Arctic 基于 Hive 的流批一体实践
背景
随着大数据业务的发展,基于 Hive 的数仓体系逐渐难以满足日益增长的业务需求,一方面已有很大体量的用户,但是在实时性,功能性上严重缺失;另一方面 Hudi,Iceberg 这类系统在事务性,快照管理上带来巨大提升,但是对已经存在的 Hive 用户有较大的迁移成本,并且难以满足流式计算毫秒级延迟的需求。为了满足网易内外部客户对于流批一体业务的需求,网易数帆基于 Apache Iceberg 研发了新一代流式湖仓,相较于 Hudi,Iceberg 等传统湖仓,它提供了流式更新,维表 Join,partial upsert 等功能,并且将 Hive,Iceberg,消息队列整合为一套流式湖仓服务,实现了开箱即用的流批一体,能帮助业务平滑地从 Hive 过渡到 Streaming Lakehouse。
Arctic 是什么

Arctic 是搭建在 Apache Iceberg 之上的流式湖仓服务 ( Streaming LakeHouse Service )。相比 Iceberg、Hudi、Delta 等数据湖,Arctic 提供了更加优化的 CDC,流式更新,OLAP 等功能,并且结合了 Iceberg 高效的离线处理能力,Arctic 能服务于更多的流批混用场景。Arctic 还提供了包括结构自优化、并发冲突解决、标准化的湖仓管理功能等,可以有效减少数据湖在管理和优化上负担。
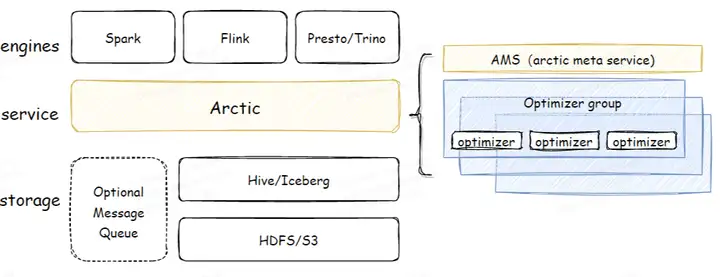
Arctic Table 依赖 Iceberg 作为基础表格式,但是 Arctic 没有倾入 Iceberg 的实现,而是将 Iceberg 做为 lib 使用,同时 Arctic 作为专门为流批一体计算设计的流式湖仓,Arctic Table 还封装了消息队列作为表的一部分,在流式计算场景下可以提供更低的消息延迟,并且提供了流式更新,主键唯一性保证等功能。
流体一批的解决方案
在实时计算中,由于低延迟的要求,业务通常采用 Kafka 这类消息队列作为流表方案,但是在离线计算中,通常采用 Hive 作为离线表,并且由于消息队列不支持 AP 查询,通常还需要额外的 OLAP 系统如 Kudu 以支持实时计算链接的最终数据输出。这就是典型的 Lambda 架构:

这套架构最明显的问题就是多套系统带来的运维成本和重复开发带来的低效率,其次就是两套系统同时建模带来的语义二义性问题,并且真实生产场景中,还会出现实时和离线视图合并的需求,或者引入 KV 的实时维表关联的需求。Arctic 的核心目标之一,就是为业务提供基于数据湖的去 Lambda 化,业务系统使用 Arctic 替代 Kafka 和Hive,实现存储底座的流批一体。

为此 Arctic 提供了以下功能:
- Message Queue 的封装:Arctic 通过将 MessageQueue 和数据湖封装成一张表,实现了 Spark、Flink、Trino 等不同计算引擎访问时不需要区分流表和批表,实现了计算指标上的统一。
- 毫秒级流计算延迟:Message Queue 提供了毫秒级的读延迟,并且提供了数据写入和读取的一致性保障。
- 分钟级的 OLAP 延迟:Arctic 支持流式写入以及流式更新,在查询时通过 Merge on Read 实现分钟级的 OLAP 查询。
Table Store
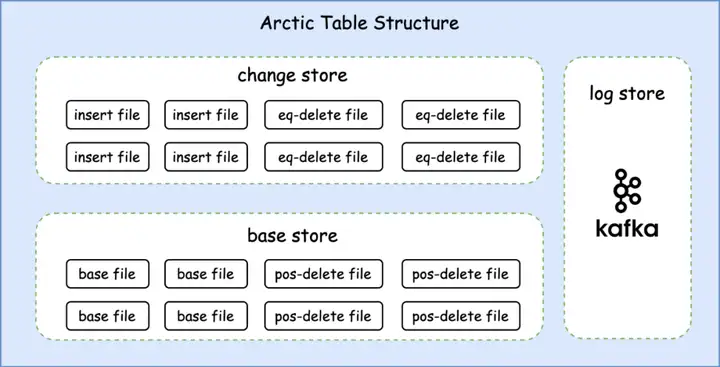
Arctic Table 由不同的 Table Store 组成,TableStore 是 Arctic 在存储系统中定义的表格式实体,Tablestore 类似于数据库中的 cluster index,代表独立的存储结构,目前分为三种 TableStore。
ChangeStore
ChangeStroe 是一张 Iceberg 表,它代表了表上的增量数据,或者说最新的数据变更,通常由 Apache Flink 任务实时写入,并用于下游任务近实时的消费。
BaseStore
BaseStore 也是张 Iceberg 表,它代表了表上的存量数据。通常来自批计算的全量初始化,或者通过Optimizer 定时将来自 ChangeStore 的数据合并入 BaseStore。在对Arctic 表执行查询时, BaseStore 的数据会联合 ChangeStore 的数据一起通过Merge-On-Read 返回。
LogStore
尽管 Changestore 已经能够为表提供近实时的 CDC 能力,但在对延迟有更高要求的场景仍然需要诸如 Apache Kafka 这样的消息队列提供毫秒级的 CDC 数据分发能力。而消息队列在 Arctic 表中被封装为 Logstore。它由 Flink 任务实时写入,并用于下游 Flink 任务进行实时消费。
Arctic 对 Hive 的兼容
在真实业务实践中,Hive 有着非常庞大的存量用户以及围绕其构建的中台体系,要想一步直接完成从 Hive 到湖仓系统的转换难度非常大,因此如何利用已有的 Hive 生态是 Arctic 实现流批一体首先需要解决的问题。为此 Arctic 提供了 Hive 兼容的能力,以帮助 Hive 用户可以平滑的迁移到流式数仓中。具体到细节,Arctic 提供了以下 Hive 兼容能力:
- 数据访问层面的兼容:Arctic 与 Hive原生的读写方式保持兼容,即通过 Arctic 写入的数据,Hive 可以读;Hive 写入的数据,Arctic 可以读。
- 元数据层面的兼容:Arctic 表可以在 HMS 上注册并管理,用户直接对 Hive 表执行 DDL 可以被 Arctic 感知到。
- Hive 生态的兼容:Arctic 表可以复用目前围绕 Hive 的生态,比如可以直接通过 ranger 对 Hive 进行权限管理的方式对 Arctic 表进行授权。
- 存量 Hive 表的兼容:海量的存量 Hive 表,如果有实时化的需求,可以以很低的代价将 Hive 表升级为 Arctic 表。
Hive 兼容的 Table Store
解决 Hive 兼容的首要问题是需要解决 Hive 和 Arctic 文件分布上的不同,在 Arctic 表中被分为 ChangeStore、BaseStore、LogStore 三个不同的 Table Store,从定义上,BaseStore 代表着表的存量数据,这与 Hive 的离线数仓定位是一致的,但是在实现上,Arctic 并未直接将 BaseStore 替换为 Hive Table , 而是仍然保留 Iceberg Table 作为 BaseStore 的实现以提供 ACID 等特性,并通过目录划分的方式,划分出对 Hive 兼容的目录空间,具体结构如下图所示:
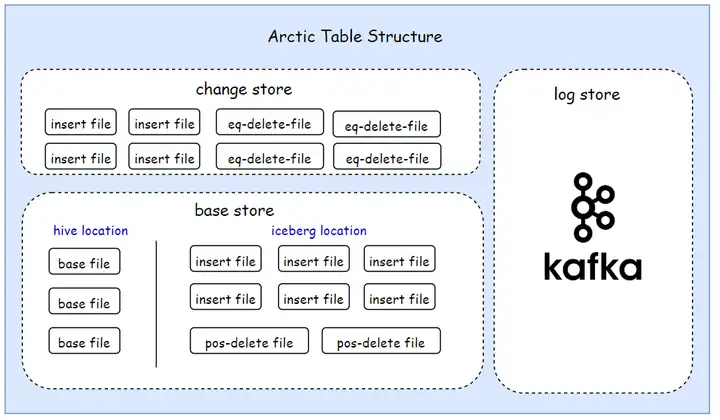
重点我们关注 Basestore 下的结构,其中区分了两个目录空间:
- hive location: Hive 表(或分区)的目录空间,会记录在 Hive Meta Store 中,用原生的 Hive reader 会读到这部分数据。
- iceberg location: 存储近实时写入数据的目录空间,用 Iceberg 管理,包含 insert file 与 delete file,原生的 Hive reader 无法读取到其中的数据, Arctic reader 能读取到。
两个目录空间的设计保障了支持 Arctic 完整特性的基础之上仍然兼容 Hive 原生读取。
Hive 数据同步
Hive location 的划分实现了 Arctic 写入数据对 Hive 查询引擎读的兼容,但是通过 Hive 查询引擎写入的数据或者 schema 变更却无法让 Arctic 立即识别,为此 Arctic 引入了 Hive Syncer 用于识别通过 Hive 查询引擎对表结构和数据的变更。Hive Syncer 包括 2 个目标:
- Hive 表结构变更同步到 Arctic
- Hive 表数据变更同步到 Arctic
_Table Metadata Sync_Hive
表结构信息的同步是通过对比 Arctic Table Schema 和 Hive Table Schema 的差异实现的,由于对比代价较小,Arctic 采取的方式是在所有的读取/写入/schema 查询/变更 执行前都会执行 Metadata Sync 操作。通过对 Schema 的对比,Arctic 可以自动识别在 Hive 表上的 DDL 变更。Hive Schema 的同步能力使得 Arctic 的数据开发可以继续复用Hive生态下的数据建模工具,数据开发只需要如同对 Hive 表建模一样即可完成对 Arctic 表的建模。
_Table Data Sync_Hive
表数据的变更的检查是通过分区下的 transient_lastDdlTime 字段识别的,读取 Hive 分区下数据时会对比分区的修改时间是否和 Arctic 的 metadata 中记载是否一致,如果不一致就通过 HDFS 的 listDir 接口获取分区下的全部文件,并对比 Arctic 表最新 snapshot 对应的文件,如果文件列表有差异,说明有通过非 Arctic 的途径对 Hive 表的数据进行了修改,此时 Arctic 会生成一个新的快照,对 Arctic 表的文件信息进行修正。由于 HDFS 的 listDir 操作是一个比较重的操作,默认情况下是通过 AMS 定时触发 DataSync 检查,如果对数据一致性要求更高,可以通过参数 base.hive.auto-sync-data-write 配置为每次查询前进行 Data Sync 检查。Hive 数据同步的能力使得用户从离线开发链路迁移到实时开发链接的过程中保留离线数据开发的逻辑,通过离线完成对实时的数据修正,并且保证了实时和离线建模的统一以及指标的统一。
存量 Hive 表原地升级
Arctic 不仅支持创建 Hive 兼容表,还支持直接将已经存在的 Hive 表升级为一张 Arctic 下的 Hive 兼容表。在 AMS 上导入 HMS 对应的 hive-site.xml 即可看到 HMS 上对应的表,在对应的 Hive 表上点击 Upgrade 按钮即可对 Hive 表进行原地升级。
Arctic 还支持在进行原地升级时指定主键,这样可以将 Hive 表升级为有主键的 Arctic 表。
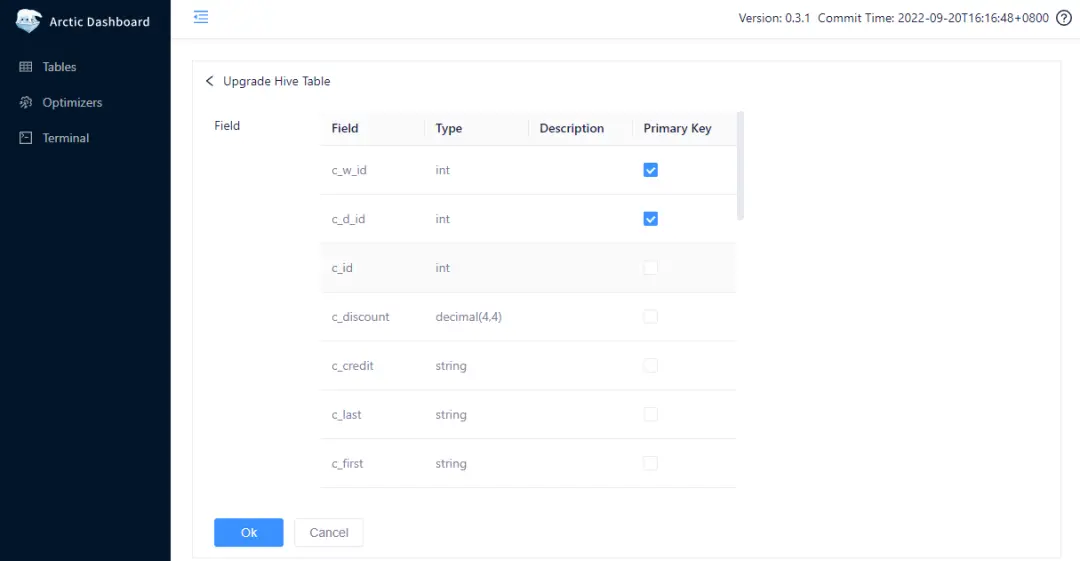
Hive 的原地升级操作是非常轻量级的,在执行 Upgrade 操作的背后,AMS 仅仅是新建一个空的 Arctic Table,然后扫描 Hive 目录,并创建一个包括所有 Hive 下的 Parquet 文件的 Snapshot 即可,整个过程并不涉及到数据文件的复制和重写。
兼容 Hive 表的权限管理
围绕着 Hive 已经有了一套完整的大数据生态,其中对于表的权限管理和数据脱敏极为重要,当前 Arctic的 Hive 兼容表已经适配了 incubator-kyuubi 项目下的 spark-auth 插件 //github.com/apache/incubator-kyuubi 通过该插件 Arctic 完成了对 Ranger 的适配,在实际应用中,通过 Ranger 对 Arctic 对应的 Hive 进行授权,在 SparkJob 中即可完成对 Arctic 表的鉴权。
基于Hive 的流批一体实践
Arctic 的 Hive 兼容模式是为了帮助适应了 Hive 的用户快速上手 Arctic,对于 Hive 用户来说,如果满足以下其中一点:
1. 有大量的存量 Hive 表,并且其中部分 Hive 表有流式写入、订阅的需求
2. 在离线场景下有成熟的产品构建,并且希望为离线赋予部分实时的能力,但是又不想对离线平台做过多的改造
即可尝试通过 Arctic Hive 兼容表解决你的痛点。
实践案例:网易云音乐特征生产工程实时化
网易云音乐的推荐业务围绕着 Spark+Hive 已经构建了一套成熟的大数据+AI 开发体系,随着业务的增长,业务对整套系统的实时性要求在不断增强,但是直接通过 Flink + Kafka 构建的实时链路并不够完善。在离线链路中围绕着 Hive 有着完善的基础设施和方法论,数据开发和算法工程师通过模型设计中心完成表的设计,数据开发负责数据的摄取,清洗,打宽,聚合等基础处理,算法工程师负责在 DWS 层的数据上实现特征生产算法,分析师通过对 ODS 层、DWD 层以及 DWS 层的表执行 Ad Hoc 式的查询并构建分析报表以评估特征数据质量。整套链路层次分明、分工清晰,即最大限度的复用了计算结果,又比较好的统一了指标口径,是典型的 T+1 的数仓建设。但是在实时链路中,数据开发仅仅协助完成原始数据到 Kafka 的摄取,算法工程师需要从 ODS 层数据进行加工,整个链路缺乏数据分层,既不能复用离线计算结果,也无法保证指标的一致性。
整个特征工程的生产路线的现状如下图所示:
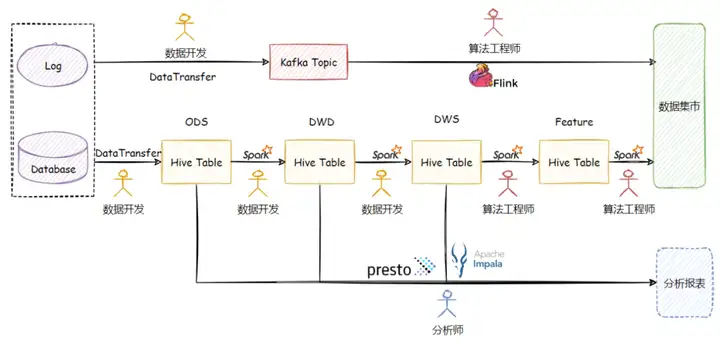
由于存在大量的存量 Hive 表,并且还有来自 Presto 和 Impala 的查询链路需要复用 ODS 和 DWD 层的 Hive 表,整个特征工程想直接使用 Iceberg 或 Hudi 这样的系统其切换代价还是很大的,系统切换期间对系统整体 SLA 要求较高,新系统磨合过程中如果造成数据产出延迟,对于业务来说是不可接受的。最终我们采用了 Arctic Hive 兼容表的模式, 分阶段的将 Hive 表升级为 Arctic 下的 Hive 兼容表,升级后的数据生产链路如下图所示:
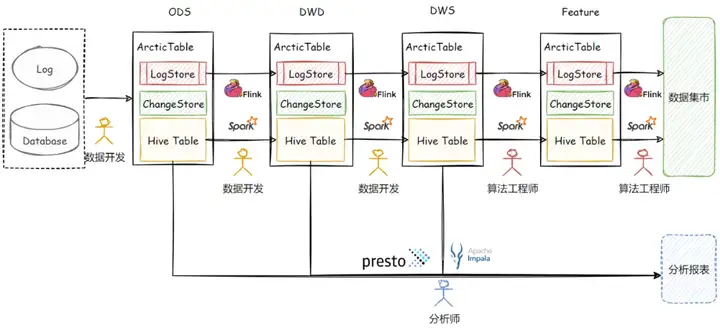
升级后Arctic 为整个特征工程带来了以下好处:
1. Arctic 以无感知的方式完成了约 2PB 级别的 Hive 表实时化,由于做到 Hive 的读写兼容,本身 T+1 的全量数据回补以及分析师的报表查询 SQL 不用做任何修改,升级过程中保证了不影响离线链路开发。
2. 实时特征的生产复用了数仓 DWS 层数据,不需要从 ODS 层直接构建特征算法,而数仓的清洗、聚合均由数据开发完成,提升了算法工程师的人效,使得算法工程师可以更好的专注于特征算法本身。平均下来每个算法节省人效约 1 天。
3. 完成了实时链路和离线链路的统一,在数据血缘,数据指标,模型设计上可以做到更好的数据治理。
4. Arctic 本身可以为 ODS 和 DWD 层的表配置更激进的 Optimize 策略,以 10 分钟的频率对 Hive Table 的数据进行 Overwrite, 分析师可以享受到更加实时的分析报表。
总结
本文介绍了网易数帆开源的新一代流式湖仓 Arctic 以及其基于 Hive 的流批一体实践。希望读者可以经此文章了解 Arctic 并对业务构建流批一体的数据湖有帮助。感谢一直一来对 Arctic 社区的支持,如果您对 Arctic 、湖仓一体、流批一体感兴趣,并想一起推动它的发展,请在 Github 上关注 Arctic 项目//github.com/NetEase/arctic。也欢迎加入 Arctic 交流群:微信添加“kllnn999”为好友,注明“Arctic 交流”。
了解更多
作者简介:
张永翔,网易数帆资深平台开发工程师,Arctic Committer,6 年从业经验,先后从事网易 RDS、数据中台、实时计算平台等开发,目前主要负责 Arctic 流式湖仓服务开发。
胡溢胜,网易云音乐数据专家,10 年数仓经验,涉及通信、互联网、环保、医疗等行业。2020 年加入网易云音乐,目前负责网易云音乐社交直播业务线的数据建设。

