的写入逻辑,如果打开这个功能,一次数据写入,时间轴/.hoodie目录下除了原本要产生的文件外,还要产生/.hoodie/.schema下的3个文件,建议把/.hoodie/.schema下内容写入元数据表中
- 现有表的schema变更提取:4.4中的建议忽略了未打开该功能前的现存表的历史变更(忽略后问题不大)。