【一月一本技术书】-【Go语言设计与实现】- 9月
- 2022 年 9 月 19 日
- 筆記
Go : 2009.11.10
代表作:Docker、k8s、etcd
模仿C语言,目标:互联网的C语言

讲的晦涩难懂。。。。硬板。。放弃了好几次才读完。满分10分,打6分。
下个月:Python数据结构与算法分析吧。需要算法刷题了。
四大:编译原理、基础知识、运行时、进阶知识
编译原理
编译过程
抽象语法树 Abstract Syntax Tree\ AST\ 是源代码语法的结构的一种抽象表示。
用树状的方式表示编程语言的语法结构。每一个节点表示源代码的一个元素。每一颗子树表示一个语法元素。
2 * 3 + 7

抽象语法树抹去了源代码中不重要的一些字符:空格、分号、括号等
静态单赋值Static Single Assignment\SSA 是中间代码的特性。
每个变量只会被赋值一次。 优化
x := 1 # 无效
x := 2 # 有效
y := x
x_1 := 1 # 无效,编译后,没有这个玩意了
x_2 := 2
y_1 := x_2
指令集
- 复杂指令集 CISC: 通过增加指令的类型减少需要执行的指令数
- 精简指令集 RISC: 使用更少的指令类型完成目标计算任务
编译原理
编译器代码:src/cmd/compile目录中
编译器分为 前端和后端
- 前端: 词法分析、语法分析、类型检查、中间代码生成
- 后端: 目标代码的生成、优化;将中间代码翻译成目标机器能够运行的二进制机器码
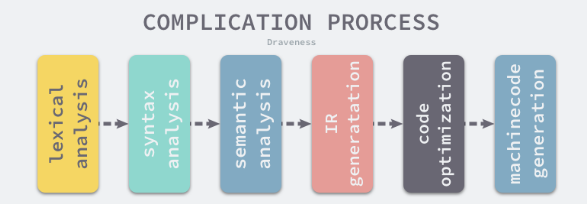

四个阶段:词法和语法分析、类型检查和AST转换、通用SSA生成、机器代码生成
- 词法和语法分析
解析源代码文件开始,词法分析的作用就是解析源代码文件。将字符串序列转换成Token序列。方便后面的处理和解析。
执行词法分析的程序称为 词法解析器 lexer
语法分析的输入是词法分析器输出的Token序列。根据编程语言定义好的文法 Grammar分析Token序列。
每一个go的源代码文件最终会被归纳成一个SourceFile结构。
SourceFile = PackageClause ";" { ImportDecl ";" } { TopLevelDecl ";" } .
词法分析器会返回一个不包含空格、换行等字符的Token序列。 package,json,import,(,io,)…
语法分析器会把Token序列转换成有意义的结构体—语法树,AST.
"json.go": SourceFile {
PackageName: "json",
ImportDecl: []Import{
"io",
},
TopLevelDecl: ...
}
一个源文件对应着一个AST. 包含:包名、定义的常量、结构体和函数。
GO使用的语法解析器是LALR(1)的文法。

语法解析的过程中发生的任何语法错误都会被语法解析器发现并打印到标准输出上。
- 类型检查
AST生成之后。编译器会对语法树中定义和使用的类型进行检查。
- 常量、类型和函数名及类型
- 变量的赋值和初始化
- 函数和闭包的主体
- 哈希键值对的类型
- 导入函数体
- 外部的声明
遍历整颗抽象语法树,保证节点不存在类型错误,
-
中间代码生成
类型检查之后就不存在语法错误了,编译器就会将AST转换成中间代码
会使用gc.compileFunctions编译整个Go语言项目中的全部函数。并发编译
-
机器码生成
不同类型的CPU分别使用不同的包生成机器码,amd64、arm、arm64、mips、mips64、ppc64、s390x、x86、wasm.

Go语言的编译器能够生成Wasm WebAssembly 格式的指令,就可以运行在常见的主流浏览器中。

编译器入口
src/cmd/complie/internal/gc/main.go。
抽象语法树会经历类型检查、SSA 中间代码生成以及机器码生成三个阶段
检查常量、类型和函数的类型;
处理变量的赋值;
对函数的主体进行类型检查;
决定如何捕获变量;
检查内联函数的类型;
进行逃逸分析;
将闭包的主体转换成引用的捕获变量;
编译顶层函数;
检查外部依赖的声明
词法分析和语法分析
源代码对于计算机来说是无法被理解的字符串。
第一步:将字符串分组。如下分为 make、 chan、 int 和 括号
make(chan int)
词法分析是将字符序列转换为标记(token)序列的过程。
- lex
lex是用于生成词法分析器的工具。
lex生成的代码能够将一个文件中的字符分解成Token序列。
lex就是一个正则匹配的生成器。
lex文件示例:
%{
#include <stdio.h>
%}
%%
package printf("PACKAGE "); # 解析package
import printf("IMPORT "); # 解析 import
\. printf("DOT "); # 解析点
\{ printf("LBRACE ");
\} printf("RBRACE ");
\( printf("LPAREN ");
\) printf("RPAREN ");
\" printf("QUOTE ");
\n printf("\n");
[0-9]+ printf("NUMBER ");
[a-zA-Z_]+ printf("IDENT ");
%%
这个lex文件就可以解析下面这段代码
package main
import (
"fmt"
)
func main() {
fmt.Println("Hello")
}
.l结尾的lex代码并不能直接运行,通过lex命令将上面的.l展开成C语音代码。
$ lex simplego.l
$ cat lex.yy.c
...
int yylex (void) {
...
while ( 1 ) {
...
yy_match:
do {
register YY_CHAR yy_c = yy_ec[YY_SC_TO_UI(*yy_cp)];
if ( yy_accept[yy_current_state] ) {
(yy_last_accepting_state) = yy_current_state;
(yy_last_accepting_cpos) = yy_cp;
}
while ( yy_chk[yy_base[yy_current_state] + yy_c] != yy_current_state ) {
yy_current_state = (int) yy_def[yy_current_state];
if ( yy_current_state >= 30 )
yy_c = yy_meta[(unsigned int) yy_c];
}
yy_current_state = yy_nxt[yy_base[yy_current_state] + (unsigned int) yy_c];
++yy_cp;
} while ( yy_base[yy_current_state] != 37 );
...
do_action:
switch ( yy_act )
case 0:
...
case 1:
YY_RULE_SETUP
printf("PACKAGE ");
YY_BREAK
...
}
lex.yy.c的前600行基本是宏和函数的声明和定义。后面的代码大都是yylex这个函数服务的。
这个函数使用有限自动机 Deterministic Finite Automaton\DFA.的程序结构来分析输入的字符流。
lex.yy.c编译成二进制可执行文件,就是词法分析器。
把GO语言代码作为输入传递到词法分析器中。会生成如下内容。
$ cc lex.yy.c -o simplego -ll
$ cat main.go | ./simplego
PACKAGE IDENT
IMPORT LPAREN
QUOTE IDENT QUOTE
RPAREN
IDENT IDENT LPAREN RPAREN LBRACE
IDENT DOT IDENT LPAREN QUOTE IDENT QUOTE RPAREN
RBRACE
lex生成的词法分析器lexer通过正则匹配的方式将机器原本很难理解的字符串分解成很多的Token. 有利于后面的处理。
从.l文件到二进制如下。

GO语言的词法解析是通过scanner.go文件中的syntax.scanner结构体实现的。
type scanner struct {
source
mode uint
nlsemi bool
// current token, valid after calling next()
line, col uint
blank bool // line is blank up to col
tok token
lit string // valid if tok is _Name, _Literal, or _Semi ("semicolon", "newline", or "EOF"); may be malformed if bad is true
bad bool // valid if tok is _Literal, true if a syntax error occurred, lit may be malformed
kind LitKind // valid if tok is _Literal
op Operator // valid if tok is _Operator, _AssignOp, or _IncOp
prec int // valid if tok is _Operator, _AssignOp, or _IncOp
}
tokens.go定义了go语言中支持的全部Token类。
例如操作符、括号和关键字等。
const (
_ token = iota
_EOF // EOF
// operators and operations
_Operator // op
...
// delimiters
_Lparen // (
_Lbrack // [
...
// keywords
_Break // break
...
_Type // type
_Var // var
tokenCount //
)
语言中的元素分成几个不同的类型,分别是名称和字面量、操作符、分割符、关键字。
语法分析
根据某种特定的形式文法Grammar.对Token序列构成的输入文本进行分析并确定其语法结构的过程。
- 文法
上下文无关文法 是用来形式化、精确描述某种编程语言的工具。
通过文法定义一种语言的语法。包含一系列用于转换字符串的生产规则 Production Rule.
上下文无关文法中的每一个生产规则 都会将 规则左侧的非终结符 转换成 右侧的字符串。
终结符是文法中无法再被展开的符号。比如: ‘id’、 123
文法都由以下四个部分组成
- N 有限个非终结符的集合。
2)Σ 有限个终结符的集合
3)P 有限个生产规则12的集合;
4)S 非终结符集合中唯一的开始符号;
文法被定义成一个四元组 (N,Σ,P,S)
S→aSb
S→ab
S→ϵ
上述规则构成的文法就能够表示 ab、aabb 以及 aaa..bbb 等字符串,编程语言的文法就是由这一系列的生产规则表示的
SourceFile = PackageClause ";" { ImportDecl ";" } { TopLevelDecl ";" } .
PackageClause = "package" PackageName .
PackageName = identifier .
ImportDecl = "import" ( ImportSpec | "(" { ImportSpec ";" } ")" ) .
ImportSpec = [ "." | PackageName ] ImportPath .
ImportPath = string_lit .
TopLevelDecl = Declaration | FunctionDecl | MethodDecl .
Declaration = ConstDecl | TypeDecl | VarDecl .
每个Go语言代码文件最终都会被解析成一个独立的抽象语法树。所以语法树最顶层的结构或者开始符号都是SourceFile:
SourceFile = PackageClause ";" { ImportDecl ";" } { TopLevelDecl ";" } .
每一个文件都包含一个package的定义 以及可选的 import。 和 其他的顶层声明 TopLevelDecl。
每一个sourceFile在编译器中都对应一个syntax.File结构体
type File struct {
Pragma Pragma
PkgName *Name
DeclList []Decl
Lines uint
node
}
顶层声明有5大类型:分别是常量、类型、变量、函数和方法
- 分析方法
1)自定向下分析:
2)自底向上分析
类型检查
得到抽象语法树之后开始类型检查。
术语:强类型、弱类型、静态类型、动态类型、编译、解释
-
强类型定义:在编译期间会有严格的类型限制。编译器会在编译期间发生变量复制、返回值和函数调用时的类型错误。
-
弱类型定义:类型错误可能出现在运行时 进行隐式的类型转换,
java在编译期间进行类型检查的编程语言是强类型的
GO语言一样。
类型的转换是显示的还是隐式的
编译器会帮助我们推断类型变量吗。 -
静态类型 检查
对源代码的分析来确定 运行程序 类型安全的过程。能够减少程序在运行时的类型检查。可以看作是代码优化的方式
静态类型检查能够帮助我们在编译期间发现程序中出现的类型错误。
一些动态类型的编程语言都会为这些编程语言加入静态类型检查。 javascript的Flow. -
动态类型 检查
运行时确定类型安全的过程。
只使用动态类型检查的编程语言叫做动态类型编程于洋。 js ruby php.
静态和动态类型检查不是完全冲突和对立的。
Java 不仅在编译期间提前检查类型发现类型错误,还为对象添加了类型信息,在运行时使用反射根据对象的类型动态地执行方法增强灵活性并减少冗余代码。
执行过程
GO编译器 不仅使用静态类型检查来保证程序运行的类型安全,还会在编程期间引入类型信息,能够使用反射来判断参数和变量的类型。
gc.Main函数
for i := 0; i < len(xtop); i++ {
n := xtop[i]
if op := n.Op; op != ODCL && op != OAS && op != OAS2 && (op != ODCLTYPE || !n.Left.Name.Param.Alias) {
xtop[i] = typecheck(n, ctxStmt)
}
}
for i := 0; i < len(xtop); i++ {
n := xtop[i]
if op := n.Op; op == ODCL || op == OAS || op == OAS2 || op == ODCLTYPE && n.Left.Name.Param.Alias {
xtop[i] = typecheck(n, ctxStmt)
}
}
...
checkMapKeys()
这段代码分为俩部分。
gc.typecheck()函数检查常量、类型函数声明以及变量赋值语句的类型。
gc.checkMapKeys()检查哈希中键的类型。
cmd/compile/internal/gc.typecheck1 根据传入节点 Op 的类型进入不同的分支,其中包括加减乘数等操作符、函数调用、方法调用等 150 多种,因为节点的种类很多,所以这里只节选几个典型案例深入分析。
func typecheck1(n *Node, top int) (res *Node) {
switch n.Op {
case OTARRAY:
...
case OTMAP:
...
case OTCHAN:
...
}
...
return n
}
- 切片 OTARRATY
如果当前节点的操作类型是OTARRAY.那么这个分支首先会对右节点,进行类型检查。
case OTARRAY:
r := typecheck(n.Right, Etype)
if r.Type == nil {
n.Type = nil
return n
}
然后根据当前节点的左节点不容。分三种 [] int、 […] int 、[3] int
第一种直接调用 types.NewSlice,直接返回了一个 TSLICE 类型的结构体.元素的类型信息也会存储在结构体总。
if n.Left == nil {
t = types.NewSlice(r.Type)
第二种会调用gc.typecheckcomplit处理。
func typecheckcomplit(n *Node) (res *Node) {
...
if n.Right.Op == OTARRAY && n.Right.Left != nil && n.Right.Left.Op == ODDD {
n.Right.Right = typecheck(n.Right.Right, ctxType)
if n.Right.Right.Type == nil {
n.Type = nil
return n
}
elemType := n.Right.Right.Type
length := typecheckarraylit(elemType, -1, n.List.Slice(), "array literal")
n.Op = OARRAYLIT
n.Type = types.NewArray(elemType, length)
n.Right = nil
return n
}
...
}
第三种。调用type.NewArray初始化一个存储着数组中元素类型和数组大小的结构体。
} else {
n.Left = indexlit(typecheck(n.Left, ctxExpr))
l := n.Left
v := l.Val()
bound := v.U.(*Mpint).Int64()
t = types.NewArray(r.Type, bound) }
n.Op = OTYPE
n.Type = t
n.Left = nil
n.Right = nil
- 哈希 OTMAP
如果处理的节点是哈希,那么编译器会分别检查哈希的键值类型以验证它们类型的合法性:
case OTMAP:
n.Left = typecheck(n.Left, Etype)
n.Right = typecheck(n.Right, Etype)
l := n.Left
r := n.Right
n.Op = OTYPE
n.Type = types.NewMap(l.Type, r.Type)
mapqueue = append(mapqueue, n)
n.Left = nil
n.Right = nil
中间代码生成
经过词法与语法分析和类型检查俩个部分之后,AST已经不存在语法错误了。
编译器的后端工作–中间代码生成。
中间代码
中间代码是编译器或虚拟机使用的语言。可以来帮助我们分析计算机程序。
编译器在将源代码转换到机器码的过程中,先把源代码换成一种中间的表示形式。 即中间代码。

很多编译器需要将源代码翻译成多种机器码,直接翻译高级编程语言相对比较困难。拆成中间代码生成和机器码生成。
中间代码是更接近机器语言的表示形式。
cmd/compile/internal/gc.funccompile 编译函数
func Main(archInit func(*Arch)) {
...
initssaconfig()
for i := 0; i < len(xtop); i++ {
n := xtop[i]
if n.Op == ODCLFUNC {
funccompile(n)
}
}
compileFunctions()
}
配置初始化和函数编译俩部分。
配置初始化
SSA配置的初始化过程是中间代码生成之前的准备工作,会缓存可能用到的类型指针、初始化SSA配置和一些之后会调用的运行时函数。
func initssaconfig() {
types_ := ssa.NewTypes()
_ = types.NewPtr(types.Types[TINTER]) // *interface{}
_ = types.NewPtr(types.NewPtr(types.Types[TSTRING])) // **string
_ = types.NewPtr(types.NewPtr(types.Idealstring)) // **string
_ = types.NewPtr(types.NewSlice(types.Types[TINTER])) // *[]interface{}
..
_ = types.NewPtr(types.Errortype) // *error
这个函数分为三部分
1)调用ssa.NewTypes()初始化ssa.Types结构体。并调用types.NewPtr函数缓存类型的信息。比如Bool Int8 String等。

types.NewPtr函数的主要作用是根据类型生成指向这些类型的指针。同时会根据编译器的配置将 生成的指针类型缓存在当前类型中。优化类型指针的获取效率。
func NewPtr(elem *Type) *Type {
if t := elem.Cache.ptr; t != nil {
if t.Elem() != elem {
Fatalf("NewPtr: elem mismatch")
}
return t
}
t := New(TPTR)
t.Extra = Ptr{Elem: elem}
t.Width = int64(Widthptr)
t.Align = uint8(Widthptr)
if NewPtrCacheEnabled {
elem.Cache.ptr = t
}
return t
}
- 根据当前的CPU架构初始化SSA配置。
ssaConfig = ssa.NewConfig(thearch.LinkArch.Name, *types_, Ctxt, Debug['N'] == 0)
输入参数:CPU架构、ssa.Types结构体、上下文信息、Debug配置。
生成中间代码和机器码的函数。当前编译器使用的指针、寄存器大小、可用寄存器列表、掩码等编译选项
func NewConfig(arch string, types Types, ctxt *obj.Link, optimize bool) *Config {
c := &Config{arch: arch, Types: types}
c.useAvg = true
c.useHmul = true
switch arch {
case "amd64":
c.PtrSize = 8
c.RegSize = 8
c.lowerBlock = rewriteBlockAMD64
c.lowerValue = rewriteValueAMD64
c.registers = registersAMD64[:]
...
case "arm64":
...
case "wasm":
default:
ctxt.Diag("arch %s not implemented", arch)
}
c.ctxt = ctxt
c.optimize = optimize
...
return c
}
配置一旦创建,整个编译期间都是只读的。并且被全部编译阶段共享。
3)最后,会初始化 一些编译器可能用到的Go语言运行时函数
assertE2I = sysfunc("assertE2I")
assertE2I2 = sysfunc("assertE2I2")
assertI2I = sysfunc("assertI2I")
assertI2I2 = sysfunc("assertI2I2")
deferproc = sysfunc("deferproc")
Deferreturn = sysfunc("deferreturn")
...
遍历和替换
在生成中间代码之前,编译器还需要替换AST中节点的一些元素。go.walk等函数实现。
func walk(fn *Node)
func walkappend(n *Node, init *Nodes, dst *Node) *Node
...
func walkrange(n *Node) *Node
func walkselect(sel *Node)
func walkselectcases(cases *Nodes) []*Node
func walkstmt(n *Node) *Node
func walkstmtlist(s []*Node)
func walkswitch(sw *Node)
这些用于遍历抽象语法树的函数会将一些关键字和内建函数转换成函数调用
例如: 上述函数会将 panic、recover 两个内建函数转换成 runtime.gopanic 和 runtime.gorecover 两个真正运行时函数,而关键字 new 也会被转换成调用 runtime.newobject 函数。

编译器会将Go语言关键字转换成运行时包中的函数,
SSA生成
经过walk函数处理之后,AST就不会再变了。会使用gc.compileSSA将抽象语法树转换成中间代码。
func compileSSA(fn *Node, worker int) {
f := buildssa(fn, worker) # 负责生成具有SSA特色的中间代码
pp := newProgs(fn, worker)
genssa(f, pp)
pp.Flush()
}

中间代码的生成过程是从 AST 抽象语法树到 SSA 中间代码的转换过程,在这期间会对语法树中的关键字再进行改写,改写后的语法树会经过多轮处理转变成最后的 SSA 中间代码,相关代码中包括了大量 switch 语句、复杂的函数和调用栈
机器码生成
编译的最后一个阶段是根据SSA中间代码生成机器码,这里的机器码是在目标CPU架构上能够运行的二进制代码。
中间代码的降级Lower过程。在降级过程中,编译器将一些值重写成了目标CPU架构的特定值。
指令集架构
指令集架构是 计算机的抽象模型。它是计算机软件和硬件之间的接口和桥梁。
每一个指令集架构都定义了 支持 的数据结构、寄存器、管理主内存的硬件支持(内存一致、地址模型、虚拟内存)、支持的指令集合IO模型。
让同一个二进制文件能够在不同版本的硬件上运行。

机器码生成
俩部分协同工作
1)负责SSA中间代码降级和根据目标架构进行特定处理的ssa包
2)负责生成机器码的obj.
- SSA 降级
SSA 降级是在中间代码生成的过程中完成的,其中将近 50 轮处理的过程中,lower 以及后面的阶段都属于 SSA 降级这一过程,这么多轮的处理会将 SSA 转换成机器特定的操作

和汇编代码非常相似。
汇编器 #
汇编器是将汇编语言翻译为机器语言的程序,Go 语言的汇编器是基于 Plan 9 汇编器的输入类型设计的,
数据结构
数组
数组和切片是Go语音中常见的数据结构
数组是由相同类型元素的集合组成的数据结构。会为数组分配一块连续的内存来保存其中的元素。
常见是一维的。多维的在数值和图形领域

俩个维度来描述数组,
1) 数组中存储的元素类型
2) 数组最大能存储的元素个数
[10] int
[200] interface{}
Go语言数组在初始化之后,大小就无法改变。存储元素类型相同、大小一致才是同一类型的数组
func NewArray(elem *Type, bound int64) *Type {
if bound < 0 {
Fatalf("NewArray: invalid bound %v", bound)
}
t := New(TARRAY)
t.Extra = &Array{Elem: elem, Bound: bound}
t.SetNotInHeap(elem.NotInHeap())
return t
}
编译期间的数组类型是types.NewArray函数生成的。elem是元素类型,bound是数组大小。
当前数组是否应该在堆栈中初始化在编译期间就确定了
初始化
俩种不同的创建方式
arr1 := [3] int{1,2,3} # 显示指定数组大小
arr2 = [...] int{1,2,3} # 声明数组,在编译期推导数组的大小
编译器的推导过程
- 上限推导
俩种不同的声明方式会做出不同的处理
[10]T 这种。变量类型在进行到类型检查就会被提取出来。随后使用types.NewArray创建 包含数组大小的types.Array结构体
[…]T这种。会在gc.typecheckcomplit函数中对该数组的大小进行推导。
func typecheckcomplit(n *Node) (res *Node) {
...
if n.Right.Op == OTARRAY && n.Right.Left != nil && n.Right.Left.Op == ODDD {
n.Right.Right = typecheck(n.Right.Right, ctxType)
if n.Right.Right.Type == nil {
n.Type = nil
return n
}
elemType := n.Right.Right.Type
length := typecheckarraylit(elemType, -1, n.List.Slice(), "array literal")
n.Op = OARRAYLIT
n.Type = types.NewArray(elemType, length)
n.Right = nil
return n
}
...
switch t.Etype {
case TARRAY:
typecheckarraylit(t.Elem(), t.NumElem(), n.List.Slice(), "array literal") # 遍历计算
n.Op = OARRAYLIT
n.Right = nil
}
}
调用typecheckarryalit通过遍历元素的方式来计算数组中元素的数量
- 语句转换
由一个字面量组成的数组,根据数组元素数量的不同。编译器会在负责初始化字面量的gc.anylit函数中做俩种不同的优化
1)当元素数量<= 4 ,会直接将数组中的元素放置在栈上
2)>4 ,会将数组中的元素放置到静态区,并在运行时 取出
访问和赋值
无论是在栈上,还是静态存储区。 数组在内存中都是一连串的内存空间。
指向数组开头的指针、元素的数量、元素类型占的空间大小 三个 维度来表示一个数组。
数组访问越界是非常严重的错误,Go 语言中可以在编译期间的静态类型检查判断数组越界。
数组和字符串的一些简单越界错误都会在编译期间发现。
比如:直接使用整数或者常量访问数组,但是使用变量去访问数组或字符串时,就无法提前发现错误。
需要go语言在运行时阻止不合法的访问
arr[4]: invalid array index 4 (out of bounds for 3-element array)
arr[i]: panic: runtime error: index out of range [4] with length 3
越界操作会由运行时的runtime.panicIndex和runtime.goPanicIndex触发程序的运行时错误,并导致程序崩溃退出
TEXT runtime·panicIndex(SB),NOSPLIT,$0-8
MOVL AX, x+0(FP)
MOVL CX, y+4(FP)
JMP runtime·goPanicIndex(SB)
func goPanicIndex(x int, y int) {
panicCheck1(getcallerpc(), "index out of range")
panic(boundsError{x: int64(x), signed: true, y: y, code: boundsIndex})
}
当数组的访问操作,OINDEX 成功通过编译器检查后,会被转换成几个SSA指令,
package check
func outOfRange() int {
arr := [3]int{1, 2, 3}
i := 4
elem := arr[i]
return elem
}
$ GOSSAFUNC=outOfRange go build array.go
dumped SSA to ./ssa.html
start阶段生成的SSA代码就是优化之前的第一版中间代码。
elem := arr[i]中间代码如下
b1:
...
v22 (6) = LocalAddr <*[3]int> {arr} v2 v20
v23 (6) = IsInBounds <bool> v21 v11
If v23 → b2 b3 (likely) (6)
b2: ← b1-
v26 (6) = PtrIndex <*int> v22 v21
v27 (6) = Copy <mem> v20
v28 (6) = Load <int> v26 v27 (elem[int])
...
Ret v30 (+7)
b3: ← b1-
v24 (6) = Copy <mem> v20
v25 (6) = PanicBounds <mem> [0] v21 v11 v24
Exit v25 (6)
对数组访问操作生成了判断数组上限的指令 IsInBounds 以及当条件不满足时,触发程序崩溃的PanicBounds指令。
编译器会将PanicBounds指令转换成runtime.panicIndex函数。当数组下标没有越界时,编译器会先获取数组的内存地址和访问的下标。利用PtrIndex计算出目标元素的地址。最后使用Load操作将指针中的元素加载到内存中。
编译器无法判断下标是否越界,会将PanicBounds指令交给运行时进行判断。
改成整数访问,中间代码如下
b1:
...
v21 (5) = LocalAddr <*[3]int> {arr} v2 v20
v22 (5) = PtrIndex <*int> v21 v14
v23 (5) = Load <int> v22 v20 (elem[int])
...
赋值的过程中会先确定目标数组的地址,再通过 PtrIndex 获取目标元素的地址,最后使用 Store 指令将数据存入地址中,从上面的这些 SSA 代码中我们可以看出 数组寻址和赋值都是在编译阶段完成的,没有运行时的参与。
b1:
...
v21 (5) = LocalAddr <*[3]int> {arr} v2 v19
v22 (5) = PtrIndex <*int> v21 v13
v23 (5) = Store <mem> {int} v22 v20 v19
...
切片
数组在go语言中没那么常用,更常用的数据结构是切片, 即动态数组,长度不固定,可以向切片中追加元素。它会在容量不足时自动扩容。
声明方式不需要指定切片中的元素个数,只需要指定元素类型
[] int
[] interface{}
编译期生成类型只包含切片中的元素类型。
func NewSlice(elem *Type) *Type {
if t := elem.Cache.slice; t != nil {
if t.Elem() != elem {
Fatalf("elem mismatch")
}
return t
}
t := New(TSLICE)
t.Extra = Slice{Elem: elem}
elem.Cache.slice = t
return t
}
编译期间的切片是types.Slice类型的,运行时切片有reflect.SliceHeader结构体表示
type SliceHeader struct {
Data uintptr # 指向数组的指针
Len int # 当前切片的长度
Cap int # 当前切片的容量
}

Data是一片连续的内存空间。这片内存空间用于存储切片中的全部元素。
切片与数组的关系非常密切。切片引入了一个抽象层。提供了对数组中部分连续片段的引用。而作为数组的引用。我们可以在运行区间修改它的长度和范围。当切片底层数组长度不足时就会触发扩容,切片指向的数组可能会发生变化。但是上层感知不到。上层只与切片打交道。
切片初始化
arr[0:3] or slice[0:3] # 通过下班获取一部分
slice := [] int {1,2,3} # 字面量初始化
slice := make([]int, 10) # make创建
- 使用下标
最接近汇编语言的方式。转换成OpSliceMack操作。
// ch03/op_slice_make.go
package opslicemake
func newSlice() []int {
arr := [3]int{1, 2, 3}
slice := arr[0:1]
return slice
}
slice := arr[0:1] 对应如下的SSA中间代码
v27 (+5) = SliceMake <[]int> v11 v14 v17
name &arr[*[3]int]: v11
name slice.ptr[*int]: v11
name slice.len[int]: v14
name slice.cap[int]: v17
SliceMake 操作接收四个参数: 元素类型、数组指针、切片大小、 容量。
下标初始化不会拷贝原数组或原切片中的数据,只会创建一个指向原数组的切片结构体。所以修改新切片的数据也会修改原切片。
- 字面量
[]int{1,2,3}, 编译期间会展开如下代码片段
var vstat [3]int
vstat[0] = 1
vstat[1] = 2
vstat[2] = 3
var vauto *[3]int = new([3]int)
*vauto = vstat
slice := vauto[:]
- 根据切片中的元素数量对底层数组的大小进行推断并创建一个数组
2)将这些字面量元素存储到初始化数组中。
3)创建一个同样指向【3】int类型的数组指针
4)将静态存储区的数组vstat 复制给vauto指针所在的地址
5)通过[:] 操作获取一个底层使用vauto的切片。
- 关键字
slice := make([]int, 10)
使用字面量创建切片,大部分工作在编译期间完成,使用make关键字创建切片时,很多工作需要运行时的参与。
调用方法必须向make函数传入切片的大小以及可选的容量。gc.typecheck1函数会检验入参。检查len是否传入,还会保证cap一定大于或等于len.还会将OMAKE节点转换为OMAKESLICE。
go.walker会依据来个条件转换OMAKESLICE类型的节点
1.切片的大小和容量是否足够小
2.切片是否发生了逃逸,最终在堆上初始化。
当切片发生逃逸或者非常大时,运行时需要runtime.makeslice在堆上初始化切片。
如果切片不会发生逃逸并且切片非常小的时候,make([] int, 3,4)会直接被转换成如下代码
var arr [4]int n := arr[:3]
创建切片的运行时函数runtime.makeslice
func makeslice(et *_type, len, cap int) unsafe.Pointer {
mem, overflow := math.MulUintptr(et.size, uintptr(cap))
if overflow || mem > maxAlloc || len < 0 || len > cap {
mem, overflow := math.MulUintptr(et.size, uintptr(len))
if overflow || mem > maxAlloc || len < 0 {
panicmakeslicelen()
}
panicmakeslicecap()
}
return mallocgc(mem, et, true)
}
主要工作是计算切片占用的内存空间并在堆上申请一片连续的内存。
内存空间 = 切片中元素的大小 * 切片容量
虽然编译期间可以检查出很多错误,但是在创建切片的过程中如果发生了以下错误会直接触发运行时错误并崩溃。
1.内存空间的大小发生了溢出
2.申请的内存大于最大可分配的内存
3.传入的长度小于0 或者大于容量。
mallocgc是用于申请内存的函数,这个函数比较复杂,
如果遇到了较小的对象会直接初始化在Go语音调度器里面的P结构中。而大于32KB的对象会在堆上初始化,
访问元素
使用len和cap获取长度或者容量是切片最常见的操作。
对应俩个特殊操作 OLEN 和 OCAP.
SSA生成阶段会转换成OpSliceLen 和 OpSliceCap。可能会触发decompose builtin阶段的优化,len(slice) / cap(slice)在一些情况下会直接替换成切片的长度或者容量。不需要在运行时获取。
(SlicePtr (SliceMake ptr _ _ )) -> ptr
(SliceLen (SliceMake _ len _)) -> len
(SliceCap (SliceMake _ _ cap)) -> cap
除了获取切片的长度和容量之外,访问切片中元素使用的OINDEX操作也会在中间代码生成期间转换成对地址的直接访问.
切片操作基本都是在编译期间完成的。除了访问切片的长度、容量或者其中的元素之外。
编译期间会将包含range关键字的遍历转换成形式更简单的循环。
追加和扩容
使用append关键字向切片中追加元素。
中间代码生成阶段的gc.state.append方法会根据返回值是否会覆盖原变量,进入俩种流程。
如果append返回的新切片不需要赋值回原有的变量。进入如下
// append(slice, 1, 2, 3)
ptr, len, cap := slice
newlen := len + 3
if newlen > cap {
ptr, len, cap = growslice(slice, newlen)
newlen = len + 3
}
*(ptr+len) = 1
*(ptr+len+1) = 2
*(ptr+len+2) = 3
return makeslice(ptr, newlen, cap)
如果追加后切片的大小大于容量,那么就会调用 growslice对切片进行扩容。然后依次将新的元素依次加入切片。
如果使用slice = append(slice,1,2,3)。那么append后的切片会覆盖原切片。
// slice = append(slice, 1, 2, 3)
a := &slice
ptr, len, cap := slice
newlen := len + 3
if uint(newlen) > uint(cap) {
newptr, len, newcap = growslice(slice, newlen)
vardef(a)
*a.cap = newcap
*a.ptr = newptr
}
newlen = len + 3
*a.len = newlen
*(ptr+len) = 1
*(ptr+len+1) = 2
*(ptr+len+2) = 3
是否覆盖原变量的逻辑其实差不多。最大的区别在于得到的新切片是否会赋值回原变量。
如果我们选择覆盖原有的变量。就不需要担心切片发生拷贝影响性能。

切片容量不足的处理流程。growslice.
扩容是为切片分配新的内存空间并拷贝原始切片中元素的过程。
func growslice(et *_type, old slice, cap int) slice {
newcap := old.cap
doublecap := newcap + newcap
if cap > doublecap {
newcap = cap
} else {
if old.len < 1024 {
newcap = doublecap
} else {
for 0 < newcap && newcap < cap {
newcap += newcap / 4
}
if newcap <= 0 {
newcap = cap
}
}
}
根据不同的容量选择不同的策略
1.如果期望容量大于当前容量的俩倍,就会使用期望容量
2.如果当前切片的长度小于1024,就会将容量翻倍。
3.如果当前切片的长度大于1024,那么就增加25%的容量。
拷贝切片
copy(a,b)
gc.copyany分俩种情况进行处理。
如果当前copy不是在运行时调用的。直接替换成下面的代码
n := len(a)
if n > len(b) {
n = len(b)
}
if a.ptr != b.ptr {
memmove(a.ptr, b.ptr, n*sizeof(elem(a)))
}
运行 时发生,调用runtime.slicecopy
func slicecopy(to, fm slice, width uintptr) int {
if fm.len == 0 || to.len == 0 {
return 0
}
n := fm.len
if to.len < n {
n = to.len
}
if width == 0 {
return n
}
...
size := uintptr(n) * width
if size == 1 {
*(*byte)(to.array) = *(*byte)(fm.array)
} else {
memmove(to.array, fm.array, size)
}
return n
}
都通过runtime.memmove将整块内存的内容拷贝到目标的内存区域中:

哈希表
go语言的哈希的实现原理。
数组表示元素的序列。
哈希表示的是键值对之间的映射关系。
设计原理
O(1)的读写性能。
提供了键值之间的映射。想要实现一个性能优异的哈希表。需要注意俩个关键点—哈希函数和冲突解决方法
- 哈希函数
哈希函数的选择在很大程度上 能够决定哈希表的读写性能。
理想的情况下,哈希函数应该能够将不同键 映射到不同的索引上。这就要求 哈希函数的输出范围 > 输入范围
键的数量会远远大于映射的范围。理想情况很难存在。

比较实际的方式是让哈希函数的结果 尽可能的均匀分布。然后通过工程上的手段解决哈希碰撞的问题。
不均匀的哈希函数

-
冲突解决
通常情况下,哈希函数的输入范围一定远远大于输出范围。
所以一定会遇到冲突。冲突不一定是哈希完全相等。可能是部分相等。比如:前4个字节相同。 -
开放寻址法
开放寻址法 是一种在哈希表中解决哈希碰撞的方法。核心思想是依次探测和比较数组中的元素以判断目标键值对 是否存在于哈希表中。
底层数据结构必须是数组。数组长度有限。所以向哈希表写入(author, draven)会从如下的索引开始遍历
index := hash('author') % array.len
如果发生了冲突。会将键值对写入到下一个索引不为空的位置。
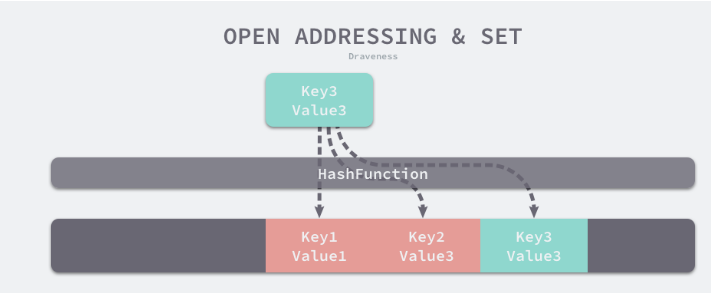
读取数据
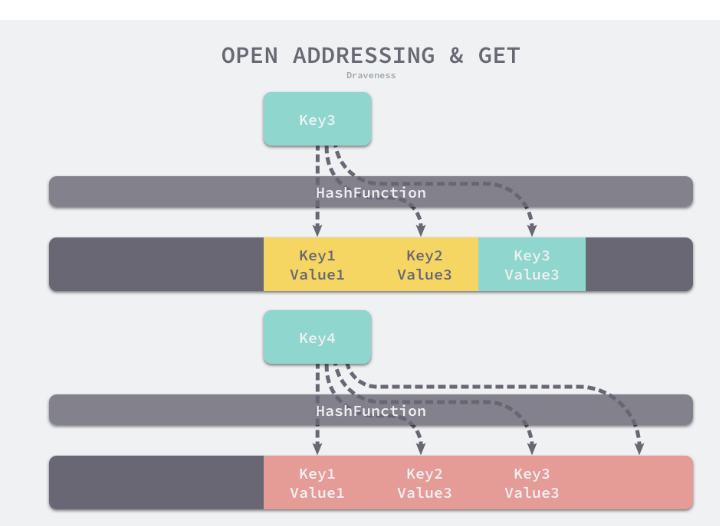
开放地址法中对性能影响最大的是装载因子。它是数组中元素的数量与 数组大小的比值。随着装载因子的增加。线性探测的平均用时就会逐渐增加。会影响哈希表的读写性能。当装载率超过70%之后。哈希表的性能就会急剧下降。达到100%,就会完全失效。 -
拉链法
拉链法是哈希表最常见的实现方法。 数据结构使用数组+链表。还会引入红黑树优化性能



哈希函数会选择一个桶,和开放地址法一样,就是对哈希返回的结果取模。
选择了2号桶后就可以遍历当前桶中的链表。在遍历链表的时候会遇到以下俩种情况
1.找到键相同的键值对- 更新值
2.没有找到-在链表末尾追加新的键值对
拉链法的装载因子
装载因子:= 元素数量 / 桶数量
当装载因子变大是,读写性能也就越差。
数据结构
go语言运行时同时使用了多个数据结构组合表示哈希表。runtime.hmap是最核心的结构体。
type hmap struct {
count int # 当前哈希表中的元素数量
flags uint8 #
B uint8 # 表示当前哈希表持有的buckets 数量。
noverflow uint16
hash0 uint32 # 哈希的种子。为哈希函数的结果引入 随机性
buckets unsafe.Pointer
oldbuckets unsafe.Pointer # 保存之前的buckets的字段
nevacuate uintptr
extra *mapextra
}
type mapextra struct {
overflow *[]*bmap
oldoverflow *[]*bmap
nextOverflow *bmap
}

每一个bmap都能够存储8个键值对。当哈希表中存储的数据过多。单个桶已经装满就会使用 extra.nextOverflow中桶存储移除的数据。
上述俩种不同的桶在内存中是连续存储的。分为正常桶(黄色桶)和溢出桶(绿色桶)
bmap,源代码中 只包含一个tophash字段。
type bmap struct {
tophash [bucketCnt]uint8
}
在运行期间不止包含tophash字段
type bmap struct {
topbits [8]uint8
keys [8]keytype
values [8]valuetype
pad uintptr
overflow uintptr
}
哈希表初始化
- 字面量
key:value的语法来表示键值对
hash := map[string]int{
"1": 2,
"3": 4,
"5": 6,
}
gc.maplit
func maplit(n *Node, m *Node, init *Nodes) {
a := nod(OMAKE, nil, nil)
a.Esc = n.Esc
a.List.Set2(typenod(n.Type), nodintconst(int64(n.List.Len())))
litas(m, a, init)
entries := n.List.Slice()
if len(entries) > 25 { # 哈希表数量小于25个时,一次直接加入到哈希表中
...
return
}
// Build list of var[c] = expr.
// Use temporaries so that mapassign1 can have addressable key, elem.
...
}
超过了25个,会创建俩个数组分别存储键值。会通过如下for循环加入哈希
hash := make(map[string]int, 26)
vstatk := []string{"1", "2", "3", ... , "26"}
vstatv := []int{1, 2, 3, ... , 26}
for i := 0; i < len(vstak); i++ {
hash[vstatk[i]] = vstatv[i]
}
- 运行时
当创建的哈希表被分配到栈上,并且容量小于BUCKETSIZE = 8时,GO语言在编译阶段会使用如下方式快速初始化哈希。
var h *hmap
var hv hmap
var bv bmap
h := &hv
b := &bv
h.buckets = b
h.hash0 = fashtrand0()
读写操作
哈希表的访问一般都是通过下标或者遍历进行的。
_ = hash[key]
for k, v := range hash {
// k, v
}
- 访问
在编译类型检查期间,hash[key] 以及类似的 操作都会被转换成哈希的 OINDEXMAP操作。
中间代码生成阶段会在gc.walkexpr 中间这些OINDEXMAP操作转换成如下代码
v := hash[key] // => v := *mapaccess1(maptype, hash, &key)
v, ok := hash[key] // => v, ok := mapaccess2(maptype, hash, &key)
runtime.mapaccess1 会先通过哈希表设置的哈希函数、、种子获取当前键对应的哈希。再通过bucketMask和add拿到该键值对所在的桶序号和哈希高位的8位数字。
小结
Go 语言使用拉链法来解决哈希碰撞的问题实现了哈希表,它的访问、写入和删除等操作都在编译期间转换成了运行时的函数或者方法。哈希在每一个桶中存储键对应哈希的前 8 位,当对哈希进行操作时,这些 tophash 就成为可以帮助哈希快速遍历桶中元素的缓存。
哈希表的每个桶都只能存储 8 个键值对,一旦当前哈希的某个桶超出 8 个,新的键值对就会存储到哈希的溢出桶中。随着键值对数量的增加,溢出桶的数量和哈希的装载因子也会逐渐升高,超过一定范围就会触发扩容,扩容会将桶的数量翻倍,元素再分配的过程也是在调用写操作时增量进行的,不会造成性能的瞬时巨大抖动。
字符串

如果是代码中存在的字符串,编译器会将其标记成只读数据SRODATA.
$ cat main.go
package main
func main() {
str := "hello"
println([]byte(str))
}
$ GOOS=linux GOARCH=amd64 go tool compile -S main.go
...
go.string."hello" SRODATA dupok size=5 # SRODATA标记
0x0000 68 65 6c 6c 6f hello
...
只读意味着字符串会被分配到只读的内存空间。
可以通过在string 和 []byte 类型之间反复转换实现修改。
1.先讲这段内存拷贝到堆或者栈上。
2.将变量的类型转换成[] byte后,并修改字节数据
3.将修改后的字节数组转回string.
字符串数据结构
type StringHeader struct {
Data uintptr # 指向字节数组的指针
Len int # 数组大小
}
与切片相比,只少了一个表示容量的Cap字段。字符串就是一个只读的切片类型。
所有在字符串上的写入操作都是通过拷贝实现的。
字符串 解析过程
解析器会在词法分析阶段解析字符串。会对源文件中的字符串进行切片和分组。将原有的字符流转换成Token序列。
俩种声明
str1 := "this is a string"
str2 := `this is another
string`
双引号和反引号。
双引号:只能用于单行字符串的初始化。如果内部出现双引号需要\符合转义。
反引号:可以摆脱单行的限制。双引号不再负责标记字符串的开始和结束。在遇到json或者其他复杂数据格式的场景下非常方便。
字符串拼接
+符号, 会将该符号对应的OADD节点转换为OADDSTR类型的节点。然后调用gc.addstr函数生成用于拼接字符串的代码
func walkexpr(n *Node, init *Nodes) *Node {
switch n.Op {
...
case OADDSTR:
n = addstr(n, init)
}
}
类型转换
解析 和 序列化json等数据格式是,需要将数据在string和[]byte之间来回转换。
从字节数组到字符串的转换需要使用runtime.slicebytesostring函数。例如:string(bytes),
长度为0和长度为1 的字节数组,处理起来比较简单。
func slicebytetostring(buf *tmpBuf, b []byte) (str string) {
l := len(b)
if l == 0 {
return ""
}
if l == 1 {
stringStructOf(&str).str = unsafe.Pointer(&staticbytes[b[0]])
stringStructOf(&str).len = 1
return
}
var p unsafe.Pointer
if buf != nil && len(b) <= len(buf) {
p = unsafe.Pointer(buf)
} else {
p = mallocgc(uintptr(len(b)), nil, false)
}
stringStructOf(&str).str = p
stringStructOf(&str).len = len(b)
memmove(p, (*(*slice)(unsafe.Pointer(&b))).array, uintptr(len(b)))
return
}
处理过后会根据传入的缓冲区大小决定是否需要为新字符串分配一片内存空间。
字符串转换成[]byte类型时,需要使用runtime.stringtoslicebyte函数,
func stringtoslicebyte(buf *tmpBuf, s string) []byte {
var b []byte
if buf != nil && len(s) <= len(buf) {
*buf = tmpBuf{}
b = buf[:len(s)]
} else {
b = rawbyteslice(len(s))
}
copy(b, s)
return b
}

语言基础
函数调用
函数是go语言的一等公民。
调用惯例
somefunction(arg0,arg1)
调用惯例是调用方和被调用方对于参数和返回值传递的约定。
- C语言
示例
// ch04/my_function.c
int my_function(int arg1, int arg2) {
return arg1 + arg2;
}
int main() {
int i = my_function(1, 2);
}
编译成汇编
main:
pushq %rbp
movq %rsp, %rbp
subq $16, %rsp
movl $2, %esi // 设置第二个参数
movl $1, %edi // 设置第一个参数
call my_function
movl %eax, -4(%rbp)
my_function:
pushq %rbp
movq %rsp, %rbp
movl %edi, -4(%rbp) // 取出第一个参数,放到栈上
movl %esi, -8(%rbp) // 取出第二个参数,放到栈上
movl -8(%rbp), %eax // eax = esi = 1
movl -4(%rbp), %edx // edx = edi = 2
addl %edx, %eax // eax = eax + edx = 1 + 2 = 3
popq %rbp
调用过程:
1.调用方main函数将my_function的俩个参数分别存到edi和esi寄存器中。
2.在my_function调用时,它会将寄存器edi和esi中的数据存储到eax和edx俩个寄存器中。随后通过汇编指令addl 计算俩个入参之和。
3.在my_fuction调用后,使用寄存器eax 传奇返回值。然后存储到栈上的i变量中。
当my_function函数的入参增加至8个时。会得到不同的汇编代码。
main:
pushq %rbp
movq %rsp, %rbp
subq $16, %rsp // 为参数传递申请 16 字节的栈空间
movl $8, 8(%rsp) // 传递第 8 个参数
movl $7, (%rsp) // 传递第 7 个参数
movl $6, %r9d
movl $5, %r8d
movl $4, %ecx
movl $3, %edx
movl $2, %esi
movl $1, %edi
call my_function
前6个参数会使用edi、esi、edx、ecx、r8d\r9d 六个寄存器传递。
最后的俩个参数通过栈传递。

rbp寄存器会存储函数调用栈的基址指针。main函数的栈空间的其实地址。而另一个寄存器rsp存储的是main函数调用栈结束的位置。
这俩个寄存器共同表示了函数的栈空间。
在调用my_function之前。main函数通过sub1 $16,%rsp指令分配了16个字节的站地址。随后将第6个以上的参数按照从右到左的顺序存入栈中。余下的6个参数通过寄存器传递。
my_function:
pushq %rbp
movq %rsp, %rbp
movl %edi, -4(%rbp) // rbp-4 = edi = 1
movl %esi, -8(%rbp) // rbp-8 = esi = 2
...
movl -8(%rbp), %eax // eax = 2
movl -4(%rbp), %edx // edx = 1
addl %eax, %edx // edx = eax + edx = 3
...
movl 16(%rbp), %eax // eax = 7
addl %eax, %edx // edx = eax + edx = 28
movl 24(%rbp), %eax // eax = 8
addl %edx, %eax // edx = eax + edx = 36
popq %rbp
my_function会先将寄存器中的全部数据转移到栈上。然后利用eax寄存器计算所有入参的和并返回结果。
函数的返回值是通过eax寄存器进行传递的。由于只使用一个寄存器存储返回值。所以C语言的函数不能同时返回多个值。
- Go语言
package main
func myFunction(a, b int) (int, int) {
return a + b, a - b
}
func main() {
myFunction(66, 77)
}
"".main STEXT size=68 args=0x0 locals=0x28
0x0000 00000 (main.go:7) MOVQ (TLS), CX
0x0009 00009 (main.go:7) CMPQ SP, 16(CX)
0x000d 00013 (main.go:7) JLS 61
0x000f 00015 (main.go:7) SUBQ $40, SP // 分配 40 字节栈空间
0x0013 00019 (main.go:7) MOVQ BP, 32(SP) // 将基址指针存储到栈上
0x0018 00024 (main.go:7) LEAQ 32(SP), BP
0x001d 00029 (main.go:8) MOVQ $66, (SP) // 第一个参数
0x0025 00037 (main.go:8) MOVQ $77, 8(SP) // 第二个参数
0x002e 00046 (main.go:8) CALL "".myFunction(SB)
0x0033 00051 (main.go:9) MOVQ 32(SP), BP
0x0038 00056 (main.go:9) ADDQ $40, SP
0x003c 00060 (main.go:9) RET

"".myFunction STEXT nosplit size=49 args=0x20 locals=0x0
0x0000 00000 (main.go:3) MOVQ $0, "".~r2+24(SP) // 初始化第一个返回值
0x0009 00009 (main.go:3) MOVQ $0, "".~r3+32(SP) // 初始化第二个返回值
0x0012 00018 (main.go:4) MOVQ "".a+8(SP), AX // AX = 66
0x0017 00023 (main.go:4) ADDQ "".b+16(SP), AX // AX = AX + 77 = 143
0x001c 00028 (main.go:4) MOVQ AX, "".~r2+24(SP) // (24)SP = AX = 143
0x0021 00033 (main.go:4) MOVQ "".a+8(SP), AX // AX = 66
0x0026 00038 (main.go:4) SUBQ "".b+16(SP), AX // AX = AX - 77 = -11
0x002b 00043 (main.go:4) MOVQ AX, "".~r3+32(SP) // (32)SP = AX = -11
0x0030 00048 (main.go:4) RET

Go语言使用栈传递参数和接收返回值。所以只需要在栈上多分配一些内存就可以返回多个值。
参数传递
值传递还是引用传递。
- 传值: 函数调用会对参数进行拷贝,被调用方和调用方俩者持有不相关的俩份数据
- 传引用:持有相同的数据
不同的语言会选择不同的方式传递参数。GO语言选择了传值得方式。无论是基本类型、结构体、还是指针。都会对传递的参数进行拷贝。 - 整型和数组
整型变量i和数组arr.
func myFunction(i int, arr [2]int) {
fmt.Printf("in my_funciton - i=(%d, %p) arr=(%v, %p)\n", i, &i, arr, &arr)
}
func main() {
i := 30
arr := [2]int{66, 77}
fmt.Printf("before calling - i=(%d, %p) arr=(%v, %p)\n", i, &i, arr, &arr)
myFunction(i, arr)
fmt.Printf("after calling - i=(%d, %p) arr=(%v, %p)\n", i, &i, arr, &arr)
}
$ go run main.go
before calling - i=(30, 0xc00009a000) arr=([66 77], 0xc00009a010)
in my_funciton - i=(30, 0xc00009a008) arr=([66 77], 0xc00009a020)
after calling - i=(30, 0xc00009a000) arr=([66 77], 0xc00009a010)
在my_function中修改
func myFunction(i int, arr [2]int) {
i = 29
arr[1] = 88
fmt.Printf("in my_funciton - i=(%d, %p) arr=(%v, %p)\n", i, &i, arr, &arr)
}
$ go run main.go
before calling - i=(30, 0xc000072008) arr=([66 77], 0xc000072010)
in my_funciton - i=(29, 0xc000072028) arr=([66 88], 0xc000072040)
after calling - i=(30, 0xc000072008) arr=([66 77], 0xc000072010)
Go 语言的整型和数组类型都是值传递的,也就是在调用函数时会对内容进行拷贝。需要注意的是如果当前数组的大小非常的大,这种传值的方式会对性能造成比较大的影响
- 结构体和指针
type MyStruct struct {
i int
}
func myFunction(a MyStruct, b *MyStruct) {
a.i = 31
b.i = 41
fmt.Printf("in my_function - a=(%d, %p) b=(%v, %p)\n", a, &a, b, &b)
}
func main() {
a := MyStruct{i: 30}
b := &MyStruct{i: 40}
fmt.Printf("before calling - a=(%d, %p) b=(%v, %p)\n", a, &a, b, &b)
myFunction(a, b)
fmt.Printf("after calling - a=(%d, %p) b=(%v, %p)\n", a, &a, b, &b)
}
$ go run main.go
before calling - a=({30}, 0xc000018178) b=(&{40}, 0xc00000c028)
in my_function - a=({31}, 0xc000018198) b=(&{41}, 0xc00000c038)
after calling - a=({30}, 0xc000018178) b=(&{41}, 0xc00000c028)
结论1:传递结构体时:会拷贝结构体中的全部内容
结论2:传递结构体指针时:会拷贝结构体指针。
修改结构体指针,是改变了指针指向的结构体。 b.i => (*b).i
尽量使用指针作为参数类型来避免发生数据拷贝进而影响性能。
接口
Go语言中的接口是一组方法的签名。使用接口能够让我们写出易于测试的代码。
接口概述
接口是计算机系统中多个组件共享的边界。不同的组件能够在边界上交换信息。
接口的本质是引入一个新的中间层。调用方可以通过接口与具体的实现分离。解除上下游的耦合。
上层的模块不需要依赖下层的具体模块。只需要依赖一个约定好的接口。

面向接口的编程方式有着非常强大的生命力。
Go语言中的接口是一种内置的类型。定义了一组方法的签名。
- 隐式接口
java中的接口,还可以定义变量。可以在类中直接使用。
public interface MyInterface {
public String hello = "Hello";
public void sayHello();
}
public class MyInterfaceImpl implements MyInterface {
public void sayHello() {
System.out.println(MyInterface.hello);
}
}
go语言不需要使用上述方式显示的声明实现的接口.
一个常见的Go语言接口是这样的:
type error interface {
Error() string
}
如果一个类型需要实现error接口。那么只需要实现Error() string方法。
type RPCError struct {
Code int64
Message string
}
func (e *RPCError) Error() string {
return fmt.Sprintf("%s, code=%d", e.Message, e.Code)
}
Go语言中的接口实现都是隐式的。只需要实现Error() String方法就实现了error接口。
在java中:实现接口需要显示地声明接口 并实现所有方法
在Go中:实现接口的所有方法就隐式地实现了接口。
上述RPCError结构体并不太关心它实现了哪些接口,Go语言只会在传递参数、返回参数以及变量赋值时才会对某个类型是否实现接口进行检查。
func main() {
var rpcErr error = NewRPCError(400, "unknown err") // typecheck1
err := AsErr(rpcErr) // typecheck2
println(err)
}
func NewRPCError(code int64, msg string) error {
return &RPCError{ // typecheck3
Code: code,
Message: msg,
}
}
func AsErr(err error) error {
return err
}
将 *RPCError 类型的变量赋值给 error 类型的变量 rpcErr;
将 *RPCError 类型的变量 rpcErr 传递给签名中参数类型为 error 的 AsErr 函数;
将 *RPCError 类型的变量从函数签名的返回值类型为 error 的 NewRPCError 函数中返回;
- 类型
接口也是Go语言中的一种类型,能够出现在变量的定义、函数的入参和返回值中,并对它们进行约束。
go语言有俩种不同的接口,一种是带有一组方法的接口。
另一种是不带任何方法的interface{}

runtime.iface表示第一种接口。
runtime.aface表示不包含任何方法接口的interface{}
interface{}类型不是任意类型。变量在运行期间的类型会发生变换。
获取变量类型时会得到interface{}

package main
func main() {
type Test struct{}
v := Test{}
Print(v)
}
func Print(v interface{}) {
println(v)
}
上述函数不接受任意类型的参数,只接受interface{}类型的值,在调用Print函数时,会对参数v进行类型转换,将原来的Test类型转换成interface类型。
- 指针和接口
在GO语言中,同时使用指针和接口时 会发生一些让人困惑的问题。
接口在定义一组方法时没有对实现的接收者做限制。
所以我们会看到某个类型实现接口的俩种方式。


结构体类型和指针类型是不同的。
上图中俩种实现不可以同时存在,如果同时存在,会报错:“method redeclared”
对 Cat结构体来说。在实现接口时,可以选择接受者的类型,即结构体或者结构体指针
type Cat struct {}
type Duck interface { ... }
func (c Cat) Quack {} // 使用结构体实现接口
func (c *Cat) Quack {} // 使用结构体指针实现接口
var d Duck = Cat{} // 使用结构体初始化变量
var d Duck = &Cat{} // 使用结构体指针初始化变量
实现接口的类型和初始化返回的类型两个维度共组成了四种情况,然而这四种情况不是都能通过编译器的检查:

使用结构体指针实现接口,结构体初始化变量无法通过编译。其他三种情况都可以正常执行。
当实现接口的类型和初始化的变量返回的类型相同是,代码通过是理所应当的。
方法接受者和初始化类型都是结构体。
方法接受者和初始化类型都是结构体指针
而剩下的俩种方式为什么一个可以通过编译,一个不行呢。
可以通过的是:方法的接受者是结构体,初始化变量是结构体指针。
type Cat struct{}
func (c Cat) Quack() {
fmt.Println("meow")
}
func main() {
var c Duck = &Cat{}
c.Quack()
}
作为指针的&Cat{}变量能够隐式地获取到指向的结构体。通过指针找到对应的结构体,然后引用Quack()
type Duck interface {
Quack()
}
type Cat struct{}
func (c *Cat) Quack() {
fmt.Println("meow")
}
func main() {
var c Duck = Cat{}
c.Quack()
}
$ go build interface.go
./interface.go:20:6: cannot use Cat literal (type Cat) as type Duck in assignment:
Cat does not implement Duck (Quack method has pointer receiver)
Cat 类型没有实现 Duck 接口,Quack 方法的接受者是指针。这两个报错对于刚刚接触 Go 语言的开发者比较难以理解,如果我们想要搞清楚这个问题,首先要知道 Go 语言在传递参数时都是传值的。

初始化的变量c是Cat{} 还是 &Cat{}。使用c.Quack()调用方法是都会发生值拷贝。
-
对于&Cat{}来说,这意味着拷贝一个新的&Cat{}指针,这个指针指向一个相同并且唯一的结构体。所以编译器可以隐式的对变量解引用 dereference。获取结构体。
-
对于Cat{} 来说。意味着,Quack方法会接受一个全新的Cat{}.因为方法的参数是*Cat{}。编译器不会无中生有创建一个新的指针,即使可以创建新的指针,这个指针也不会指向最初调用该方法的结构体。
上面的分析解释了指针类型的现象,当我们使用指针实现接口时,只有指针类型的变量才会实现该接口;当我们使用结构体实现接口时,指针类型和结构体类型都会实现该接口。当然这并不意味着我们应该一律使用结构体实现接口,这个问题在实际工程中也没那么重要,在这里我们只想解释现象背后的原因。 -
nil 和 non-nil
数据结构
go语言根据接口类型是否包含一组方法将接口类型分成了俩类
- 使用runtime.iface结构体表示包含方法的接口。
- 使用runtime.eface结构体表示不包含任何方法的interface{}类型。
type eface struct { // 16 字节
_type *_type # 指向底层数据类型的指针
data unsafe.Pointer # 指向底层数据的指针
}
type iface struct { // 16 字节
tab *itab
data unsafe.Pointer # 指向底层数据的指针
}
- 类型结构体
runtime._type 是Go语言类型的运行时表示,
type _type struct {
size uintptr #该类型占用的内存空间
ptrdata uintptr
hash uint32 # 快速确定类型是否相等
tflag tflag
align uint8
fieldAlign uint8
kind uint8
equal func(unsafe.Pointer, unsafe.Pointer) bool # 当前类型的多个对象是否相等。
gcdata *byte
str nameOff
ptrToThis typeOff
}
- itab结构体
type itab struct { // 32 字节
inter *interfacetype
_type *_type
hash uint32 # 是对 _type.hash 的拷贝
_ [4]byte
fun [1]uintptr # 是一个动态大小的数组,它是一个用于动态派发的虚函数表,存储了一组函数指针
}
类型转换
接口类型是如何初始化和传递的。
- 指针类型
类型断言
具体类型转换为接口类型
接口类型转换为具体类型
动态派发
Dynamic dispatch.是在运行期间选择具体多态操作(方法或函数)执行的过程。
Go语言不是严格意义上的面向对象的语言。但是接口的引入为它带来了动态派发的特性。
编译期间不能确认接口类型,go语言会在运行期间决定具体调用该方法的哪个实现。
func main() {
var c Duck = &Cat{Name: "draven"}
c.Quack() # Duck接口类型的身份调用,调用时需要经过运行时的动态派发
c.(*Cat).Quack() # *Cat 具体类型的身份调用。编译期就会确定调用的函数。
}
反射
reflect 实现了运行时的反射能力。
能够让程序操作不同类型的对象。
reflect.TypeOf 能获取类型信息;
reflect.ValueOf 能获取数据的运行时表示;

类型 reflect.Type 是反射包定义的一个接口,我们可以使用 reflect.TypeOf 函数获取任意变量的类型,reflect.Type 接口中定义了一些有趣的方法,MethodByName 可以获取当前类型对应方法的引用、Implements 可以判断当前类型是否实现了某个接口:
type Type interface {
Align() int
FieldAlign() int
Method(int) Method
MethodByName(string) (Method, bool)
NumMethod() int
...
Implements(u Type) bool
...
}
type Value struct {
// 包含过滤的或者未导出的字段
}
func (v Value) Addr() Value
func (v Value) Bool() bool
func (v Value) Bytes() []byte
...
三大法则
从 interface{} 变量可以反射出反射对象;
从反射对象可以获取 interface{} 变量;
要修改反射对象,其值必须可设置;
常用关键字
for 和 range
for循环编译成汇编指令
package main
func main() {
for i := 0; i < 10; i++ {
println(i)
}
}
"".main STEXT size=98 args=0x0 locals=0x18
00000 (main.go:3) TEXT "".main(SB), $24-0
...
00029 (main.go:3) XORL AX, AX ;; i := 0
00031 (main.go:4) JMP 75
00033 (main.go:4) MOVQ AX, "".i+8(SP)
00038 (main.go:5) CALL runtime.printlock(SB)
00043 (main.go:5) MOVQ "".i+8(SP), AX
00048 (main.go:5) MOVQ AX, (SP)
00052 (main.go:5) CALL runtime.printint(SB)
00057 (main.go:5) CALL runtime.printnl(SB)
00062 (main.go:5) CALL runtime.printunlock(SB)
00067 (main.go:4) MOVQ "".i+8(SP), AX
00072 (main.go:4) INCQ AX ;; i++
00075 (main.go:4) CMPQ AX, $10 ;; 比较变量 i 和 10
00079 (main.go:4) JLT 33 ;; 跳转到 33 行如果 i < 10
...
- 神奇的指针
当我们在遍历一个数组时,如果获取 range 返回变量的地址并保存到另一个数组或者哈希时,会遇到令人困惑的现象
func main() {
arr := []int{1, 2, 3}
newArr := []*int{}
for _, v := range arr {
newArr = append(newArr, &v)
}
for _, v := range newArr {
fmt.Println(*v)
}
}
$ go run main.go
3 3 3
正确的做法应该是使用 &arr[i] 替代 &v,我们会在下面分析这一现象背后的原因。
- 遍历清空数组
func main() {
arr := []int{1, 2, 3}
for i, _ := range arr {
arr[i] = 0
}
}
依次遍历切片和哈希看起来是非常耗费性能的, 因为数组、切片和哈希占用的内存空间都是连续的,所以最快的方法是直接清空这片内存中的内容,当我们编译上述代码时会得到以下的汇编指令
- 随机遍历
func main() {
hash := map[string]int{
"1": 1,
"2": 2,
"3": 3,
}
for k, v := range hash {
println(k, v)
}
}
每次执行都会不同。
Go 语言在运行时为哈希表的遍历引入了不确定性,也是告诉所有 Go 语言的使用者,程序不要依赖于哈希表的稳定遍历,我们在下面的小节会介绍在遍历的过程是如何引入不确定性的。
经典循环
Go语言中的经典循环在编译器看来是一个OFOR类型的节点。由下面四个部分组成。
初始化循环的 Ninit;
循环的继续条件 Left;
循环体结束时执行的 Right;
循环体 NBody:
for Ninit; Left; Right {
NBody
}

范围循环
编译器会将所有for-range循环 变成经典循环。
将是将ORANGE节点转换成OFOR节点

select
select 是操作系统中的系统调用。 select \ poll \ epoll 等函数构建I/O多路复用模型提升程序的性能。
Go语言的select与操作系统的select比较相似。
C语言的select系统调用可以同时监听读个文件描述符的可读或者可写的状态。
Go语言中的select也能够让Goroutine同时等待多个Channel可读或者可写。
在多个文件或者Channel状态改变之前,select会一直阻塞当前线程或者Goroutine.

select 是与switch相似的控制结构。与switch不同的是,select中虽然也有多个case.但是这些case中的表达式必须都是Channel的收发操作。
func fibonacci(c, quit chan int) {
x, y := 0, 1
for {
select {
case c <- x:
x, y = y, x+y
case <-quit:
fmt.Println("quit")
return
}
}
}
c <- x 或者 <- quit 俩个表达式中任意一个返回,无论哪一个表达式返回,都会立即执行case中的代码。
同时触发,会随机执行其中的一个。
现象
1.select能在Channel上进行非阻塞的收发操作。
2.select在遇到多个Channel同时响应时,会随机执行一种情况。
- 非阻塞的收发
在通常情况下,select语句会阻塞当前Goroutine并等待多个Channel中的一个达到可以收发的状态。
但是如果select语句控制结构中包含 default语句,那么有下列俩种情况
- 当存在可以收发的Channel时,直接处理该Channel对应的case.
- 当不存在可以收发的Channel时,执行default中的语句。
- 随机执行
避免饥饿问题的发生。
数据结构
select 在Go语言的源代码中不存在对应的结构体。使用runtime.scase结构体表示 select在控制结构中的case.
type scase struct {
c *hchan // chan,case中使用的Channel
elem unsafe.Pointer // data element
}
实现原理
select 语句在编译期会被转换成OSELECT节点。
每个OSELECT节点都会持有一组OCASE节点,如果OCASE的执行条件是空,那就是一个default节点。

分析4种情况
select 不存在任何的 case;
select 只存在一个 case;
select 存在两个 case,其中一个 case 是 default;
select 存在多个 case;
- 直接阻塞
select结构中不包含任何case.
func walkselectcases(cases *Nodes) []*Node {
n := cases.Len()
if n == 0 {
return []*Node{mkcall("block", nil, nil)}
}
...
}
select 语句转换成调用runtime.block函数,
func block() {
gopark(nil, nil, waitReasonSelectNoCases, traceEvGoStop, 1)
}
block函数会调用gopark让出当前Goroutine对处理器的使用权,并传入等待原因 waitReasonSelectNoCases.
空的select语句会直接阻塞当前的Goroutine。导致Goroutine进入无法被唤醒的永久休眠状态。
- 单一管道
select条件只包含一个case.
编译器会改写成if条件语句。
// 改写前
select {
case v, ok <-ch: // case ch <- v
...
}
// 改写后
if ch == nil {
block()
}
v, ok := <-ch // case ch <- v
...
在处理单操作select语句时,会根据Channel的收发情况生成不同的语句。当case中的Channel是空指针时,会直接挂起当前Goroutine并陷入永久休眠。
-
非阻塞操作
当select中仅包含2个case.并且其中一个是default.Go语言的编译器会认为这是一次非阻塞的 收发操作。
gc.walkselectcases会对这种情况单独处理,优化之前会将case中的所有Channel都转换成指向Channel的地址。 -
发送
当case中表达式的类型是OSEND时,编译器会使用条件语句和 runtime.selectnbsend函数改写代码。
select {
case ch <- i:
...
default:
...
}
if selectnbsend(ch, i) {
...
} else {
...
}
runtime.selectnbsend ,为我们提供了向Channel非阻塞地发送数据的能力。
我们在Channel一节介绍了向Channel发送数据的runtime.chansend函数包含一个block参数。该参数会决定这一次的发送是不是阻塞的。
func selectnbsend(c *hchan, elem unsafe.Pointer) (selected bool) {
return chansend(c, elem, false, getcallerpc())
}
- 接收
由于从Channel中接收数据可能返回一个或者俩个值,所以接收数据的情况会比发送稍显复杂。
// 改写前
select {
case v <- ch: // case v, ok <- ch:
......
default:
......
}
// 改写后
if selectnbrecv(&v, ch) { // if selectnbrecv2(&v, &ok, ch) {
...
} else {
...
}
返回值数量不同会导致使用不同的函数。
俩个用于非阻塞接收消息的函数。 selectnbrecv 和 selectnbrecv2(对chanrecv返回值的处理稍有不同)
func selectnbrecv(elem unsafe.Pointer, c *hchan) (selected bool) {
selected, _ = chanrecv(c, elem, false)
return
}
func selectnbrecv2(elem unsafe.Pointer, received *bool, c *hchan) (selected bool) {
selected, *received = chanrecv(c, elem, false)
return
}
- 常见流程
- 将所有的case转换成包含Channel以及类型等信息的runtime.scase结构体。
- 调用运行时函数runtime.selectgo从多个准备就绪的Channel中选择一个可执行的runtime.scase结构体。
- 通过for循环生成一组if语句,在语句中判断自己是不是被选中的case.
selv := [3]scase{}
order := [6]uint16
for i, cas := range cases {
c := scase{}
c.kind = ...
c.elem = ...
c.c = ...
}
chosen, revcOK := selectgo(selv, order, 3)
if chosen == 0 {
...
break
}
if chosen == 1 {
...
break
}
if chosen == 2 {
...
break
}
selectgo函数执行过程
- 执行一些必要的初始化操作并确定case的处理顺序。
- 在循环中根据case的类型做出不同的处理。
- 初始化
runtime.selectgo函数首先会执行必要的储户和操作,并决定处理case的俩个顺序- 轮询顺序 pollOrder 和 加锁顺序 lockOrder
func selectgo(cas0 *scase, order0 *uint16, ncases int) (int, bool) {
cas1 := (*[1 << 16]scase)(unsafe.Pointer(cas0))
order1 := (*[1 << 17]uint16)(unsafe.Pointer(order0))
ncases := nsends + nrecvs
scases := cas1[:ncases:ncases]
pollorder := order1[:ncases:ncases]
lockorder := order1[ncases:][:ncases:ncases]
norder := 0
for i := range scases {
cas := &scases[i]
}
for i := 1; i < ncases; i++ {
j := fastrandn(uint32(i + 1))
pollorder[norder] = pollorder[j]
pollorder[j] = uint16(i)
norder++
}
pollorder = pollorder[:norder]
lockorder = lockorder[:norder]
// 根据 Channel 的地址排序确定加锁顺序
...
sellock(scases, lockorder)
...
}
轮询顺序: 通过runtime.fastrandn 函数进入随机性
加锁顺序: 按照Channel的地址排序后确定加锁顺序。
随机的轮询顺序可以便秘Channel的饥饿问题。保证公平性
根据Channel的地址顺序确定加锁顺序能够避免死锁的发生。
- 循环
当我们为select语句锁定了所有Channel之后,就会进入runtime.selectgo函数的主循环,
分 三个阶段查找或者等待某个channel准备就绪。
- 查找是否已经存在准备就绪的Channel。即可以执行收发操作。
- 将当前Goroutine加入Channel对应的收发队列上,并等待其他Goroutine的唤醒。
- 当前Goroutine被唤醒之后找到满足条件的Changnel并进行处理。
runtime.selectgo函数会根据不同情况通过goto语句跳转到函数内部的不同标签执行相应的逻辑,其中包括:
- bufrecv: 可以从缓冲区读取数据
- bufsend: 可以向缓冲区写入数据
- recv: 可以从休眠的发送方获取数据
- send: 可以向休眠的发送方发送数据
- rclose: 可以从关闭的Channel读取EOF
- sclose: 向关闭的Channel发送数据
- retc: 结束调用并返回。
分析第一个阶段:查询已经准备就绪的Channel。循环遍历所有case并找到需要被唤起的runtime.sudog结构。
在这个阶段,我们会根据case的四种类型分别处理
-
当case不包含channel时:会被跳过。
-
当case会从Channel 中接收数据时。
如果当前Channel的sendq上有等待的Goroutine.就会跳到recv标签并从 缓冲区读取数据后将等待的Goroutine中的数据放入到缓冲区中相同的位置。
如果当前Channel的缓冲区不为空,就会跳到bufrecv标签处从缓冲区获取数据。
如果当前Channel已经被关闭,就会跳到rclose做一些清除的收尾工作。 -
当case会向Channel发送数据时
如果当前Channel已经被关闭,就会直接跳到sclose标签,触发panic尝试中止程序。
如果当前channel的recvq上有等待的Goroutine.就会跳到send标签向channel发送数据。
如果当前channel的缓冲区存在空闲位置,就会将发送的数据存入缓冲区。 -
当select语句中包含default时:
表示前面的的所有的case语句都没有被执行。这里会解锁所有channel并返回,意味着当前select结构中的收发都是非阻塞的。
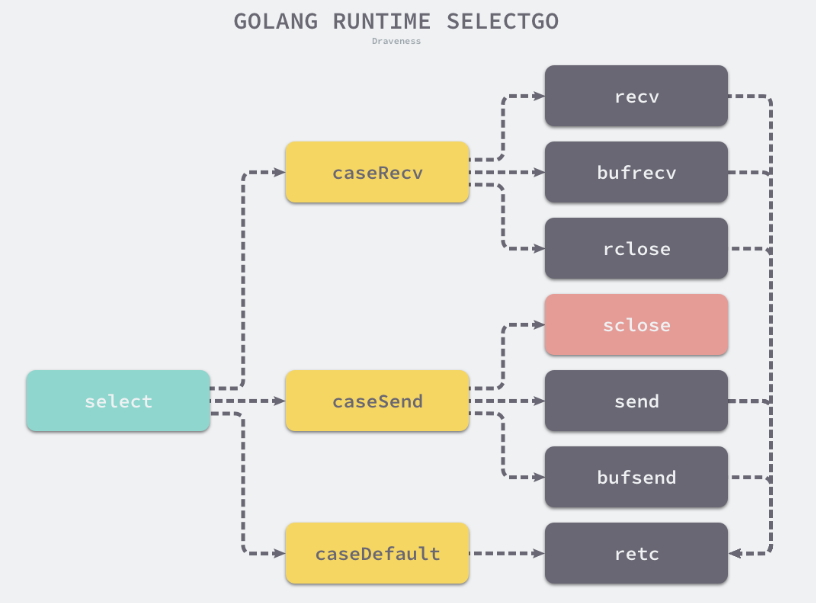
第一阶段的主要职责是查找所有case中是否有可以立刻被处理的Channel. 无论是在等待的Goroutine上还是缓冲区中。
只要存在数据满足条件就会立刻处理。如果不能立刻找到活跃的channel。就会进入循环的下一阶段。
按照需要将当前的goroutine加入到channel的sendq或者recvq队列中。

func selectgo(cas0 *scase, order0 *uint16, ncases int) (int, bool) {
...
gp = getg()
nextp = &gp.waiting
for _, casei := range lockorder {
casi = int(casei)
cas = &scases[casi]
c = cas.c
sg := acquireSudog()
sg.g = gp
sg.c = c
if casi < nsends {
c.sendq.enqueue(sg)
} else {
c.recvq.enqueue(sg)
}
}
gopark(selparkcommit, nil, waitReasonSelect, traceEvGoBlockSelect, 1)
...
}
除了将当前的Goroutine对应的runtime.sudog结构体加入队列之外,这些结构体都会被串成链表附着在Goroutine上。在入队后会调用runtime.gopark挂起当前Goroutine等待调度器的唤醒。
golang select waiting

等待select中的一些Channel准备就绪后,当前Goroutine就会被调度器唤醒。这时会继续执行runtime.selectgo函数的第三部分。从runtime.sudog中读取数据。
func selectgo(cas0 *scase, order0 *uint16, ncases int) (int, bool) {
...
sg = (*sudog)(gp.param)
gp.param = nil
casi = -1
cas = nil
sglist = gp.waiting
for _, casei := range lockorder {
k = &scases[casei]
if sg == sglist {
casi = int(casei)
cas = k
} else {
c = k.c
if int(casei) < nsends {
c.sendq.dequeueSudoG(sglist)
} else {
c.recvq.dequeueSudoG(sglist)
}
}
sgnext = sglist.waitlink
sglist.waitlink = nil
releaseSudog(sglist)
sglist = sgnext
}
c = cas.c
goto retc
...
}
第三次遍历全部case时,我们会获取当前Goroutine接收到的参数 sudog结构。我们会依次对比所有case对应的sudog结构找到被唤醒的case.获取该case对应的索引并返回。
由于当前的select结构找到了一个case执行,那么剩下的case中没有被用到的sudog就会被忽略并且释放掉。为了不影响channel的正常使用。我们还是需要将这些废弃的sudog从channel中出队。
小结
select结构,优化,根据select中case的不同选择不同的优化路径。
四个优化
- 空的 select 语句会被转换成调用 runtime.block 直接挂起当前 Goroutine;
- 如果 select 语句中只包含一个 case,编译器会将其转换成 if ch == nil { block }; n; 表达式;
首先判断操作的 Channel 是不是空的;
然后执行 case 结构中的内容; - 如果 select 语句中只包含两个 case 并且其中一个是 default,那么会使用 runtime.selectnbrecv 和 runtime.selectnbsend 非阻塞地执行收发操作;
在默认情况下会通过 runtime.selectgo 获取执行 case 的索引,并通过多个 if 语句执行对应 case 中的代码; - 在编译器已经对 select 语句进行优化之后,Go 语言会在运行时执行编译期间展开的 runtime.selectgo 函数,该函数会按照以下的流程执行:
运行时3个步骤: - 随机生成一个遍历的轮询顺序 pollOrder 并根据 Channel 地址生成锁定顺序 lockOrder;
- 根据 pollOrder 遍历所有的 case 查看是否有可以立刻处理的 Channel;
如果存在,直接获取 case 对应的索引并返回;
如果不存在,创建 runtime.sudog 结构体,将当前 Goroutine 加入到所有相关 Channel 的收发队列,并调用 runtime.gopark 挂起当前 Goroutine 等待调度器的唤醒; - 当调度器唤醒当前 Goroutine 时,会再次按照 lockOrder 遍历所有的 case,从中查找需要被处理的 runtime.sudog 对应的索引;
defer
defer 会在当前函数返回前 执行 传入的函数。
经常被 用于关闭文件描述符、关闭数据库连接、解锁资源
defer的实现一定是由编译器和运行时 共同完成的。
使用defer的最常见场景是在函数调用结束后完成一些收尾工作。
例如:回滚数据库事务
func createPost(db *gorm.DB) error {
tx := db.Begin()
defer tx.Rollback()
if err := tx.Create(&Post{Author: "Draveness"}).Error; err != nil {
return err
}
return tx.Commit().Error
}
defer 现象
-
defer 关键字的调用时机以及多次调用defer时执行顺序是如何确定的。
-
defer 关键字使用传值的方式 传递参数时会进行预计算,导致不符合预期的结果。
-
作用域
向defer关键字传入的函数会在函数返回之前运行,
假如我们在 for循环中 多次调用 defer关键字
func main() {
for i := 0; i < 5; i++ {
defer fmt.Println(i)
}
}
$ go run main.go
4
3
2
1
0
func main() {
{
defer fmt.Println("defer runs")
fmt.Println("block ends")
}
fmt.Println("main ends")
}
$ go run main.go
block ends
main ends
defer runs
- 预计算参数
GO语言中所有的函数调用都是传值的。
要计算main函数运行的时间:
func main() {
startedAt := time.Now()
defer fmt.Println(time.Since(startedAt))
time.Sleep(time.Second)
}
$ go run main.go
0s
不符合预期,defer关键字会立刻拷贝函数中引用的外部参数。所以time.Since(startedAt)的结果不是在main函数退出之前计算的,而是在defer关键字调用时计算的。导致输出为0s。
解决办法:传入匿名函数
func main() {
startedAt := time.Now()
defer func() { fmt.Println(time.Since(startedAt)) }()
time.Sleep(time.Second)
}
$ go run main.go
1s
虽然调用 defer 关键字时也使用值传递,但是因为拷贝的是函数指针,所以 time.Since(startedAt) 会在 main 函数返回前调用并打印出符合预期的结果。
defer 数据结构
type _defer struct {
siz int32 # 参数和结果的内存大小
started bool
openDefer bool # 是否经过开放编码的优化
sp uintptr # 栈指针
pc uintptr # 调用方的程序计数器
fn *funcval # 传入的函数
_panic *_panic # 触发延迟调用的结构体, 可能为空
link *_defer #
}
runtime._defer结构体是延迟调用链表上的一个元素。所有的结构体都会通过link字段 串联成 链表。

执行机制
gc.state.stmt会负责处理程序中的defer,该函数会根据条件的不同,使用三种不同的机制处理该关键字。
func (s *state) stmt(n *Node) {
...
switch n.Op {
case ODEFER:
if s.hasOpenDefers {
s.openDeferRecord(n.Left) // 开放编码
} else {
d := callDefer // 堆分配
if n.Esc == EscNever {
d = callDeferStack // 栈分配
}
s.callResult(n.Left, d)
}
}
}
堆分配、栈分配和开放编码是处理 defer 关键字的三种方法
堆上分配
堆上分配的runtime._defer 结构体是默认的兜底方案,当方案被启用时,编译器会调用 callResult和 call.这表示 defer在编译器看来也是函数调用。
call 会负责为所有函数和方法调用生成中间代码,工作包括以下内容:
- 获取需要执行的函数名、闭包指针、代码指针、和函数调用的接收方
- 获取栈地址并将函数或者方法的参数写入栈中
- 使用newValue1A以及相关函数生成函数调用的中间代码
- 如果当前调用的函数是defer. 那么会单独生成相关的结束代码块。
- 获取函数的返回值地址并结束当前调用。
func (s *state) call(n *Node, k callKind, returnResultAddr bool) *ssa.Value {
...
var call *ssa.Value
if k == callDeferStack {
// 在栈上初始化 defer 结构体
...
} else {
...
switch {
case k == callDefer:
aux := ssa.StaticAuxCall(deferproc, ACArgs, ACResults) # 调用 deferproc函数,此函数 接收参数的大小和闭包所在的地址俩个参数
call = s.newValue1A(ssa.OpStaticCall, types.TypeMem, aux, s.mem())
...
}
call.AuxInt = stksize
}
s.vars[&memVar] = call
...
}
编译器还会通过三个步骤为所有调用defer的函数末尾插入 deferreturn 的函数调用。
- gc.walkstmt在遇到 ODEFER节点时会执行 sethasdefer(true) 设置当前函数的hasdefer属性。
- buildssa会执行 s.hasdefer = fn.FUnc.HasDefer() 更新 state的hasdefer.
- gc.state.exit会根据state的hasdefer在函数返回之前插入runtime.deferreturn的函数调用。
func (s *state) exit() *ssa.Block {
if s.hasdefer {
...
s.rtcall(Deferreturn, true, nil)
}
...
}
当运行时将 runtime._defer 分配到堆上时,Go 语言的编译器不仅将 defer 转换成了 runtime.deferproc,还在所有调用 defer 的函数结尾插入了 runtime.deferreturn。上述两个运行时函数是 defer 关键字运行时机制的入口,它们分别承担了不同的工作:
runtime.deferproc 负责创建新的延迟调用;
runtime.deferreturn 负责在函数调用结束时执行所有的延迟调用;
- 创建延迟调用
deferproc会为defer创建一个新的runtime._defer结构体,设置它的函数指针 fn、pc、sp.并将相关的参数拷贝到相邻的内存空间中。
func deferproc(siz int32, fn *funcval) {
sp := getcallersp()
argp := uintptr(unsafe.Pointer(&fn)) + unsafe.Sizeof(fn)
callerpc := getcallerpc()
d := newdefer(siz) # 想尽办法 获得 defer结构体。无论使用哪种方式,
# 只要获取到 runtime._defer 结构体,它都会被追加到所在 Goroutine _defer 链表的最前面。
if d._panic != nil {
throw("deferproc: d.panic != nil after newdefer")
}
d.fn = fn
d.pc = callerpc
d.sp = sp
switch siz {
case 0:
case sys.PtrSize:
*(*uintptr)(deferArgs(d)) = *(*uintptr)(unsafe.Pointer(argp))
default:
memmove(deferArgs(d), unsafe.Pointer(argp), uintptr(siz))
}
return0()
}
最后调用的 runtime.return0 是唯一一个不会触发延迟调用的函数,它可以避免递归 runtime.deferreturn 的递归调用

defer 关键字的插入顺序是从后向前的,而 defer 关键字执行是从前向后的,这也是为什么后调用的 defer 会优先执行
- 执行延迟调用
runtime.deferreturn 会从 Goroutine的 defer链表中取出最前面的defer并调用jmpdefer传入需要执行的函数和参数。
func deferreturn(arg0 uintptr) {
gp := getg()
d := gp._defer
if d == nil {
return
}
sp := getcallersp()
...
switch d.siz {
case 0:
case sys.PtrSize:
*(*uintptr)(unsafe.Pointer(&arg0)) = *(*uintptr)(deferArgs(d))
default:
memmove(unsafe.Pointer(&arg0), deferArgs(d), uintptr(d.siz))
}
fn := d.fn
gp._defer = d.link
freedefer(d)
jmpdefer(fn, uintptr(unsafe.Pointer(&arg0))) # 是一个用汇编语言实现的运行时函数
# 跳转到 defer 所在的代码段并在执行结束之后跳转回 runtime.deferreturn。
}
栈上分配
默认情况下,defer结构体都会在堆上分配,如果能够将部分结构体分配到站上就可以节约内存分配带来的额外开销。
当该关键字 在函数 体中最多执行一次时,编译期间的call会将结构体分配到栈上并调用。 deferprocStack:
func (s *state) call(n *Node, k callKind) *ssa.Value {
...
var call *ssa.Value
if k == callDeferStack {
// 在栈上创建 _defer 结构体
t := deferstruct(stksize)
...
ACArgs = append(ACArgs, ssa.Param{Type: types.Types[TUINTPTR], Offset: int32(Ctxt.FixedFrameSize())})
aux := ssa.StaticAuxCall(deferprocStack, ACArgs, ACResults) // 调用 deferprocStack
arg0 := s.constOffPtrSP(types.Types[TUINTPTR], Ctxt.FixedFrameSize())
s.store(types.Types[TUINTPTR], arg0, addr)
call = s.newValue1A(ssa.OpStaticCall, types.TypeMem, aux, s.mem())
call.AuxInt = stksize
} else {
...
}
s.vars[&memVar] = call
...
}
因为在编译期间我们已经创建了 runtime._defer 结构体,所以在运行期间 runtime.deferprocStack 只需要设置一些未在编译期间初始化的字段,就可以将栈上的 runtime._defer 追加到函数的链表上:
除了分配位置的不同,栈上分配和堆上分配的 runtime._defer 并没有本质的不同,而该方法可以适用于绝大多数的场景,与堆上分配的 runtime._defer 相比,该方法可以将 defer 关键字的额外开销降低 ~30%。
开放编码
Open Coded实现defer关键字。该设计使用代码内联优化defer关键的额外开销并引入函数数据 funcdata管理panic的调用。
panic 和 recover
都是go语言的内置函数,提供了互补的功能。

panic 能够改变程序的控制流。调用panic后会立刻停止执行当前函数的剩余代码。并在当前Goroutine中递归执行调用方的 defer.
recover 可以中止panic造成的程序崩溃,它是一个只能在defer中发挥作用的函数,在其他作用域中调用不会发挥作用。
paninc 现象
- panic 只会触发当前Goroutine的defer
- recover只有在 defer中调用才会生效
- panic 允许在defer中嵌套多次调用
跨协程失效
func main() {
defer println("in main")
go func() {
defer println("in goroutine")
panic("")
}()
time.Sleep(1 * time.Second)
}
$ go run main.go
in goroutine
panic:
...
in main并没有打印。 只打印了 in goroutine.

失效的崩溃恢复
func main() {
defer fmt.Println("in main")
if err := recover(); err != nil {
fmt.Println(err)
}
panic("unknown err")
}
$ go run main.go
in main
panic: unknown err
goroutine 1 [running]: # 非正常退出
main.main()
...
exit status 2
recover 只有在panic之后调用才生效,就是要在defer函数中。
嵌套奔溃
panic是可以多次嵌套调用的
func main() {
defer fmt.Println("in main")
defer func() {
defer func() {
panic("panic again and again")
}()
panic("panic again")
}()
panic("panic once")
}
$ go run main.go
in main
panic: panic once
panic: panic again
panic: panic again and again
goroutine 1 [running]:
...
exit status 2
panic 数据结构
runtime._panic 结构体表示。
type _panic struct {
argp unsafe.Pointer # 执行defer调用时参数的指针
arg interface{} # 调用panic时传入的参数
link *_panic # 指向了更早的panic结构
recovered bool # 当前panic是否被recover恢复
aborted bool # 当前的panic是否被强行终止
pc uintptr
sp unsafe.Pointer
goexit bool
}
程序奔溃
编译器会将panic转换成gopanic.该函数的执行过程包3个步骤
- 创建新的panic并添加到Goroutine的panic链表的最前面
- 在循环中 不断从当前的Goroutine的defer中链表获取 defer并调用 reflectcall运行延迟调用函数。
- 调用runtime.fatalpanic中止整个程序。
func gopanic(e interface{}) {
gp := getg()
...
var p _panic
p.arg = e
p.link = gp._panic
gp._panic = (*_panic)(noescape(unsafe.Pointer(&p)))
for {
d := gp._defer
if d == nil {
break
}
d._panic = (*_panic)(noescape(unsafe.Pointer(&p)))
reflectcall(nil, unsafe.Pointer(d.fn), deferArgs(d), uint32(d.siz), uint32(d.siz))
d._panic = nil
d.fn = nil
gp._defer = d.link
freedefer(d)
if p.recovered {
...
}
}
fatalpanic(gp._panic) # 实现了无法被恢复的程序崩溃,它在中止程序之前会通过
*(*int)(nil) = 0
}
需要注意的是,上述函数中省略了三部分比较重要的代码:
- 恢复程序的 recover 分支中的代码;
- 通过内联优化 defer 调用性能的代码3;
runtime: make defers low-cost through inline code and extra funcdata - 修复 runtime.Goexit 异常情况的代码;
runtime.printpanics 打印出全部的 panic 消息以及调用时传入的参数
打印崩溃消息后会调用 runtime.exit 退出当前程序并返回错误码 2,程序的正常退出也是通过 runtime.exit 实现的。
func fatalpanic(msgs *_panic) {
pc := getcallerpc()
sp := getcallersp()
gp := getg()
if startpanic_m() && msgs != nil {
atomic.Xadd(&runningPanicDefers, -1)
printpanics(msgs)
}
if dopanic_m(gp, pc, sp) {
crash()
}
exit(2)
}
崩溃恢复
recover是如何中止程序崩溃的。
编译器会将关键字 recover转换成 runtime.gorecover
func gorecover(argp uintptr) interface{} {
gp := getg()
p := gp._panic
if p != nil && !p.recovered && argp == uintptr(p.argp) {
p.recovered = true
return p.arg
}
return nil
}
该函数的实现很简单,如果当前 Goroutine 没有调用 panic,那么该函数会直接返回 nil,这也是崩溃恢复在非 defer 中调用会失效的原因。在正常情况下,它会修改 runtime._panic 的 recovered 字段,runtime.gorecover 函数中并不包含恢复程序的逻辑,程序的恢复是由 runtime.gopanic 函数负责的:
func gopanic(e interface{}) {
...
for {
// 执行延迟调用函数,可能会设置 p.recovered = true
...
pc := d.pc
sp := unsafe.Pointer(d.sp)
...
if p.recovered {
gp._panic = p.link
for gp._panic != nil && gp._panic.aborted {
gp._panic = gp._panic.link
}
if gp._panic == nil {
gp.sig = 0
}
gp.sigcode0 = uintptr(sp)
gp.sigcode1 = pc
mcall(recovery)
throw("recovery failed")
}
}
...
}
make 和 new
初始化一个结构体,会用到 make和new。
make 的作用 是初始化内置的数据结构, 切片、哈希表 、 channel.
new 的作用 根据传入的类型分配一片内存空间,并返回这片内存空间的指针
slice := make([]int, 0, 100)
hash := make(map[int]bool, 10)
ch := make(chan int, 5)
i := new(int)
var v int
i := &v
new 只能接收类型作为参数 然后返回一个指向该类型的指针

make

在编译期间的类型检查阶段,Go 语言会将代表 make 关键字的 OMAKE 节点根据参数类型的不同转换成了 OMAKESLICE、OMAKEMAP 和 OMAKECHAN 三种不同类型的节点,这些节点会调用不同的运行时函数来初始化相应的数据结构。
new
编译器会在中间代码生成阶段通过以下两个函数处理该关键字
- gc.callnew 会将关键字转换成 ONEWOBJ 类型的节点
- gc.state.exper会根据申请空间的大小分俩种情况处理
- 如果申请的空间为0,就会返回一个表示空指针的 zerobase变量。
- 在遇到其他情况时会将关键字转换成 runtime.newobject函数。
func callnew(t *types.Type) *Node {
...
n := nod(ONEWOBJ, typename(t), nil)
...
return n
}
func (s *state) expr(n *Node) *ssa.Value {
switch n.Op {
case ONEWOBJ:
if n.Type.Elem().Size() == 0 {
return s.newValue1A(ssa.OpAddr, n.Type, zerobaseSym, s.sb)
}
typ := s.expr(n.Left)
vv := s.rtcall(newobject, true, []*types.Type{n.Type}, typ)
return vv[0]
}
}
需要注意的是,无论是直接使用 new,还是使用 var 初始化变量,它们在编译器看来都是 ONEW 和 ODCL 节点。如果变量会逃逸到堆上,这些节点在这一阶段都会被gc.walkstmt 转换成通过 runtime.newobject 函数并在堆上申请内存.
func walkstmt(n *Node) *Node {
switch n.Op {
case ODCL:
v := n.Left
if v.Class() == PAUTOHEAP {
if prealloc[v] == nil {
prealloc[v] = callnew(v.Type)
}
nn := nod(OAS, v.Name.Param.Heapaddr, prealloc[v])
nn.SetColas(true)
nn = typecheck(nn, ctxStmt)
return walkstmt(nn)
}
case ONEW:
if n.Esc == EscNone {
r := temp(n.Type.Elem())
r = nod(OAS, r, nil)
r = typecheck(r, ctxStmt)
init.Append(r)
r = nod(OADDR, r.Left, nil)
r = typecheck(r, ctxExpr)
n = r
} else {
n = callnew(n.Type.Elem())
}
}
}
runtime.newobject 函数会获取传入类型占用空间的大小,调用 runtime.mallocgc 在堆上申请一片内存空间并返回指向这片内存空间的指针:
func newobject(typ *_type) unsafe.Pointer {
return mallocgc(typ.size, typ, true)
}
运行时
上下文Context
Context 是Go语言中用来设置截止日期、同步信号、传递请求相关值得结构体。
上下文与Goroutine有比较密切的 关系,
是Go语言在1.7版本引入标准库的接口。定义了4个需要实现的方法
- Deadline 返回context.Context被取消的时间,也就是完成工作的截止日期
- Done 返回一个Channel.这个Channel会在当前工作完成或者上下文被取消后关闭,多次调用返回同一个Channel.
- Err 返回Context结束的原因。
- 如果被取消,会返回Canceled错误。
- 如果超时,会返回DeadlineExceeded错误。
- Value 从Context中获取键对应的值,对于同一个上下文来说,多次调用Value并传入相同的key.会返回相同的结果。该方法可以用来传递请求特定的数据。
type Context interface {
Deadline() (deadline time.Time, ok bool)
Done() <-chan struct{}
Err() error
Value(key interface{}) interface{}
}
context 包中提供的BackGround、TODO、WithDeadline和WithValue函数会返回实现该接口的私有结构体。
设计原理
在Goroutine构成的树形结构中对信号进行同步以减少计算资源的浪费 是Context的最大作用。
GO服务的每一个请求都是通过单独的Goroutine处理的。http/rpc请求的处理器会启动新的Goroutine访问数据库和其他服务。
会创建多个Goroutine来处理一次请求,Context的作用实在不同Goroutine之间同步请求特定数据、取消信号、处理请求的截止日期

每一个Context都会从最顶层的Goroutine一层一层传递到最下层。
可以在最上层Goroutine执行出现错误时,将信号同步给下层。
创建一个过期时间为1s的上下文。并向上下文传入handle函数,该方法会使用500ms的时间处理传入的请求:
func main() {
ctx, cancel := context.WithTimeout(context.Background(), 1*time.Second)
defer cancel()
go handle(ctx, 500*time.Millisecond)
select {
case <-ctx.Done():
fmt.Println("main", ctx.Err())
}
}
func handle(ctx context.Context, duration time.Duration) {
select {
case <-ctx.Done():
fmt.Println("handle", ctx.Err())
case <-time.After(duration):
fmt.Println("process request with", duration)
}
}
因为过期时间大于处理时间,所以我们有足够的时间处理该请求,该上述代码会打印出下面的内容:
$ go run context.go
process request with 500ms
main context deadline exceeded
handle 函数没有进入超时的select分支,但是main函数的select却会等待Context超时,并打印出 main context deadline exceeded
如果我们将处理请求时间增加是1.5s.整个程序都会因为上下文的过期而被终止。
默认上下文
context包中最常用的方法还是Background、TODO.这俩个方法都会返回预先初始化好的私有变量 background 、 todo.它们会在同一个Go程序中被复用。
func Background() Context {
return background
}
func TODO() Context {
return todo
}
这俩个私有变量都是通过new(emptyCtx)语句初始化的。它们是指向私有结构体context.emptyCtx的指针,
type emptyCtx int
func (*emptyCtx) Deadline() (deadline time.Time, ok bool) {
return
}
func (*emptyCtx) Done() <-chan struct{} {
return nil
}
func (*emptyCtx) Err() error {
return nil
}
func (*emptyCtx) Value(key interface{}) interface{} {
return nil
}
通过空方法实现了Context接口中的所有方法,没有任何功能

取消信号
WithCancel函数能从Context中衍生出一个新的上下文并返回用于取消该上下文的函数。
一旦我们指向返回的取消函数,当前上下文以及他的子上下文都会被取消。多有的Goroutine都会同步收到这一取消信号。

func WithCancel(parent Context) (ctx Context, cancel CancelFunc) {
c := newCancelCtx(parent)
propagateCancel(parent, &c)
return &c, func() { c.cancel(true, Canceled) }
}
同步原语与锁
go语言作为一个原生支持用户态进程Goroutine的语言, 当提到并发编程、多线程编程时。都离不开锁这一概念。
锁是一种并发编程中的同步原语 Synchronization Primitives.
它能保证多个Goroutine在访问同一片内存时不会出现竞争条件 Race Condition.
基本原语
sync.Mutex、sync.RWMutex、sync.WaitGroup、sync.Once和sync.Cond:

- Mutex
type Mutex struct {
state int32 # 当前互斥锁的状态。
sema uint32 # 用于控制锁状态的信号量
}
俩个加起来只占8字节的结构体,表示了go语言中的互斥锁。
- 状态
互斥锁的状态比较复杂,最低三位分别表示mutexLocked、mutexWoken、mutexStarving.
剩下的位置用来表示多少个Goroutine在等待互斥锁的释放
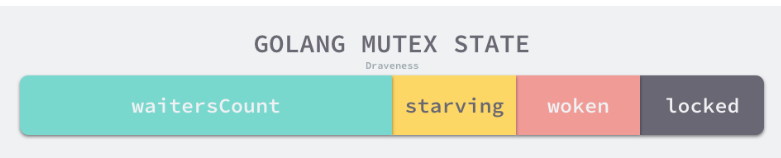

默认情况下,互斥锁的状态位都是0. int32中的不同位分别表示了不同的状态。
1) mutexLocked – 表示互斥锁的锁定状态
2) mutexWoken – 表示从正常模式被从唤醒
3) mutexStarving – 当前的互斥锁进入饥饿状态
4) waitersCount – 当前互斥锁上等待的Goroutine个数。
- 正常模式和饥饿模式
Mutex有俩种模式, 正常模式和饥饿模式,
在正常模式下,锁的 等待者会按照先进先出的顺序获取锁,
但是刚被唤起的Goroutine与新创建的Goroutine竞争时,大概率或获取不到锁,为了减少这种情况的出现。
一旦Goroutine超过1ms没有获取到锁。它就会将当前互斥锁切换饥饿模式,防止部分Goroutine被【饿死】

饥饿模式是1.9中引入的优化,为了保证互斥锁的公平性。
在饥饿模式中,互斥锁会直接交给等待队列最前面的Goroutine.新的Goroutine在该状态下不能获取锁、也不会进入自旋状态。它们只会在队列的末尾等待。
如果一个Goroutine获得了互斥锁并且他在队列的末尾或者他等待的时间少于1ms,那么当前的互斥锁就会切回正常模式。

与饥饿模式相比,正常模式下的互斥锁能够提供更好的性能,
饥饿模式能避免Goroutine由于陷入等待无法获取锁而造成的高尾延时。
- 加锁和解锁
互斥锁的加锁和解锁的过程。
分别使用Mutex.lock和unlock方法。
当锁的状态是0时,将mutexLocked位置成1
func (m *Mutex) Lock() {
if atomic.CompareAndSwapInt32(&m.state, 0, mutexLocked) {
return
}
m.lockSlow()
}
如果互斥锁的状态不是0时,就会调用lockSlow尝试通过自旋 Spinning等方式等待锁的释放。该方法的主题是一个非常大的for循环。
1、判断当前Goroutine能否进入自旋
2、通过自旋等待互斥锁的释放
3、计算互斥锁的最新状态
4、更新互斥锁的状态并 获取锁。
锁是如何判断当前Goroutine能否进入自旋等互斥锁的释放。
func (m *Mutex) lockSlow() {
var waitStartTime int64
starving := false
awoke := false
iter := 0
old := m.state
for {
if old&(mutexLocked|mutexStarving) == mutexLocked && runtime_canSpin(iter) {
if !awoke && old&mutexWoken == 0 && old>>mutexWaiterShift != 0 &&
atomic.CompareAndSwapInt32(&m.state, old, old|mutexWoken) {
awoke = true
}
runtime_doSpin()
iter++
old = m.state
continue
}
自旋是多线程同步机制,当前的进程在进入自旋的过程中会一直保持CPU的占用。
持续检查某个条件是否为真。
在多核的CPU上,自旋可以避免Goroutine的切换。
使用恰当会对性能带来很大的增益。
Goroutine进入自旋的条件非常苛刻。
1.互斥锁只有在普通模式才能进入自旋。
2.runtime.sync_runtime_capSpin需要返回true:
- 运行在多CPU的机器上
2)当前Goroutine为了获取该锁进入自旋的次数小于4次
3)当前机器上至少存在一个正在运行的处理器P 并且处理的运行队列为空
一旦当前Goroutine能够进入自旋就会调用runtime.sync_runtime_doSpin和runtime.procyield并执行30次的PAUS指令。
该指令只会占用CPU并消耗CPU时间。
func sync_runtime_doSpin() {
procyield(active_spin_cnt)
}
TEXT runtime·procyield(SB),NOSPLIT,$0-0
MOVL cycles+0(FP), AX
again:
PAUSE
SUBL $1, AX
JNZ again
RET
处理了自旋相关的特殊逻辑后,互斥锁会根据上下文计算当前互斥锁的最新状态。
几个不同的条件分别会更新state字段中存储的不同信息。
new := old
if old&mutexStarving == 0 {
new |= mutexLocked
}
if old&(mutexLocked|mutexStarving) != 0 {
new += 1 << mutexWaiterShift
}
if starving && old&mutexLocked != 0 {
new |= mutexStarving
}
if awoke {
new &^= mutexWoken
}
计算了新的互斥锁状态之后,会使用 CAS 函数 sync/atomic.CompareAndSwapInt32 更新状态:
if atomic.CompareAndSwapInt32(&m.state, old, new) {
if old&(mutexLocked|mutexStarving) == 0 {
break // 通过 CAS 函数获取了锁
}
...
#如果没有通过 CAS 获得锁,会调用 runtime.sync_runtime_SemacquireMutex 通过信号量保证资源不会被两个 Goroutine 获取。
runtime_SemacquireMutex(&m.sema, queueLifo, 1)
starving = starving || runtime_nanotime()-waitStartTime > starvationThresholdNs
old = m.state
if old&mutexStarving != 0 {
delta := int32(mutexLocked - 1<<mutexWaiterShift)
if !starving || old>>mutexWaiterShift == 1 {
delta -= mutexStarving
}
atomic.AddInt32(&m.state, delta)
break
}
awoke = true
iter = 0
} else {
old = m.state
}
}
}
sync_runtime_SemacquireMutex 会在方法中不断尝试获取锁并陷入休眠等待信号量的释放,一旦当前 Goroutine 可以获取信号量,它就会立刻返回,sync.Mutex.Lock 的剩余代码也会继续执行。
在正常模式下,这段代码会设置唤醒和饥饿标记、重置迭代次数并重新执行获取锁的循环;
在饥饿模式下,当前 Goroutine 会获得互斥锁,如果等待队列中只存在当前 Goroutine,互斥锁还会从饥饿模式中退出;
互斥锁的解锁过程 sync.Mutex.Unlock 与加锁过程相比就很简单,该过程会先使用 sync/atomic.AddInt32 函数快速解锁,这时会发生下面的两种情况:
如果该函数返回的新状态等于 0,当前 Goroutine 就成功解锁了互斥锁;
如果该函数返回的新状态不等于 0,这段代码会调用 sync.Mutex.unlockSlow 开始慢速解锁:
func (m *Mutex) Unlock() {
new := atomic.AddInt32(&m.state, -mutexLocked)
if new != 0 {
m.unlockSlow(new)
}
}
sync.Mutex.unlockSlow 会先校验锁状态的合法性 — 如果当前互斥锁已经被解锁过了会直接抛出异常 “sync: unlock of unlocked mutex” 中止当前程序。
在正常情况下会根据当前互斥锁的状态,分别处理正常模式和饥饿模式下的互斥锁:
func (m *Mutex) unlockSlow(new int32) {
if (new+mutexLocked)&mutexLocked == 0 {
throw("sync: unlock of unlocked mutex")
}
if new&mutexStarving == 0 { // 正常模式
old := new
for {
if old>>mutexWaiterShift == 0 || old&(mutexLocked|mutexWoken|mutexStarving) != 0 {
return
}
new = (old - 1<<mutexWaiterShift) | mutexWoken
if atomic.CompareAndSwapInt32(&m.state, old, new) {
runtime_Semrelease(&m.sema, false, 1)
return
}
old = m.state
}
} else { // 饥饿模式
runtime_Semrelease(&m.sema, true, 1)
}
}
在正常模式下,上述代码会使用如下所示的处理过程:
如果互斥锁不存在等待者或者互斥锁的 mutexLocked、mutexStarving、mutexWoken 状态不都为 0,那么当前方法可以直接返回,不需要唤醒其他等待者;
如果互斥锁存在等待者,会通过 sync.runtime_Semrelease 唤醒等待者并移交锁的所有权;
在饥饿模式下,上述代码会直接调用 sync.runtime_Semrelease 将当前锁交给下一个正在尝试获取锁的等待者,等待者被唤醒后会得到锁,在这时互斥锁还不会退出饥饿状态;
计时器
全局四叉堆
Go 1.10 之前的 计时器 都是 最小四叉堆实现
var timers struct {
lock mutex
gp *g
created bool
sleeping bool
rescheduling bool
sleepUntil int64
waitnote note
t []*timer # 最小四叉堆
}
运行时创建的所有计时器都会加入到四叉堆中
runtime.timerproc Goroutine会运行时间驱动的事件。运行时会在发生以下事件时唤醒计时器
- 四叉堆中的计数器到期
- 四叉堆中加入了触发时间更早的新计时器
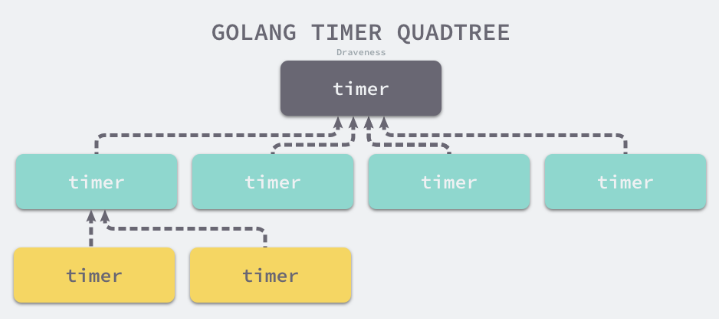

全局四叉堆共用的互斥锁对计时器的影响非常大。
分片四叉堆
1.10 将全局的四叉堆分割成了64个更小的四叉堆。
在理想的情况下,四叉堆的数量应该等于处理器的数量。但是需要实现动态分配的过程。
最终选择初始化64个四叉堆。以牺牲内存占用的代价换取性能的提升。
const timersLen = 64
var timers [timersLen]struct {
timersBucket
}
type timersBucket struct {
lock mutex
gp *g
created bool
sleeping bool
rescheduling bool
sleepUntil int64
waitnote note
t []*timer
}
如果当前机器上的处理器P的个数超过了64,多个处理器上的计时器就可能存储在同一个桶中。
每一个计时器桶 都由一个运行runtime.timerproc函数的Goroutine处理。

网络轮询器
最新版本实现中,计时器桶已被移除,所有的计时器都以最小四叉堆的形式存储在处理器 runtime.p中。

type p struct {
...
timersLock mutex # 用于保护计时器的互斥锁
timers []*timer # 用于存储计时器的最小四叉堆
numTimers uint32 # 计时器中的数量
adjustTimers uint32 # 处于timerModifiedEarlier状态的计时器数量
deletedTimers uint32 # 处于timerDeleted状态的计时器数量
...
}
timer数据结构
type timer struct {
pp puintptr
when int64 # 当前计时器被唤醒的时间
period int64 # 俩次被唤醒的时间间隔
f func(interface{}, uintptr) # 计时器被唤醒都会调用的函数
arg interface{} # 计时器被唤醒是调用f 传入的参数
seq uintptr #
nextwhen int64 # 计时器处于timerModifiedXX状态时,用于设置when字段
status uint32 # 计时器的状态
}
对外暴露的是Timer
type Timer struct {
C <-chan Time
r runtimeTimer
}
状态机
运行时使用状态机的方式处理全部的计时器,其中包括10种状态和几种操作。
由于go语言的计时器支持增删改和重置操作。
| 状态 | 解释 |
|---|---|
| timerNoStatus | 还没有设置状态 |
| timerWaiting | 等待触发 |
| timerRunning | 运行计时器函数 |
| timerDeleted | 被删除 |
| timerRemoving | 正在被删除 |
| timerRemoved | 已经被停止并从堆中删除 |
| timerModifying | 正在被修改 |
| timerModifiedEarlier | 被修改到了更早的时间 |
| timerModifiedLater | 被修改到了更晚的时间 |
| timerMoving | 已经被修改正在被移动 |
Channel
作为Go核心的数据结构和Goroutine之间的通信方式。
Channel是支撑Go语言高性能并发编程模型的重要结构。
Channel设计原理
设计模式:不要通过共享内存的方式进行通信,应该通过通信的方式共享内存。
多线程使用共享内存传递数据

Go语言提供了一种不同的并发模型,即通信顺序进程 Communicating sequential processes CSP.
Goroutine和Channel分别对应CSP中的实体和传递信息的媒介。

俩个Goroutine,一个会向Channel中发送数据,另一个会从Channel中接收数据。
它们俩者能够独立运行并不存在直接关联,通过Channel间接完成通信。
-
先入先出
1) 先从Channel读取数据的Goroutine会先接收到数据
2) 先向Channel发送数据的Goroutine会得到先发送数据的权利 -
无锁管道
锁是一种常见的并发控制技术,我们一般会将锁分成乐观锁和悲观锁。即乐观并发控制和悲观并发控制
无锁 lock-free队列更准确的描述是使用乐观并发控制的队列。
乐观并发控制也叫乐观锁。
乐观锁只是一种并发控制的思想。


乐观并发控制本质上是基于验证的协议,我们使用原子指令 CAS(compare-and-swap 或者 compare-and-set)在多线程中同步数据,无锁队列的实现也依赖这一原子指令
Channel 在运行时的内部表示是 runtime.hchan,该结构体中包含了用于保护成员变量的互斥锁,
Channel 是一个用于同步和通信的有锁队列,使用互斥锁解决程序中可能存在的线程竞争问题是很常见的,我们能很容易地实现有锁队列。
然而锁导致的休眠和唤醒会带来额外的上下文切换,如果临界区过大,加锁解锁导致的额外开销就会成为性能瓶颈。
1994 年的论文 Implementing lock-free queues 就研究了如何使用无锁的数据结构实现先进先出队列,
而 Go 语言社区也在 2014 年提出了无锁 Channel 的实现方案,该方案将 Channel 分成了以下三种类型:
1)同步channel – 不需要缓冲区,发送方会直接将数据 交给 handoff 接收方
2)异步channel – 基于环形缓存的传统生产者消费者模型
3)chan struct{} 类型 的异步Channel – struct{}类型不占用内存 空间。不需要实现缓冲区和直接发送handoff的语义。
Channel数据结构
type hchan struct {
qcount uint # Channel中元素的个数
dataqsiz uint # Channel中循环队列的长度
buf unsafe.Pointer # 缓冲区数据指针
elemsize uint16 # 当前Channel能够收发的元素个数
closed uint32
elemtype *_type # 能够收发的元素类型。
sendx uint # 发送操作处理到的位置
recvx uint # 接收操作处理到的位置
recvq waitq # 由于缓冲区不足而导致阻塞的Goroutine的双向链表
sendq waitq # 由于缓冲区不足而导致阻塞的Goroutine的双向链表
lock mutex
}
type waitq struct {
first *sudog
last *sudog
}
创建管道
使用make关键字。make(chan int, 10) 转换成 OMAKE类型的节点。
并在类型检查阶段将OMAKE类型的节点转换成 OMAKECHAN类型。
func typecheck1(n *Node, top int) (res *Node) {
switch n.Op {
case OMAKE:
...
switch t.Etype {
case TCHAN:
l = nil
if i < len(args) { // 带缓冲区的异步 Channel
...
n.Left = l
} else { // 不带缓冲区的同步 Channel
n.Left = nodintconst(0)
}
n.Op = OMAKECHAN
}
}
}
这一阶段会对传入 make 关键字的缓冲区大小进行检查,如果我们不向 make 传递表示缓冲区大小的参数,
那么就会设置一个默认值 0,也就是当前的 Channel 不存在缓冲区。
OMAKECHAN 类型的节点最终都会在 SSA 中间代码生成阶段之前被转换成调用 runtime.makechan 或者 runtime.makechan64 的函数:
func walkexpr(n *Node, init *Nodes) *Node {
switch n.Op {
case OMAKECHAN:
size := n.Left
fnname := "makechan64"
argtype := types.Types[TINT64]
if size.Type.IsKind(TIDEAL) || maxintval[size.Type.Etype].Cmp(maxintval[TUINT]) <= 0 {
fnname = "makechan"
argtype = types.Types[TINT]
}
n = mkcall1(chanfn(fnname, 1, n.Type), n.Type, init, typename(n.Type), conv(size, argtype))
}
}
runtime.makechan 和 runtime.makechan64 会根据传入的参数类型和缓冲区大小创建一个新的 Channel 结构,
其中后者用于处理缓冲区大小大于 2 的 32 次方的情况,因为这在 Channel 中并不常见,所以我们重点关注 runtime.makechan:
func makechan(t *chantype, size int) *hchan {
elem := t.elem
mem, _ := math.MulUintptr(elem.size, uintptr(size))
var c *hchan
switch {
case mem == 0:
c = (*hchan)(mallocgc(hchanSize, nil, true))
c.buf = c.raceaddr()
case elem.kind&kindNoPointers != 0:
c = (*hchan)(mallocgc(hchanSize+mem, nil, true))
c.buf = add(unsafe.Pointer(c), hchanSize)
default:
c = new(hchan)
c.buf = mallocgc(mem, elem, true)
}
c.elemsize = uint16(elem.size)
c.elemtype = elem
c.dataqsiz = uint(size)
return c
}
根据 Channel 中收发元素的类型和缓冲区的大小初始化 runtime.hchan 和缓冲区:
如果当前 Channel 中不存在缓冲区,那么就只会为 runtime.hchan 分配一段内存空间;
如果当前 Channel 中存储的类型不是指针类型,会为当前的 Channel 和底层的数组分配一块连续的内存空间;
在默认情况下会单独为 runtime.hchan 和缓冲区分配内存;
在函数的最后会统一更新 runtime.hchan 的 elemsize、elemtype 和 dataqsiz 几个字段。
发送数据
向Channel发送数据是,需要使用ch <- i语句,会解析为OSEND节点,并转换成 runtime.chansend1.
chansend1只是调用了chansend,并传入Channel和需要发送的数据。
在发送数据的逻辑执行之前会先为当前 Channel 加锁,防止多个线程并发修改数据。
func chansend(c *hchan, ep unsafe.Pointer, block bool, callerpc uintptr) bool {
lock(&c.lock)
if c.closed != 0 {
unlock(&c.lock)
panic(plainError("send on closed channel"))
}
如果 Channel 已经关闭,那么向该 Channel 发送数据时会报 “send on closed channel” 错误并中止程序。
因为 runtime.chansend 函数的实现比较复杂,所以我们这里将该函数的执行过程分成以下的三个部分:
当存在等待的接收者时,通过 runtime.send 直接将数据发送给阻塞的接收者;
当缓冲区存在空余空间时,将发送的数据写入 Channel 的缓冲区;
当不存在缓冲区或者缓冲区已满时,等待其他 Goroutine 从 Channel 接收数据;
直接发送
如果目标 Channel 没有被关闭并且已经有处于读等待的 Goroutine,那么 runtime.chansend 会从接收队列 recvq 中取出最先陷入等待的 Goroutine 并直接向它发送数据:
if sg := c.recvq.dequeue(); sg != nil {
send(c, sg, ep, func() { unlock(&c.lock) }, 3)
return true
}
接收数据
i <- ch
变成 ORECV 类型的节点,后者会在类型检查阶段被转换成 OAS2RECV 类型。数据的接收操作遵循以下的路线图:

如果当前 Channel 已经被关闭并且缓冲区中不存在任何数据,那么会清除 ep 指针中的数据并立刻返回。
当存在等待的发送者时,通过 runtime.recv 从阻塞的发送者或者缓冲区中获取数据;
当缓冲区存在数据时,从 Channel 的缓冲区中接收数据;
当缓冲区中不存在数据时,等待其他 Goroutine 向 Channel 发送数据;
调度器
线程是操作系统调度时的最基本单元。
而linux在调度器并不区分进程和线程的调度。
大多数线程属于进程。

多个线程可以属于同一个进程并共享内存空间。
因为多线程不需要创建新的虚拟内存空间。
不需要内存管理单元处理上下文的切换,线程之间的通信是基于共享的内存进行的。
每个线程都会占用1M以上的内存空间,在切换线程时不止会消耗较多的内存。恢复寄存器中的内容还需要向操作系统申请或销毁资源。
每一次线程上下文切换都需要销毁1us左右的时间。但是GO调度器对Goroutine的上下文切换约为0.2us.减少了80%的开销。

Go 语言的调度器通过使用与 CPU 数量相等的线程减少线程频繁切换的内存开销,
同时在每一个线程上执行额外开销更低的 Goroutine 来降低操作系统和硬件的负载。
调度器设计原理
- 单线程调度器 0.x
只包含40行代码,只能存在一个活跃线程,由G-M模型组成。 - 多线程调度器 1.0
允许允许多线程的程序,全局锁导致竞争严重。 - 任务窃取调度器 1.1
引入了处理器P.构成了目前的G-M-P模型。在处理器P的基础上实现了基于工作窃取的调度器。
在某些情况下,Goroutine不会让出线程,进而造成饥饿问题。
时间过长的垃圾回收 会导致 程序长时间无法工作 - 抢占式调度器 1.2 – 至今
1) 基于协作的抢占式调度器 1.2 – 1.13
通过编译器在函数调用时插入抢占检查指令,在函数调用时检查当前 Goroutine 是否发起了抢占请求,实现基于协作的抢占式调度;
Goroutine 可能会因为垃圾回收和循环长时间占用资源导致程序暂停;
2)基于信号的抢占式调度器 – 1.14 ~ 至今
实现基于信号的真抢占式调度;
垃圾回收在扫描栈时会触发抢占调度;
抢占的时间点不够多,还不能覆盖全部的边缘情况;
网络轮询器
利用操作系统的I/O多路复用机制。
- I/O模型
操作系统中包含阻塞I/O、非阻塞I/O、信号驱动I/O、异步I/O、I/O多路复用 5种I/O模型。
文件描述符 File Descriptor, FD, 适用于访问文件或者其他I/O资源的抽象句柄。 管道或网络套接字。
不同的I/O模型会使用不同的方式操作文件描述符
- 阻塞I/O
通过read 或者 write系统调用读写文件或者网络时,应用程序会被阻塞。
ssize_t read(int fd, void *buf, size_t count);
ssize_t write(int fd, const void *buf, size_t nbytes);
应用程序会从用户态陷入内核态,内核会检查文件描述符是否可读,当文件描述符中存在数据时,操作系统内核会将准备好的数据拷贝给应用程序,并交回控制权。

- 非阻塞I/O
当进程把一个文件描述符设置成非阻塞时,执行read和write等I/O操作会立刻返回,

第一次从文件描述符中读取数据会触发系统调用并返回ENGAIN错误,ENGAIN意味着该文件描述符还在等待缓冲区中的数据。
随后,应用程序会不断轮询调用read,直到返回值大于0. 这时应用程序就可以对读取操作系统缓冲区中的数据并进行操作
进程在使用非阻塞I/O操作是,可以在等待过程中执行其他任务。提高CPU的利用率
- I/O多路复用
用来处理同一个事件循环中的多个I/O事件。
需要使用特定的系统调用。
select.该函数可以同时监听最多1024个文件描述符的可读或可写状态。
除了标准的select之外,操作系统中还提供了一个比较相似的poll函数。使用链表存储文件描述符,摆脱了1024的数量上限。

多路复用函数会阻塞的监听一组文件描述符,当文件描述符的状态转变为可读或者可写时,select会返回可读或者可写事件的个数。
应用程序可以在输入的文件描述符中查找哪些可读或者可写,然后执行相应的操作。

I/O多路复用模型是效率较高的I/O模型,可以同时阻塞监听一组文件描述符的状态。Redis Nginx都使用的I/O多路复用模型。
- 多模块
Go语言在网络轮询器中使用I/O多路复用模型处理I/O操作。但是没有选择select.
select有较多的限制。
1)监听能力有限- 最多只能监听1024个文件描述符
2)内存拷贝开销大 – 需要维护一个较大的数据结构存储文件描述符,该结构需要拷贝到内核中。
3)时间复杂度O(n) – 返回准备就绪的事件个数后,需要遍历所有的文件描述符。
为了提高I/O多路复用的性能,不同的操作系统也都实现了自己的I/O多路复用函数,例如:epoll, kqueue, evport等。
Go语言为了提高在不同操作系统上的I/O操作性能,使用平台特定的函数实现了多个版本的网络轮询模块。

- 接口
epoll、kqueue、solaries等多路复用模块都要实现以下5个函数,这5个函数构成一个虚拟的接口
func netpollinit()
func netpollopen(fd uintptr, pd *pollDesc) int32
func netpoll(delta int64) gList
func netpollBreak()
func netpollIsPollDescriptor(fd uintptr) bool
netpollinit() : 初始化网络轮询器,通过sync.Once和netpollInited变量保证函数只调用一次。
netpollopen(): 监听文件描述符上的边缘触发事件,创建事件并加入监听
netpoll(): 轮询网络并返回一组已经准备就绪的Goroutine.传入的参数会决定他的行为
如果参数小于0:无限期等待文件描述符就绪
等于0:非阻塞地轮询网络
大于0:阻塞特定事件轮询网络
netpollBreak(): 唤醒网络轮询器,
netpollIsPollDescriptor(): 判断文件描述符是否被轮询器使用。
数据结构
操作系统的I/O多路复用函数会监控文件描述符的可读可写。
Go语言网络轮询器会监听runtime.pollDesc结构体的状态。它会封装操作系统的文件描述符。
type pollDesc struct {
link *pollDesc
lock mutex
fd uintptr
...
rseq uintptr
rg uintptr
rt timer
rd int64
wseq uintptr
wg uintptr
wt timer
wd int64
}
该结构体中包含用于监控可读 和 可写状态的变量。按照功能分成四组。
- resq\wseq: 表示文件描述符被重用或者计时器被重置。
- rg\wg: 表示二进制的信号量,可能为pdReady、pdWait、等待文件描述符可读或者可写的Goroutine、nil
- rd\wd: 等待文件描述符可读或者可写的截止日期
- rt\wt:用于等待文件描述符的计时器
还保存了用于保护数据的互斥锁,文件描述符。
会使用link字段 串联成链表存储在runtime.pollCache中:
type pollCache struct {
lock mutex
first *pollDesc
}

pollCache是运行时包中的全局变量,该结构体包含一个用于保护轮询数据的互斥锁和链表头。
运行时会在第一次调用pollCache.alloc方法初始化总大小约为4KB的pollDesc结构体,
runtime.persistentAlloc会保证这些数据结构初始化在不会触发垃圾回收的内存中。让这些数据结构只能被内部的epoll和kqueue模块引用。
func (c *pollCache) alloc() *pollDesc {
lock(&c.lock)
if c.first == nil {
const pdSize = unsafe.Sizeof(pollDesc{})
n := pollBlockSize / pdSize
if n == 0 {
n = 1
}
mem := persistentalloc(n*pdSize, 0, &memstats.other_sys)
for i := uintptr(0); i < n; i++ {
pd := (*pollDesc)(add(mem, i*pdSize))
pd.link = c.first
c.first = pd
}
}
pd := c.first
c.first = pd.link
unlock(&c.lock)
return pd # 返回链表头还没有被使用的 runtime.pollDesc
}
这种批量初始化的做法能够增加网络轮询器的吞吐量。
Go 语言运行时会调用 runtime.pollCache.free 方法释放已经用完的 runtime.pollDesc 结构,它会直接将结构体插入链表的最前面:
func (c *pollCache) free(pd *pollDesc) {
lock(&c.lock)
pd.link = c.first
c.first = pd
unlock(&c.lock)
}
多路复用
网络轮询器实际上是对I/O多路复用技术的封装,
- 网络轮询器的初始化
- 如何向网络轮询器加入待监控的任务
- 如何从网络轮询器获取触发的事件
上述三个过程包含了网络轮询器相关的方方面面。分析遵循俩个规则。
1.因为不同的I/O多路复用模块的实现大同小异,会使用linux操作系统上的epoll实现。
2.因为处理读事件和写事件类似,省略写事件。
- 初始化
因为文件I/O、网络I/O、计时器都依赖网络轮询器。
有俩条不同路径初始化网络轮询器。
- internal/poll.pollDesc.ini – 通过net.netFD.init和os.newFile初始化网络I/O和文件I/O的轮询时。
- runtime.doaddtimer – 向处理器中增加新的计时器时
网络轮询器的初始化会使用runtime.poll_runtime_pollServerInit和runtime.netpollGenericInit俩个函数。
func poll_runtime_pollServerInit() {
netpollGenericInit()
}
func netpollGenericInit() {
if atomic.Load(&netpollInited) == 0 {
lock(&netpollInitLock)
if netpollInited == 0 {
netpollinit()
atomic.Store(&netpollInited, 1)
}
unlock(&netpollInitLock)
}
}
runtime.netpollGenericInit 会调用平台上特定实现的 runtime.netpollinit,即 Linux 上的 epoll,它主要做了以下几件事情:
是调用 epollcreate1 创建一个新的 epoll 文件描述符,这个文件描述符会在整个程序的生命周期中使用;
通过 runtime.nonblockingPipe 创建一个用于通信的管道;
使用 epollctl 将用于读取数据的文件描述符打包成 epollevent 事件加入监听;
var (
epfd int32 = -1
netpollBreakRd, netpollBreakWr uintptr
)
func netpollinit() {
epfd = epollcreate1(_EPOLL_CLOEXEC)
r, w, _ := nonblockingPipe()
ev := epollevent{
events: _EPOLLIN,
}
*(**uintptr)(unsafe.Pointer(&ev.data)) = &netpollBreakRd
epollctl(epfd, _EPOLL_CTL_ADD, r, &ev)
netpollBreakRd = uintptr(r)
netpollBreakWr = uintptr(w)
}
初始化的管道为我们提供了中断多路复用等待文件描述符中事件的方法。
netpollBreak会向管道中写入数据唤醒epoll.
func netpollBreak() {
for {
var b byte
n := write(netpollBreakWr, unsafe.Pointer(&b), 1)
if n == 1 {
break
}
if n == -_EINTR {
continue
}
if n == -_EAGAIN {
return
}
}
}
因为目前的计时器由网络轮询器管理和触发,它能够让网络轮询器立刻返回并让运行时检查是否有需要触发的计时器。
- 轮询事件
调用pollDesc.init初始化文件描述符时,不止会初始化网络轮询器,还会通过poll_runtime_pollOpen重置轮询信息pollDesc,并调用netpollopen初始化轮询事件。
func poll_runtime_pollOpen(fd uintptr) (*pollDesc, int) {
pd := pollcache.alloc()
lock(&pd.lock)
if pd.wg != 0 && pd.wg != pdReady {
throw("runtime: blocked write on free polldesc")
}
...
pd.fd = fd
pd.closing = false
pd.everr = false
...
pd.wseq++
pd.wg = 0
pd.wd = 0
unlock(&pd.lock)
var errno int32
errno = netpollopen(fd, pd)
return pd, int(errno)
}
runtime.netpollopen 它会调用 epollctl 向全局的轮询文件描述符 epfd 中加入新的轮询事件监听文件描述符的可读和可写状态:
func netpollopen(fd uintptr, pd *pollDesc) int32 {
var ev epollevent
ev.events = _EPOLLIN | _EPOLLOUT | _EPOLLRDHUP | _EPOLLET
*(**pollDesc)(unsafe.Pointer(&ev.data)) = pd
return -epollctl(epfd, _EPOLL_CTL_ADD, int32(fd), &ev)
}
从全局的 epfd 中删除待监听的文件描述符可以使用 runtime.netpollclose,因为该函数的实现与 runtime.netpollopen 比较相似,所以这里不展开分析了。
- 事件循环
- Goroutine让出线程并等待读写事件
- 多路复用等待读写事件的发生并返回
这俩个步骤连接了操作系统中的I/O多路复用机制和Go语言的运行时,在俩个不同的体系之间构建了桥梁。
- 等待事件
在文件描述符上执行读写操作时,如果不可读或者不可写,当前Goroutine会执行poll_runtime_pollWait检查pollDesc的状态,并调用netpollblock等待文件描述符可读或可写
func poll_runtime_pollWait(pd *pollDesc, mode int) int {
...
for !netpollblock(pd, int32(mode), false) {
...
}
return 0
}
func netpollblock(pd *pollDesc, mode int32, waitio bool) bool {
gpp := &pd.rg
if mode == 'w' {
gpp = &pd.wg
}
...
if waitio || netpollcheckerr(pd, mode) == 0 {
gopark(netpollblockcommit, unsafe.Pointer(gpp), waitReasonIOWait, traceEvGoBlockNet, 5)
}
...
}
runtime.netpollblock 是 Goroutine 等待 I/O 事件的关键函数,它会使用运行时提供的 runtime.gopark 让出当前线程,将 Goroutine 转换到休眠状态并等待运行时的唤醒。
- 轮询等待
Go 语言的运行时会在调度或者系统监控中调用 runtime.netpoll 轮询网络,该函数的执行过程可以分成以下几个部分:
- 根据传入的delay计算epoll系统调用需要等待的时间
- 调用epollwait等待可读或者可写事件的发生。
- 在循环中依次处理epollevent事件
func netpoll(delay int64) gList {
var waitms int32
if delay < 0 {
waitms = -1
} else if delay == 0 {
waitms = 0
} else if delay < 1e6 {
waitms = 1
} else if delay < 1e15 {
waitms = int32(delay / 1e6)
} else {
waitms = 1e9
}
计算了需要等待的时间之后,runtime.netpoll 会执行 epollwait 等待文件描述符转换成可读或者可写,如果该函数返回了负值,可能会返回空的 Goroutine 列表或者重新调用 epollwait 陷入等待:
var events [128]epollevent
retry:
n := epollwait(epfd, &events[0], int32(len(events)), waitms)
if n < 0 {
if waitms > 0 {
return gList{}
}
goto retry
}
当 epollwait 系统调用返回的值大于 0 时,意味着被监控的文件描述符出现了待处理的事件,我们在如下所示的循环中会依次处理这些事件:
var toRun gList
for i := int32(0); i < n; i++ {
ev := &events[i]
if *(**uintptr)(unsafe.Pointer(&ev.data)) == &netpollBreakRd {
...
continue
}
var mode int32
if ev.events&(_EPOLLIN|_EPOLLRDHUP|_EPOLLHUP|_EPOLLERR) != 0 {
mode += 'r'
}
...
if mode != 0 {
pd := *(**pollDesc)(unsafe.Pointer(&ev.data))
pd.everr = false
netpollready(&toRun, pd, mode)
}
}
return toRun
}
处理的事件总共包含两种,一种是调用 runtime.netpollBreak 触发的事件,该函数的作用是中断网络轮询器;另一种是其他文件描述符的正常读写事件,对于这些事件,我们会交给
7.3 栈内存管理
第四部分 进阶内容
第八章 元编程
8.1 插件系统
8.2 代码生成
第九章 标准库
9.1 JSON
9.2 HTTP
9.3 数据库
6.6 网络轮询器 #
各位读者朋友,很高兴大家通过本博客学习 Go 语言,感谢一路相伴!《Go语言设计与实现》的纸质版图书已经上架京东,有需要的朋友请点击 链接 购买。
在今天,大部分的服务都是 I/O 密集型的,应用程序会花费大量时间等待 I/O 操作的完成。网络轮询器是 Go 语言运行时用来处理 I/O 操作的关键组件,它使用了操作系统提供的 I/O 多路复用机制增强程序的并发处理能力。本节会深入分析 Go 语言网络轮询器的设计与实现原理。
6.6.1 设计原理 #
网络轮询器不仅用于监控网络 I/O,还能用于监控文件的 I/O,它利用了操作系统提供的 I/O 多路复用模型来提升 I/O 设备的利用率以及程序的性能。本节会分别介绍常见的几种 I/O 模型以及 Go 语言运行时的网络轮询器如何使用多模块设计在不同的操作系统上支持多路复用。
I/O 模型 #
操作系统中包含阻塞 I/O、非阻塞 I/O、信号驱动 I/O 与异步 I/O 以及 I/O 多路复用五种 I/O 模型。我们在本节中会介绍上述五种模型中的三种:
阻塞 I/O 模型;
非阻塞 I/O 模型;
I/O 多路复用模型;
在 Unix 和类 Unix 操作系统中,文件描述符(File descriptor,FD)是用于访问文件或者其他 I/O 资源的抽象句柄,例如:管道或者网络套接字1。而不同的 I/O 模型会使用不同的方式操作文件描述符。
阻塞 I/O #
阻塞 I/O 是最常见的 I/O 模型,在默认情况下,当我们通过 read 或者 write 等系统调用读写文件或者网络时,应用程序会被阻塞:
ssize_t read(int fd, void *buf, size_t count);
ssize_t write(int fd, const void *buf, size_t nbytes);
C
如下图所示,当我们执行 read 系统调用时,应用程序会从用户态陷入内核态,内核会检查文件描述符是否可读;当文件描述符中存在数据时,操作系统内核会将准备好的数据拷贝给应用程序并交回控制权。
blocking-io-mode
图 6-39 阻塞 I/O 模型
操作系统中多数的 I/O 操作都是如上所示的阻塞请求,一旦执行 I/O 操作,应用程序会陷入阻塞等待 I/O 操作的结束。
非阻塞 I/O #
当进程把一个文件描述符设置成非阻塞时,执行 read 和 write 等 I/O 操作会立刻返回。在 C 语言中,我们可以使用如下所示的代码片段将一个文件描述符设置成非阻塞的:
int flags = fcntl(fd, F_GETFL, 0);
fcntl(fd, F_SETFL, flags | O_NONBLOCK);
C
在上述代码中,最关键的就是系统调用 fcntl 和参数 O_NONBLOCK,fcntl 为我们提供了操作文件描述符的能力,我们可以通过它修改文件描述符的特性。当我们将文件描述符修改成非阻塞后,读写文件会经历以下流程:
non-blocking-io-mode
图 6-40 非阻塞 I/O 模型
第一次从文件描述符中读取数据会触发系统调用并返回 EAGAIN 错误,EAGAIN 意味着该文件描述符还在等待缓冲区中的数据;随后,应用程序会不断轮询调用 read 直到它的返回值大于 0,这时应用程序就可以对读取操作系统缓冲区中的数据并进行操作。进程使用非阻塞的 I/O 操作时,可以在等待过程中执行其他任务,提高 CPU 的利用率。
I/O 多路复用 #
I/O 多路复用被用来处理同一个事件循环中的多个 I/O 事件。I/O 多路复用需要使用特定的系统调用,最常见的系统调用是 select,该函数可以同时监听最多 1024 个文件描述符的可读或者可写状态:
int select(int nfds, fd_set *restrict readfds, fd_set *restrict writefds, fd_set *restrict errorfds, struct timeval *restrict timeout);
C
除了标准的 select 之外,操作系统中还提供了一个比较相似的 poll 函数,它使用链表存储文件描述符,摆脱了 1024 的数量上限。
io-multiplexing
图 6-41 I/O 多路复用函数监听文件描述符
多路复用函数会阻塞的监听一组文件描述符,当文件描述符的状态转变为可读或者可写时,select 会返回可读或者可写事件的个数,应用程序可以在输入的文件描述符中查找哪些可读或者可写,然后执行相应的操作。
io-multiplexing-mode
图 6-42 I/O 多路复用模型
I/O 多路复用模型是效率较高的 I/O 模型,它可以同时阻塞监听了一组文件描述符的状态。很多高性能的服务和应用程序都会使用这一模型来处理 I/O 操作,例如:Redis 和 Nginx 等。
多模块 #
Go 语言在网络轮询器中使用 I/O 多路复用模型处理 I/O 操作,但是他没有选择最常见的系统调用 select2。虽然 select 也可以提供 I/O 多路复用的能力,但是使用它有比较多的限制:
监听能力有限 — 最多只能监听 1024 个文件描述符;
内存拷贝开销大 — 需要维护一个较大的数据结构存储文件描述符,该结构需要拷贝到内核中;
时间复杂度 O(n) — 返回准备就绪的事件个数后,需要遍历所有的文件描述符;
为了提高 I/O 多路复用的性能,不同的操作系统也都实现了自己的 I/O 多路复用函数,例如:epoll、kqueue 和 evport 等。Go 语言为了提高在不同操作系统上的 I/O 操作性能,使用平台特定的函数实现了多个版本的网络轮询模块:
src/runtime/netpoll_epoll.go
src/runtime/netpoll_kqueue.go
src/runtime/netpoll_solaris.go
src/runtime/netpoll_windows.go
src/runtime/netpoll_aix.go
src/runtime/netpoll_fake.go
这些模块在不同平台上实现了相同的功能,构成了一个常见的树形结构。编译器在编译 Go 语言程序时,会根据目标平台选择树中特定的分支进行编译:
netpoll-modules
图 6-43 多模块网络轮询器
如果目标平台是 Linux,那么就会根据文件中的 // +build linux 编译指令选择 src/runtime/netpoll_epoll.go 并使用 epoll 函数处理用户的 I/O 操作。
接口 #
epoll、kqueue、solaries 等多路复用模块都要实现以下五个函数,这五个函数构成一个虚拟的接口:
func netpollinit()
func netpollopen(fd uintptr, pd *pollDesc) int32
func netpoll(delta int64) gList
func netpollBreak()
func netpollIsPollDescriptor(fd uintptr) bool
Go
上述函数在网络轮询器中分别扮演了不同的作用:
runtime.netpollinit — 初始化网络轮询器,通过 sync.Once 和 netpollInited 变量保证函数只会调用一次;
runtime.netpollopen — 监听文件描述符上的边缘触发事件,创建事件并加入监听;
runtime.netpoll — 轮询网络并返回一组已经准备就绪的 Goroutine,传入的参数会决定它的行为3;
如果参数小于 0,无限期等待文件描述符就绪;
如果参数等于 0,非阻塞地轮询网络;
如果参数大于 0,阻塞特定时间轮询网络;
runtime.netpollBreak — 唤醒网络轮询器,例如:计时器向前修改时间时会通过该函数中断网络轮询器4;
runtime.netpollIsPollDescriptor — 判断文件描述符是否被轮询器使用;
我们在这里只需要了解多路复用模块中的几个函数,本节的后半部分会详细分析它们的实现原理。
6.6.2 数据结构 #
操作系统中 I/O 多路复用函数会监控文件描述符的可读或者可写,而 Go 语言网络轮询器会监听 runtime.pollDesc 结构体的状态,它会封装操作系统的文件描述符:
type pollDesc struct {
link *pollDesc
lock mutex
fd uintptr
...
rseq uintptr
rg uintptr
rt timer
rd int64
wseq uintptr
wg uintptr
wt timer
wd int64
}
Go
该结构体中包含用于监控可读和可写状态的变量,我们按照功能将它们分成以下四组:
rseq 和 wseq — 表示文件描述符被重用或者计时器被重置5;
rg 和 wg — 表示二进制的信号量,可能为 pdReady、pdWait、等待文件描述符可读或者可写的 Goroutine 以及 nil;
rd 和 wd — 等待文件描述符可读或者可写的截止日期;
rt 和 wt — 用于等待文件描述符的计时器;
除了上述八个变量之外,该结构体中还保存了用于保护数据的互斥锁、文件描述符。runtime.pollDesc 结构体会使用 link 字段串联成链表存储在 runtime.pollCache 中:
type pollCache struct {
lock mutex
first *pollDesc
}
Go
runtime.pollCache 是运行时包中的全局变量,该结构体中包含一个用于保护轮询数据的互斥锁和链表头:
poll-desc-list
图 6-44 轮询缓存链表
运行时会在第一次调用 runtime.pollCache.alloc 方法时初始化总大小约为 4KB 的 runtime.pollDesc 结构体,runtime.persistentAlloc 会保证这些数据结构初始化在不会触发垃圾回收的内存中,让这些数据结构只能被内部的 epoll 和 kqueue 模块引用:
func (c pollCache) alloc() pollDesc {
lock(&c.lock)
if c.first == nil {
const pdSize = unsafe.Sizeof(pollDesc{})
n := pollBlockSize / pdSize
if n == 0 {
n = 1
}
mem := persistentalloc(npdSize, 0, &memstats.other_sys)
for i := uintptr(0); i < n; i++ {
pd := (pollDesc)(add(mem, i*pdSize))
pd.link = c.first
c.first = pd
}
}
pd := c.first
c.first = pd.link
unlock(&c.lock)
return pd
}
Go
每次调用该结构体都会返回链表头还没有被使用的 runtime.pollDesc,这种批量初始化的做法能够增加网络轮询器的吞吐量。Go 语言运行时会调用 runtime.pollCache.free 方法释放已经用完的 runtime.pollDesc 结构,它会直接将结构体插入链表的最前面:
func (c *pollCache) free(pd *pollDesc) {
lock(&c.lock)
pd.link = c.first
c.first = pd
unlock(&c.lock)
}
Go
上述方法没有重置 runtime.pollDesc 结构体中的字段,该结构体被重复利用时才会由 runtime.poll_runtime_pollOpen 函数重置。
6.6.3 多路复用 #
网络轮询器实际上是对 I/O 多路复用技术的封装,本节将通过以下的三个过程分析网络轮询器的实现原理:
网络轮询器的初始化;
如何向网络轮询器加入待监控的任务;
如何从网络轮询器获取触发的事件;
上述三个过程包含了网络轮询器相关的方方面面,能够让我们对其实现有完整的理解。需要注意的是,我们在分析实现时会遵循以下两个规则:
因为不同 I/O 多路复用模块的实现大同小异,本节会使用 Linux 操作系统上的 epoll 实现;
因为处理读事件和写事件的逻辑类似,本节会省略写事件相关的代码;
初始化 #
因为文件 I/O、网络 I/O 以及计时器都依赖网络轮询器,所以 Go 语言会通过以下两条不同路径初始化网络轮询器:
internal/poll.pollDesc.init — 通过 net.netFD.init 和 os.newFile 初始化网络 I/O 和文件 I/O 的轮询信息时;
runtime.doaddtimer — 向处理器中增加新的计时器时;
网络轮询器的初始化会使用 runtime.poll_runtime_pollServerInit 和 runtime.netpollGenericInit 两个函数:
func poll_runtime_pollServerInit() {
netpollGenericInit()
}
func netpollGenericInit() {
if atomic.Load(&netpollInited) == 0 {
lock(&netpollInitLock)
if netpollInited == 0 {
netpollinit()
atomic.Store(&netpollInited, 1)
}
unlock(&netpollInitLock)
}
}
Go
runtime.netpollGenericInit 会调用平台上特定实现的 runtime.netpollinit,即 Linux 上的 epoll,它主要做了以下几件事情:
是调用 epollcreate1 创建一个新的 epoll 文件描述符,这个文件描述符会在整个程序的生命周期中使用;
通过 runtime.nonblockingPipe 创建一个用于通信的管道;
使用 epollctl 将用于读取数据的文件描述符打包成 epollevent 事件加入监听;
var (
epfd int32 = -1
netpollBreakRd, netpollBreakWr uintptr
)
func netpollinit() {
epfd = epollcreate1(_EPOLL_CLOEXEC)
r, w, _ := nonblockingPipe()
ev := epollevent{
events: _EPOLLIN,
}
*(**uintptr)(unsafe.Pointer(&ev.data)) = &netpollBreakRd
epollctl(epfd, _EPOLL_CTL_ADD, r, &ev)
netpollBreakRd = uintptr(r)
netpollBreakWr = uintptr(w)
}
Go
初始化的管道为我们提供了中断多路复用等待文件描述符中事件的方法,runtime.netpollBreak 会向管道中写入数据唤醒 epoll:
func netpollBreak() {
for {
var b byte
n := write(netpollBreakWr, unsafe.Pointer(&b), 1)
if n == 1 {
break
}
if n == -_EINTR {
continue
}
if n == -_EAGAIN {
return
}
}
}
Go
因为目前的计时器由网络轮询器管理和触发,它能够让网络轮询器立刻返回并让运行时检查是否有需要触发的计时器。
轮询事件 #
调用 internal/poll.pollDesc.init 初始化文件描述符时不止会初始化网络轮询器,还会通过 runtime.poll_runtime_pollOpen 重置轮询信息 runtime.pollDesc 并调用 runtime.netpollopen 初始化轮询事件:
func poll_runtime_pollOpen(fd uintptr) (*pollDesc, int) {
pd := pollcache.alloc()
lock(&pd.lock)
if pd.wg != 0 && pd.wg != pdReady {
throw(“runtime: blocked write on free polldesc”)
}
…
pd.fd = fd
pd.closing = false
pd.everr = false
…
pd.wseq++
pd.wg = 0
pd.wd = 0
unlock(&pd.lock)
var errno int32
errno = netpollopen(fd, pd)
return pd, int(errno)
}
Go
runtime.netpollopen 的实现非常简单,它会调用 epollctl 向全局的轮询文件描述符 epfd 中加入新的轮询事件监听文件描述符的可读和可写状态:
func netpollopen(fd uintptr, pd *pollDesc) int32 {
var ev epollevent
ev.events = _EPOLLIN | _EPOLLOUT | _EPOLLRDHUP | _EPOLLET
*(**pollDesc)(unsafe.Pointer(&ev.data)) = pd
return -epollctl(epfd, _EPOLL_CTL_ADD, int32(fd), &ev)
}
Go
从全局的 epfd 中删除待监听的文件描述符可以使用 runtime.netpollclose,因为该函数的实现与 runtime.netpollopen 比较相似,所以这里不展开分析了。
事件循环 #
本节将继续介绍网络轮询器的核心逻辑,也就是事件循环。我们将从以下的两个部分介绍事件循环的实现原理:
Goroutine 让出线程并等待读写事件;
多路复用等待读写事件的发生并返回;
上述过程连接了操作系统中的 I/O 多路复用机制和 Go 语言的运行时,在两个不同体系之间构建了桥梁,我们将分别介绍上述的两个过程。
等待事件 #
当我们在文件描述符上执行读写操作时,如果文件描述符不可读或者不可写,当前 Goroutine 会执行 runtime.poll_runtime_pollWait 检查 runtime.pollDesc 的状态并调用 runtime.netpollblock 等待文件描述符的可读或者可写:
func poll_runtime_pollWait(pd *pollDesc, mode int) int {
…
for !netpollblock(pd, int32(mode), false) {
…
}
return 0
}
func netpollblock(pd *pollDesc, mode int32, waitio bool) bool {
gpp := &pd.rg
if mode == ‘w’ {
gpp = &pd.wg
}
…
if waitio || netpollcheckerr(pd, mode) == 0 {
gopark(netpollblockcommit, unsafe.Pointer(gpp), waitReasonIOWait, traceEvGoBlockNet, 5)
}
…
}
Go
runtime.netpollblock 是 Goroutine 等待 I/O 事件的关键函数,它会使用运行时提供的 runtime.gopark 让出当前线程,将 Goroutine 转换到休眠状态并等待运行时的唤醒。
轮询等待 #
Go 语言的运行时会在调度或者系统监控中调用 runtime.netpoll 轮询网络,该函数的执行过程可以分成以下几个部分:
根据传入的 delay 计算 epoll 系统调用需要等待的时间;
调用 epollwait 等待可读或者可写事件的发生;
在循环中依次处理 epollevent 事件;
因为传入 delay 的单位是纳秒,下面这段代码会将纳秒转换成毫秒:
func netpoll(delay int64) gList {
var waitms int32
if delay < 0 {
waitms = -1
} else if delay == 0 {
waitms = 0
} else if delay < 1e6 {
waitms = 1
} else if delay < 1e15 {
waitms = int32(delay / 1e6)
} else {
waitms = 1e9
}
Go
计算了需要等待的时间之后,runtime.netpoll 会执行 epollwait 等待文件描述符转换成可读或者可写,如果该函数返回了负值,可能会返回空的 Goroutine 列表或者重新调用 epollwait 陷入等待:
var events [128]epollevent
retry:
n := epollwait(epfd, &events[0], int32(len(events)), waitms)
if n < 0 {
if waitms > 0 {
return gList{}
}
goto retry
}
Go
当 epollwait 系统调用返回的值大于 0 时,意味着被监控的文件描述符出现了待处理的事件,我们在如下所示的循环中会依次处理这些事件:
var toRun gList
for i := int32(0); i < n; i++ {
ev := &events[i]
if *(**uintptr)(unsafe.Pointer(&ev.data)) == &netpollBreakRd {
...
continue
}
var mode int32
if ev.events&(_EPOLLIN|_EPOLLRDHUP|_EPOLLHUP|_EPOLLERR) != 0 {
mode += 'r'
}
...
if mode != 0 {
pd := *(**pollDesc)(unsafe.Pointer(&ev.data))
pd.everr = false
netpollready(&toRun, pd, mode)
}
}
return toRun
}
Go
处理的事件总共包含两种,一种是调用 runtime.netpollBreak 触发的事件,该函数的作用是中断网络轮询器;另一种是其他文件描述符的正常读写事件,对于这些事件,我们会交给 runtime.netpollready 处理:
func netpollready(toRun *gList, pd *pollDesc, mode int32) {
var rg, wg *g
...
if mode == 'w' || mode == 'r'+'w' {
wg = netpollunblock(pd, 'w', true)
}
...
if wg != nil {
toRun.push(wg)
}
}
runtime.netpollunblock 会在读写事件发生时,将 runtime.pollDesc 中的读或者写信号量转换成 pdReady 并返回其中存储的 Goroutine;如果返回的 Goroutine 不会为空,那么运行时会将该 Goroutine 会加入 toRun 列表,并将列表中的全部 Goroutine 加入运行队列并等待调度器的调度。
runtime.netpoll 返回的 Goroutine 列表都会被 runtime.injectglist 注入到处理器或者全局的运行队列上。因为系统监控 Goroutine 直接运行在线程上,所以它获取的 Goroutine 列表会直接加入全局的运行队列,其他 Goroutine 获取的列表都会加入 Goroutine 所在处理器的运行队列上。
- 截止日期
网络轮询器和计时器的关系非常紧密,这不仅仅是因为网络轮询器负责计时器的唤醒,还因为文件和网络 I/O 的截止日期也由网络轮询器负责处理。截止日期在 I/O 操作中,尤其是网络调用中很关键,网络请求存在很高的不确定因素,我们需要设置一个截止日期保证程序的正常运行,这时需要用到网络轮询器中的 runtime.poll_runtime_pollSetDeadline:
func poll_runtime_pollSetDeadline(pd *pollDesc, d int64, mode int) {
rd0, wd0 := pd.rd, pd.wd
if d > 0 {
d += nanotime()
}
pd.rd = d
...
if pd.rt.f == nil {
if pd.rd > 0 {
pd.rt.f = netpollReadDeadline
pd.rt.arg = pd
pd.rt.seq = pd.rseq
resettimer(&pd.rt, pd.rd)
}
} else if pd.rd != rd0 {
pd.rseq++
if pd.rd > 0 {
modtimer(&pd.rt, pd.rd, 0, rtf, pd, pd.rseq)
} else {
deltimer(&pd.rt)
pd.rt.f = nil
}
}
该函数会先使用截止日期计算出过期的时间点,然后根据 runtime.pollDesc 的状态做出以下不同的处理:
如果结构体中的计时器没有设置执行的函数时,该函数会设置计时器到期后执行的函数、传入的参数并调用 runtime.resettimer 重置计时器;
如果结构体的读截止日期已经被改变,我们会根据新的截止日期做出不同的处理:
如果新的截止日期大于 0,调用 runtime.modtimer 修改计时器;
如果新的截止日期小于 0,调用 runtime.deltimer 删除计时器;
在 runtime.poll_runtime_pollSetDeadline 的最后,会重新检查轮询信息中存储的截止日期:
var rg *g
if pd.rd < 0 {
if pd.rd < 0 {
rg = netpollunblock(pd, 'r', false)
}
...
}
if rg != nil {
netpollgoready(rg, 3)
}
...
}
如果截止日期小于 0,上述代码会调用 runtime.netpollgoready 直接唤醒对应的 Goroutine。
系统监控
很多系统都有守护进程,它们能够在后天监控系统的运行状态,在出现意外时及时响应。
系统监控是Go语言运行时的重要组成部分。它会每隔一段时间检查Go语言运行时,确保程序没有进入异常状态。
设计原理
在支持多任务的操作系统中,守护进程是在后台运行的计算机程序,它不会由用户直接操作。
一般会在操作系统启动时自动运行。 k8s的DaemonSet和Go语言的系统监控都使用类似设计提供一些通用的功能。

守护进程是很有效的设计,它在整个系统的生命周期中都会存在,会随着系统的启动而启动,系统的结束而结束。在操作系统和 Kubernetes 中,我们经常会将数据库服务、日志服务以及监控服务等进程作为守护进程运行。
Go 语言的系统监控也起到了很重要的作用,它在内部启动了一个不会中止的循环,在循环的内部会轮询网络、抢占长期运行或者处于系统调用的 Goroutine 以及触发垃圾回收,通过这些行为,它能够让系统的运行状态变得更健康。
监控循环
当 Go 语言程序启动时,运行时会在第一个 Goroutine 中调用 runtime.main 启动主程序,该函数会在系统栈中创建新的线程:
func main() {
...
if GOARCH != "wasm" {
systemstack(func() {
newm(sysmon, nil)
})
}
...
}
runtime.newm 会创建一个存储待执行函数和处理器的新结构体 runtime.m。运行时执行系统监控不需要处理器,系统监控的 Goroutine 会直接在创建的线程上运行:
func newm(fn func(), _p_ *p) {
mp := allocm(_p_, fn)
mp.nextp.set(_p_)
mp.sigmask = initSigmask
...
newm1(mp)
}
runtime.newm1 会调用特定平台的 runtime.newosproc通过系统调用 clone 创建一个新的线程并在新的线程中执行 runtime.mstart:
func newosproc(mp *m) {
stk := unsafe.Pointer(mp.g0.stack.hi)
var oset sigset
sigprocmask(_SIG_SETMASK, &sigset_all, &oset)
ret := clone(cloneFlags, stk, unsafe.Pointer(mp), unsafe.Pointer(mp.g0), unsafe.Pointer(funcPC(mstart)))
sigprocmask(_SIG_SETMASK, &oset, nil)
...
}
在新创建的线程中,我们会执行存储在 runtime.m 中的 runtime.sysmon 启动系统监控:
func sysmon() {
sched.nmsys++
checkdead()
lasttrace := int64(0)
idle := 0
delay := uint32(0)
for {
if idle == 0 {
delay = 20
} else if idle > 50 {
delay *= 2
}
if delay > 10*1000 {
delay = 10 * 1000
}
usleep(delay)
...
}
}
当运行时刚刚调用上述函数时,会先通过 runtime.checkdead 检查是否存在死锁,然后进入核心的监控循环;系统监控在每次循环开始时都会通过 usleep 挂起当前线程,该函数的参数是微秒,运行时会遵循以下的规则决定休眠时间
初始的休眠时间是 20μs;
最长的休眠时间是 10ms;
当系统监控在 50 个循环中都没有唤醒 Goroutine 时,休眠时间在每个循环都会倍增;
当程序趋于稳定之后,系统监控的触发时间就会稳定在 10ms。它除了会检查死锁之外,还会在循环中完成以下的工作:
运行计时器 — 获取下一个需要被触发的计时器;
轮询网络 — 获取需要处理的到期文件描述符;
抢占处理器 — 抢占运行时间较长的或者处于系统调用的 Goroutine;
垃圾回收 — 在满足条件时触发垃圾收集回收内存;
- 检查死锁
系统监控通过 runtime.checkdead 检查运行时是否发生了死锁,我们可以将检查死锁的过程分成以下三个步骤:
检查是否存在正在运行的线程;
检查是否存在正在运行的 Goroutine;
检查处理器上是否存在计时器;
该函数首先会检查 Go 语言运行时中正在运行的线程数量,我们通过调度器中的多个字段计算该值的结果:
func checkdead() {
var run0 int32
run := mcount() - sched.nmidle - sched.nmidlelocked - sched.nmsys
if run > run0 {
return
}
if run < 0 {
print("runtime: checkdead: nmidle=", sched.nmidle, " nmidlelocked=", sched.nmidlelocked, " mcount=", mcount(), " nmsys=", sched.nmsys, "\n")
throw("checkdead: inconsistent counts")
}
...
}
runtime.mcount 根据下一个待创建的线程 id 和释放的线程数得到系统中存在的线程数;
nmidle 是处于空闲状态的线程数量;
nmidlelocked 是处于锁定状态的线程数量;
nmsys 是处于系统调用的线程数量;
利用上述几个线程相关数据,我们可以得到正在运行的线程数,如果线程数量大于 0,说明当前程序不存在死锁;如果线程数小于 0,说明当前程序的状态不一致;如果线程数等于 0,我们需要进一步检查程序的运行状态:
func checkdead() {
...
grunning := 0
for i := 0; i < len(allgs); i++ {
gp := allgs[i]
if isSystemGoroutine(gp, false) {
continue
}
s := readgstatus(gp)
switch s &^ _Gscan {
case _Gwaiting, _Gpreempted:
grunning++
case _Grunnable, _Grunning, _Gsyscall:
print("runtime: checkdead: find g ", gp.goid, " in status ", s, "\n")
throw("checkdead: runnable g")
}
}
unlock(&allglock)
if grunning == 0 {
throw("no goroutines (main called runtime.Goexit) - deadlock!")
}
...
}
当存在 Goroutine 处于 _Grunnable、_Grunning 和 _Gsyscall 状态时,意味着程序发生了死锁;
当所有的 Goroutine 都处于 _Gidle、_Gdead 和 _Gcopystack 状态时,意味着主程序调用了 runtime.goexit;
当运行时存在等待的 Goroutine 并且不存在正在运行的 Goroutine 时,我们会检查处理器中存在的计时器:
func checkdead() {
...
for _, _p_ := range allp {
if len(_p_.timers) > 0 {
return
}
}
throw("all goroutines are asleep - deadlock!")
}
- 运行时计数器
在系统监控的循环中,我们通过 runtime.nanotime 和 runtime.timeSleepUntil 获取当前时间和计时器下一次需要唤醒的时间;当前调度器需要执行垃圾回收或者所有处理器都处于闲置状态时,如果没有需要触发的计时器,那么系统监控可以暂时陷入休眠:
休眠的时间会依据强制 GC 的周期 forcegcperiod 和计时器下次触发的时间确定,runtime.notesleep 会使用信号量同步系统监控即将进入休眠的状态。当系统监控被唤醒之后,我们会重新计算当前时间和下一个计时器需要触发的时间、调用 runtime.noteclear 通知系统监控被唤醒并重置休眠的间隔。
如果在这之后,我们发现下一个计时器需要触发的时间小于当前时间,这也说明所有的线程可能正在忙于运行 Goroutine,系统监控会启动新的线程来触发计时器,避免计时器的到期时间有较大的偏差。
- 轮询网络
如果上一次轮询网络已经过去了 10ms,那么系统监控还会在循环中轮询网络,检查是否有待执行的文件描述符:
func sysmon() {
...
for {
...
lastpoll := int64(atomic.Load64(&sched.lastpoll))
if netpollinited() && lastpoll != 0 && lastpoll+10*1000*1000 < now {
atomic.Cas64(&sched.lastpoll, uint64(lastpoll), uint64(now))
list := netpoll(0)
if !list.empty() {
incidlelocked(-1)
injectglist(&list)
incidlelocked(1)
}
}
...
}
}
上述函数会非阻塞地调用 runtime.netpoll 检查待执行的文件描述符并通过 runtime.injectglist 将所有处于就绪状态的 Goroutine 加入全局运行队列中:
func injectglist(glist *gList) {
if glist.empty() {
return
}
lock(&sched.lock)
var n int
for n = 0; !glist.empty(); n++ {
gp := glist.pop()
casgstatus(gp, _Gwaiting, _Grunnable)
globrunqput(gp)
}
unlock(&sched.lock)
for ; n != 0 && sched.npidle != 0; n-- {
startm(nil, false)
}
*glist = gList{}
}
该函数会将所有 Goroutine 的状态从 _Gwaiting 切换至 _Grunnable 并加入全局运行队列等待运行,如果当前程序中存在空闲的处理器,会通过 runtime.startm 启动线程来执行这些任务。
- 抢占处理器
系统监控会在循环中调用 runtime.retake 抢占处于运行或者系统调用中的处理器,该函数会遍历运行时的全局处理器,每个处理器都存储了一个 runtime.sysmontick:
type sysmontick struct {
schedtick uint32
schedwhen int64
syscalltick uint32
syscallwhen int64
}
该结构体中的四个字段分别存储了处理器的调度次数、处理器上次调度时间、系统调用的次数以及系统调用的时间。runtime.retake 的循环包含了两种不同的抢占逻辑
func retake(now int64) uint32 {
n := 0
for i := 0; i < len(allp); i++ {
_p_ := allp[i]
pd := &_p_.sysmontick
s := _p_.status
if s == _Prunning || s == _Psyscall {
t := int64(_p_.schedtick)
if pd.schedwhen+forcePreemptNS <= now {
preemptone(_p_)
}
}
if s == _Psyscall {
if runqempty(_p_) && atomic.Load(&sched.nmspinning)+atomic.Load(&sched.npidle) > 0 && pd.syscallwhen+10*1000*1000 > now {
continue
}
if atomic.Cas(&_p_.status, s, _Pidle) {
n++
_p_.syscalltick++
handoffp(_p_)
}
}
}
return uint32(n)
}
当处理器处于 _Prunning 或者 _Psyscall 状态时,如果上一次触发调度的时间已经过去了 10ms,我们会通过 runtime.preemptone 抢占当前处理器;
当处理器处于 _Psyscall 状态时,在满足以下两种情况下会调用 runtime.handoffp 让出处理器的使用权:
当处理器的运行队列不为空或者不存在空闲处理器时2;
当系统调用时间超过了 10ms 时3;
系统监控通过在循环中抢占处理器来避免同一个 Goroutine 占用线程太长时间造成饥饿问题。
- 垃圾回收
在最后,系统监控还会决定是否需要触发强制垃圾回收,runtime.sysmon 会构建 runtime.gcTrigger 并调用 runtime.gcTrigger.test 方法判断是否需要触发垃圾回收:
如果需要触发垃圾回收,我们会将用于垃圾回收的 Goroutine 加入全局队列,让调度器选择合适的处理器去执行。
内存管理
内存分配器
程序中的数据和变量都会被分配到程序所在的虚拟内存中。内存空间包含俩个重要区域:栈区 Stack 和堆区 Heap。
函数调用的参数、返回值、局部变量大都汇被分配到栈上。这部分内存会由编译器进行管理
不同编程语言使用不同的方法管理堆区的内存。
C++编程语言会由工程师主动申请和释放内存,
Go、java由工程师和编译器共同管理。堆中的对象由内存分配器分配并由垃圾回收器会后。
不同的编程语言会选择不同的方式管理内存。
内存分配器设计原理
内存管理包含三个不同的组件,分别是用户程序 Muator、分配器 Allocator和收集器 Collector.
当用户程序申请内存时,它会通过内存分配器申请新内存,而分配器会负责从堆中初始化相应的内存区域。

-
分配方法
编程语言的内存分配器一般包含俩种分配方法 ,线性分配器 Sequential Allocator ,Bump Allocator
空闲链表分配器 Free-List Allocator. -
线性分配器
Bump Allocator 是一种高效的内存分配方法,但是有较大的局限性。
当我们使用线性分配器时,只需要在内存中维护一个指向内存特定位置的指针。
如果用户程序向分配器申请内存,分配器只需要检查剩余的空闲内存、返回分配的内存区域、修改指针在内存中的位置。
线性分配器带来了较快的执行速度和较低的实现复杂度。但是无法再内存被释放时重用内存。
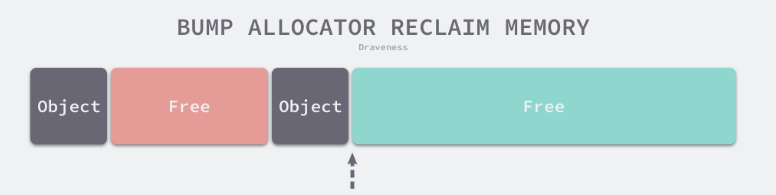
所以线性分配器需要与合适的垃圾回收算法配合,例如标记压缩 Mark-Compact、复制回收Copying GC、分代回收 Generation GC
可以通过拷贝的方式整理存活对象的碎片,将空闲内存定期合并,
线性分配器需要与具有拷贝特性的垃圾回收算法配合,所以C和C++等需要直接对外暴露指针的语言就无法使用该策略。 -
空闲链表分配器
Free-List Allocator 可以重用已经被释放的内存,它在内部会维护一个类似链表的数据结构。
当用户程序申请内存时,空闲链表分配器会依次遍历空闲的内存块,找到足够大的内存块,然后申请资源并修改链表




因为不同的内存块通过指针构成了链表,所以使用这种方式的分配器可以利用回收的资源。
但是分配内存的时候需要遍历链表,所以它的时间复杂度是O(n).
空闲链表分配器可以选择不同的策略在链表中的内存块中进行选择,最常见以下四种:
1)首次适应 First-Fit – 从链表头开始遍历,选择第一个大小大于申请内存的内存块
2)循环首次适应 Next-Fit – 从上次遍历的结束位置开始遍历,选择第一个大小大于申请内存的内存块
3)最优适应 Best-Fit – 从链表头遍历整个链表,选择最合适的内存块
4)隔离适应 Segregated-Fit – 将内存分割成多个链表,每个链表中的内存块大小相同。申请内存时先找到满足条件的链表,再从链表中选择合适的内存块。
Go语言类似第四个。

该策略会将内存分割成由 4、8、16、32 字节的内存块组成的链表,当我们向内存分配器申请 8 字节的内存时,它会在上图中找到满足条件的空闲内存块并返回。
隔离适应的分配策略减少了需要遍历的内存块数量,提高了内存分配的效率。
-
分级分配
线程缓存分配 Thread-Caching Malloc。TCMalloc. 是用于分配内存的机制,它比glibc中的malloc还要快很多。
Go语言借鉴了TCMalloc的设计实现高速的内存分配。
核心理念:使用多级缓存将对象根据大小分类,并按照类别实施不同的分配策略 -
对象大小
Go语言的内存分配的内存大小选择不同的处理逻辑,运行时根据对象的大小,将对象分成微对象、小对象、大对象 3种。
| 类别 | 大小 |
| —- | ———– |
| 微对象 | (0, 16B) |
| 小对象 | [16B, 32KB] |
| 大对象 | (32KB, +∞) |
因为程序中的绝大多数对象的大小都在32KB以下,而申请的内存大小影响Go语言运行时分配内存的过程和开销。
所以分别处理大对象和小对象有利于提高内存分配器的性能。 -
多级缓存 内存分配
内存分配器不仅会区别对待大小不同的对象,还会将内存分成不同的级别 分别管理。
TCMalloc和Go运行时分配器都会引入线程缓存Thread Cache、中心缓存 Central Cache、页堆 Page Heap.三个组件分级管理内存

线程缓存属于每一个独立的线程,它能够满足线程上绝大多数的内存分配需求,
因为不涉及多线程,所以不需要使用互斥锁来保护内存。
当线程缓存不能满足需求时,运行时会使用中心缓存作为解决小对象的内存分配,
在遇到32KB以上的对象时,内存分配器会选择页堆直接分配大内存。
这种多层级的内存分配设计与计算机操作系统的多级缓存有些类似,因为多数的对象都是小对象,我们可以通过线程缓存和中心缓存提供足够的内存空间。
发现资源不足时,从上一级组件中获取更多的内存资源。
- 虚拟机内存布局
GO语言堆区内存地址空间的设计及演进过程。
1.10 以前版本。堆区的内存空间都是连续的。
1.11 版本。go团队使用稀疏的堆内存空间替代了连续的内存。解决了连续内存带来的限制以及在特殊场景下可能出现的问题。
- 线性内存
Go 语言装载1.10版本在启动时会初始化整片虚拟内存区域。
三个区域spans、bitmap、arena分别预留了512MB、16GB、512GB的内存空间。
这些内存并不是真正存在的物理内存,而是虚拟内存。

spans 区域存储了指向内存管理单元 runtime.mspan 的指针,每个内存单元会管理几页的内存空间,每页大小为 8KB;
bitmap 用于标识 arena 区域中的那些地址保存了对象,位图中的每个字节都会表示堆区中的 32 字节是否空闲;
arena 区域是真正的堆区,运行时会将 8KB 看做一页,这些内存页中存储了所有在堆上初始化的对象
对于任意一个地址,我们都可以根据 arena 的基地址计算该地址所在的页数
并通过 spans 数组获得管理该片内存的管理单元 runtime.mspan,
spans 数组中多个连续的位置可能对应同一个 runtime.mspan 结构。
- 稀疏内存
1.11 提出的方案。
使用稀疏的内存布局不仅能移除堆大小的上限5,还能解决 C 和 Go 混合使用时的地址空间冲突问题。不过因为基于稀疏内存的内存管理失去了内存的连续性这一假设,这也使内存管理变得更加复杂:
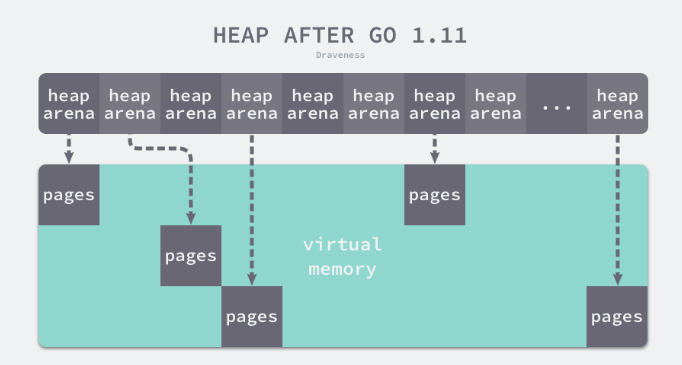
运行时使用二维的 runtime.heapArena 数组管理所有的内存,每个单元都会管理 64MB 的内存空间:

type heapArena struct {
bitmap [heapArenaBitmapBytes]byte
spans [pagesPerArena]*mspan
pageInUse [pagesPerArena / 8]uint8
pageMarks [pagesPerArena / 8]uint8
pageSpecials [pagesPerArena / 8]uint8
checkmarks *checkmarksMap
zeroedBase uintptr
}
该结构体中的 bitmap 和 spans 与线性内存中的 bitmap 和 spans 区域一一对应
zeroedBase 字段指向了该结构体管理的内存的基地址。上述设计将原有的连续大内存切分成稀疏的小内存,而用于管理这些内存的元信息也被切成了小块。
不同平台和架构的二维数组大小可能完全不同,
如果我们的 Go 语言服务在 Linux 的 x86-64 架构上运行,二维数组的一维大小会是 1,而二维大小是 4,194,304,
因为每一个指针占用 8 字节的内存空间,所以元信息的总大小为 32MB。
由于每个 runtime.heapArena 都会管理 64MB 的内存,整个堆区最多可以管理 256TB 的内存,这比之前的 512GB 多好几个数量级。
由于内存的管理变得更加复杂,上述改动对垃圾回收稍有影响,大约会增加 1% 的垃圾回收开销,不过这也是我们为了解决已有问题必须付出的成本
- 地址空间
因为所有的内存空间最终都是要从操作系统中申请的。所以Go语言的运行时构建了操作系统的内存管理抽象层,
该抽象层将运行时管理的地址空间分为以下四种状态。
| 状态 | 解释 |
|---|---|
| None | 内存没有被保留或者映射,是地址空间的默认状态 |
| Reserved | 运行时持有该地址空间,但是访问该内存会导致错误 |
| Prepared | 内存被保留,一般没有对应的物理内存访问该片内存的行为是未定义的可以快速转换到 Ready 状态 |
| Ready | 可以被安全访问 |
每个不同的操作系统都会包含一组用于管理内存的特定方法,这些方法可以让内存地址空间在不同的状态之间转换,我们可以通过下图了解不同状态之间的转换过程:

runtime.sysAlloc 会从操作系统中获取一大块可用的内存空间,可能为几百 KB 或者几 MB;
runtime.sysFree 会在程序发生内存不足(Out-of Memory,OOM)时调用并无条件地返回内存;
runtime.sysReserve 会保留操作系统中的一片内存区域,访问这片内存会触发异常;
runtime.sysMap 保证内存区域可以快速转换至就绪状态;
runtime.sysUsed 通知操作系统应用程序需要使用该内存区域,保证内存区域可以安全访问;
runtime.sysUnused 通知操作系统虚拟内存对应的物理内存已经不再需要,可以重用物理内存;
runtime.sysFault 将内存区域转换成保留状态,主要用于运行时的调试;
运行时使用 Linux 提供的 mmap、munmap 和 madvise 等系统调用实现了操作系统的内存管理抽象层,抹平了不同操作系统的差异,
为运行时提供了更加方便的接口,除了 Linux 之外,运行时还实现了 BSD、Darwin、Plan9 以及 Windows 等平台上抽象层。
内存管理组件
Go语言的内存分配器包含内存管理单元、线程缓存、中心缓存、和页堆。
runtime.mspan、runtime.mcache、runtime.mcentral 和 runtime.mheap

所有的 Go 语言程序都会在启动时初始化如上图所示的内存布局,
每一个处理器都会分配一个线程缓存 runtime.mcache 用于处理微对象和小对象的分配,它们会持有内存管理单元 runtime.mspan。
每个类型的内存管理单元都会管理特定大小的对象,
当内存管理单元中不存在空闲对象时,它们会从 runtime.mheap 持有的 134 个中心缓存 runtime.mcentral 中获取新的内存单元,
中心缓存属于全局的堆结构体 runtime.mheap,它会从操作系统中申请内存。
在 amd64 的 Linux 操作系统上,runtime.mheap 会持有 4,194,304 runtime.heapArena,每个 runtime.heapArena 都会管理 64MB 的内存,单个 Go 语言程序的内存上限也就是 256TB。
- 内存管理单元
runtime.mspan是Go语言内存管理的基本单元你,有next prev俩个字段。分别指向了前一个和后一个mspan.
type mspan struct {
next *mspan
prev *mspan
...
}

串联后的mspan 构成双向链表。运行时会使用mSpanList存储双向链表的头节点和尾节点并在线程缓存和中心缓存中使用。
- 页和内存
每个mspan都管理npages个大小为8kb的页。这里的页不是操作系统中的内存页。
它们是操作系统内存页的整数倍。该结构体会使用下面这些字段来管理内存页的分配和回收:
type mspan struct {
startAddr uintptr // 起始地址
npages uintptr // 页数
freeindex uintptr
allocBits *gcBits
gcmarkBits *gcBits
allocCache uint64
...
}
startAddr 和 npages — 确定该结构体管理的多个页所在的内存,每个页的大小都是 8KB;
freeindex — 扫描页中空闲对象的初始索引;
allocBits 和 gcmarkBits — 分别用于标记内存的占用和回收情况;
allocCache — allocBits 的补码,可以用于快速查找内存中未被使用的内存;
runtime.mspan 会以两种不同的视角看待管理的内存,当结构体管理的内存不足时,运行时会以页为单位向堆申请内存:

当用户程序或者线程向 runtime.mspan 申请内存时,它会使用 allocCache 字段以对象为单位在管理的内存中快速查找待分配的空间:

如果我们能在内存中找到空闲的内存单元会直接返回,当内存中不包含空闲的内存时,
上一级的组件 runtime.mcache 会为调用 runtime.mcache.refill 更新内存管理单元以满足为更多对象分配内存的需求。
- 状态
运行时会使用 runtime.mSpanStateBox 存储内存管理单元的状态 runtime.mSpanState:
type mspan struct {
...
state mSpanStateBox
...
}
该状态可能处于 mSpanDead、mSpanInUse、mSpanManual 和 mSpanFree 四种情况。
当 runtime.mspan 在空闲堆中,它会处于 mSpanFree 状态;
当 runtime.mspan 已经被分配时,它会处于 mSpanInUse、mSpanManual 状态,运行时会遵循下面的规则转换该状态:
在垃圾回收的任意阶段,可能从 mSpanFree 转换到 mSpanInUse 和 mSpanManual;
在垃圾回收的清除阶段,可能从 mSpanInUse 和 mSpanManual 转换到 mSpanFree;
在垃圾回收的标记阶段,不能从 mSpanInUse 和 mSpanManual 转换到 mSpanFree;
设置 runtime.mspan 状态的操作必须是原子性的以避免垃圾回收造成的线程竞争问题。
- 跨度类
runtime.spanClass 是 runtime.mspan 的跨度类,它决定了内存管理单元中存储的对象大小和个数:
type mspan struct {
...
spanclass spanClass
...
}
Go 语言的内存管理模块中一共包含 67 种跨度类,
每一个跨度类都会存储特定大小的对象并且包含特定数量的页数以及对象,
所有的数据都会被预选计算好并存储在 runtime.class_to_size 和 runtime.class_to_allocnpages 等变量中:
- 线程缓存
runtime.mcache 是 Go 语言中的线程缓存,它会与线程上的处理器一一绑定,
主要用来缓存用户程序申请的微小对象。每一个线程缓存都持有 68 * 2 个 runtime.mspan,
这些内存管理单元都存储在结构体的 alloc 字段中:
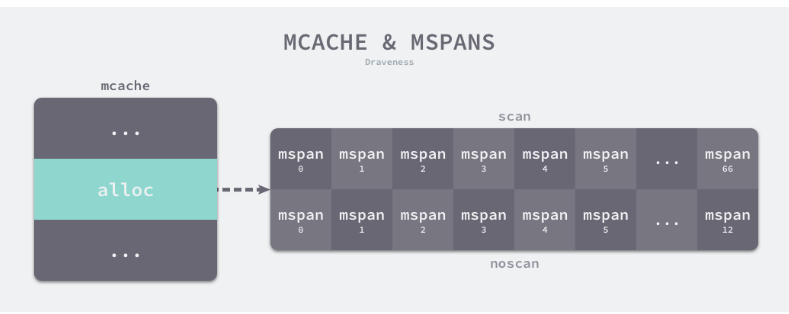

线程缓存在刚刚被初始化时是不包含 runtime.mspan 的,只有当用户程序申请内存时才会从上一级组件获取新的 runtime.mspan 满足内存分配的需求。
初始化
运行时在初始化处理器时会调用 runtime.allocmcache 初始化线程缓存,该函数会在系统栈中使用 runtime.mheap 中的线程缓存分配器初始化新的 runtime.mcache 结构体:
func allocmcache() *mcache {
var c *mcache
systemstack(func() {
lock(&mheap_.lock)
c = (*mcache)(mheap_.cachealloc.alloc())
c.flushGen = mheap_.sweepgen
unlock(&mheap_.lock)
})
for i := range c.alloc {
c.alloc[i] = &emptymspan
}
c.nextSample = nextSample()
return c
}
替换
runtime.mcache.refill 会为线程缓存获取一个指定跨度类的内存管理单元,被替换的单元不能包含空闲的内存空间,而获取的单元中需要至少包含一个空闲对象用于分配内存:
微分配器 #
线程缓存中还包含几个用于分配微对象的字段,下面的这三个字段组成了微对象分配器,专门管理 16 字节以下的对象:
type mcache struct {
tiny uintptr
tinyoffset uintptr
local_tinyallocs uintptr
}
- 中心缓存
runtime.mcentral 是内存分配器的中心缓存,与线程缓存不同,访问中心缓存中的内存管理单元需要使用互斥锁:
type mcentral struct {
spanclass spanClass
partial [2]spanSet
full [2]spanSet
}
每个中心缓存都会管理某个跨度类的内存管理单元,它会同时持有两个 runtime.spanSet,分别存储包含空闲对象和不包含空闲对象的内存管理单元。
- 内存管理单元
线程缓存会通过中心缓存的 runtime.mcentral.cacheSpan 方法获取新的内存管理单元,该方法的实现比较复杂,我们可以将其分成以下几个部分
调用 runtime.mcentral.partialSwept 从清理过的、包含空闲空间的 runtime.spanSet 结构中查找可以使用的内存管理单元;
调用 runtime.mcentral.partialUnswept 从未被清理过的、有空闲对象的 runtime.spanSet 结构中查找可以使用的内存管理单元;
调用 runtime.mcentral.fullUnswept 获取未被清理的、不包含空闲空间的 runtime.spanSet 中获取内存管理单元并通过 runtime.mspan.sweep 清理它的内存空间;
调用 runtime.mcentral.grow 从堆中申请新的内存管理单元;
更新内存管理单元的 allocCache 等字段帮助快速分配内存;
首先我们会在中心缓存的空闲集合中查找可用的 runtime.mspan,运行时总是会先从获取清理过的内存管理单元,后检查未清理的内存管理单元:
当找到需要回收的内存单元时,运行时会触发 runtime.mspan.sweep 进行清理,如果在包含空闲空间的集合中没有找到管理单元,那么运行时尝试会从未清理的集合中获取
如果 runtime.mcentral 通过上述两个阶段都没有找到可用的单元,它会调用 runtime.mcentral.grow 触发扩容从堆中申请新的内存
无论通过哪种方法获取到了内存单元,该方法的最后都会更新内存单元的 allocBits 和 allocCache 等字段,让运行时在分配内存时能够快速找到空闲的对象
-
扩容
中心缓存的扩容方法 runtime.mcentral.grow 会根据预先计算的 class_to_allocnpages 和 class_to_size 获取待分配的页数以及跨度类并调用 runtime.mheap.alloc 获取新的 runtime.mspan 结构:
获取了 runtime.mspan 后,我们会在上述方法中初始化 limit 字段并清除该结构在堆上对应的位图。 -
页堆
runtime.mheap 是内存分配的核心结构体,Go 语言程序会将其作为全局变量存储,而堆上初始化的所有对象都由该结构体统一管理,该结构体中包含两组非常重要的字段,
其中一个是全局的中心缓存列表 central,另一个是管理堆区内存区域的 arenas 以及相关字段。
页堆中包含一个长度为 136 的 runtime.mcentral 数组,其中 68 个为跨度类需要 scan 的中心缓存,另外的 68 个是 noscan 的中心缓存:

Go 语言所有的内存空间都由如下所示的二维矩阵 runtime.heapArena 管理,这个二维矩阵管理的内存可以是不连续的:

内存分配
堆上所有的对象都会通过调用newobject函数分配内存。
该函数会调用mallocgc分配指定大小的内存空间。

微对象 (0, 16B) — 先使用微型分配器,再依次尝试线程缓存、中心缓存和堆分配内存;
小对象 [16B, 32KB] — 依次尝试使用线程缓存、中心缓存和堆分配内存;
大对象 (32KB, +∞) — 直接在堆上分配内存;
垃圾收集器

当程序的内存占用达到一定阈值时,整个应用程序就会全部暂停,垃圾收集器会扫描已经分配的所有对象并回收不再使用的内存空间,
当这个过程结束后,用户程序才可以继续执行,Go 语言在早期也使用这种策略实现垃圾收集
内存分配器和垃圾收集器共同管理着程序中的堆内存空间
- 标记清除
标记清除(Mark-Sweep)算法是最常见的垃圾收集算法,标记清除收集器是跟踪式垃圾收集器,其执行过程可以分成标记(Mark)和清除(Sweep)两个阶段:
标记阶段 — 从根对象出发查找并标记堆中所有存活的对象;
清除阶段 — 遍历堆中的全部对象,回收未被标记的垃圾对象并将回收的内存加入空闲链表;
如下图所示,内存空间中包含多个对象,我们从根对象出发依次遍历对象的子对象并将从根节点可达的对象都标记成存活状态,即 A、C 和 D 三个对象,剩余的 B、E 和 F 三个对象因为从根节点不可达,所以会被当做垃圾

标记阶段结束后会进入清除阶段,在该阶段中收集器会依次遍历堆中的所有对象,释放其中没有被标记的 B、E 和 F 三个对象并将新的空闲内存空间以链表的结构串联起来,方便内存分配器的使用。

这里介绍的是最传统的标记清除算法,垃圾收集器从垃圾收集的根对象出发,递归遍历这些对象指向的子对象并将所有可达的对象标记成存活;标记阶段结束后,垃圾收集器会依次遍历堆中的对象并清除其中的垃圾,整个过程需要标记对象的存活状态,用户程序在垃圾收集的过程中也不能执行,我们需要用到更复杂的机制来解决 STW 的问题。
- 三色抽象
为了解决原始标记清除算法带来的长时间 STW,多数现代的追踪式垃圾收集器都会实现三色标记算法的变种以缩短 STW 的时间。
三色标记算法将程序中的对象分成白色、黑色和灰色三类
白色对象 — 潜在的垃圾,其内存可能会被垃圾收集器回收;
黑色对象 — 活跃的对象,包括不存在任何引用外部指针的对象以及从根对象可达的对象;
灰色对象 — 活跃的对象,因为存在指向白色对象的外部指针,垃圾收集器会扫描这些对象的子对象;

在垃圾收集器开始工作时,程序中不存在任何的黑色对象,垃圾收集的根对象会被标记成灰色,
垃圾收集器只会从灰色对象集合中取出对象开始扫描,当灰色集合中不存在任何对象时,标记阶段就会结束。
三色标记垃圾收集器的工作原理很简单,我们可以将其归纳成以下几个步骤:
从灰色对象的集合中选择一个灰色对象并将其标记成黑色;
将黑色对象指向的所有对象都标记成灰色,保证该对象和被该对象引用的对象都不会被回收;
重复上述两个步骤直到对象图中不存在灰色对象;
当三色的标记清除的标记阶段结束之后,应用程序的堆中就不存在任何的灰色对象,
我们只能看到黑色的存活对象以及白色的垃圾对象,垃圾收集器可以回收这些白色的垃圾,
下面是使用三色标记垃圾收集器执行标记后的堆内存,堆中只有对象 D 为待回收的垃圾:

本来不应该被回收的对象却被回收了,这在内存管理中是非常严重的错误,我们将这种错误称为悬挂指针
,即指针没有指向特定类型的合法对象,影响了内存的安全性,想要并发或者增量地标记对象还是需要使用屏障技术。
- 屏障技术
内存屏障技术是一种屏障指令,它可以让 CPU 或者编译器在执行内存相关操作时遵循特定的约束,
目前多数的现代处理器都会乱序执行指令以最大化性能,
但是该技术能够保证内存操作的顺序性,
在内存屏障前执行的操作一定会先于内存屏障后执行的操作
想要在并发或者增量的标记算法中保证正确性,我们需要达成以下两种三色不变性(Tri-color invariant)中的一种:
强三色不变性 — 黑色对象不会指向白色对象,只会指向灰色对象或者黑色对象;
弱三色不变性 — 黑色对象指向的白色对象必须包含一条从灰色对象经由多个白色对象的可达路径

垃圾收集中的屏障技术更像是一个钩子方法,
它是在用户程序读取对象、创建新对象以及更新对象指针时执行的一段代码,
根据操作类型的不同,我们可以将它们分成读屏障(Read barrier)和写屏障(Write barrier)两种,
因为读屏障需要在读操作中加入代码片段,对用户程序的性能影响很大,所以编程语言往往都会采用写屏障保证三色不变性。
Go 语言中使用的两种写屏障技术,分别是 Dijkstra 提出的插入写屏障和 Yuasa 提出的删除写屏障
- 插入写屏障
Dijkstra 在 1978 年提出了插入写屏障,通过如下所示的写屏障,
用户程序和垃圾收集器可以在交替工作的情况下保证程序执行的正确性:
writePointer(slot, ptr):
shade(ptr)
*slot = ptr
上述插入写屏障的伪代码非常好理解,
每当执行类似 *slot = ptr 的表达式时,我们会执行上述写屏障通过 shade 函数尝试改变指针的颜色。
如果 ptr 指针是白色的,那么该函数会将该对象设置成灰色,其他情况则保持不变。

假设我们在应用程序中使用 Dijkstra 提出的插入写屏障,
在一个垃圾收集器和用户程序交替运行的场景中会出现如上图所示的标记过程
垃圾收集器将根对象指向 A 对象标记成黑色并将 A 对象指向的对象 B 标记成灰色;
用户程序将 A 对象原本指向 B 的指针指向 C,触发删除写屏障,但是因为 B 对象已经是灰色的,所以不做改变;
用户程序将 B 对象原本指向 C 的指针删除,触发删除写屏障,白色的 C 对象被涂成灰色;
垃圾收集器依次遍历程序中的其他灰色对象,将它们分别标记成黑色
上述过程中的第三步触发了 Yuasa 删除写屏障的着色,
因为用户程序删除了 B 指向 C 对象的指针,所以 C 和 D 两个对象会分别违反强三色不变性和弱三色不变性:
强三色不变性 — 黑色的 A 对象直接指向白色的 C 对象;
弱三色不变性 — 垃圾收集器无法从某个灰色对象出发,经过几个连续的白色对象访问白色的 C 和 D 两个对象;
Yuasa 删除写屏障通过对 C 对象的着色,保证了 C 对象和下游的 D 对象能够在这一次垃圾收集的循环中存活,避免发生悬挂指针以保证用户程序的正确性。
- 增量和并发
传统的垃圾收集算法会在垃圾收集的执行期间暂停应用程序,一旦触发垃圾收集,
垃圾收集器会抢占 CPU 的使用权占据大量的计算资源以完成标记和清除工作,然而很多追求实时的应用程序无法接受长时间的 STW。

远古时代的计算资源还没有今天这么丰富,今天的计算机往往都是多核的处理器,垃圾收集器一旦开始执行就会浪费大量的计算资源,
为了减少应用程序暂停的最长时间和垃圾收集的总暂停时间,我们会使用下面的策略优化现代的垃圾收集器:
增量垃圾收集 — 增量地标记和清除垃圾,降低应用程序暂停的最长时间;
并发垃圾收集 — 利用多核的计算资源,在用户程序执行时并发标记和清除垃圾;
因为增量和并发两种方式都可以与用户程序交替运行,所以我们需要使用屏障技术保证垃圾收集的正确性;
与此同时,应用程序也不能等到内存溢出时触发垃圾收集,因为当内存不足时,应用程序已经无法分配内存,这与直接暂停程序没有什么区别,
增量和并发的垃圾收集需要提前触发并在内存不足前完成整个循环,避免程序的长时间暂停。
-
增量收集器
增量式(Incremental)的垃圾收集是减少程序最长暂停时间的一种方案,
它可以将原本时间较长的暂停时间切分成多个更小的 GC 时间片,
虽然从垃圾收集开始到结束的时间更长了,
但是这也减少了应用程序暂停的最大时间:
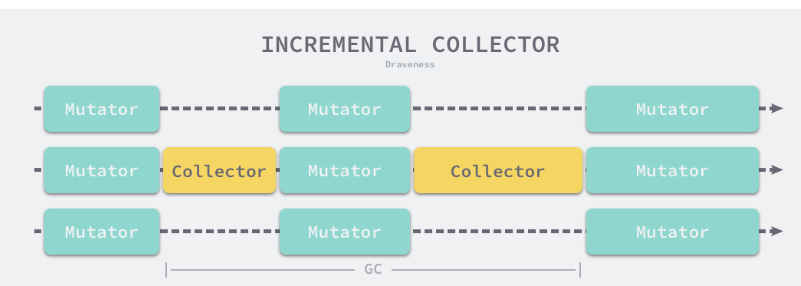
增量式的垃圾收集需要与三色标记法一起使用,
为了保证垃圾收集的正确性,我们需要在垃圾收集开始前打开写屏障,
这样用户程序修改内存都会先经过写屏障的处理,保证了堆内存中对象关系的强三色不变性或者弱三色不变性。
虽然增量式的垃圾收集能够减少最大的程序暂停时间,
但是增量式收集也会增加一次 GC 循环的总时间,
在垃圾收集期间,因为写屏障的影响用户程序也需要承担额外的计算开销,
所以增量式的垃圾收集也不是只带来好处的,但是总体来说还是利大于弊 -
并发收集器
并发(Concurrent)的垃圾收集不仅能够减少程序的最长暂停时间,还能减少整个垃圾收集阶段的时间,
通过开启读写屏障、利用多核优势与用户程序并行执行,并发垃圾收集器确实能够减少垃圾收集对应用程序的影响:
虽然并发收集器能够与用户程序一起运行,但是并不是所有阶段都可以与用户程序一起运行,
部分阶段还是需要暂停用户程序的,不过与传统的算法相比,并发的垃圾收集可以将能够并发执行的工作尽量并发执行;
当然,因为读写屏障的引入,并发的垃圾收集器也一定会带来额外开销,不仅会增加垃圾收集的总时间,还会影响用户程序,这是我们在设计垃圾收集策略时必须要注意的。


演进过程
Go 语言的垃圾收集器从诞生的第一天起就一直在演进,除了少数几个版本没有大更新之外,几乎每次发布的小版本都会提升垃圾收集的性能,
而与性能一同提升的还有垃圾收集器代码的复杂度,本节将从 Go 语言 v1.0 版本开始分析垃圾收集器的演进过程。
v1.0 — 完全串行的标记和清除过程,需要暂停整个程序;
v1.1 — 在多核主机并行执行垃圾收集的标记和清除阶段
v1.3 — 运行时基于只有指针类型的值包含指针的假设增加了对栈内存的精确扫描支持,实现了真正精确的垃圾收集
将 unsafe.Pointer 类型转换成整数类型的值认定为不合法的,可能会造成悬挂指针等严重问题;
v1.5 — 实现了基于三色标记清扫的并发垃圾收集器
大幅度降低垃圾收集的延迟从几百 ms 降低至 10ms 以下;
计算垃圾收集启动的合适时间并通过并发加速垃圾收集的过程;
v1.6 — 实现了去中心化的垃圾收集协调器;
基于显式的状态机使得任意 Goroutine 都能触发垃圾收集的状态迁移;
使用密集的位图替代空闲链表表示的堆内存,降低清除阶段的 CPU 占用
v1.7 — 通过并行栈收缩将垃圾收集的时间缩短至 2ms 以内
v1.8 — 使用混合写屏障将垃圾收集的时间缩短至 0.5ms 以内
v1.9 — 彻底移除暂停程序的重新扫描栈的过程
v1.10 — 更新了垃圾收集调频器(Pacer)的实现,分离软硬堆大小的目标
v1.12 — 使用新的标记终止算法简化垃圾收集器的几个阶段
v1.13 — 通过新的 Scavenger 解决瞬时内存占用过高的应用程序向操作系统归还内存的问题
v1.14 — 使用全新的页分配器优化内存分配的速度
我们从 Go 语言垃圾收集器的演进能够看到该组件的实现和算法变得越来越复杂,
最开始的垃圾收集器还是不精确的单线程 STW 收集器,
但是最新版本的垃圾收集器却支持并发垃圾收集、去中心化协调等特性,
我们在这里将介绍与最新版垃圾收集器相关的组件和特性。
- 并发垃圾收集
并发垃圾收集器必须在合适的时间点触发垃圾收集循环,
假设我们的 Go 语言程序运行在一台 4 核的物理机上,那么在垃圾收集开始后,收集器会占用 25% 计算资源在后台来扫描并标记内存中的对象

Go 语言的并发垃圾收集器会在扫描对象之前暂停程序做一些标记对象的准备工作,
其中包括启动后台标记的垃圾收集器以及开启写屏障,如果在后台执行的垃圾收集器不够快,应用程序申请内存的速度超过预期,
运行时会让申请内存的应用程序辅助完成垃圾收集的扫描阶段,在标记和标记终止阶段结束之后就会进入异步的清理阶段,将不用的内存增量回收。
v1.5 版本实现的并发垃圾收集策略由专门的 Goroutine 负责在处理器之间同步和协调垃圾收集的状态。
当其他的 Goroutine 发现需要触发垃圾收集时,它们需要将该信息通知给负责修改状态的主 Goroutine,
然而这个通知的过程会带来一定的延迟,这个延迟的时间窗口很可能是不可控的,用户程序会在这段时间继续分配内存。
- 回收堆目标
STW 的垃圾收集器虽然需要暂停程序,但是它能够有效地控制堆内存的大小,
Go 语言运行时的默认配置会在堆内存达到上一次垃圾收集的 2 倍时,触发新一轮的垃圾收集,
这个行为可以通过环境变量 GOGC 调整,在默认情况下它的值为 100,即增长 100% 的堆内存才会触发 GC。


实现原理
在介绍垃圾收集器的演进过程之前,我们需要初步了解最新垃圾收集器的执行周期,
这对我们了解其全局的设计会有比较大的帮助。
Go 语言的垃圾收集可以分成清除终止、标记、标记终止和清除四个不同阶段,它们分别完成了不同的工作

清理终止阶段;
暂停程序,所有的处理器在这时会进入安全点(Safe point);
如果当前垃圾收集循环是强制触发的,我们还需要处理还未被清理的内存管理单元;
标记阶段;
将状态切换至 _GCmark、开启写屏障、用户程序协助(Mutator Assists)并将根对象入队;
恢复执行程序,标记进程和用于协助的用户程序会开始并发标记内存中的对象,写屏障会将被覆盖的指针和新指针都标记成灰色,而所有新创建的对象都会被直接标记成黑色;
开始扫描根对象,包括所有 Goroutine 的栈、全局对象以及不在堆中的运行时数据结构,扫描 Goroutine 栈期间会暂停当前处理器;
依次处理灰色队列中的对象,将对象标记成黑色并将它们指向的对象标记成灰色;
使用分布式的终止算法检查剩余的工作,发现标记阶段完成后进入标记终止阶段;
标记终止阶段;
暂停程序、将状态切换至 _GCmarktermination 并关闭辅助标记的用户程序;
清理处理器上的线程缓存;
清理阶段;
将状态切换至 _GCoff 开始清理阶段,初始化清理状态并关闭写屏障;
恢复用户程序,所有新创建的对象会标记成白色;
后台并发清理所有的内存管理单元,当 Goroutine 申请新的内存管理单元时就会触发清理;
运行时虽然只会使用 _GCoff、_GCmark 和 _GCmarktermination 三个状态表示垃圾收集的全部阶段,
但是在实现上却复杂很多,本节将按照垃圾收集的不同阶段详细分析其实现原理。
- 全局变量
在垃圾收集中有一些比较重要的全局变量,在分析其过程之前,我们会先逐一介绍这些重要的变量,
这些变量在垃圾收集的各个阶段中会反复出现,所以理解他们的功能是非常重要的,我们先介绍一些比较简单的变量:
runtime.gcphase 是垃圾收集器当前处于的阶段,可能处于 _GCoff、_GCmark 和 _GCmarktermination,Goroutine 在读取或者修改该阶段时需要保证原子性;
runtime.gcBlackenEnabled 是一个布尔值,当垃圾收集处于标记阶段时,该变量会被置为 1,在这里辅助垃圾收集的用户程序和后台标记的任务可以将对象涂黑;
runtime.gcController 实现了垃圾收集的调步算法,它能够决定触发并行垃圾收集的时间和待处理的工作;
runtime.gcpercent 是触发垃圾收集的内存增长百分比,默认情况下为 100,即堆内存相比上次垃圾收集增长 100% 时应该触发 GC,并行的垃圾收集器会在到达该目标前完成垃圾收集;
runtime.writeBarrier 是一个包含写屏障状态的结构体,其中的 enabled 字段表示写屏障的开启与关闭;
runtime.worldsema 是全局的信号量,获取该信号量的线程有权利暂停当前应用程序;
除了上述全局的变量之外,我们在这里还需要简单了解一下 runtime.work 变量
var work struct {
full lfstack
empty lfstack
pad0 cpu.CacheLinePad
wbufSpans struct {
lock mutex
free mSpanList
busy mSpanList
}
...
nproc uint32
tstart int64
nwait uint32
ndone uint32
...
mode gcMode
cycles uint32
...
stwprocs, maxprocs int32
...
}
该结构体中包含大量垃圾收集的相关字段,例如:表示完成的垃圾收集循环的次数、当前循环时间和 CPU 的利用率、垃圾收集的模式等等
- 触发时机
运行时会通过如下所示的 runtime.gcTrigger.test 方法决定是否需要触发垃圾收集,
当满足触发垃圾收集的基本条件时 — 允许垃圾收集、程序没有崩溃并且没有处于垃圾收集循环,该方法会根据三种不同方式触发进行不同的检查:
func (t gcTrigger) test() bool {
if !memstats.enablegc || panicking != 0 || gcphase != _GCoff {
return false
}
switch t.kind {
case gcTriggerHeap:
return memstats.heap_live >= memstats.gc_trigger
case gcTriggerTime:
if gcpercent < 0 {
return false
}
lastgc := int64(atomic.Load64(&memstats.last_gc_nanotime))
return lastgc != 0 && t.now-lastgc > forcegcperiod
case gcTriggerCycle:
return int32(t.n-work.cycles) > 0
}
return true
}
gcTriggerHeap — 堆内存的分配达到控制器计算的触发堆大小;
gcTriggerTime — 如果一定时间内没有触发,就会触发新的循环,该触发条件由 runtime.forcegcperiod 变量控制,默认为 2 分钟;
gcTriggerCycle — 如果当前没有开启垃圾收集,则触发新的循环
用于开启垃圾收集的方法 runtime.gcStart 会接收一个 runtime.gcTrigger 类型的谓词,所有出现 runtime.gcTrigger 结构体的位置都是触发垃圾收集的代码:
runtime.sysmon 和 runtime.forcegchelper — 后台运行定时检查和垃圾收集;
runtime.GC — 用户程序手动触发垃圾收集;
runtime.mallocgc — 申请内存时根据堆大小触发垃圾收集;

- 后台触发
运行时会在应用程序启动时在后台开启一个用于强制触发垃圾收集的 Goroutine,
该 Goroutine 的职责非常简单 — 调用 runtime.gcStart 尝试启动新一轮的垃圾收集
func init() {
go forcegchelper()
}
func forcegchelper() {
forcegc.g = getg()
for {
lock(&forcegc.lock)
atomic.Store(&forcegc.idle, 1)
goparkunlock(&forcegc.lock, waitReasonForceGGIdle, traceEvGoBlock, 1)
gcStart(gcTrigger{kind: gcTriggerTime, now: nanotime()})
}
}
- 手动触发
用户程序会通过 runtime.GC 函数在程序运行期间主动通知运行时执行,该方法在调用时会阻塞调用方直到当前垃圾收集循环完成,在垃圾收集期间也可能会通过 STW 暂停整个程序:
func GC() {
n := atomic.Load(&work.cycles)
gcWaitOnMark(n)
gcStart(gcTrigger{kind: gcTriggerCycle, n: n + 1})
gcWaitOnMark(n + 1)
for atomic.Load(&work.cycles) == n+1 && sweepone() != ^uintptr(0) {
sweep.nbgsweep++
Gosched()
}
for atomic.Load(&work.cycles) == n+1 && atomic.Load(&mheap_.sweepers) != 0 {
Gosched()
}
mp := acquirem()
cycle := atomic.Load(&work.cycles)
if cycle == n+1 || (gcphase == _GCmark && cycle == n+2) {
mProf_PostSweep()
}
releasem(mp)
}
-
申请内存
最后一个可能会触发垃圾收集的就是 runtime.mallocgc 了,
我们在上一节内存分配器中曾经介绍过运行时会将堆上的对象按大小分成微对象、小对象和大对象三类,
这三类对象的创建都可能会触发新的垃圾收集循环: -
垃圾收集启动
垃圾收集在启动过程一定会调用 runtime.gcStart,
主要职责是修改全局的垃圾收集状态到 _GCmark 并做一些准备工作,我们会分以下几个阶段介绍该函数的实现:
两次调用 runtime.gcTrigger.test 检查是否满足垃圾收集条件;
暂停程序、在后台启动用于处理标记任务的工作 Goroutine、确定所有内存管理单元都被清理以及其他标记阶段开始前的准备工作;
进入标记阶段、准备后台的标记工作、根对象的标记工作以及微对象、恢复用户程序,进入并发扫描和标记阶段;
验证垃圾收集条件的同时,该方法还会在循环中不断调用 runtime.sweepone 清理已经被标记的内存单元,完成上一个垃圾收集循环的收尾工作: -
暂停与恢复程序
runtime.stopTheWorldWithSema 和 runtime.startTheWorldWithSema 是一对用于暂停和恢复程序的核心函数,
它们有着完全相反的功能,但是程序的暂停会比恢复要复杂一些,我们来看一下前者的实现原理
func stopTheWorldWithSema() {
_g_ := getg()
sched.stopwait = gomaxprocs
atomic.Store(&sched.gcwaiting, 1)
preemptall()
_g_.m.p.ptr().status = _Pgcstop
sched.stopwait--
for _, p := range allp {
s := p.status
if s == _Psyscall && atomic.Cas(&p.status, s, _Pgcstop) {
p.syscalltick++
sched.stopwait--
}
}
for {
p := pidleget()
if p == nil {
break
}
p.status = _Pgcstop
sched.stopwait--
}
wait := sched.stopwait > 0
if wait {
for {
if notetsleep(&sched.stopnote, 100*1000) {
noteclear(&sched.stopnote)
break
}
preemptall()
}
}
}
暂停程序主要使用了 runtime.preemptall,该函数会调用我们在前面介绍过的 runtime.preemptone,因为程序中活跃的最大处理数为 gomaxprocs,所以 runtime.stopTheWorldWithSema 在每次发现停止的处理器时都会对该变量减一,直到所有的处理器都停止运行。该函数会依次停止当前处理器、等待处于系统调用的处理器以及获取并抢占空闲的处理器,处理器的状态在该函数返回时都会被更新至 _Pgcstop,等待垃圾收集器的重新唤醒。
程序恢复过程会使用 runtime.startTheWorldWithSema,该函数的实现也相对比较简单:
调用 runtime.netpoll 从网络轮询器中获取待处理的任务并加入全局队列;
调用 runtime.procresize 扩容或者缩容全局的处理器;
调用 runtime.notewakeup 或者 runtime.newm 依次唤醒处理器或者为处理器创建新的线程;
如果当前待处理的 Goroutine 数量过多,创建额外的处理器辅助完成任务;
func startTheWorldWithSema(emitTraceEvent bool) int64 {
mp := acquirem()
if netpollinited() {
list := netpoll(0)
injectglist(&list)
}
procs := gomaxprocs
p1 := procresize(procs)
sched.gcwaiting = 0
...
for p1 != nil {
p := p1
p1 = p1.link.ptr()
if p.m != 0 {
mp := p.m.ptr()
p.m = 0
mp.nextp.set(p)
notewakeup(&mp.park)
} else {
newm(nil, p)
}
}
if atomic.Load(&sched.npidle) != 0 && atomic.Load(&sched.nmspinning) == 0 {
wakep()
}
...
}
程序的暂停和启动过程都比较简单,暂停程序会使用 runtime.preemptall 抢占所有的处理器,
恢复程序时会使用 runtime.notewakeup 或者 runtime.newm 唤醒程序中的处理器。
-
后台标记模式
在垃圾收集启动期间,运行时会调用 runtime.gcBgMarkStartWorkers 为全局每个处理器创建用于执行后台标记任务的 Goroutine,每一个 Goroutine 都会运行 runtime.gcBgMarkWorker,
所有运行 runtime.gcBgMarkWorker 的 Goroutine 在启动后都会陷入休眠等待调度器的唤醒

-
并发扫描与标记辅助

栈空间管理
设计原理
栈区的内存一般由编译器自动分配和释放,其中存储着函数的入参以及局部变量。
这些参数会随着函数的创建而创建,函数的返回而消亡。
一般不会在程序中长期存在,这种线性的内存分配策略有着极高的效率
但是工程师页往往不能控制栈内存的分配。这部分工作基本都是由编译器完成的。
- 寄存器
寄存器是CPU的稀缺资源。它的存储能力非常有限。但是能提供最快的读写速度。
充分利用寄存器的速度可以构建高性能的应用程序。
栈区的操作会使用到俩个以上的寄存器。
栈寄存器是CPU寄存器的一种。主要作用是跟踪函数的调用栈,Go语言的汇编代码包含BP和SP俩个栈寄存器。
它们分别存储了栈的基址地址和栈顶的地址。
栈内存与函数调用的关系非常紧密。

BP和SP之间的内存就是当前函数的调用栈。
因为历史原因,栈内存都是从高地址向低地址扩展的。
当应用程序申请或者释放栈内存时只需要修改SP寄存器的值。这种线性的内存分配方式与堆内存相比更加快速。
- 线程栈
如果我们在linux操作系统中执行pthread_create系统调用。进程会启动一个新的线程。
如果用户没有通过软资源限制 RLIMIT_STACK指定线程栈的大小。那么操作系统会根据架构选择不同的默认栈的大小。
| 架构 | 默认栈大小 |
| ——- | —– |
| i386 | 2 MB |
| IA-64 | 32 MB |
| PowerPC | 4 MB |
| … | … |
| x86_64 | 2 MB |
多数架构默认栈大小都在2-4MB左右,极少数会使用32MB的栈。
用户程序可以在分配的站上存储函数参数和局部变量。
然而这个固定的栈大小在某些场景下不是合适的值,如果程序需要同时运行几百个甚至上千个线程。
这些线程中的大部分都只会用到很少的栈空间。当函数的调用栈非常深时,固定栈大小也无法满足用户程序的需求。
线程和进程都是代码执行的上下 文。
如果一个应用程序包含成百上千个执行上下文都是线程。会占有大量的内存空间并带来其他额开销。
GO语言在设计时认为执行上下文是轻量级的,所以它在用户态实现Goroutine作为执行上下文。
- 逃逸分析
在C语言和C++这类需要手动管理内存的编程语言中。
将对象或者结构体分配到栈上或者堆上是由工程师自主决定的。
在编译器优化中,逃逸分析是用来决定指针动态作用域的方法。
Go语言的编译器使用逃逸分析决定哪些变量应该在栈上分配。哪些变量应该在堆上分配。
遵循俩个不变形:
指向栈对象的指针不能存在于堆中;
指向栈对象的指针不能在栈对象回收后存活;

决定变量是在栈上还是堆上虽然重要,但是这是一个定义相对清晰的问题,
我们可以通过编译器统一作决策。为了保证内存的绝对安全,编译器可能会将一些变量错误地分配到堆上,但是因为堆也会被垃圾收集器扫描,所以不会造成内存泄露以及悬挂指针等安全问题,解放了工程师的生产力。
- 栈内存空间
Go语言使用用户态线程 Goroutine作为执行上下文。
它的额外开销和默认栈大小都比线程小很多
v1.0 ~ v1.1 — 最小栈内存空间为 4KB;
v1.2 — 将最小栈内存提升到了 8KB7;
v1.3 — 使用连续栈替换之前版本的分段栈
v1.4 — 将最小栈内存降低到了 2KB
Goroutine 的初始栈内存在最初的几个版本中多次修改,从 4KB 提升到 8KB 是临时的解决方案,其目的是为了减轻分段栈中的栈分裂对程序的性能影响;
在 v1.3 版本引入连续栈之后,Goroutine 的初始栈大小降低到了 2KB,进一步减少了 Goroutine 占用的内存空间。
- 分段栈
分段栈是1.3版本之前的实现,所有的Goroutine在初始化时都会调用stackalloc:go分配一块固定大小的内存空间。
这块内存的大小有StackMin:go表示。在1.2版本中为8KB.
void* runtime·stackalloc(uint32 n) {
uint32 pos;
void *v;
if(n == FixedStack || m->mallocing || m->gcing) {
if(m->stackcachecnt == 0)
stackcacherefill();
pos = m->stackcachepos;
pos = (pos - 1) % StackCacheSize;
v = m->stackcache[pos];
m->stackcachepos = pos;
m->stackcachecnt--;
m->stackinuse++;
return v;
}
return runtime·mallocgc(n, 0, FlagNoProfiling|FlagNoGC|FlagNoZero|FlagNoInvokeGC);
}
如果通过该方法申请的内存大小为固定的 8KB 或者满足其他的条件,
运行时会在全局的栈缓存链表中找到空闲的内存块并作为新 Goroutine 的栈空间返回;
在其余情况下,栈内存空间会从堆上申请一块合适的内存。
当 Goroutine 调用的函数层级或者局部变量需要的越来越多时,运行时会调用 runtime.morestack:go1.2 和 runtime.newstack:go1.2 创建一个新的栈空间,
这些栈空间虽然不连续,但是当前 Goroutine 的多个栈空间会以链表的形式串联起来,运行时会通过指针找到连续的栈片段:

- 连续栈
连续栈可以解决分段栈中存在的两个问题,其核心原理是每当程序的栈空间不足时,初始化一片更大的栈空间并将原栈中的所有值都迁移到新栈中,
新的局部变量或者函数调用就有充足的内存空间。使用连续栈机制时,栈空间不足导致的扩容会经历以下几个步骤
在内存空间中分配更大的栈内存空间;
将旧栈中的所有内容复制到新栈中;
将指向旧栈对应变量的指针重新指向新栈;
销毁并回收旧栈的内存空间;
在扩容的过程中,最重要的是调整指针的第三步,这一步能够保证指向栈的指针的正确性,因为栈中的所有变量内存都会发生变化,所以原本指向栈中变量的指针也需要调整。
我们在前面提到过经过逃逸分析的 Go 语言程序的遵循以下不变性 —— 指向栈对象的指针不能存在于堆中,所以指向栈中变量的指针只能在栈上,我们只需要调整栈中的所有变量就可以保证内存的安全了。

因为需要拷贝变量和调整指针,连续栈增加了栈扩容时的额外开销,但是通过合理栈缩容机制就能避免热分裂带来的性能问题10,
在 GC 期间如果 Goroutine 使用了栈内存的四分之一,那就将其内存减少一半,这样在栈内存几乎充满时也只会扩容一次,不会因为函数调用频繁扩缩容

栈操作
Go 语言中的执行栈由 runtime.stack 表示,该结构体中只包含两个字段,分别表示栈的顶部和栈的底部,每个栈结构体都表示范围为 [lo, hi) 的内存空间:
type stack struct {
lo uintptr
hi uintptr
}
栈的结构虽然非常简单,但是想要理解 Goroutine 栈的实现原理,还是需要我们从编译期间和运行时两个阶段入手:
编译器会在编译阶段会通过 cmd/internal/obj/x86.stacksplit 在调用函数前插入 runtime.morestack 或者 runtime.morestack_noctxt 函数;
运行时在创建新的 Goroutine 时会在 runtime.malg 中调用 runtime.stackalloc 申请新的栈内存,并在编译器插入的 runtime.morestack 中检查栈空间是否充足;
- 栈初始化
栈空间在运行时中包含两个重要的全局变量,分别是 runtime.stackpool 和 runtime.stackLarge,
这两个变量分别表示全局的栈缓存和大栈缓存,前者可以分配小于 32KB 的内存,后者用来分配大于 32KB 的栈空间:
var stackpool [_NumStackOrders]struct {
item stackpoolItem
_ [cpu.CacheLinePadSize - unsafe.Sizeof(stackpoolItem{})%cpu.CacheLinePadSize]byte
}
type stackpoolItem struct {
mu mutex
span mSpanList
}
var stackLarge struct {
lock mutex
free [heapAddrBits - pageShift]mSpanList
}
这两个用于分配空间的全局变量都与内存管理单元 runtime.mspan 有关,
我们可以认为 Go 语言的栈内存都是分配在堆上的,运行时初始化会调用 runtime.stackinit 初始化这些全局变量:
func stackinit() {
for i := range stackpool {
stackpool[i].item.span.init()
}
for i := range stackLarge.free {
stackLarge.free[i].init()
}
}
从调度器和内存分配的经验来看,如果运行时只使用全局变量来分配内存的话,
势必会造成线程之间的锁竞争进而影响程序的执行效率,
栈内存由于与线程关系比较密切,所以我们在每一个线程缓存 runtime.mcache 中都加入了栈缓存减少锁竞争影响
type mcache struct {
stackcache [_NumStackOrders]stackfreelist
}
type stackfreelist struct {
list gclinkptr
size uintptr
}

运行时使用全局的 runtime.stackpool 和线程缓存中的空闲链表分配 32KB 以下的栈内存,
使用全局的 runtime.stackLarge 和堆内存分配 32KB 以上的栈内存,提高本地分配栈内存的性能。
- 栈分配
运行时会在 Goroutine 的初始化函数 runtime.malg 中调用 runtime.stackalloc 分配一个大小足够栈内存空间,
根据线程缓存和申请栈的大小,该函数会通过三种不同的方法分配栈空间:
如果栈空间较小,使用全局栈缓存或者线程缓存上固定大小的空闲链表分配内存;
如果栈空间较大,从全局的大栈缓存 runtime.stackLarge 中获取内存空间;
如果栈空间较大并且 runtime.stackLarge 空间不足,在堆上申请一片大小足够内存空间;
- 栈扩容
编译器会在 cmd/internal/obj/x86.stacksplit 中为函数调用插入 runtime.morestack 运行时检查,
它会在几乎所有的函数调用之前检查当前 Goroutine 的栈内存是否充足,
如果当前栈需要扩容,我们会保存一些栈的相关信息并调用 runtime.newstack 创建新的栈:
runtime.newstack 会先做一些准备工作并检查当前 Goroutine 是否发出了抢占请求,如果发出了抢占请求:
当前线程可以被抢占时,直接调用 runtime.gogo 触发调度器的调度;
如果当前 Goroutine 在垃圾回收被 runtime.scanstack 标记成了需要收缩栈,调用 runtime.shrinkstack;
如果当前 Goroutine 被 runtime.suspendG 函数挂起,调用 runtime.preemptPark 被动让出当前处理器的控制权并将 Goroutine 的状态修改至 _Gpreempted;
调用 runtime.gopreempt_m 主动让出当前处理器的控制权;
如果当前 Goroutine 不需要被抢占,意味着我们需要新的栈空间来支持函数调用和本地变量的初始化,运行时会先检查目标大小的栈是否会溢出:
如果目标栈的大小没有超出程序的限制,我们会将 Goroutine 切换至 _Gcopystack 状态并调用 runtime.copystack 开始栈拷贝。
在拷贝栈内存之前,运行时会通过 runtime.stackalloc 分配新的栈空间:
- 栈缩容
runtime.shrinkstack 栈缩容时调用的函数,该函数的实现原理非常简单,其中大部分都是检查是否满足缩容前置条件的代码
如果要触发栈的缩容,新栈的大小会是原始栈的一半,不过如果新栈的大小低于程序的最低限制 2KB,那么缩容的过程就会停止
运行时只会在栈内存使用不足 1/4 时进行缩容,缩容也会调用扩容时使用的 runtime.copystack 开辟新的栈空间。
栈总结
栈内存是应用程序中重要的内存空间,它能够支持本地的局部变量和函数调用,
栈空间中的变量会与栈一同创建和销毁,这部分内存空间不需要工程师过多的干预和管理,
现代的编程
语言通过逃逸分析减少了我们的工作量,理解栈空间的分配对于理解 Go 语言的运行时有很大的帮助。
进阶内容
插件系统
通过插件系统,我们可以在运行时加载动态库 实现一些比较有趣的功能
设计原理
基于C语言的动态库实现。
- 静态库或者静态链接库是由编译期决定的程序、外部函数和变量构成的。编译器或者链接器会将程序和变量等内容拷贝到目标的应用 并生成一个独立的可执行对象文件。
- 动态库或者共享对象可以在多个可执行文件共享。程序使用的模块会在运行时从共享对象中加载。而不是在编译程序时打包成独立的可执行文件。
只依赖静态库并且通过静态链接生成的二进制文件因为包含了全部的依赖,能够独立执行,但是编译的结果比较大。
动态库或者共享对象在多个执行文件共享,可以减少内存占用。其链接过程实在装载或者运行期间触发的。所以可以包含一些可以热插拔的模块,并降低内存的占用。

使用静态链接编译二进制文件在部署上有非常明显的优势,最终的编译产物也可以直接运行在大多数的机器上,
静态链接带来的部署优势远比更低的内存占用显得重要,所以很多编程语言包括 Go 都将静态链接作为默认的链接方式。
- 插件系统
动态链接带来的低内存优势已经没有太大作用,
主要是可以提供灵活性,实现热插拔。
通过在主程序和共享库直接定义一系列的约定或者接口,我们可以通过以下的代码动态加载其他人编译的 Go 语言共享对象,
这样做的好处是主程序和共享库的开发者不需要共享代码,只要双方的约定不变,修改共享库后也不需要重新编译主程序。
type Driver interface {
Name() string
}
func main() {
p, err := plugin.Open("driver.so")
if err != nil {
panic(err)
}
newDriverSymbol, err := p.Lookup("NewDriver")
if err != nil {
panic(err)
}
newDriverFunc := newDriverSymbol.(func() Driver)
newDriver := newDriverFunc()
fmt.Println(newDriver.Name())
}
- 操作系统
不同的操作系统会实现不同的动态链接机制和共享库格式。
Linux中的共享对象会使用ELF格式并提供了一组操作动态链接器接口。
void *dlopen(const char *filename, int flag);
char *dlerror(void);
void *dlsym(void *handle, const char *symbol);
int dlclose(void *handle);
dlopen 会根据传入的文件名加载对应的动态库并返回一个句柄(Handle);
我们可以直接使用 dlsym 函数在该句柄中搜索特定的符号,也就是函数或者变量,它会返回该符号被加载到内存中的地址。
因为待查找的符号可能不存在于目标动态库中,所以在每次查找后我们都应该调用 dlerror 查看当前查找的结果。
动态库
Go 语言插件系统的全部实现都包含在 plugin 中,这个包实现了符号系统的加载和决议。插件是一个带有公开函数和变量的包,我们需要使用下面的命令编译插件:
go build -buildmode=plugin ...
该命令会生成一个共享对象 .so 文件,当该文件被加载到 Go 语言程序时会使用下面的结构体 plugin.Plugin 表示,该结构体中包含文件的路径以及包含的符号等信息:
type Plugin struct {
pluginpath string
syms map[string]interface{}
...
}
与插件系统相关的两个核心方法分别是用于加载共享文件的 plugin.Open 和在插件中查找符号的 plugin.Plugin.Lookup,本节将详细介绍它们的实现原理。
- CGO
plugin.pluginOpen 只是简单包装了一下标准库中的 dlopen 和 dlerror 函数并在加载成功后返回指向动态库的句柄:
static uintptr_t pluginOpen(const char* path, char** err) {
void* h = dlopen(path, RTLD_NOW|RTLD_GLOBAL);
if (h == NULL) {
*err = (char*)dlerror();
}
return (uintptr_t)h;
}
plugin.pluginLookup 使用了标准库中的 dlsym 和 dlerror 获取动态库句柄中的特定符号:
static void* pluginLookup(uintptr_t h, const char* name, char** err) {
void* r = dlsym((void*)h, name);
if (r == NULL) {
*err = (char*)dlerror();
}
return r;
}
- 加载过程
用于加载共享对象的函数 plugin.Open 会将共享对象文件的路径作为参数并返回 plugin.Plugin 结构:
func Open(path string) (*Plugin, error) {
return open(path)
}
上述函数会调用私有的函数 plugin.open 加载插件,它是插件加载过程的核心函数,我们可以将该函数拆分成以下几个步骤:
准备 C 语言函数 plugin.pluginOpen 的参数;
通过 cgo 调用 plugin.pluginOpen 并初始化加载的模块;
查找加载模块中的 init 函数并调用该函数;
通过插件的文件名和符号列表构建 plugin.Plugin 结构;
- 符号查找
plugin.Plugin.Lookup 可以在 plugin.Open 返回的结构体中查找符号 plugin.Symbol,
该符号是 interface{} 类型的一个别名,我们可以将它转换成变量或者函数真实的类型:
func (p *Plugin) Lookup(symName string) (Symbol, error) {
return lookup(p, symName)
}
func lookup(p *Plugin, symName string) (Symbol, error) {
if s := p.syms[symName]; s != nil {
return s, nil
}
return nil, errors.New("plugin: symbol " + symName + " not found in plugin " + p.pluginpath)
}
上述方法调用的私有函数 plugin.lookup 实现比较简单,它直接利用了结构体中的符号表,如果没有找到对应的符号会直接返回错误。
windows不支持,不建议使用。
代码生成
计算机程序可以生成另一个程序。
go 语言中的测试就是用了代码生成机制。
go test命令会扫描包中的测试用例并生成程序、编译、并执行。
代码生成设计原理
元编程是计算机编程中一个很重要,很有趣的概念。
元编程:一种计算机程序可以将代码 看待成数据的能力。
如果能够将代码看作数据,那么代码就可以像数据一样在运行时被修改、更新和替换。
元编程赋予了编程语言更加强大的表达能力
能够让我将一些计算过程从运行时 挪到 编译时。
通过编译期间的展开生成代码或者运行程序在运行时 改变自身的行为。
元编程就是 一种使用代码生成代码的方式 。
无论是编译期间生成代码还是 运行时改变代码的行为都是生成代码的一种。

现代的编程语言大都会为我们提供不同的元编程能力,
从总体来看,根据生成代码的时机不同,我们将元编程能力分为两种类型,
其中一种是编译期间的元编程,例如:宏和模板;
另一种是运行期间的元编程,也就是运行时,它赋予了编程语言在运行期间修改行为的能力,
当然也有一些特性既可以在编译期实现,也可以在运行期间实现。
Go 语言作为编译型的编程语言,它提供了比较有限的运行时元编程能力,例如:反射特性,然而由于性能的问题,反射在很多场景下都不被推荐使用。
当然除了反射之外,Go 语言还提供了另一种编译期间的代码生成机制 — go generate,它可以在代码编译之前根据源代码生成代码。
代码生成
Go 语言的代码生成机制会读取包含预编译指令的注释
然后执行注释中的命令读取包中的文件
它们将文件解析成抽象语法树并根据语法树生成新的 Go 语言代码和文件
生成的代码会在项目的编译期间与其他代码一起编译和运行。
//go:generate command argument...
go generate 不会被 go build 等命令自动执行,该命令需要显式的触发,手动执行该命令时会在文件中扫描上述形式的注释并执行后面的执行命令,
需要注意的是 go:generate 和前面的 // 之间没有空格,这种不包含空格的注释一般是 Go 语言的编译器指令,而我们在代码中的正常注释都应该保留这个空格
代码生成最常见的例子就是官方提供的 stringer,这个工具可以扫描如下所示的常量定义,然后为当前常量类型 Piller 生成对应的 String() 方法
// pill.go
package painkiller
//go:generate stringer -type=Pill
type Pill int
const (
Placebo Pill = iota
Aspirin
Ibuprofen
Paracetamol
Acetaminophen = Paracetamol
)
当我们在上述文件中加入 //go:generate stringer -type=Pill 注释并调用 go generate 命令时,
在同一目录下会出现如下所示的 pill_string.go 文件,该文件中包含两个函数,分别是 _ 和 String:
// Code generated by "stringer -type=Pill"; DO NOT EDIT.
package painkiller
import "strconv"
func _() {
// An "invalid array index" compiler error signifies that the constant values have changed.
// Re-run the stringer command to generate them again.
var x [1]struct{}
_ = x[Placebo-0]
_ = x[Aspirin-1]
_ = x[Ibuprofen-2]
_ = x[Paracetamol-3]
}
const _Pill_name = "PlaceboAspirinIbuprofenParacetamol"
var _Pill_index = [...]uint8{0, 7, 14, 23, 34}
func (i Pill) String() string {
if i < 0 || i >= Pill(len(_Pill_index)-1) {
return "Pill(" + strconv.FormatInt(int64(i), 10) + ")"
}
return _Pill_name[_Pill_index[i]:_Pill_index[i+1]]
}
代码生成的过程可以分成以下两个部分
扫描 Go 语言源文件,查找待执行的 //go:generate 预编译指令;
执行预编译指令,再次扫描源文件并根据源文件中的代码生成代码;
- 预编译指令
当执行go generate命令时,会调用源代码的generate.runGenerate扫描包中的预编译指令。
该函数会遍历命令行传入包中的全部文件,并依次调用 generate.generate:
func runGenerate(ctx context.Context, cmd *base.Command, args []string) {
...
for _, pkg := range load.Packages(args) {
...
pkgName := pkg.Name
for _, file := range pkg.InternalGoFiles() {
if !generate(pkgName, file) {
break
}
}
pkgName += "_test"
for _, file := range pkg.InternalXGoFiles() {
if !generate(pkgName, file) {
break
}
}
}
}
cmd/go/internal/generate.generate 会打开传入的文件并初始化一个用于扫描 cmd/go/internal/generate.Generator 的结构:
func generate(pkg, absFile string) bool {
fd, err := os.Open(absFile)
if err != nil {
log.Fatalf("generate: %s", err)
}
defer fd.Close()
g := &Generator{
r: fd,
path: absFile,
pkg: pkg,
commands: make(map[string][]string),
}
return g.run()
}
结构体 cmd/go/internal/generate.Generator 的私有方法 cmd/go/internal/generate.Generator.run 会在对应的文件中扫描指令并执行,该方法的实现原理很简单,我们在这里简单展示一下该方法的简化实现:
func (g *Generator) run() (ok bool) {
input := bufio.NewReader(g.r)
for {
var buf []byte
buf, err = input.ReadSlice('\n')
if err != nil {
if err == io.EOF && isGoGenerate(buf) {
err = io.ErrUnexpectedEOF
}
break
}
if !isGoGenerate(buf) {
continue
}
g.setEnv()
words := g.split(string(buf))
g.exec(words)
}
return true
}
上述代码片段会按行读取被扫描的文件并调用 cmd/go/internal/generate.isGoGenerate 判断当前行是否以 //go:generate 注释开头,
如果该行确定以 //go:generate 开头,那么会解析注释中的命令和参数并调用 cmd/go/internal/generate.Generator.exec 运行当前命令。
- 抽象语法树
stringer 充分利用了 Go 语言标准库对编译器各种能力的支持,
其中包括用于解析抽象语法树的 go/ast、用于格式化代码的 go/fmt 等,
Go 通过标准库中的这些包对外直接提供了编译器的相关能力,让使用者可以直接在它们上面构建复杂的代码生成机制并实施元编程技术。
作为二进制文件,stringer 命令的入口就是如下所示的 golang/tools/main.main 函数,
在下面的代码中,我们初始化了一个用于解析源文件和生成代码的 golang/tools/main.Generator,然后开始拼接生成的文件:
func main() {
types := strings.Split(*typeNames, ",")
...
g := Generator{
trimPrefix: *trimprefix,
lineComment: *linecomment,
}
...
g.Printf("// Code generated by \"stringer %s\"; DO NOT EDIT.\n", strings.Join(os.Args[1:], " "))
g.Printf("\n")
g.Printf("package %s", g.pkg.name)
g.Printf("\n")
g.Printf("import \"strconv\"\n")
for _, typeName := range types {
g.generate(typeName)
}
src := g.format()
baseName := fmt.Sprintf("%s_string.go", types[0])
outputName = filepath.Join(dir, strings.ToLower(baseName))
if err := ioutil.WriteFile(outputName, src, 0644); err != nil {
log.Fatalf("writing output: %s", err)
}
}
整个生成代码的过程就是使用编译器提供的库解析源文件并按照已有的模板生成新的代码,
这与 Web 服务中利用模板生成 HTML 文件没有太多的区别,只是生成文件的用途稍微有一些不同,
标准库
JSON
json作为一种轻量级的数据交换格式。
设计原理
几乎所有的现代编程语言都会将处理JSON的函数直接纳入标准库。
共同encoding/json对外提供标准的JSON序列化和反序列化方法。
json.Marsha1和Unmarsha1.

序列化和反序列化的开销完全不同,JSON 反序列化的开销是序列化开销的好几倍,相信这背后的原因也非常好理解。
Go 语言中的 JSON 序列化过程不需要被序列化的对象预先实现任何接口,它会通过反射获取结构体或者数组中的值并以树形的结构递归地进行编码,
标准库也会根据 encoding/json.Unmarshal 中传入的值对 JSON 进行解码。
Go 语言 JSON 标准库编码和解码的过程大量地运用了反射这一特性,
JSON 标准库中的接口和标签,这是它为开发者提供的为数不多的影响编解码过程的接口
- 接口
MarshalJSON() ([]byte, error)
}
type Unmarshaler interface {
UnmarshalJSON([]byte) error
}
在 JSON 序列化和反序列化的过程中,它会使用反射判断结构体类型是否实现了上述接口,如果实现了上述接口就会优先使用对应的方法进行编码和解码操作,除了这两个方法之外,Go 语言其实还提供了另外两个用于控制编解码结果的方法,即 encoding.TextMarshaler 和 encoding.TextUnmarshaler:
type TextMarshaler interface {
MarshalText() (text []byte, err error)
}
type TextUnmarshaler interface {
UnmarshalText(text []byte) error
}
一旦发现 JSON 相关的序列化方法没有被实现,上述两个方法会作为候选方法被 JSON 标准库调用并参与编解码的过程。
总的来说,我们可以在任意类型上实现上述这四个方法自定义最终的结果,后面的两个方法的适用范围更广,但是不会被 JSON 标准库优先调用。
- 标签
Go 语言的结构体标签也是一个比较有趣的功能,在默认情况下,当我们在序列化和反序列化结构体时,
标准库都会认为字段名和 JSON 中的键具有一一对应的关系,
然而 Go 语言的字段一般都是驼峰命名法,JSON 中下划线的命名方式相对比较常见,所以使用标签这一特性直接建立键与字段之间的映射关系是一个非常方便的设计。

JSON 中的标签由两部分组成,如下所示的 name 和 age 都是标签名,后面的所有的字符串是标签选项,即 encoding/json.tagOptions,
标签名和字段名会建立一一对应的关系,后面的标签选项也会影响编解码的过程:
type Author struct {
Name string `json:"name,omitempty"`
Age int32 `json:"age,string,omitempty"`
}
常见的两个标签是 string 和 omitempty,前者表示当前的整数或者浮点数是由 JSON 中的字符串表示的,
而另一个字段 omitempty 会在字段为零值时,直接在生成的 JSON 中忽略对应的键值对,
例如:”age”: 0、”author”: “” 等。
标准库会使用如下所示的 encoding/json.parseTag 来解析标签:
func parseTag(tag string) (string, tagOptions) {
if idx := strings.Index(tag, ","); idx != -1 {
return tag[:idx], tagOptions(tag[idx+1:])
}
return tag, tagOptions("")
}
从该方法的实现中,我们能分析出 JSON 标准库中的合法标签是什么形式的:标签名和标签选项都以 , 连接,最前面的字符串为标签名,后面的都是标签选项。
序列化
encoding/json.Marshal 是 JSON 标准库中提供的最简单的序列化函数,它会接收一个 interface{} 类型的值作为参数,
这也意味着几乎全部的 Go 语言变量都可以被 JSON 标准库序列化,为了提供如此复杂和通用的功能,在静态语言中使用反射是常见的选项,下面我们来深入了解一下它的实现:
func Marshal(v interface{}) ([]byte, error) {
e := newEncodeState()
err := e.marshal(v, encOpts{escapeHTML: true})
if err != nil {
return nil, err
}
buf := append([]byte(nil), e.Bytes()...)
encodeStatePool.Put(e)
return buf, nil
}
上述方法会调用 encoding/json.newEncodeState 从全局的编码状态池中获取 encoding/json.encodeState,随后的序列化过程都会使用这个编码状态,该结构体也会在编码结束后被重新放回池中以便重复利用。

按照如上所示的复杂调用栈,一系列的序列化方法在最后获取了对象的反射类型并调用了 encoding/json.newTypeEncoder 这个核心的编码方法,
该方法会递归地为所有的类型找到对应的编码方法,不过它的执行过程可以分成以下两个步骤:
- 获取用户自定义的 encoding/json.Marshaler 或者 encoding.TextMarshaler 编码器;
- 获取标准库中为基本类型内置的 JSON 编码器;
在该方法的第一部分,我们会检查当前值的类型是否可以使用用户自定义的编码器,这里有两种不同的判断方法:
func newTypeEncoder(t reflect.Type, allowAddr bool) encoderFunc {
if t.Kind() != reflect.Ptr && allowAddr && reflect.PtrTo(t).Implements(marshalerType) {
return newCondAddrEncoder(addrMarshalerEncoder, newTypeEncoder(t, false))
}
if t.Implements(marshalerType) {
return marshalerEncoder
}
if t.Kind() != reflect.Ptr && allowAddr && reflect.PtrTo(t).Implements(textMarshalerType) {
return newCondAddrEncoder(addrTextMarshalerEncoder, newTypeEncoder(t, false))
}
if t.Implements(textMarshalerType) {
return textMarshalerEncoder
}
...
}
如果当前值是值类型、可以取地址并且值类型对应的指针类型实现了 encoding/json.Marshaler 接口,调用 encoding/json.newCondAddrEncoder 获取一个条件编码器,条件编码器会在 encoding/json.addrMarshalerEncoder 失败时重新选择新的编码器;
如果当前类型实现了 encoding/json.Marshaler 接口,可以直接使用 encoding/json.marshalerEncoder 序列化;
在这段代码中,标准库对 encoding.TextMarshaler 的处理也几乎完全相同,只是它会先判断 encoding/json.Marshaler 接口,这也印证了我们在设计原理一节中的推测。
encoding/json.newTypeEncoder 会根据传入值的反射类型获取对应的编码器,其中包括 bool、int、float 等基本类型编码器等和数组、结构体、切片等复杂类型的编码器:
func boolEncoder(e *encodeState, v reflect.Value, opts encOpts) {
if opts.quoted {
e.WriteByte('"')
}
if v.Bool() {
e.WriteString("true")
} else {
e.WriteString("false")
}
if opts.quoted {
e.WriteByte('"')
}
}
反序列化
标准库会使用 encoding/json.Unmarshal 处理 JSON 的反序列化,与执行过程确定的序列化相比,反序列化的过程是逐渐探索的过程,所以会复杂很多,开销也会高出几倍。
因为 Go 语言的表达能力比较有限,反序列化的使用相对比较繁琐,所以需要传入一个变量帮助标准库进行反序列化:
func Unmarshal(data []byte, v interface{}) error {
var d decodeState
err := checkValid(data, &d.scan)
if err != nil {
return err
}
d.init(data)
return d.unmarshal(v)
}
JSON 本身就是一种树形的数据结构,无论是序列化还是反序列化,都会遵循自顶向下的编码和解码过程,使用递归的方式处理 JSON 对象。
作为标准库的 JSON 提供的接口非常简洁,虽然它的性能一直被开发者所诟病,但是作为框架它提供了很好的通用性,
通过分析 JSON 库的实现,我们也可以从中学习到使用反射的各种方法。
HTTP
超文本传输协议(Hypertext Transfer Protocol、HTTP 协议)是今天使用最广泛的应用层协议,1989 年由 Tim Berners-Lee 在 CERN 起草的协议已经成为了互联网的数据传输的核心1。在过去几年的时间里,HTTP/2 和 HTTP/3 也对现有的协议进行了更新,提供更加安全和快速的传输功能。多数的编程语言都会在标准库中实现 HTTP/1.1 和 HTTP/2.0 已满足工程师的日常开发需求,今天要介绍的 Go 语言的网络库也实现了这两个大版本的 HTTP 协议。
设计原理
HTTP 协议是应用层协议,在通常情况下我们都会使用 TCP 作为底层的传输层协议传输数据包,但是 HTTP/3 在 UDP 协议上实现了新的传输层协议 QUIC 并使用 QUIC 传输数据,这也意味着 HTTP 既可以跑在 TCP 上,也可以跑在 UDP 上。

Go 语言标准库通过 net/http 包提供 HTTP 的客户端和服务端实现,在分析内部的实现原理之前,我们先来了解一下 HTTP 协议相关的一些设计以及标准库内部的层级结构和模块之间的关系。
HTTP 协议中最常见的概念是 HTTP 请求与响应,我们可以将它们理解成客户端和服务端之间传递的消息,客户端向服务端发送 HTTP 请求,服务端收到 HTTP 请求后会做出计算后以 HTTP 响应的形式发送给客户端。
与其他的二进制协议不同,作为文本传输协议,HTTP 协议的协议头都是文本数据,HTTP 请求头的首行会包含请求的方法、路径和协议版本,接下来是多个 HTTP 协议头以及携带的负载
GET / HTTP/1.1
User-Agent: Mozilla/4.0 (compatible; MSIE5.01; Windows NT)
Host: draveness.me
Accept-Language: en-us
Accept-Encoding: gzip, deflate
Content-Length: <length>
Connection: Keep-Alive
<html>
...
</html>
HTTP 响应也有着比较类似的结构,其中也包含响应的协议版本、状态码、响应头以及负载,在这里就不展开介绍了。
HTTP 协议目前主要还是跑在 TCP 协议上的,TCP 协议是面向连接的、可靠的、基于字节流的传输层通信协议2,应用层交给 TCP 协议的数据并不会以消息为单位向目的主机传输,这些数据在某些情况下会被组合成一个数据段发送给目标的主机3。因为 TCP 协议是基于字节流的,所以基于 TCP 协议的应用层协议都需要自己划分消息的边界。
在应用层协议中,最常见的两种解决方案是基于长度或者基于终结符(Delimiter)。HTTP 协议其实同时实现了上述两种方案,在多数情况下 HTTP 协议都会在协议头中加入 Content-Length 表示负载的长度,消息的接收者解析到该协议头之后就可以确定当前 HTTP 请求/响应结束的位置,分离不同的 HTTP 消息,下面就是一个使用 Content-Length 划分消息边界的例子:
HTTP/1.1 200 OK
Content-Type: text/html; charset=UTF-8
Content-Length: 138
...
Connection: close
<html>
<head>
<title>An Example Page</title>
</head>
<body>
<p>Hello World, this is a very simple HTML document.</p>
</body>
</html>
不过 HTTP 协议除了使用基于长度的方式实现边界,也会使用基于终结符的策略,当 HTTP 使用块传输(Chunked Transfer)机制时,HTTP 头中就不再包含 Content-Length 了,它会使用负载大小为 0 的 HTTP 消息作为终结符表示消息的边界。
Go 语言的 net/http 中同时包好了 HTTP 客户端和服务端的实现,为了支持更好的扩展性,它引入了 net/http.RoundTripper 和 net/http.Handler 两个接口。
net/http.RoundTripper 是用来表示执行 HTTP 请求的接口,调用方将请求作为参数可以获取请求对应的响应,
而 net/http.Handler 主要用于 HTTP 服务器响应客户端的请求:
type RoundTripper interface {
RoundTrip(*Request) (*Response, error)
}
HTTP 请求的接收方可以实现 net/http.Handler 接口,其中实现了处理 HTTP 请求的逻辑,处理的过程中会调用 net/http.ResponseWriter 接口的方法构造 HTTP 响应,
它提供的三个接口 Header、Write 和 WriteHeader 分别会获取 HTTP 响应、将数据写入负载以及写入响应头:
type Handler interface {
ServeHTTP(ResponseWriter, *Request)
}
type ResponseWriter interface {
Header() Header
Write([]byte) (int, error)
WriteHeader(statusCode int)
}
客户端和服务端面对的都是双向的 HTTP 请求与响应,客户端构建请求并等待响应,服务端处理请求并返回响应。
HTTP 请求和响应在标准库中不止有一种实现,它们都包含了层级结构,标准库中的 net/http.RoundTripper 包含如下所示的层级结构:

每个 net/http.RoundTripper 接口的实现都包含了一种向远程发出请求的过程;标准库中也提供了 net/http.Handler 的多种实现为客户端的 HTTP 请求提供不同的服务。
客户端
客户端可以直接通过 net/http.Get 使用默认的客户端 net/http.DefaultClient 发起 HTTP 请求,也可以自己构建新的 net/http.Client 实现自定义的 HTTP 事务,在多数情况下使用默认的客户端都能满足我们的需求,不过需要注意的是使用默认客户端发出的请求没有超时时间,所以在某些场景下会一直等待下去。除了自定义 HTTP 事务之外,我们还可以实现自定义的 net/http.CookieJar 接口管理和使用 HTTP 请求中的 Cookie:
事务和 Cookie 是我们在 HTTP 客户端包为我们提供的两个最重要模块,本节将从 HTTP GET 请求开始,按照构建请求、数据传输、获取连接以及等待响应几个模块分析客户端的实现原理。当我们调用 net/http.Client.Get 发出 HTTP 时,会按照如下的步骤执行:
- 调用 net/http.NewRequest 根据方法名、URL 和请求体构建请求;
- 调用 net/http.Transport.RoundTrip 开启 HTTP 事务、获取连接并发送请求;
- 在 HTTP 持久连接的 net/http.persistConn.readLoop 方法中等待响应

HTTP 的客户端中包含几个比较重要的结构体,它们分别是 net/http.Client、net/http.Transport 和 net/http.persistConn:
net/http.Client 是 HTTP 客户端,它的默认值是使用 net/http.DefaultTransport 的 HTTP 客户端;
net/http.Transport 是 net/http.RoundTripper 接口的实现,它的主要作用就是支持 HTTP/HTTPS 请求和 HTTP 代理;
net/http.persistConn 封装了一个 TCP 的持久连接,是我们与远程交换消息的句柄(Handle);
客户端 net/http.Client 是级别较高的抽象,它提供了 HTTP 的一些细节,包括 Cookies 和重定向;
而 net/http.Transport 会处理 HTTP/HTTPS 协议的底层实现细节,其中会包含连接重用、构建请求以及发送请求等功能。
- 构建请求
net/http.Request 表示 HTTP 服务接收到的请求或者 HTTP 客户端发出的请求,其中包含 HTTP 请求的方法、URL、协议版本、协议头以及请求体等字段,
除了这些字段之外,它还会持有一个指向 HTTP 响应的引用:
type Request struct {
Method string
URL *url.URL
Proto string // "HTTP/1.0"
ProtoMajor int // 1
ProtoMinor int // 0
Header Header
Body io.ReadCloser
...
Response *Response
}
net/http.NewRequest 是标准库提供的用于创建请求的方法,这个方法会校验 HTTP 请求的字段并根据输入的参数拼装成新的请求结构体
func NewRequestWithContext(ctx context.Context, method, url string, body io.Reader) (*Request, error) {
if method == "" {
method = "GET"
}
if !validMethod(method) {
return nil, fmt.Errorf("net/http: invalid method %q", method)
}
u, err := urlpkg.Parse(url)
if err != nil {
return nil, err
}
rc, ok := body.(io.ReadCloser)
if !ok && body != nil {
rc = ioutil.NopCloser(body)
}
u.Host = removeEmptyPort(u.Host)
req := &Request{
ctx: ctx,
Method: method,
URL: u,
Proto: "HTTP/1.1",
ProtoMajor: 1,
ProtoMinor: 1,
Header: make(Header),
Body: rc,
Host: u.Host,
}
if body != nil {
...
}
return req, nil
}
请求拼装的过程比较简单,它会检查并校验输入的方法、URL 以及负载,然而初始化了新的 net/http.Request 结构,处理负载的过程稍微有一些复杂,我们会根据负载的类型不同,使用不同的方法将它们包装成 io.ReadCloser 类型。
- 开启事务
当我们使用标准库构建了 HTTP 请求之后,会开启 HTTP 事务发送 HTTP 请求并等待远程的响应,经过下面一连串的调用,我们最终来到了标准库实现底层 HTTP 协议的结构体 — net/http.Transport:
net/http.Client.Do
net/http.Client.do
net/http.Client.send
net/http.send
net/http.Transport.RoundTrip
net/http.Transport 实现了 net/http.RoundTripper 接口,也是整个请求过程中最重要并且最复杂的结构体,该结构体会在 net/http.Transport.roundTrip 中发送 HTTP 请求并等待响应,我们可以将该函数的执行过程分成两个部分:
- 根据 URL 的协议查找并执行自定义的 net/http.RoundTripper 实现;
- 从连接池中获取或者初始化新的持久连接并调用连接的 net/http.persistConn.roundTrip 发出请求;
我们可以在标准库的 net/http.Transport 中调用 net/http.Transport.RegisterProtocol 为不同的协议注册 net/http.RoundTripper 的实现,
在下面的这段代码中就会根据 URL 中的协议选择对应的实现来替代默认的逻辑:
func (t *Transport) roundTrip(req *Request) (*Response, error) {
ctx := req.Context()
scheme := req.URL.Scheme
if altRT := t.alternateRoundTripper(req); altRT != nil {
if resp, err := altRT.RoundTrip(req); err != ErrSkipAltProtocol {
return resp, err
}
}
...
}
在默认情况下,我们都会使用 net/http.persistConn 持久连接处理 HTTP 请求,该方法会先获取用于发送请求的连接,随后调用 net/http.persistConn.roundTrip:
func (t *Transport) roundTrip(req *Request) (*Response, error) {
...
for {
select {
case <-ctx.Done():
return nil, ctx.Err()
default:
}
treq := &transportRequest{Request: req, trace: trace}
cm, err := t.connectMethodForRequest(treq)
if err != nil {
return nil, err
}
pconn, err := t.getConn(treq, cm)
if err != nil {
return nil, err
}
resp, err := pconn.roundTrip(treq)
if err == nil {
return resp, nil
}
}
}
net/http.Transport.getConn 是获取连接的方法,该方法会通过两种方法获取用于发送请求的连接:
func (t *Transport) getConn(treq *transportRequest, cm connectMethod) (pc *persistConn, err error) {
req := treq.Request
ctx := req.Context()
w := &wantConn{
cm: cm,
key: cm.key(),
ctx: ctx,
ready: make(chan struct{}, 1),
}
if delivered := t.queueForIdleConn(w); delivered {
return w.pc, nil
}
t.queueForDial(w)
select {
case <-w.ready:
...
return w.pc, w.err
...
}
}
- 调用 net/http.Transport.queueForIdleConn 在队列中等待闲置的连接;
- 调用 net/http.Transport.queueForDial 在队列中等待建立新的连接;
连接是一种相对比较昂贵的资源,如果在每次发出 HTTP 请求之前都建立新的连接,可能会消耗比较多的时间,带来较大的额外开销,通过连接池对资源进行分配和复用可以有效地提高 HTTP 请求的整体性能,多数的网络库客户端都会采取类似的策略来复用资源。
当我们调用 net/http.Transport.queueForDial 尝试与远程建立连接时,标准库会在内部启动新的 Goroutine 执行 net/http.Transport.dialConnFor 用于建连,从最终调用的 net/http.Transport.dialConn 中我们能找到 TCP 连接和 net 库的身影:
func (t *Transport) dialConn(ctx context.Context, cm connectMethod) (pconn *persistConn, err error) {
pconn = &persistConn{
t: t,
cacheKey: cm.key(),
reqch: make(chan requestAndChan, 1),
writech: make(chan writeRequest, 1),
closech: make(chan struct{}),
writeErrCh: make(chan error, 1),
writeLoopDone: make(chan struct{}),
}
conn, err := t.dial(ctx, "tcp", cm.addr())
if err != nil {
return nil, err
}
pconn.conn = conn
pconn.br = bufio.NewReaderSize(pconn, t.readBufferSize())
pconn.bw = bufio.NewWriterSize(persistConnWriter{pconn}, t.writeBufferSize())
go pconn.readLoop()
go pconn.writeLoop()
return pconn, nil
}
在创建新的 TCP 连接后,我们还会在后台为当前的连接创建两个 Goroutine,分别从 TCP 连接中读取数据或者向 TCP 连接写入数据,从建立连接的过程我们可以发现,如果我们为每一个 HTTP 请求都创建新的连接并启动 Goroutine 处理读写数据,会占用很多的资源。
- 等待请求
持久的 TCP 连接会实现 net/http.persistConn.roundTrip 处理写入 HTTP 请求并在 select 语句中等待响应的返回:
func (pc *persistConn) roundTrip(req *transportRequest) (resp *Response, err error) {
writeErrCh := make(chan error, 1)
pc.writech <- writeRequest{req, writeErrCh, continueCh}
resc := make(chan responseAndError)
pc.reqch <- requestAndChan{
req: req.Request,
ch: resc,
}
for {
select {
case re := <-resc:
if re.err != nil {
return nil, pc.mapRoundTripError(req, startBytesWritten, re.err)
}
return re.res, nil
...
}
}
}
每个 HTTP 请求都由另一个 Goroutine 中的 net/http.persistConn.writeLoop 循环写入的,这两个 Goroutine 独立执行并通过 Channel 进行通信。
net/http.Request.write 会根据 net/http.Request 结构中的字段按照 HTTP 协议组成 TCP 数据段:
func (pc *persistConn) writeLoop() {
defer close(pc.writeLoopDone)
for {
select {
case wr := <-pc.writech:
startBytesWritten := pc.nwrite
wr.req.Request.write(pc.bw, pc.isProxy, wr.req.extra, pc.waitForContinue(wr.continueCh))
...
case <-pc.closech:
return
}
}
}
当我们调用 net/http.Request.write 向请求中写入数据时,实际上直接写入了 net/http.persistConnWriter 中的 TCP 连接中,TCP 协议栈会负责将 HTTP 请求中的内容发送到目标服务器上:
type persistConnWriter struct {
pc *persistConn
}
func (w persistConnWriter) Write(p []byte) (n int, err error) {
n, err = w.pc.conn.Write(p)
w.pc.nwrite += int64(n)
return
}
持久连接中的另一个读循环 net/http.persistConn.readLoop 会负责从 TCP 连接中读取数据并将数据发送会 HTTP 请求的调用方,真正负责解析 HTTP 协议的还是 net/http.ReadResponse:
func ReadResponse(r *bufio.Reader, req *Request) (*Response, error) {
tp := textproto.NewReader(r)
resp := &Response{
Request: req,
}
line, _ := tp.ReadLine()
if i := strings.IndexByte(line, ' '); i == -1 {
return nil, badStringError("malformed HTTP response", line)
} else {
resp.Proto = line[:i]
resp.Status = strings.TrimLeft(line[i+1:], " ")
}
statusCode := resp.Status
if i := strings.IndexByte(resp.Status, ' '); i != -1 {
statusCode = resp.Status[:i]
}
resp.StatusCode, err = strconv.Atoi(statusCode)
resp.ProtoMajor, resp.ProtoMinor, _ = ParseHTTPVersion(resp.Proto)
mimeHeader, _ := tp.ReadMIMEHeader()
resp.Header = Header(mimeHeader)
readTransfer(resp, r)
return resp, nil
}
我们在上述方法中可以看到 HTTP 响应结构的大致框架,其中包含状态码、协议版本、请求头等内容,响应体还是在读取循环 net/http.persistConn.readLoop 中根据 HTTP 协议头进行解析的。
服务器
Go 语言标准库 net/http 包提供了非常易用的接口,如下所示,我们可以利用标准库提供的功能快速搭建新的 HTTP 服务:
func handler(w http.ResponseWriter, r *http.Request) {
fmt.Fprintf(w, "Hi there, I love %s!", r.URL.Path[1:])
}
func main() {
http.HandleFunc("/", handler)
log.Fatal(http.ListenAndServe(":8080", nil))
}
上述的 main 函数只调用了两个标准库提供的函数,它们分别是用于注册处理器的 net/http.HandleFunc 函数和用于监听和处理器请求的 net/http.ListenAndServe,多数的服务器框架都会包含这两类接口,分别负责注册处理器和处理外部请求,这一种非常常见的模式,我们在这里也会按照这两个维度介绍标准库如何支持 HTTP 服务器的实现。
- 注册处理器
HTTP 服务是由一组实现了 net/http.Handler 接口的处理器组成的,处理 HTTP 请求时会根据请求的路由选择合适的处理器:

当我们直接调用 net/http.HandleFunc 注册处理器时,标准库会使用默认的 HTTP 服务器 net/http.DefaultServeMux 处理请求,该方法会直接调用 net/http.ServeMux.HandleFunc:
func (mux *ServeMux) HandleFunc(pattern string, handler func(ResponseWriter, *Request)) {
mux.Handle(pattern, HandlerFunc(handler))
}
上述方法会将处理器转换成 net/http.Handler 接口类型调用 net/http.ServeMux.Handle 注册处理器:
func (mux *ServeMux) Handle(pattern string, handler Handler) {
if _, exist := mux.m[pattern]; exist {
panic("http: multiple registrations for " + pattern)
}
e := muxEntry{h: handler, pattern: pattern}
mux.m[pattern] = e
if pattern[len(pattern)-1] == '/' {
mux.es = appendSorted(mux.es, e)
}
if pattern[0] != '/' {
mux.hosts = true
}
}
路由和对应的处理器会被组成 net/http.DefaultServeMux,该结构会持有一个 net/http.muxEntry 哈希,其中存储了从 URL 到处理器的映射关系,HTTP 服务器在处理请求时就会使用该哈希查找处理器。
- 处理请求
标准库提供的 net/http.ListenAndServe 可以用来监听 TCP 连接并处理请求,该函数会使用传入的监听地址和处理器初始化一个 HTTP 服务器 net/http.Server,调用该服务器的 net/http.Server.ListenAndServe 方法:
func ListenAndServe(addr string, handler Handler) error {
server := &Server{Addr: addr, Handler: handler}
return server.ListenAndServe()
}
net/http.Server.ListenAndServe 会使用网络库提供的 net.Listen 监听对应地址上的 TCP 连接并通过 net/http.Server.Serve 处理客户端的请求:
func (srv *Server) ListenAndServe() error {
if addr == "" {
addr = ":http"
}
ln, err := net.Listen("tcp", addr)
if err != nil {
return err
}
return srv.Serve(ln)
}
net/http.Server.Serve 会在循环中监听外部的 TCP 连接并为每个连接调用 net/http.Server.newConn 创建新的 net/http.conn,它是 HTTP 连接的服务端表示:
func (srv *Server) Serve(l net.Listener) error {
l = &onceCloseListener{Listener: l}
defer l.Close()
baseCtx := context.Background()
ctx := context.WithValue(baseCtx, ServerContextKey, srv)
for {
rw, err := l.Accept()
if err != nil {
select {
case <-srv.getDoneChan():
return ErrServerClosed
default:
}
...
return err
}
connCtx := ctx
c := srv.newConn(rw)
c.setState(c.rwc, StateNew) // before Serve can return
go c.serve(connCtx)
}
}
创建了服务端的连接之后,标准库中的实现会为每个 HTTP 请求创建单独的 Goroutine 并在其中调用 net/http.Conn.serve 方法,
如果当前 HTTP 服务接收到了海量的请求,会在内部创建大量的 Goroutine,这可能会使整个服务质量明显降低无法处理请求。
func (c *conn) serve(ctx context.Context) {
c.remoteAddr = c.rwc.RemoteAddr().String()
ctx = context.WithValue(ctx, LocalAddrContextKey, c.rwc.LocalAddr())
ctx, cancelCtx := context.WithCancel(ctx)
c.cancelCtx = cancelCtx
defer cancelCtx()
c.r = &connReader{conn: c}
c.bufr = newBufioReader(c.r)
c.bufw = newBufioWriterSize(checkConnErrorWriter{c}, 4<<10)
for {
w, _ := c.readRequest(ctx)
serverHandler{c.server}.ServeHTTP(w, w.req)
w.finishRequest()
...
}
}
上述代码片段是我们简化后的连接处理过程,其中包含读取 HTTP 请求、调用 Handler 处理 HTTP 请求以及调用完成该请求。读取 HTTP 请求会调用 net/http.Conn.readRequest,该方法会从连接中获取 HTTP 请求并构建一个实现了 net/http.ResponseWriter 接口的变量 net/http.response,向该结构体写入的数据都会被转发到它持有的缓冲区中:
func (w *response) write(lenData int, dataB []byte, dataS string) (n int, err error) {
...
w.written += int64(lenData)
if w.contentLength != -1 && w.written > w.contentLength {
return 0, ErrContentLength
}
if dataB != nil {
return w.w.Write(dataB)
} else {
return w.w.WriteString(dataS)
}
}
解析了 HTTP 请求并初始化 net/http.ResponseWriter 之后,我们就可以调用 net/http.serverHandler.ServeHTTP 查找处理器来处理 HTTP 请求了:
type serverHandler struct {
srv *Server
}
func (sh serverHandler) ServeHTTP(rw ResponseWriter, req *Request) {
handler := sh.srv.Handler
if handler == nil {
handler = DefaultServeMux
}
if req.RequestURI == "*" && req.Method == "OPTIONS" {
handler = globalOptionsHandler{}
}
handler.ServeHTTP(rw, req)
}
如果当前的 HTTP 服务器中不包含任何处理器,我们会使用默认的 net/http.DefaultServeMux 处理外部的 HTTP 请求。
net/http.ServeMux 是一个 HTTP 请求的多路复用器,它可以接收外部的 HTTP 请求、根据请求的 URL 匹配并调用最合适的处理器:
func (mux *ServeMux) ServeHTTP(w ResponseWriter, r *Request) {
h, _ := mux.Handler(r)
h.ServeHTTP(w, r)
}
经过一系列的函数调用,上述过程最终会调用 HTTP 服务器的 net/http.ServerMux.match,该方法会遍历前面注册过的路由表并根据特定规则进行匹配:
func (mux *ServeMux) match(path string) (h Handler, pattern string) {
v, ok := mux.m[path]
if ok {
return v.h, v.pattern
}
for _, e := range mux.es {
if strings.HasPrefix(path, e.pattern) {
return e.h, e.pattern
}
}
return nil, ""
}
如果请求的路径和路由中的表项匹配成功,我们会调用表项中对应的处理器,处理器中包含的业务逻辑会通过 net/http.ResponseWriter 构建 HTTP 请求对应的响应并通过 TCP 连接发送回客户端。
Go 语言的 HTTP 标准库提供了非常丰富的功能,很多语言的标准库只提供了最基本的功能,实现 HTTP 客户端和服务器往往都需要借助其他开源的框架,但是 Go 语言的很多项目都会直接使用标准库实现 HTTP 服务器,这也从侧面说明了 Go 语言标准库的价值。
数据库
设计原理
结构化查询语言 structured query language SQL.是在关系型数据库系统中使用的领域特定语言 Domanin-Specific Language DSL.
主要用于处理结构化的数据。有更加强大的表达能力。
- 可以使用单个命令在数据库中访问多条数据
- 不需要在查询中指定获取数据的方法。
所有的关系型数据库都会提供 SQL 作为查询语言,应用程序可以使用相同的 SQL 查询在不同数据库中查询数据,当然不同的数据库在实现细节和接口上还略有一些不同,这些不兼容的特性在不同数据库中仍然无法通用,例如:PostgreSQL 中的几何类型,不过它们基本都会兼容标准的 SQL 查询以方便应用程序接入:
SQL 是应用程序和数据库之间的中间层,应用程序在多数情况下都不需要关心底层数据库的实现,它们只关心 SQL 查询返回的数据。
Go 语言的 database/sql 就建立在上述前提下,我们可以使用相同的 SQL 语言查询关系型数据库,所有关系型数据库的客户端都需要实现如下所示的驱动接口:

type Driver interface {
Open(name string) (Conn, error)
}
type Conn interface {
Prepare(query string) (Stmt, error)
Close() error
Begin() (Tx, error)
}
database/sql/driver.Driver 接口中只包含一个 Open 方法,该方法接收一个数据库连接串作为输入参数并返回一个特定数据库的连接,作为参数的数据库连接串是数据库特定的格式,这个返回的连接仍然是一个接口,整个标准库中的全部接口可以构成如下所示的树形结构:

MySQL 的驱动 go-sql-driver/mysql 就实现了上图中的树形结构,我们可以使用语言原生的接口在 MySQL 中查询或者管理数据。
驱动接口
我们在这里从 database/sql 标准库提供的几个方法为入口分析这个中间层的实现原理,其中包括数据库驱动的注册、获取数据库连接和查询数据,这些方法都是我们在与数据库打交道时的最常用接口。
database/sql 中提供的 database/sql.Register 方法可以注册自定义的数据库驱动,这个 package 的内部包含两个变量,分别是 drivers 哈希以及 driversMu 互斥锁,所有的数据库驱动都会存储在这个哈希中:
func Register(name string, driver driver.Driver) {
driversMu.Lock()
defer driversMu.Unlock()
if driver == nil {
panic("sql: Register driver is nil")
}
if _, dup := drivers[name]; dup {
panic("sql: Register called twice for driver " + name)
}
drivers[name] = driver
}
MySQL 驱动会在 go-sql-driver/mysql/mysql.init 中调用上述方法将实现 database/sql/driver.Driver 接口的结构体注册到全局的驱动列表中:
func init() {
sql.Register("mysql", &MySQLDriver{})
}
当我们在全局变量中注册了驱动之后,就可以使用 database/sql.Open 方法获取特定数据库的连接。在如下所示的方法中,我们通过传入的驱动名获取 database/sql/driver.Driver 组成 database/sql.dsnConnector 结构体后调用 database/sql.OpenDB:
func Open(driverName, dataSourceName string) (*DB, error) {
driversMu.RLock()
driveri, ok := drivers[driverName]
driversMu.RUnlock()
if !ok {
return nil, fmt.Errorf("sql: unknown driver %q (forgotten import?)", driverName)
}
...
return OpenDB(dsnConnector{dsn: dataSourceName, driver: driveri}), nil
}
database/sql.OpenDB 会返回一个 database/sql.DB 结构,这是标准库包为我们提供的关键结构体,无论是我们直接使用标准库查询数据库,还是使用 GORM 等 ORM 框架都会用到它:
func OpenDB(c driver.Connector) *DB {
ctx, cancel := context.WithCancel(context.Background())
db := &DB{
connector: c,
openerCh: make(chan struct{}, connectionRequestQueueSize),
lastPut: make(map[*driverConn]string),
connRequests: make(map[uint64]chan connRequest),
stop: cancel,
}
go db.connectionOpener(ctx)
return db
}
结构体 database/sql.DB 在刚刚初始化时不会包含任何的数据库连接,它持有的数据库连接池会在真正应用程序申请连接时在单独的 Goroutine 中获取。database/sql.DB.connectionOpener 方法中包含一个不会退出的循环,每当该 Goroutine 收到了请求时都会调用 database/sql.DB.openNewConnection:
func (db *DB) openNewConnection(ctx context.Context) {
ci, _ := db.connector.Connect(ctx)
...
dc := &driverConn{
db: db,
createdAt: nowFunc(),
returnedAt: nowFunc(),
ci: ci,
}
if db.putConnDBLocked(dc, err) {
db.addDepLocked(dc, dc)
} else {
db.numOpen--
ci.Close()
}
}
数据库结构体 database/sql.DB 中的链接器是实现了 database/sql/driver.Connector 类型的接口,我们可以使用该接口创建任意数量完全等价的连接,创建的所有连接都会被加入连接池中,MySQL 的驱动在 go-sql-driver/mysql/mysql.connector.Connect 方法实现了连接数据库的逻辑。
无论是使用 ORM 框架还是直接使用标准库,当我们在查询数据库时都会调用 database/sql.DB.Query 方法,该方法的入参就是 SQL 语句和 SQL 语句中的参数,它会初始化新的上下文并调用 database/sql.DB.QueryContext:
func (db *DB) QueryContext(ctx context.Context, query string, args ...interface{}) (*Rows, error) {
var rows *Rows
var err error
for i := 0; i < maxBadConnRetries; i++ {
rows, err = db.query(ctx, query, args, cachedOrNewConn)
if err != driver.ErrBadConn {
break
}
}
if err == driver.ErrBadConn {
return db.query(ctx, query, args, alwaysNewConn)
}
return rows, err
}
database/sql.DB.query 的执行过程可以分成两个部分,首先调用私有方法 database/sql.DB.conn 获取底层数据库的连接,数据库连接既可能是刚刚通过连接器创建的,也可能是之前缓存的连接;获取连接之后调用 database/sql.DB.queryDC 在特定的数据库连接上执行查询:
func (db *DB) queryDC(ctx, txctx context.Context, dc *driverConn, releaseConn func(error), query string, args []interface{}) (*Rows, error) {
queryerCtx, ok := dc.ci.(driver.QueryerContext)
var queryer driver.Queryer
if !ok {
queryer, ok = dc.ci.(driver.Queryer)
}
if ok {
var nvdargs []driver.NamedValue
var rowsi driver.Rows
var err error
withLock(dc, func() {
nvdargs, err = driverArgsConnLocked(dc.ci, nil, args)
if err != nil {
return
}
rowsi, err = ctxDriverQuery(ctx, queryerCtx, queryer, query, nvdargs)
})
if err != driver.ErrSkip {
if err != nil {
releaseConn(err)
return nil, err
}
rows := &Rows{
dc: dc,
releaseConn: releaseConn,
rowsi: rowsi,
}
rows.initContextClose(ctx, txctx)
return rows, nil
}
}
...
}
上述方法在准备了 SQL 查询所需的参数之后,会调用 database/sql.ctxDriverQuery 完成 SQL 查询,我们会判断当前的查询上下文究竟实现了哪个接口,然后调用对应接口的 Query 或者 QueryContext:
func ctxDriverQuery(ctx context.Context, queryerCtx driver.QueryerContext, queryer driver.Queryer, query string, nvdargs []driver.NamedValue) (driver.Rows, error) {
if queryerCtx != nil {
return queryerCtx.QueryContext(ctx, query, nvdargs)
}
dargs, err := namedValueToValue(nvdargs)
if err != nil {
return nil, err
}
...
return queryer.Query(query, dargs)
}
对应的数据库驱动会真正负责执行调用方输入的 SQL 查询,作为中间层的标准库可以不在乎具体的实现,抹平不同关系型数据库的差异,为用户程序提供统一的接口。
Go 语言的标准库 database/sql 是一个抽象层的经典例子,虽然关系型数据库的功能相对比较复杂,但是我们仍然可以通过定义一系列构成树形结构的接口提供合理的抽象,这也是我们在编写框架和中间层时应该注意的,即面向接口编程 —— 只依赖抽象的接口,不要依赖具体的实现。


