【论文翻译】KLMo: Knowledge Graph Enhanced Pretrained Language Model with Fine-Grained Relationships
KLMo:建模细粒度关系的知识图增强预训练语言模型
(KLMo: Knowledge Graph Enhanced Pretrained Language Model with Fine-Grained Relationships)
- 摘要
知识图谱(KG)中实体之间的交互作用为语言表征学习提供了丰富的知识。然而,现有的知识增强型预训练语言模型(PLMS)只关注实体信息,而忽略了实体之间的细粒度关系。在这项工作中,我们建议将KG(包括实体和关系)纳入语言学习过程中,以获得KG增强的预训练语言模型,即KLMo。具体来说,设计了一种新的知识聚合器来显式建模文本中的实体片段(entity span)和上下文KG中的所有实体和关系之间的交互。利用一个关系预测目标,通过远程监督来合并关系信息。进一步利用链接目标的实体来将文本中的实体跨链接到KG中的实体。这样,结构化的知识就可以有效地集成到语言表示形式中。实验结果表明,与最先进的知识增强型PLMs相比,KLMo在实体类型和关系分类等知识驱动任务上取得了很大的进步。
- 01引言
带有实体和关系的知识图(KG)为语言学习提供了丰富的知识(Wang et al.,2017,2014)。最近,研究人员探索了将KG信息纳入PLMs中来增强语言表征,比如ERNIE-THU (Zhang et al., 2019), WKLM (Xiong et al.,2019) , KEPLER (Wang et al., 2019), KnowBERT (Peters et al., 2019), BERT-MK (He et al., 2019) and KALM (Rosset et al., 2020), .但是,它们只利用实体信息,而忽略了实体之间的细粒度关系。实体间关系的细粒度语义信息对语言表示学习也是至关重要的。
2001年,郎朗参加了BBC的毕业舞会,但他在中国直到2012年在《幸福三重奏》中亮相才很受欢迎。
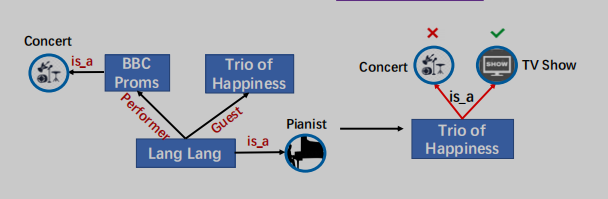
图1:将知识合并到PLMs中的一个示例。KG中的关系对于正确预测Trio of Happiness的类型至关重要。
以图1为例,实体类型,没有明确地知道细粒度Lang Lang和Trio of Happiness的关系是客人(Guest),这是不同于关系表演者(Performer)LangLang和BBC Proms,不可能正确预测Trio of Happiness作为电视节目的类型,因为输入句子字面上意味着Trio of Happiness和BBC Proms属于同一类型。KG中实体之间的细粒度关系为实体提供了特定的约束,从而在知识驱动任务的语言学习中发挥重要作用。为了明确地将KG中的实体和细粒度关系合并到PLMs中,我们面临的一个主要挑战是文本-知识对齐(TKA)问题:很难为文本和知识的融合进行token-关系和token-实体对齐。为了解决这个问题,我们提出了KG增强的预训练语言模型(KLMo)来将KG(即实体和细粒度关系)集成到语言表示学习中。KLMo的主要组件是一个知识聚合器,它负责从两个单独的嵌入空间即token嵌入空间和KG嵌入空间,进行文本和知识信息的融合。知识聚合器通过实体片段级的交叉KG注意力机制,建模文本中实体片段和所有实体和关系之间的交互,使tokens注意KG中高度相关的实体和关系。基于KG增强的token表示,利用关系预测目标,基于KG的远程监督,预测文本中每对实体的关系。关系预测和实体链接目标是将KG信息集成到文本表示中的关键。
我们在两个中国知识驱动的自然语言处理任务上进行了实验,即实体类型和关系分类。实验结果表明,通过充分利用包含实体和细粒度关系的结构化KG,KLMo比BERT和现有的知识增强PLMs有了很大的改进。我们还将发布一个中国的实体类型数据集,用于评估中国的PLMs。
- 02模型描述
如图2所示,KLMo被设计为一个基于多层Transformer的(Vaswani et al.,2017)模型,该模型接受一个token序列及其上下文KG中的实体和关系作为输入。文本(token)序列首先由一个基于多层Transformer的文本编码器进行编码。文本编码器的输出进一步被用作知识聚合器的输入,该知识聚合器将实体和关系的知识融入到文本(token)序列中,以获得KG增强的token表示。基于KG增强表示,将新的关系预测和实体链接目标联合优化为预训练目标,有助于将KG中的高度相关的实体和关系信息合并到文本表示中。
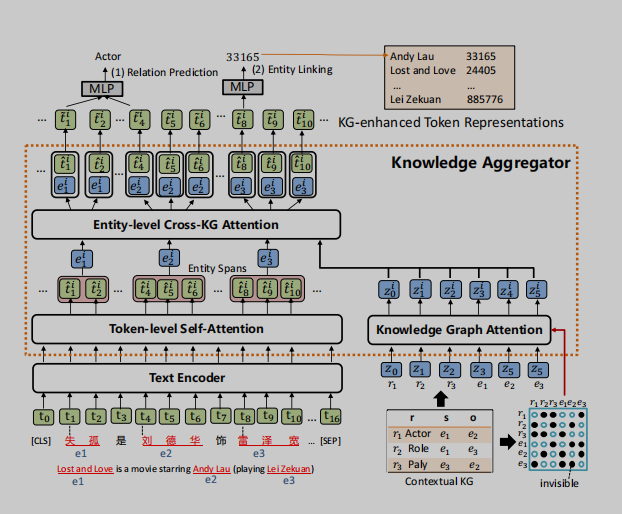
图2:模型体系结构的概述。
2.1知识聚合器
如图2所示,知识聚合器被设计为一个M层知识编码器,将KG中的知识集成到语言表示学习中。它接受token序列的隐藏层和KG中实体和关系的知识嵌入作为输入,并融合来自两个单独嵌入空间的文本和KG信息。它接受token序列的隐藏层和KG中实体和关系的知识嵌入作为输入,并融合来自两个单独嵌入空间的文本和KG信息。知识聚合器包含两个独立的多头注意力机制:token级自注意力和知识图谱注意力(Veliˇckovi‘cetal.,2017),它对输入文本和KG进行独立编码。实体表示是通过汇集一个实体片段中的所有token来计算的。然后,聚合器通过实体级的交叉KG注意力,将文本中的实体片段与上下文KG中的所有实体和关系之间的交互进行建模,从而将知识融入到文本表示中。
Knowledge Graph Attention (知识图谱注意力机制)
由于KG中的实体和关系组成了一个图,因此在知识表示学习过程中考虑图的结构是至关重要的。我们首先通过TransE(Bordes et al.,2013)表示上下文KG中的实体和关系,然后将它们转化为一个实体和关系向量序列{z0,z1,…,zq},作为知识聚合器的输入。然后,知识聚合器通过知识图谱注意力对实体和关系序列进行编码,知识图谱注意力通过将可见矩阵M引入传统的自注意机制来考虑其图结构(Liu et al.,2020)。可见矩阵M只允许在表示学习过程中,KG中的相邻实体和关系彼此可见,如图2的右下角所示。
Entity-level Cross-KG Attention(实体级别交叉KG注意力机制)
为了计算KG增强实体表示,给定一个实体提及列表(entity mention list )Ce = {(e0,start0,end0),…,(em,start m,end m)},知识聚合器首先计算实体片段表示{eˆi0…,eˆim},通过在文本中实体范围内的所有tokens上pooling计算得到文本中实体片段表示(Lee et al.,2017)。实体片段嵌入{eˆi0,…,eˆim}可以扩展到所有标记{eˆi0,…,eˆin},方法是为不属于任何实体片段的token创建eˆij=tˆij,其中tˆij表示来自的第j个标记的表示token-level的自注意力。
为了对文本中的实体跨度与上下文KG中的所有实体和关系之间的交互进行建模,聚合器执行一个实体级的交叉KG注意力,让token关注KG中高度相关的实体和关系,从而计算KG增强的实体表示。具体来说,第i个聚合器中的实体级交叉KG注意力是通过实体片段嵌入{eˆi0,…,eˆin}作为query和实体和关系嵌入{zi0,…,ziq}作为key和value之间的上下文多头注意力机制来实现的。(将文本中的实体片段表示作为query,将KG中的实体和关系表示作为key和value,进行注意力计算,从而得到知识增强的实体表示)
KG-enhanced Token Representations (知识增强文本表示)
为了将KG增强的实体信息注入到文本表示中,知识聚合器的第i层通过采用{tˆi0,…,tˆin}和{ei0…,…,eni}之间的信息融合操作来计算KG增强的token表征{ti0,…,tin}。对于第j个token,融合操作的定义如下:
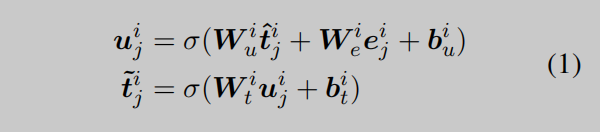
其中,uij表示集成来自token和实体信息的隐蔽态。Wi∗和bi∗分别是可学习的权重和偏差。KG增强的token表示{t˜i0,…,tin˜˜}作为输入被输入到下一层知识聚合器中。
2.2预训练目标
为了将KG知识纳入语言表征学习中,KLMo采用了多任务损失函数作为训练目标:
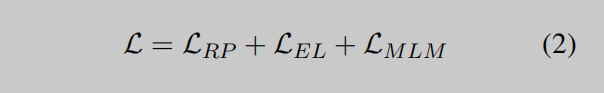
除了掩码语言模型的损失LMLM (Devlin et al., 2018; Li et al., 2020),基于相应的KG增强文本表示{t˜M0,…,t˜Mn},整合关系预测损失LRP和实体链接损失LEL来预测KG中的实体。
对于每一对实体片段,我们利用它们在KG中对应实体之间的关系作为关系预测的远距离监督。关系预测和实体链接目标是将KG中的关系和实体整合到文本中的关键。由于在实体链接目标中的Softmax操作在KG中的实体数量相当大,我们通过只预测同一批中的实体而不是KG中的所有实体来处理这个问题。为了防止KLMo在预测而不是依赖于文本上下文时完全记住实体的提到,我们在输入文本中使用一个特殊的[MASK]token随机屏蔽了10%的实体。
03实验
本节详细介绍KLMo预训练及其对两个特定知识驱动的NLP任务的微调:实体类型和关系分类。我们通过百度百科的中文语料库和百度百科的知识图谱的中文语料库对KLMo进行预训练。训练前语料库和实验设置的细节见附录A。
3.1Baselines
我们将KLMo与在同一百度百科语料库上预训练的最先进的PLMs进行了比较:(1)BERT-Base Chinese (Devlin et al., 2018),在百度百科语料库进行一轮预训练(2)ERNIE-THU (Zhang et al., 2019),这是该领域的开创性和典型工作,将实体知识纳入PLM。(3)WKLM (Xiong et al., 2019),一个弱监督的知识增强PLM,使用实体替换预测来合并实体知识,它提供了几个知识驱动任务的最先进的结果。
3.2实体类型
数据集 在这项工作中,我们创建了一个中文实体类型数据集,这是一个完全手动的数据集,包含23100个句子和28093个注释实体,分布在15个细粒度的媒体作品类别,如电影、节目和电视剧。我们将数据集分成一个有15000个句子的训练集和一个有8100个句子的测试集。数据集的详细统计数据和微调设置显示在附录B.1中。
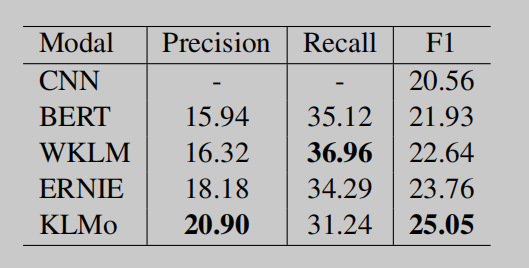
表2:关于关系分类的结果。

表3:实体类型的消融研究。
结果 我们在准确率、召回率、微f1和精度指标下评估了实体类型的各种预训练模型。结果如表1所示。我们可以找到以下的观察结果:(1)所有知识增强的PLMs在所有度量上的表现通常都比BERT baseline好得多,这表明实体知识在注释资源有限的情况下有利于实体类型的预测。(2)与现有的知识增强PLMs相比,KLMo比WKLM和ERNIE极大地提高了召回率,对micro-F1分别提高了1.58和0.57。这表明,实体之间的细粒度关系有助于KLMo为更多的实体预测适当的类别。
3.3关系分类
数据集 The CCKS 2019 Task 3 Inter-Personal Relational Extraction (IPRE) dataset (Han et al., 2020) 用于关系分类的评估。训练集通过远程监督自动标记,测试集被手动标注。有35个关系(包括一个空关系类“NA”),其中“NA”在训练集中占近86%,在测试集中占97%。数据集的详细统计数据和微调设置见附录B.2。
结果 我们采用准确率、召回率和microF1作为评价措施。结果如表2所示。除了BERT baseline外,我们还将KLMo与官方的CNN baseline进行了比较,该baseline将CNN输出作为句子嵌入,并将其输入关系分类器。从表2中可以看出,CNN和BERT baseline模型都表现不佳,这表明数据集的难度很高。这是由于在由远程监督自动产生的训练集中有大量的噪声标签。
虽然数据集非常困难,但我们仍然可以观察到:(1)所有知识增强的PLMs都大大提高了准确率和microF1分数,这表明实体信息和KG信息都可以增强语言表示,从而促进关系分类的性能。(2) KLMo对WKLM和ERNIE的准确率显著提高,对micro-F1分别提高了2.41和1.29,说明KG中的细粒度关系有助于KLMo避免对噪声标签的拟合,并正确预测关系
3.4 KG信息的影响
大多数NLP任务只提供文本输入,而实体链接本身是一项艰巨的任务。因此,我们研究了KG实体的影响和关系对实体类型的影响。w/o KG是指在不输入KG实体和关系的情况下对KLMo进行微调。表3为消融实验研究的结果。在没有KG输入进行微调的情况下,KLMo在准确率和召回率得分上仍大大优于BERT,从而在micro-F1上提高了1.74。与使用KG的KLMo微调相比,没有KG的KLMo在microf1测量上略有下降了0.84。这表明KG信息在训练前已经被集成到KLMo中。对于大多数特定的NLP任务,KLMo可以以类似于BERT的方式进行微调。
04结论
在本文中,我们提出了一种新的KG增强的预训练语言模型KLMo,明确地将KG实体和细粒度关系集成到语言表征学习中。因此,设计了一种新的知识聚合器来处理异构信息融合和文本知识对齐问题。进一步,联合优化了关系预测和实体链接目标,以促进知识信息集成。实验结果表明,KLMo的性能优于其他最先进的知识增强的PLMs,这验证了KG中的细粒度关系可以增强语言表示学习,并有利于一些知识驱动的NLP任务。
A Pre-training Settings
A.1 Pretraining Corpus
Baike Knowledge Graph
百科知识库是一个通用领域的中国知识库,它包含226种概念类型、超过1亿个实体和22亿个三元组。百度知识库中的每个实体都与各种来源的网页对齐,如百度百科度、搜狗百科和双重媒体。为了预训练一个KG增强的中文模型,我们提取了该知识库的一个子集,使用以下规则构建一个百科KG:1)删除百度百科文章以外的实体;2)删除低流行实体(小于200);3)仅保留两个实体都是百度百科实体的事实三元组。最终的百科KG包含2466069个实体,390个关系和9859314个三倍。
中国训练前语料库 KLMo主要采用百度百科的网页进行预训练,其中包含用正式中文编写的百科全书文章。文章中的实体可以通过锚定链接提取,并与百科 KG实体对齐。对语料库进行预处理后,生成一个包含78B个标记、1.74亿个句子、2100万个实体和120万个关系的大格式数据集,用于KLMo的预训练。具有少于5个单词或2个实体的句子将被丢弃。
A.2实施细节
在实验中,我们首先使用OpenKE工具包(Han等人,2018),获得了通过TransE(Bordes等人,2013)算法在百科KG三元组上训练的知识表示。这些表示法用于初始化KLMo中的实体和关系嵌入。嵌入维数设置为100,轮数设置为5000。
对于KLMo的预训练,由于预训练代价昂贵,我们继承BERT-Base中文参数来初始化token编码,而实体和关系编码模块的参数都是随机初始化的。文本编码器层L和知识聚合器层M均为6个。token嵌入dt、知识嵌入dz和实体跨度嵌入de的隐藏大小分别设置为768、100和100。标记导向注意头At、kg导向注意头Az和实体跨级注意头Ae的数量分别设置为12、4和12。KLMo的预训练在4个NVIDIA TeslaV100(32GB)gpu上运行3个时代,批量大小为128,最大序列长度为512,学习速率为5e-5。

表4:中国实体分类数据集的统计数据。

表5:中国关系分类数据集的统计数据。
B微调设置
B.1实体类型化
为了评估KLMo的性能,本文执行了两个知识驱动的任务,即实体类型和关系分类。给定一个提到实体的句子,实体输入任务是用其细粒度的语义类型来标记提及。
数据集 实体类型并不是一个新的任务。然而,据我们所知,目前还没有关于中文细粒度实体类型的公开基准数据集。因此,在这项工作中,我们创建了一个中文实体类型数据集,这是一个完全手动注释的数据集,包含23100个句子和28093个注释实体,分布在15个细粒度的媒体作品类别,如电影、节目和电视剧。我们将数据集分成一个有15000个句子的训练集和一个有8100个句子的测试集。数据集的详细统计数据如表4所示。
微调
中文实体类型数据集缺乏KG实体注释,因此我们首先使用带有百科知识库的实体链接工具来识别句子中提到的实体,并将其链接到相应的百科KG实体。链接的实体类型数据集的统计数据如表4所示。超过50%的句子在训练集和测试集中都包含至少一个链接的KG实体。为了为实体类型的KLMo,我们使用每个实体跨度的第一个标记的表示来预测其实体类型。该模型在训练集上细化了10轮,批处理大小为128,最大序列长度为256,学习速率为2e-5。


