Kotlin协程解析系列(上):协程调度与挂起
vivo 互联网客户端团队- Ruan Wen
本文是Kotlin协程解析系列文章的开篇,主要介绍Kotlin协程的创建、协程调度与协程挂起相关的内容
一、协程引入
Kotlin 中引入 Coroutine(协程) 的概念,可以帮助编写异步代码。
在使用和分析协程前,首先要了解一下:
协程是什么?
为什么需要协程?
协程最为人称道的就是可以用看起来同步的方式写出异步的代码,极大提高了代码的可读性。在实际开发中最常见的异步操作莫过于网络请求。通常我们需要通过各种回调的方式去处理网络请求,很容易就陷入到地狱回调中。
WalletHttp.target(VCoinTradeSubmitResult.class).setTag(tag)
.setFullUrl(Constants.VCOIN_TRADE_SUBMIT_URL).setParams(params)
.callback(new HttpCallback<VCoinTradeSubmitResult>() {
@Override
public void onSuccess(VCoinTradeSubmitResult vCoinTradeSubmitResult) {
super.onSuccess(vCoinTradeSubmitResult);
if (mView == null) {
return;
}
//......
}
}).post();
上述示例是一个项目开发中常见的一个网络请求操作,通过接口回调的方式去获取网络请求结果。实际开发中也会经常遇到连续多个接口请求的情况,例如我们项目中的个人中心页的逻辑就是先去异步获取。
本地缓存,获取失败的话就需要异步刷新一下账号token,然后网络请求相关个人中心的其他信息。这里简单举一个支付示例,进行支付时,可能要先去获取账号token,然后依赖该token再去做支付。
请求操作,根据支付返回数据再去查询支付结果,这种情况通过回调就可能演变为“地狱回调”。
//获取账号token
WalletHttp.target(Account.class).setTag(tag)
.setFullUrl(Constants.ACCOUNT_URL).setParams(params)
.callback(new HttpCallback<Account>() {
@Override
public void onSuccess(Account account) {
super.onSuccess(account);
//根据账号token进行支付操作
WalletHttp.target(Pay.class).setFullUrl(Constants.PAY_URL).addToken(account.getToken()).callback(new HttpCallback<Pay>() {
@Override
public void onSuccess(Pay pay){
super.onSuccess(pay);
//根据支付操作返回查询支付结果
WalletHttp.target(PayResult.class).setFullUrl(Constants.RESULT_URL).addResultCode(pay.getResultCode()).callback(new HttpCallback<PayResult>() {
@Override
public void onSuccess(PayResult result){
super.onSuccess(result);
//......
}
}).post();
}
}).post();
}
}).post();
对于这种场景,kotlin协程“同步方式写出异步代码”的这个特性就可以很好的解决上述问题。若上述场景用kotlin 协程代码实现呢,可能就为:
fun postItem(tag: String, params: Map<String, Any?>) = viewModelScope.launch {
// 获取账号信息
val account = repository.queryAccount(tag, params)
// 进行支付操作
val pay = repository.paySubmit(tag,account.token)
//查询支付结果
val result = repository.queryPayResult(tag,pay.resultCode)
//......
}
可以看出,协程代码非常简洁,以顺序的方式书写异步代码,代码可读性极强。
如果想要将原先的网络回调请求也改写成这种同步模式呢,只需要对原先请求回调用协程提供的suspendCancellableCoroutine等方法进行封装处理,即可让早期的异步代码也享受上述“同步代码”的丝滑。
协程:
一种非抢占式或者协作式的计算机程序并发调度实现,程序可以主动挂起或者恢复执行,其核心点是函数或一段程序能够被挂起,稍后再在挂起的位置恢复,通过主动让出运行权来实现协作,程序自己处理挂起和恢复来实现程序执行流程的协作调度。
协程本质上是轻量级线程。
协程的特点有:
协程可以让异步代码同步化,其本质是轻量级线程。
可在单个线程运行多个协程,其支持挂起,不会使运行协程的线程阻塞。
可以降低异步程序的设计复杂度。
Kotlin协程实现层次:
基础设施层:标准库的协程API,主要对协程提供了概念和语义上最基本的支持;
业务框架层:协程的上层框架支持,基于标准库实现的封装,也是我们日常开发使用的协程扩展库。

二、协程启动
具体在使用协程前,首先要配置对Kotlin协程的依赖。
(1)项目根目录build.gradle
buildscript {
...
ext.kotlin_coroutines = 'xxx'
...
}
(2)Module下build.gradle
dependencies {
...
//协程标准库
implementation "org.jetbrains.kotlin:kotlin-stdlib:$kotlin_coroutines"
//依赖协程核心库,包含协程公共API部分
implementation "org.jetbrains.kotlinx:kotlinx-coroutines-core:$kotlin_coroutines"
//依赖android支持库,协程Android平台的具体实现方式
implementation "org.jetbrains.kotlinx:kotlinx-coroutines-android:$kotlin_coroutines"
...
}
2.1 Thread 启动
在Java中,可以通过Thread开启并发操作:
new Thread(new Runnable() {
@Override
public void run() {
//... do what you want
}
}).start();
在Kotlin中,使用线程更为便捷:
val myThread = thread {
//.......
}
这个Thread方法有个参数start默认为true,即创造出来的线程默认启动,你可以自定义启动时机:
val myThread = thread(start = false) {
//......
}
myThread.start()
2.2 协程启动
动协程需要三部分:上下文、启动模式、协程体。
启动方式一般有三种,其中最简单的启动协程的方式为:
GlobalScope.launch {
//......
}
GlobalScope.launch()属于协程构建器Coroutine builders,Kotlin 中还有其他几种 Builders,负责创建协程:
runBlocking:T
使用runBlocking顶层函数创建,会创建一个新的协程同时阻塞当前线程,直到协程结束。适用于main函数和单元测试
launch
创建一个新的协程,不会阻塞当前线程,必须在协程作用域中才可以调用。它返回的是一个该协程任务的引用,即Job对象。这是最常用的启动协程的方式。
async
创建一个新的协程,不会阻塞当前线程,必须在协程作用域中才可以调用,并返回Deffer对象。可通过调用Deffer.await()方法等待该子协程执行完成并获取结果。常用于并发执行-同步等待和获取返回值的情况。
2.2.1 runBlocking
public fun <T> runBlocking(context: CoroutineContext = EmptyCoroutineContext, block: suspend CoroutineScope.() -> T): T
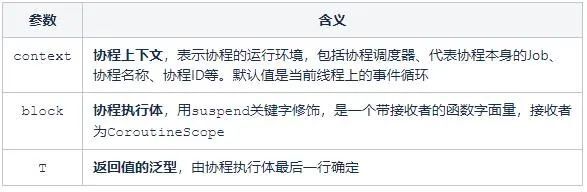
runBlocking是一个顶层函数,可以在任意地方独立使用。它能创建一个新的协程同时阻塞当前线程,直到其内部所有逻辑以及子协程所有逻辑全部执行完成。常用于main函数和测试中。
//main函数中应用
fun main() = runBlocking {
launch { // 创建一个新协程,runBlocking会阻塞线程,但内部运行的协程是非阻塞的
delay(1000L)
println("World!")
}
println("Hello,")
delay(2000L) // 延时2s,保证JVM存活
}
//测试中应用
class MyTest {
@Test
fun testMySuspendingFunction() = runBlocking {
// ......
}
}
2.2.2 launch
launch是最常用的用于启动协程的方式,会在不阻塞当前线程的情况下启动一个协程,并返回对该协程任务的引用,即Job对象。
public fun CoroutineScope.launch(
context: CoroutineContext = EmptyCoroutineContext,
start: CoroutineStart = CoroutineStart.DEFAULT,
block: suspend CoroutineScope.() -> Unit
): Job
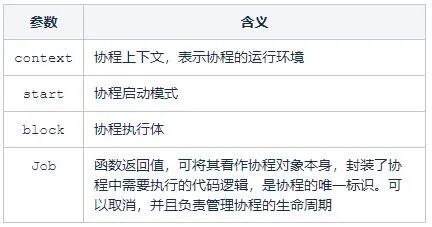
协程需要运行在协程上下文环境中,在非协程环境中的launch有两种:GlobalScope 与 CoroutineScope 。
- GlobalScope.launch()
在应用范围内启动一个新协程,不会阻塞调用线程,协程的生命周期与应用程序一致。
fun launchTest() {
print("start")
GlobalScope.launch {
delay(1000)//1秒无阻塞延迟
print("GlobalScope.launch")
}
print("end")
}
/** 打印结果
start
end
GlobalScope.launch
*/
这种启动的协程存在组件被销毁但协程还存在的情况,一般不推荐。其中GlobalScope本身就是一个作用域,launch属于其子作用域。
- CoroutineScope.launch()
启动一个新的协程而不阻塞当前线程,并返回对协程的引用作为一个Job。
fun launchTest2() {
print("start")
val job = CoroutineScope(Dispatchers.IO).launch {
delay(1000)
print("CoroutineScope.launch")
}
print("end")
}
协程上下文控制协程生命周期和线程调度,使得协程和该组件生命周期绑定,组件销毁时,协程一并销毁,从而实现安全可靠地协程调用。这是在应用中最推荐的协程使用方式。
关于launch,根据业务需求需要创建一个或多个协程,则可能就需要在一个协程中启动子协程。
fun launchTest3() {
print("start")
GlobalScope.launch {
delay(1000)
print("CoroutineScope.launch")
//在协程内创建子协程
launch {
delay(1500)
print("launch 子协程")
}
}
print("end")
}
/**** 打印结果
start
end
CoroutineScope.launch
launch 子协程
*/
2.2.3 async
async类似于launch,都是创建一个不会阻塞当前线程的新的协程。区别在于:async的返回是Deferred对象,可通过Deffer.await()等待协程执行完成并获取结果,而 launch 不行。常用于并发执行-同步等待和获取返回值的情况。
public fun <T> CoroutineScope.async(
context: CoroutineContext = EmptyCoroutineContext,
start: CoroutineStart = CoroutineStart.DEFAULT,
block: suspend CoroutineScope.() -> T
): Deferred<T>

注意:
-
await() 不能在协程之外调用,因为它需要挂起直到计算完成,而且只有协程可以以非阻塞的方式挂起。所以把它放到协程中。
-
如果Deferred不执行await()则async内部抛出的异常不会被logCat或try Catch捕获,但是依然会导致作用域取消和异常崩溃; 但当执行await时异常信息会重新抛出
-
如果将async函数中的启动模式设置为CoroutineStart.LAZY懒加载模式时则只有调用Deferred对象的await时(或者执行async.satrt())才会开始执行异步任务。
三、协程补充知识
在叙述协程启动内容,涉及到了Job、Deferred、启动模式、作用域等概念,这里补充介绍一下上述概念。
3.1 Job
Job 是协程的句柄,赋予协程可取消,赋予协程以生命周期,赋予协程以结构化并发的能力。
Job是launch构建协程返回的一个协程任务,完成时是没有返回值的。可以把Job看成协程对象本身,封装了协程中需要执行的代码逻辑,协程的操作方法都在Job身上。Job具有生命周期并且可以取消,它也是上下文元素,继承自CoroutineContext。
在日常 Android 开发过程中,协程配合 Lifecycle 可以做到自动取消。
Job生命周期
Job 的生命周期分为 6 种状态,分为
-
New
-
Active
-
Completing
-
Cancelling
-
Cancelled
-
Completed
通常外界会持有 Job 接口作为引用被协程调用者所持有。Job 接口提供 isActive、isCompleted、isCancelled 3 个变量使外界可以感知 Job 内部的状态。

val job = launch(start = CoroutineStart.LAZY) {
println("Active")
}
println("New")
job.join()
println("Completed")
/**打印结果**/
New
Active
Completed
/**********
* 1. 以 lazy 方式创建出来的协程 state 为 New
* 2. 对应的 job 调用 join 函数后,协程进入 Active 状态,并开始执行协程对应的具体代码
* 3. 当协程执行完毕后,由于没有需要等待的子协程,协程直接进入 Completed 状态
*/
关于Job,常用的方法有:
//活跃的,是否仍在执行
public val isActive: Boolean
//启动协程,如果启动了协程,则为true;如果协程已经启动或完成,则为false
public fun start(): Boolean
//取消Job,可通过传入Exception说明具体原因
public fun cancel(cause: CancellationException? = null)
//挂起协程直到此Job完成
public suspend fun join()
//取消任务并等待任务完成,结合了[cancel]和[join]的调用
public suspend fun Job.cancelAndJoin()
//给Job设置一个完成通知,当Job执行完成的时候会同步执行这个函数
public fun invokeOnCompletion(handler: CompletionHandler): DisposableHandle
Job父子层级
对于Job,还需要格外关注的是Job的父子层级关系。
-
一个Job可以包含多个子Job。
-
当父Job被取消后,所有的子Job也会被自动取消。
-
当子Job被取消或者出现异常后父Job也会被取消。
-
具有多个子 Job 的父Job 会等待所有子Job完成(或者取消)后,自己才会执行完成。
3.2 Deferred
Deferred继承自Job,具有与Job相同的状态机制。
它是async构建协程返回的一个协程任务,可通过调用await()方法等待协程执行完成并获取结果。其中Job没有结果值,Deffer有结果值。
public interface Deferred<out T> : Job
3.3 作用域
协程作用域(CoroutineScope):协程定义的作用范围,本质是一个接口。
确保所有的协程都会被追踪,Kotlin 不允许在没有使用CoroutineScope的情况下启动新的协程。CoroutineScope可被看作是一个具有超能力的ExecutorService的轻量级版本。它能启动新的协程,同时这个协程还具备suspend和resume的优势。
每个协程生成器launch、async等都是CoroutineScope的扩展,并继承了它的coroutineContext,自动传播其所有元素和取消。
启动协程需要作用域,但是作用域又是在协程创建过程中产生的。
public interface CoroutineScope {
/**
* 此域的上下文。Context被作用域封装,用于在作用域上扩展的协程构建器的实现。
*/
public val coroutineContext: CoroutineContext
}
官方提供的常用作用域:
- runBlocking:
顶层函数,可启动协程,但会阻塞当前线程
- GlobalScope
全局协程作用域。通过GlobalScope创建的协程不会有父协程,可以把它称为根协程。它启动的协程的生命周期只受整个应用程序的生命周期的限制,且不能取消,在运行时会消耗一些内存资源,这可能会导致内存泄露,不适用于业务开发。
- coroutineScope
创建一个独立的协程作用域,直到所有启动的协程都完成后才结束自身。
它是一个挂起函数,需要运行在协程内或挂起函数内。当这个作用域中的任何一个子协程失败时,这个作用域失败,所有其他的子协程都被取消。
- supervisorScope
与coroutineScope类似,不同的是子协程的异常不会影响父协程,也不会影响其他子协程。(作用域本身的失败(在block或取消中抛出异常)会导致作用域及其所有子协程失败,但不会取消父协程。)
- MainScope
为UI组件创建主作用域。一个顶层函数,上下文是SupervisorJob() + Dispatchers.Main,说明它是一个在主线程执行的协程作用域,通过cancel对协程进行取消。
fun scopeTest() {
GlobalScope.launch {//父协程
launch {//子协程
print("GlobalScope的子协程")
}
launch {//第二个子协程
print("GlobalScope的第二个子协程")
}
}
val mainScope = MainScope()
mainScope.launch {//启动协程
//todo
}
}
Jetpack 的Lifecycle相关组件提供了已经绑定UV声明周期的作用域供我们直接使用:
- lifecycleScope:
Lifecycle Ktx库提供的具有生命周期感知的协程作用域,与Lifecycle绑定生命周期,生命周期被销毁时,此作用域将被取消。会与当前的UI组件绑定生命周期,界面销毁时该协程作用域将被取消,不会造成协程泄漏,推荐使用。
- viewModelScope:
与lifecycleScope类似,与ViewModel绑定生命周期,当ViewModel被清除时,这个作用域将被取消。推荐使用。
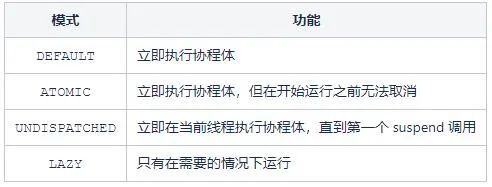
3.4 启动模式
前述进行协程创建启动时涉及到了启动模式CoroutineStart,其是一个枚举类,为协程构建器定义启动选项。在协程构建的start参数中使用。
DEFAULT模式
DEFAULT 是饿汉式启动,launch 调用后,会立即进入待调度状态,一旦调度器 OK 就可以开始执行。
suspend fun main() {
log(1)
val job = GlobalScope.launch{
log(2)
}
log(3)
Thread.sleep(5000) //防止程序退出
}
fun log(o: Any?) {
println("[${Thread.currentThread().name}]:$o")
}
前述示例代码采用默认的启动模式和默认的调度器,,运行结果取决于当前线程与后台线程的调度顺序。
/**可能的运行结果一****/
[main]:1
[main]:3
[main]:2
/**可能的运行结果二****/
[main]:1
[main]:2
[main]:3
LAZY模式
LAZY 是懒汉式启动,launch 后并不会有任何调度行为,协程体不会进入执行状态,直到我们需要他的运行结果时进行执行,其launch 调用后会返回一个 Job 实例。
对于这种情况,可以:
-
调用Job.start,主动触发协程的调度执行
-
调用Job.join,隐式的触发协程的调度执行
suspend fun main() {
log(1)
val job = GlobalScope.launch(start = CoroutineStart.LAZY){
log(2)
}
log(3)
job.join()
log(4)
}
fun log(o: Any?) {
println("[${Thread.currentThread().name}]:$o")
}
对于join,一定要等待协程执行完毕,所以其运行结果一定为:
[main]:1
[main]:3
[DefaultDispatcher-worker-1]:2
[main]:4
如果把join()换为start(),则输出结果不一定。
ATOMIC模式
ATOMIC 只有涉及 cancel 的时候才有意义。调用cancel的时机不同,结果也有差异。
suspend fun main() {
log(1)
val job = GlobalScope.launch(start = CoroutineStart.ATOMIC){
log(2)
}
job.cancel()
log(3)
Thread.sleep(2000)
}
fun log(o: Any?) {
println("[${Thread.currentThread().name}]:$o")
}
前述代码示例创建协程后立即cancel,由于是ATOMIC模式,因此协程一定会被调度,则log 1、2、3一定都会被打印输出。如果将模式改为DEFAULT模式,则log 2有可能打印输出,也可能不会。
其实cancel 调用一定会将该 job 的状态置为 cancelling,只不过ATOMIC 模式的协程在启动时无视了这一状态。
suspend fun main() {
log(1)
val job = GlobalScope.launch(start = CoroutineStart.ATOMIC) {
log(2)
delay(1000)
log(3)
}
job.cancel()
log(4)
job.join()
Thread.sleep(2000)
}
fun log(o: Any?) {
println("[${Thread.currentThread().name}]:$o")
}
/**打印输出结果可能如下****/
[main]:1
[DefaultDispatcher-worker-1]:2
[main]:4
前述代码中,2和3中加了一个delay,delay会使得协程体的执行被挂起,1000ms 之后再次调度后面的部分。对于 ATOMIC 模式,它一定会被启动,实际上在遇到第一个挂起点之前,它的执行是不会停止的,而 delay 是一个 suspend 函数,这时我们的协程迎来了自己的第一个挂起点,恰好 delay 是支持 cancel 的,因此后面的 3 将不会被打印。
UNDISPATCHED模式
协程在这种模式下会直接开始在当前线程下执行,直到第一个挂起点。
与ATOMIC的不同之处在于 UNDISPATCHED 不经过任何调度器即开始执行协程体。遇到挂起点之后的执行就取决于挂起点本身的逻辑以及上下文当中的调度器了。
suspend fun main() {
log(1)
val job = GlobalScope.launch(start = CoroutineStart.UNDISPATCHED) {
log(2)
delay(100)
log(3)
}
log(4)
job.join()
log(5)
Thread.sleep(2000)
}
fun log(o: Any?) {
println("[${Thread.currentThread().name}]:$o")
}
协程启动后会立即在当前线程执行,因此 1、2 会连续在同一线程中执行,delay 是挂起点,因此 3 会等 100ms 后再次调度,这时候 4 执行,join 要求等待协程执行完,因此等 3 输出后再执行 5。
结果如下:
[main]:1
[main]:2
[main]:4
[DefaultDispatcher-worker-1]:3
[DefaultDispatcher-worker-1]:5
3.5 withContext
withContext {}不会创建新的协程。在指定协程上运行挂起代码块,放在该块内的任何代码都始终通过IO调度器执行,并挂起该协程直至代码块运行完成。
public suspend fun <T> withContext(
context: CoroutineContext,
block: suspend CoroutineScope.() -> T
): T
withContext会使用新指定的上下文的dispatcher,将block的执行转移到指定的线程中。
它会返回结果, 可以和当前协程的父协程存在交互关系, 主要作用为了来回切换调度器。
coroutineScope{
launch(Dispatchers.Main) { // 在 UI 线程开始
val image = withContext(Dispatchers.IO) { // 切换到 IO 线程,并在执行完成后切回 UI 线程
getImage(imageId) // 将会运行在 IO 线程
}
avatarIv.setImageBitmap(image) // 回到 UI 线程更新 UI
}
}
四、协程调度
4.1 协程上下文
在协程启动部分提到,启动协程需要三个部分,其中一个部分就是上下文,其接口类型是CoroutineContext,通常所见的上下文类型是CombinedContext或者EmptyCoroutineContext,一个表示上下文组合,另一个表示空。
协程上下文是Kotlin协程的基本结构单元,主要承载着资源获取,配置管理等工作,是执行环境的通用数据资源的统一管理者。除此之外,也包括携带参数,拦截协程执行等,是实现正确的线程行为、生命周期、异常以及调试的关键。
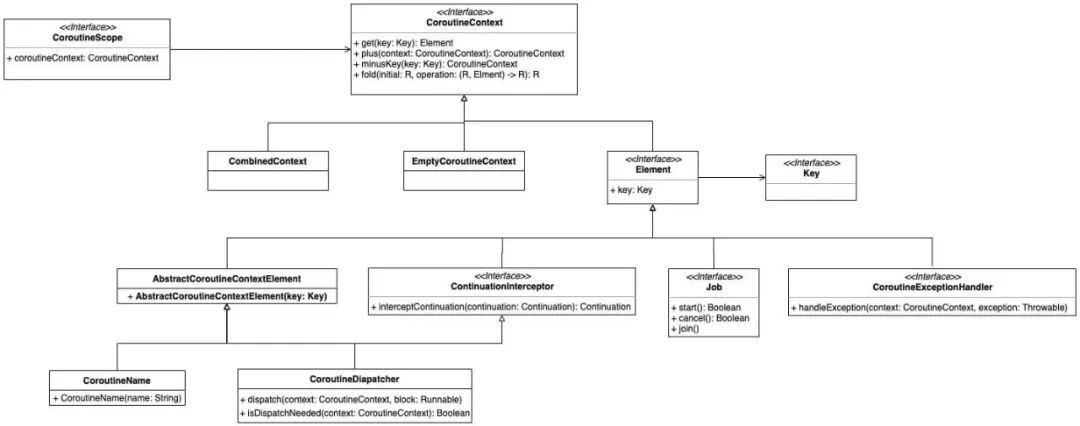
协程使用以下几种元素集定义协程行为,他们均继承自CoroutineContext:
【Job】:协程的句柄,对协程的控制和管理生命周期。
【CoroutineName】:协程的名称,用于调试
【CoroutineDispatcher】:调度器,确定协程在指定的线程执行
【CoroutineExceptionHandler】:协程异常处理器,处理未捕获的异常
这里回顾一下launch和async两个函数签名。
public fun CoroutineScope.launch(
context: CoroutineContext = EmptyCoroutineContext,
start: CoroutineStart = CoroutineStart.DEFAULT,
block: suspend CoroutineScope.() -> Unit
): Job
public fun <T> CoroutineScope.async(
context: CoroutineContext = EmptyCoroutineContext,
start: CoroutineStart = CoroutineStart.DEFAULT,
block: suspend CoroutineScope.() -> T
): Deferred<T>
两个函数第一个参数都是CoroutineContext类型。
所有协程构建函数都是以CoroutineScope的扩展函数的形式被定义的,而CoroutineScope的接口唯一成员就是CoroutineContext类型。
public interface CoroutineScope {
public val coroutineContext: CoroutineContext
}
简而言之,协程上下文是协程必备组成部分,管理了协程的线程绑定、生命周期、异常处理和调试。
4.1.1 协程上下文结构
看一下CoroutineContext的接口方法:
public interface CoroutineContext {
//操作符[]重载,可以通过CoroutineContext[Key]这种形式来获取与Key关联的Element
public operator fun <E : Element> get(key: Key<E>): E?
//提供遍历CoroutineContext中每一个Element的能力,并对每一个Element做operation操作
public fun <R> fold(initial: R, operation: (R, Element) -> R): R
//操作符+重载,可以CoroutineContext + CoroutineContext这种形式把两个CoroutineContext合并成一个
public operator fun plus(context: CoroutineContext): CoroutineContext = .......
//返回一个新的CoroutineContext,这个CoroutineContext删除了Key对应的Element
public fun minusKey(key: Key<*>): CoroutineContext
//Key定义,空实现,仅仅做一个标识
public interface Key<E : Element>
///Element定义,每个Element都是一个CoroutineContext
public interface Element : CoroutineContext {
//每个Element都有一个Key实例
public val key: Key<*>
......
}
}
Element:协程上下文的一个元素,本身就是一个单例上下文,里面有一个key,是这个元素的索引。
可知,Element本身也实现了CoroutineContext接口。
这里我们再看一下官方解释:
/**
Persistent context for the coroutine. It is an indexed set of [Element] instances.
An indexed set is a mix between a set and a map.
Every element in this set has a unique [Key].*/
从官方解释可知,CoroutineContext是一个Element的集合,这种集合被称为indexed set,介于set 和 map 之间的一种结构。set 意味着其中的元素有唯一性,map 意味着每个元素都对应一个键。
如果将协程上下文内部的一系列上下文称为子上下文,上下文为每个子上下文分配了一个Key,它是一个带有类型信息的接口。
这个接口通常被实现为companion object。
//Job
public interface Job : CoroutineContext.Element {
/**
* Key for [Job] instance in the coroutine context.
*/
public companion object Key : CoroutineContext.Key<Job>
}
//拦截器
public interface ContinuationInterceptor : CoroutineContext.Element {
/**
* The key that defines *the* context interceptor.
*/
companion object Key : CoroutineContext.Key<ContinuationInterceptor>
}
//协程名
public data class CoroutineName(
val name: String
) : AbstractCoroutineContextElement(CoroutineName) {
/**
* Key for [CoroutineName] instance in the coroutine context.
*/
public companion object Key : CoroutineContext.Key<CoroutineName>
}
//异常处理器
public interface CoroutineExceptionHandler : CoroutineContext.Element {
/**
* Key for [CoroutineExceptionHandler] instance in the coroutine context.
*/
public companion object Key : CoroutineContext.Key<CoroutineExceptionHandler>
}
源码中定义的子上下文,都会在内部声明一个静态的Key,类内部的静态变量意味着被所有类实例共享,即全局唯一的 Key 实例可以对应多个子上下文实例。
在一个类似 map 的结构中,每个键必须是唯一的,因为对相同的键 put 两次值,新值会代替旧值。通过上述方式,通过键的唯一性保证了上下文中的所有子上下文实例都是唯一的。
我们按照这个格式仿写一下然后反编译。
class MyElement :AbstractCoroutineContextElement(MyElement) {
companion object Key : CoroutineContext.Key<MyElement>
}
//反编译的java文件
public final class MyElement extends AbstractCoroutineContextElement {
@NotNull
public static final MyElement.Key Key = new MyElement.Key((DefaultConstructorMarker)null);
public MyElement() {
super((kotlin.coroutines.CoroutineContext.Key)Key);
}
public static final class Key implements kotlin.coroutines.CoroutineContext.Key {
private Key() {
}
// $FF: synthetic method
public Key(DefaultConstructorMarker $constructor_marker) {
this();
}
}
}
对比kt和Java文件,可以看到Key就是一个静态变量,且其实现类未做处理,作用与HashMap中的Key类似。
Key是静态变量,全局唯一,为Element提供唯一性保障。
前述内容总结如下:
协程上下文是一个元素的集合,单个元素本身也是一个上下文,其定义是递归的,自己包含若干个自己。
协程上下文这个集合有点像 set 结构,其中的元素都是唯一的,不重复的。其通过给每一个元素配有一个静态的键实例,构成一组键值对的方式实现。这使其类似 map 结构。这种介于 set 和 map 之间的结构称为indexed set。
CoroutineContext.get()获取元素
关于CoroutineContext,我们先看一下其是如何取元素的。
这里看一下Element、CombinedContext、EmptyCoroutineContext的内部实现,其中CombinedContext就是CoroutineContext集合结构的实现,EmptyCoroutineContext就表示一个空的CoroutineContext,它里面是空实现。
@SinceKotlin("1.3")
internal class CombinedContext(
//左上下文
private val left: CoroutineContext,
//右元素
private val element: Element
) : CoroutineContext, Serializable {
override fun <E : Element> get(key: Key<E>): E? {
var cur = this
while (true) {
//如果输入 key 和右元素的 key 相同,则返回右元素
cur.element[key]?.let { return it }
// 若右元素不匹配,则向左继续查找
val next = cur.left
if (next is CombinedContext) {
cur = next
} else { // 若左上下文不是混合上下文,则结束递归
return next[key]
}
}
}
......
}
public interface Element : CoroutineContext {
public val key: Key<*>
public override operator fun <E : Element> get(key: Key<E>): E? =
@Suppress("UNCHECKED_CAST")
// 如果给定键和元素本身键相同,则返回当前元素,否则返回空
if (this.key == key) this as E else null
......
}
public object EmptyCoroutineContext : CoroutineContext, Serializable {
//返回空
public override fun <E : Element> get(key: Key<E>): E? = null
}
通过Key检索Element,返回值只能是Element或null,链表节点中的元素值,其中CombinedContext利用while循环实现了类似递归的效果,其中较早被遍历到的元素自然具有较高的优先级。
//使用示例
println(coroutineContext[CoroutineName])
println(Dispatchers.Main[CoroutineName])
CoroutineContext.minusKey()删除元素
同理看一下Element、CombinedContext、EmptyCoroutineContext的内部实现。
internal class CombinedContext(
//左上下文
private val left: CoroutineContext,
//右元素
private val element: Element
) : CoroutineContext, Serializable {
public override fun minusKey(key: Key<*>): CoroutineContext {
//如果element就是要删除的元素,返回left,否则说明要删除的元素在left中,继续从left中删除对应的元素
element[key]?.let { return left }
//在左上下文中去掉对应元素
val newLeft = left.minusKey(key)
return when {
//如果left中不存在要删除的元素,那么当前CombinedContext就不存在要删除的元素,直接返回当前CombinedContext实例
newLeft === left -> this
//如果left中存在要删除的元素,删除了这个元素后,left变为了空,那么直接返回当前CombinedContext的element就行
newLeft === EmptyCoroutineContext -> element
//如果left中存在要删除的元素,删除了这个元素后,left不为空,那么组合一个新的CombinedContext返回
else -> CombinedContext(newLeft, element)
}
}
......
}
public object EmptyCoroutineContext : CoroutineContext, Serializable {
public override fun minusKey(key: Key<*>): CoroutineContext = this
......
}
public interface Element : CoroutineContext {
//如果key和自己的key匹配,那么自己就是要删除的Element,返回EmptyCoroutineContext(表示删除了自己),否则说明自己不需要被删除,返回自己
public override fun minusKey(key: Key<*>): CoroutineContext =
if (this.key == key) EmptyCoroutineContext else this
......
}
如果把CombinedContext和Element结合来看,那么CombinedContext的整体结构如下:

其结构类似链表,left就是指向下一个结点的指针,get、minusKey操作大体逻辑都是先访问当前element,不满足,再访问left的element,顺序都是从right到left。
CoroutineContext.fold()元素遍历
internal class CombinedContext(
//左上下文
private val left: CoroutineContext,
//右元素
private val element: Element
) : CoroutineContext, Serializable {
//先对left做fold操作,把left做完fold操作的的返回结果和element做operation操作
public override fun <R> fold(initial: R, operation: (R, Element) -> R): R =
operation(left.fold(initial, operation), element)
......
}
public object EmptyCoroutineContext : CoroutineContext, Serializable {
public override fun <R> fold(initial: R, operation: (R, Element) -> R): R = initial
......
}
public interface Element : CoroutineContext {
//对传入的initial和自己做operation操作
public override fun <R> fold(initial: R, operation: (R, Element) -> R): R =
operation(initial, this)
......
}
fold也是递归的形式操作,fold的操作大体逻辑是:先访问left,直到递归到最后的element,然后再从left到right的返回,从而访问了所有的element。
CoroutineContext.plus()添加元素
关于CoroutineContext的元素添加方法,直接看其plus()实现,也是唯一没有被重写的方法。
public operator fun plus(context: CoroutineContext): CoroutineContext =
//如果要相加的CoroutineContext为空,那么不做任何处理,直接返回
if (context === EmptyCoroutineContext) this else
//如果要相加的CoroutineContext不为空,那么对它进行fold操作,可以把acc理解成+号左边的CoroutineContext,element理解成+号右边的CoroutineContext的某一个element
context.fold(this) { acc, element ->
//首先从左边CoroutineContext中删除右边的这个element
val removed = acc.minusKey(element.key)
//如果removed为空,说明左边CoroutineContext删除了和element相同的元素后为空,那么返回右边的element即可
if (removed === EmptyCoroutineContext) element else {
//如果removed不为空,说明左边CoroutineContext删除了和element相同的元素后还有其他元素,那么构造一个新的CombinedContext返回
val interceptor = removed[ContinuationInterceptor]
if (interceptor == null) CombinedContext(removed, element) else {
val left = removed.minusKey(ContinuationInterceptor)
if (left === EmptyCoroutineContext) CombinedContext(element, interceptor) else
CombinedContext(CombinedContext(left, element), interceptor)
}
}
}
plus方法大部分情况下返回一个CombinedContext,即我们把两个CoroutineContext相加后,返回一个CombinedContext,在组合成CombinedContext时,+号右边的CoroutineContext中的元素会覆盖+号左边的CoroutineContext中的含有相同key的元素。
这个覆盖操作就在fold方法的参数operation代码块中完成,通过minusKey方法删除掉重复元素。
plus方法中可以看到里面有个对ContinuationInterceptor的处理,目的是让ContinuationInterceptor在每次相加后都能变成CoroutineContext中的最后一个元素。
ContinuationInterceptor继承自Element,称为协程上下文拦截器,作用是在协程执行前拦截它,从而在协程执行前做出一些其他的操作。通过把ContinuationInterceptor放在最后面,协程在查找上下文的element时,总能最快找到拦截器,避免了递归查找,从而让拦截行为前置执行。
4.1.2 CoroutineName
public data class CoroutineName(
val name: String
) : AbstractCoroutineContextElement(CoroutineName) {
CoroutineName是用户用来指定的协程名称的,用于方便调试和定位问题。
GlobalScope.launch(CoroutineName("GlobalScope")) {
launch(CoroutineName("CoroutineA")) {//指定协程名称
val coroutineName = coroutineContext[CoroutineName]//获取协程名称
print(coroutineName)
}
}
/** 打印结果
CoroutineName(CoroutineA)
*/
协程内部可以通过coroutineContext这个全局属性直接获取当前协程的上下文。
4.1.3 上下文组合
如果要传递多个上下文元素,CoroutineContext可以使用”+”运算符进行合并。由于CoroutineContext是由一组元素组成的,所以加号右侧的元素会覆盖加号左侧的元素,进而组成新创建的CoroutineContext。
GlobalScope.launch {
//通过+号运算添加多个上下文元素
var context = CoroutineName("协程1") + Dispatchers.Main
print("context == $context")
context += Dispatchers.IO //添加重复Dispatchers元素,Dispatchers.IO 会替换 ispatchers.Main
print("context == $context")
val contextResult = context.minusKey(context[CoroutineName]!!.key)//移除CoroutineName元素
print("contextResult == $contextResult")
}
/**打印结果
context == [CoroutineName(协程1), Dispatchers.Main]
context == [CoroutineName(协程1), Dispatchers.IO]
contextResult == Dispatchers.IO
*/
如果有重复的元素(key一致)则右边的会代替左边的元素,相关原理参看协程上下文结构章节。
4.1.4 CoroutineScope 构建
CoroutineScope实际上是一个CoroutineContext的封装,当我们需要启动一个协程时,会在CoroutineScope的实例上调用构建函数,如async和launch。
在构建函数中,一共出现了3个CoroutineContext。
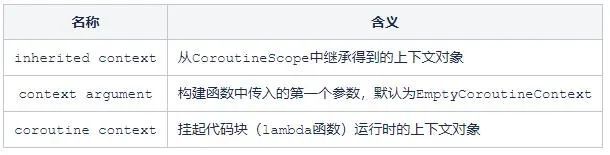
查看协程构建函数async和launch的源码,其第一行都是如下代码:
val newContext = newCoroutineContext(context)
进一步查看:
@ExperimentalCoroutinesApi
public actual fun CoroutineScope.newCoroutineContext(context: CoroutineContext): CoroutineContext {
val combined = coroutineContext + context //CoroutineContext拼接组合
val debug = if (DEBUG) combined + CoroutineId(COROUTINE_ID.incrementAndGet()) else combined
return if (combined !== Dispatchers.Default && combined[ContinuationInterceptor] == null)
debug + Dispatchers.Default else debug
}
构建器内部进行了一个CoroutineContext拼接操作,plus左值是CoroutineScope内部的CoroutineContext,右值是作为构建函数参数的CoroutineContext。
抽象类AbstractCoroutineScope实现了CoroutineScope和Job接口。大部分CoroutineScope的实现都继承自AbstractCoroutineScope,意味着他们同时也是一个Job。
public abstract class AbstractCoroutine<in T>(
parentContext: CoroutineContext,
initParentJob: Boolean,
active: Boolean
) : JobSupport(active), Job, Continuation<T>, CoroutineScope {
/**
* The context of this coroutine that includes this coroutine as a [Job].
*/
public final override val context: CoroutineContext = parentContext + this
//重写了父类的coroutineContext属性
public override val coroutineContext: CoroutineContext get() = context
}
从上述分析可知:coroutine context = parent context + coroutine job
4.1.5 典型用例
全限定Context
launch( Dispatchers.Main + Job() + CoroutineName("HelloCoroutine") + CoroutineExceptionHandler { _, _ -> /* ... */ }) {
/* ... */
}
全限定Context,即全部显式指定具体值的Elements。不论你用哪一个CoroutineScope构建该协程,它都具有一致的表现,不会受到CoroutineScope任何影响。
CoroutineScope Context
基于Activity生命周期实现一个CoroutineScope
abstract class ScopedAppActivity:
AppCompatActivity(),
CoroutineScope
{
protected lateinit var job: Job
override val coroutineContext: CoroutineContext
get() = job + Dispatchers.Main // 注意这里使用+拼接CoroutineContext
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
job = Job()
}
override fun onDestroy() {
super.onDestroy()
job.cancel()
}
}
Dispatcher:使用Dispatcher.Main,以在UI线程进行绘制
Job:在onCreate时构建,在onDestroy时销毁,所有基于该CoroutineContext创建的协程,都会在Activity销毁时取消,从而避免Activity泄露的问题
临时指定参数
CoroutineContext的参数主要有两个来源:从scope中继承+参数指定。我们可以用withContext便捷地指定某个参数启动子协程,例如我们想要在协程内部执行一个无法被取消的子协程:
withContext(NonCancellable) {
/* ... */
}
读取协程上下文参数
通过顶级挂起只读属性coroutineContext获取协程上下文参数,它位于 kotlin-stdlib / kotlin.coroutines / coroutineContext
println("Running in ${coroutineContext[CoroutineName]}")
Nested Context内嵌上下文
内嵌上下文切换:在协程A内部构建协程B时,B会自动继承A的Dispatcher。
可以在调用async时加入Dispatcher参数,切换到工作线程
// 错误的做法,在主线程中直接调用async,若耗时过长则阻塞UI
GlobalScope.launch(Dispatchers.Main) {
val deferred = async {
/* ... */
}
/* ... */
}
// 正确的做法,在工作线程执行协程任务
GlobalScope.launch(Dispatchers.Main) {
val deferred = async(Dispatchers.Default) {
/* ... */
}
/* ... */
}
4.2 协程拦截器
@SinceKotlin("1.3")
public interface ContinuationInterceptor : CoroutineContext.Element {
companion object Key : CoroutineContext.Key<ContinuationInterceptor>
public fun <T> interceptContinuation(continuation: Continuation<T>): Continuation<T>
//......
}
-
无论在CoroutineContext后面 放了多少个拦截器,Key 为 ContinuationInterceptor 的拦截器只能有一个。
-
Continuation 在调用其 Continuation#resumeWith() 方法,会执行其 suspend 修饰的函数的代码块,如果我们提前拦截到,可以做点其他事情,比如说切换线程,这是 ContinuationInterceptor 的主要作用。
协程的本质就是回调,这个回调就是被拦截的Continuation。OkHttp用拦截器做缓存,打日志,模拟请求等,协程拦截器同理。
我们通过Dispatchers 来指定协程发生的线程,Dispatchers 实现了 ContinuationInterceptor接口。
这里我们自定义一个拦截器放到协程上下文,看一下会发生什么。
class MyContinuationInterceptor: ContinuationInterceptor{
override val key = ContinuationInterceptor
override fun <T> interceptContinuation(continuation: Continuation<T>) = MyContinuation(continuation)
}
class MyContinuation<T>(val continuation: Continuation<T>): Continuation<T> {
override val context = continuation.context
override fun resumeWith(result: Result<T>) {
log("<MyContinuation> $result" )
continuation.resumeWith(result)
}
}
suspend fun main(args: Array<String>) { // start main coroutine
GlobalScope.launch(MyContinuationInterceptor()) {
log(1)
val job = async {
log(2)
delay(1000)
log(3)
"Hello"
}
log(4)
val result = job.await()
log("5. $result")
}.join()
log(6)
}
fun log(o: Any?) {
println("[${Thread.currentThread().name}]:$o")
}
/******打印结果******/
[main]:<MyContinuation> Success(kotlin.Unit) //11
[main]:1
[main]:<MyContinuation> Success(kotlin.Unit) //22
[main]:2
[main]:4
[kotlinx.coroutines.DefaultExecutor]:<MyContinuation> Success(kotlin.Unit) //33
[kotlinx.coroutines.DefaultExecutor]:3
[kotlinx.coroutines.DefaultExecutor]:<MyContinuation> Success(Hello)
[kotlinx.coroutines.DefaultExecutor]:5. Hello
[kotlinx.coroutines.DefaultExecutor]:6
- 所有协程启动时,都有一次Continuation.resumeWith 的操作,协程有机会调度到其他线程的关键之处就在于此。
- delay是挂起点,1s之后需要继续调度执行该协程,因此就有了33处日志。
前述分析CoroutineContext的plus方法涉及到了ContinuationInterceptor,plus每次都会将ContinuationInterceptor添加到拼接链的尾部,这里再详细解释一下原因。
public operator fun plus(context: CoroutineContext): CoroutineContext =
//如果要相加的CoroutineContext为空,那么不做任何处理,直接返回
if (context === EmptyCoroutineContext) this else
//如果要相加的CoroutineContext不为空,那么对它进行fold操作,可以把acc理解成+号左边的CoroutineContext,element理解成+号右边的CoroutineContext的某一个element
context.fold(this) { acc, element ->
//首先从左边CoroutineContext中删除右边的这个element
val removed = acc.minusKey(element.key)
//如果removed为空,说明左边CoroutineContext删除了和element相同的元素后为空,那么返回右边的element即可
if (removed === EmptyCoroutineContext) element else {
//如果removed不为空,说明左边CoroutineContext删除了和element相同的元素后还有其他元素,那么构造一个新的CombinedContext返回
val interceptor = removed[ContinuationInterceptor]
if (interceptor == null) CombinedContext(removed, element) else {
val left = removed.minusKey(ContinuationInterceptor)
if (left === EmptyCoroutineContext) CombinedContext(element, interceptor) else
CombinedContext(CombinedContext(left, element), interceptor)
}
}
}
原因一:CombinedContext的结构决定。
其有两个元素,left是一个前驱集合,element为一个纯粹CoroutineContext,它的get方法每次都是从element开始进行查找对应Key的CoroutineContext对象;没有匹配到才会去left集合中进行递归查找。为了加快查找ContinuationInterceptor类型的实例,才将它加入到拼接链的尾部,对应的就是element。
原因二:ContinuationInterceptor使用很频繁
每次创建协程都会去尝试查找当前协程的CoroutineContext中是否存在ContinuationInterceptor。这里我们用launch来验证一下
public fun CoroutineScope.launch(
context: CoroutineContext = EmptyCoroutineContext,
start: CoroutineStart = CoroutineStart.DEFAULT,
block: suspend CoroutineScope.()
->
Unit
): Job {
val newContext = newCoroutineContext(context)
val coroutine = if (start.isLazy)
LazyStandaloneCoroutine(newContext, block) else
StandaloneCoroutine(newContext, active = true)
coroutine.start(start, coroutine, block)
return coroutine
}
如果使用的launch使用的是默认参数,此时Coroutine就是StandaloneCoroutine,然后调用start方法启动协程。
start(block, receiver, this)
}
public operator fun <T> invoke(block: suspend () -> T, completion: Continuation<T>): Unit =
when (this) {
DEFAULT -> block.startCoroutineCancellable(completion)
ATOMIC -> block.startCoroutine(completion)
UNDISPATCHED -> block.startCoroutineUndispatched(completion)
LAZY -> Unit // will start lazily
}
如果我们使用默认参数,看一下默认参数对应执行的block.startCoroutineCancellable(completion)
public fun <T> (suspend () -> T).startCoroutineCancellable(completion: Continuation<T>): Unit = runSafely(completion) {
createCoroutineUnintercepted(completion).intercepted().resumeCancellableWith(Result.success(Unit))
}
-
首先通过createCoroutineUnintercepted来创建一个协程
-
然后再调用intercepted方法进行拦截操作
-
最后调用resumeCancellable,即Continuation的resumeWith方法,启动协程,所以每次启动协程都会自动回调一次resumeWith方法
这里看一下intercepted
public actual fun <T> Continuation<T>.intercepted(): Continuation<T> =
(this as? ContinuationImpl)?.intercepted() ?: this
看其在ContinuationImpl的intercepted方法实现
public fun intercepted(): Continuation<Any?> =
intercepted
?: (context[ContinuationInterceptor]?.interceptContinuation(this) ?: this)
.also { intercepted = it }
-
首先获取到ContinuationInterceptor实例
-
然后调用它的interceptContinuation方法返回一个处理过的Continuation(多次调用intercepted,对应的interceptContinuation只会调用一次)
至此可知,ContinuationInterceptor的拦截是通过interceptContinuation方法进行
下面再看一个ContinuationInterceptor的典型示例
val interceptor = object : ContinuationInterceptor {
override val key: CoroutineContext.Key<*> = ContinuationInterceptor
override fun <T> interceptContinuation(continuation: Continuation<T>): Continuation<T> {
println("intercept todo something. change run to thread")
return object : Continuation<T> by continuation {
override fun resumeWith(result: Result<T>) {
println("create new thread")
thread {
continuation.resumeWith(result)
}
}
}
}
}
println(Thread.currentThread().name)
lifecycleScope.launch(interceptor) {
println("launch start. current thread: ${Thread.currentThread().name}")
withContext(Dispatchers.Main) {
println("new continuation todo something in the main thread. current thread: ${Thread.currentThread().name}")
}
launch {
println("new continuation todo something. current thread: ${Thread.currentThread().name}")
}
println("launch end. current thread: ${Thread.currentThread().name}")
}
/******打印结果******/
main
// 第一次launch
intercept todo something. change run to thread
create new thread
launch start. current thread: Thread-2
new continuation todo something in the main thread. current thread: main
create new thread
// 第二次launch
intercept todo something. change run to thread
create new thread
launch end. current thread: Thread-7
new continuation todo something. current thread: Thread-8
-
首先程序运行在main线程,启动协程时将自定义的interceptor加入到上下文中,协程启动时进行拦截,将在main线程运行的程序切换到新的thread线程
-
withContext没有拦截成功,具体原因在下面的调度器再详细解释,简单来说就是我们自定义的interceptor被替换了。
-
launch start与launch end所处的线程不一样,因为withContext结束之后,它内部还会进行一次线程恢复,将自身所处的main线程切换到之前的线程。协程每一个挂起后恢复都是通过回调resumeWith进行的,然而外部launch协程我们进行了拦截,在它返回的Continuation的resumeWith回调中总是会创建新的thread。
4.3 调度器
CoroutineDispatcher调度器指定指定执行协程的目标载体,它确定了相关的协程在哪个线程或哪些线程上执行。可以将协程限制在一个特定的线程执行,或将它分派到一个线程池,亦或是让它不受限地运行。
public abstract class CoroutineDispatcher :
AbstractCoroutineContextElement(ContinuationInterceptor), ContinuationInterceptor {
//将可运行块的执行分派到给定上下文中的另一个线程上
public abstract fun dispatch(context: CoroutineContext, block: Runnable)
//返回一个continuation,它封装了提供的[continuation],拦截了所有的恢复
public final override fun <T> interceptContinuation(continuation: Continuation<T>): Continuation<T>
//......
}
协程需要调度的位置就是挂起点的位置,只有当挂起点正在挂起的时候才会进行调度,实现调度需要使用协程的拦截器。
调度的本质就是解决挂起点恢复之后的协程逻辑在哪里运行的问题。调度器也属于协程上下文一类,它继承自拦截器。
-
【val Default】: CoroutineDispatcher
-
【val Main】: MainCoroutineDispatcher
-
【val Unconfined】: CoroutineDispatcher
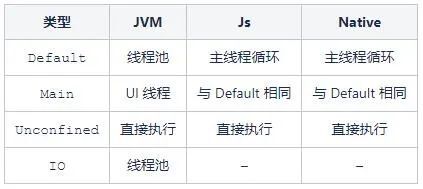
IO仅在 Jvm 上有定义,它基于 Default 调度器背后的线程池,并实现了独立的队列和限制,因此协程调度器从 Default 切换到 IO 并不会触发线程切换
关于调度器介绍到这里,还没有详细解释前述协程拦截器中的withContext为什么拦截失败。这里针对这个详细看一下源码实现。
public actual val Main: MainCoroutineDispatcher get() = MainDispatcherLoader.dispatcher
其返回类型为MainCoroutineDispatcher,继承自CoroutineDispatcher。
public abstract class MainCoroutineDispatcher : CoroutineDispatcher()
public abstract class CoroutineDispatcher :
AbstractCoroutineContextElement(ContinuationInterceptor), ContinuationInterceptor {
public open fun isDispatchNeeded(context: CoroutineContext): Boolean = true
public abstract fun dispatch(context: CoroutineContext, block: Runnable)
public open fun dispatchYield(context: CoroutineContext, block: Runnable): Unit = dispatch(context, block)
public final override fun <T> interceptContinuation(continuation: Continuation<T>): Continuation<T> =
DispatchedContinuation(this, continuation)
......
}
CoroutineDispatch实现了ContinuationInterceptor,根据前述解释的CoroutineContext结构,可知我们自定义的拦截器没有生效是因为被替换了。
CoroutineDispatch中的isDispatchNeeded就是判断是否需要分发,然后dispatch就是执行分发。
ContinuationInterceptor重要的方法就是interceptContinuation,在CoroutineDispatcher中直接返回了DispatchedContinuation对象,它是一个Continuation类型,看一下其resumeWith实现。
override fun resumeWith(result: Result<T>) {
val context = continuation.context
val state = result.toState()
//判断是否需要分发
if (dispatcher.isDispatchNeeded(context)) {
_state = state
resumeMode = MODE_ATOMIC
dispatcher.dispatch(context, this)
} else {
executeUnconfined(state, MODE_ATOMIC) {
withCoroutineContext(this.context, countOrElement) {
//不需要分发,直接使用原先的continuation对象的resumewith
continuation.resumeWith(result)
}
}
}
}
那么分发的判断逻辑是怎么实现的?这要根据具体的dispatcher来看。
如果我们拿的是Dispatchers.Main,其dispatcher为HandlerContext。
internal class HandlerContext private constructor(
private val handler: Handler,
private val name: String?,
private val invokeImmediately: Boolean
) : HandlerDispatcher(), Delay {
override fun isDispatchNeeded(context: CoroutineContext): Boolean {
return !invokeImmediately || Looper.myLooper() != handler.looper
}
override fun dispatch(context: CoroutineContext, block: Runnable) {
if (!handler.post(block)) {
cancelOnRejection(context, block)
}
}
......
其中HandlerContext继承于HandlerDispatcher,而HandlerDispatcher继承于MainCoroutineDispatcher
Dispatcher的基本实现原理大致为:
-
首先在协程进行启动的时候通过拦截器的方式进行拦截,对应的方法是interceptContinuation
-
然后返回一个具有切换线程功能的Continuation
-
在每次进行resumeWith的时候,内部再通过isDispatchNeeded进行判断当前协程的运行是否需要切换线程。
-
如果需要则调用dispatch进行线程的切换,保证协程的正确运行。如果要自定义协程线程的切换,可以通过继承CoroutineDispatcher来实现。
这里再简单看一下WithContext,我们都知道其不仅可以接受CoroutineDispatcher来帮助我们切换线程,同时在执行完毕之后还会帮助我们将之前切换掉的线程进恢复,保证协程运行的连贯性。那这是怎么实现的呢?
withContext的线程恢复原理是它内部生成了一个DispatchedCoroutine,保存切换线程时的CoroutineContext与切换之前的Continuation,最后在onCompletionInternal进行恢复。我们简单翻一翻其源码实现。
public suspend fun <T> withContext(
context: CoroutineContext,
block: suspend CoroutineScope.() -> T
): T {
contract {
callsInPlace(block, InvocationKind.EXACTLY_ONCE)
}
return suspendCoroutineUninterceptedOrReturn sc@ { uCont ->
// 创建新的CoroutineContext
val oldContext = uCont.context
val newContext = oldContext + context
......
//使用新的Dispatcher,覆盖外层
val coroutine = DispatchedCoroutine(newContext, uCont)
block.startCoroutineCancellable(coroutine, coroutine)
coroutine.getResult()
}
}
internal class DispatchedCoroutine<in T>(
context: CoroutineContext,
uCont: Continuation<T>
) : ScopeCoroutine<T>(context, uCont) {
//在complete时会会回调
override fun afterCompletion(state: Any?) {
// Call afterResume from afterCompletion and not vice-versa, because stack-size is more
// important for afterResume implementation
afterResume(state)
}
override fun afterResume(state: Any?) {
////uCont就是父协程,context仍是老版context,因此可以切换回原来的线程上
if (tryResume()) return // completed before getResult invocation -- bail out
// Resume in a cancellable way because we have to switch back to the original dispatcher
uCont.intercepted().resumeCancellableWith(recoverResult(state, uCont))
}
......
}
-
对于withContext,传入的context会覆盖外层的拦截器并生成一个newContext,因此可以实现线程切换。
-
DispatchedCoroutine作为complete传入协程体的创建函数中,因此协程体执行完成后会回调到afterCompletion中。
-
DispatchedCoroutine中传入的uCont是父协程,它的拦截器仍是外层的拦截器,因此会切换回原来的线程中。
4.3.1 典型用例
例如:点击一个按钮,进行异步操作后再回调刷新UI
getUserBtn.setOnClickListener {
getUser { user ->
handler.post {
userNameView.text = user.name
}
}
}
typealias Callback = (User) -> Unit
fun getUser(callback: Callback){
...
}
由于 getUser 函数需要切到其他线程执行,因此回调通常也会在这个非 UI 的线程中调用,所以为了确保 UI 正确被刷新,我们需要用 handler.post 切换到 UI 线程。
如果要用协程实现呢?
suspend fun getUserCoroutine() = suspendCoroutine<User> {
continuation ->
getUser {
continuation.resume(it)
}
}
getUserBtn.setOnClickListener {
GlobalScope.launch(Dispatchers.Main) {
userNameView.text = getUserCoroutine().name
}
}
suspendCoroutine 这个方法并不是帮我们启动协程的,它运行在协程当中并且帮我们获取到当前协程的 Continuation 实例,也就是拿到回调,方便后面我们调用它的 resume 或者 resumeWithException 来返回结果或者抛出异常。
4.3.2 线程绑定
调度器的目的就是切线程,我们只要提供线程,调度器就应该很方便的创建出来。
suspend fun main() {
val myDispatcher= Executors.newSingleThreadExecutor{ r -> Thread(r, "MyThread") }.asCoroutineDispatcher()
GlobalScope.launch(myDispatcher) {
log(1)
}.join()
log(2)
}
由于这个线程池是我们自己创建的,因此我们需要在合适的时候关闭它。
除了上述的方法,kotlin协程还给出了更简单的api,如下:
GlobalScope.launch(newSingleThreadContext("Dispather")) {
//......
}.join()
前述我们是通过线程的方式,同理可以通过线程池转为调度器实现。
Executors.newScheduledThreadPool(10)
.asCoroutineDispatcher().use { dispatcher ->
GlobalScope.launch(dispatcher) {
//......
}.join
五、协程挂起
在前述协程时,经常会出现suspend关键字和挂起的说法,其含义和用法是什么?一起深入看一下。
5.1 概述
suspend翻译过来就是中断、挂起,用在函数声明前,起到挂起协程的标识,本质作用是代码调用时为方法添加一个Continuation类型的参数,保证协程中Continuation的上下传递。
挂起函数只能在协程或另一个挂起函数中被调用,如果你在非协程中使用到了挂起函数,会报错。
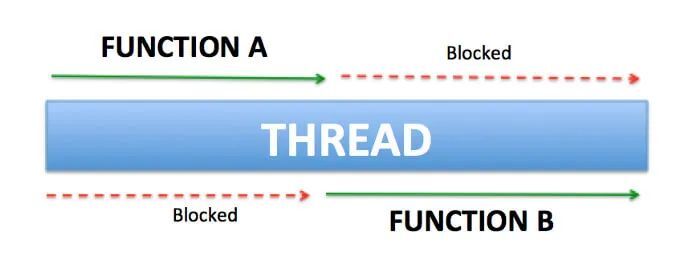
阻塞:
函数A必须在函数B之前完成执行,线程被锁定以便函数A能够完成其执行
挂起:
函数A虽然已经启动,但可以暂停,让函数B执行,然后只在稍后恢复。线程没有被函数A锁定。
“挂起”是指协程从它当前线程脱离,切换到另一个线程运行。当线程运行到suspend函数时,会暂时挂起这个函数及后续代码的执行。简而言之,挂起函数是一个可以启动、暂停和恢复的函数。
协程运行的时候每遇到被suspend修饰的方法时,都可能会挂起当前协程,不是必会挂起,例如如下方法就不会被挂起。
private suspend fun a() {
println("aa")
}
这是因为这种方法不会返回COROUTINE_SUSPENDED类型,这在后面详细解释。
5.2 suspend本质
Kotlin 使用堆栈帧来管理要运行哪个函数以及所有局部变量。
协程在常规函数基础上添加了suspend和resume两项操作用于处理长时间运行的任务。
【suspend】:挂起或暂停,用于挂起执行当前协程,并保存所有局部变量
【resume】:恢复,用于让已挂起的协程从挂起处恢复继续执行
挂起(暂停)协程时,会复制并保存当前的堆栈帧以供稍后使用,将信息保存到Continuation对象中。
恢复协程时,会将堆栈帧从其保存位置复制回来,对应的Continuation通过调用resumeWith函数才会恢复协程的执行,然后函数再次开始运行。同时返回Result类型的成功或者异常的结果。
public interface Continuation<in T> {
//对应这个Continuation的协程上下文
public val context: CoroutineContext
//恢复相应协程的执行,传递一个成功或失败的结果作为最后一个挂起点的返回值。
public fun resumeWith(result: Result<T>)
}
//将[value]作为最后一个挂起点的返回值,恢复相应协程的执行。
@SinceKotlin("1.3")
@InlineOnly
public inline fun <T> Continuation<T>.resume(value: T): Unit =
resumeWith(Result.success(value))
//恢复相应协程的执行,以便在最后一个挂起点之后重新抛出[异常]。
@SinceKotlin("1.3")
@InlineOnly
public inline fun <T> Continuation<T>.resumeWithException(exception: Throwable): Unit =
resumeWith(Result.failure(exception))
-
Continuation 类有一个 resumeWith 函数可以接收 Result 类型的参数。
-
在结果成功获取时,调用resumeWith(Result.success(value))或者调用拓展函数resume(value);出现异常时,调用resumeWith(Result.failure(exception))或者调用拓展函数resumeWithException(exception)。这就是 Continuation 的恢复调用。
@FormUrlEncoded
@POST("/api/common/countryList")
suspend fun fetchCountryList(@FieldMap params: Map<String, String?>): CountryResponse
前述挂起函数解析后反编译如下:
@FormUrlEncoded
@POST("/api/common/countryList")
@Nullable
Object fetchCountryList(@FieldMap @NotNull Map var1, @NotNull Continuation var2);
-
挂起函数反编译后,发现多了一个Continuation参数,有编译器传递,说明调用挂起函数需要Continuation。
-
只有挂起函数或者协程中才有Continuation,所以挂起函数只能在协程或者其他挂起函数中执行。
5.2.1 Continuation
这里看一下该Continuation的传递来源。
这个函数只能在协程或者挂起函数中执行,说明Continuation很有可能是从协程中传入来的,查看协程构建源码。
public fun CoroutineScope.launch(
context: CoroutineContext = EmptyCoroutineContext,
start: CoroutineStart = CoroutineStart.DEFAULT,
block: suspend CoroutineScope.() -> Unit
): Job {
val newContext = newCoroutineContext(context)
val coroutine = if (start.isLazy)
LazyStandaloneCoroutine(newContext, block) else
StandaloneCoroutine(newContext, active = true)
coroutine.start(start, coroutine, block)
return coroutine
}
通过launch启动一个协程时,其通过coroutine的start方法启动协程:
public fun <R> start(start: CoroutineStart, receiver: R, block: suspend R.() -> T) {
start(block, receiver, this)
}
然后start方法里面调用了CoroutineStart的invoke,这个时候我们发现了Continuation:
//CoroutineStart的invoke方法出现了Continuation
public operator fun <R, T> invoke(block: suspend R.() -> T, receiver: R, completion: Continuation<T>): Unit =
when (this) {
DEFAULT -> block.startCoroutineCancellable(receiver, completion)
ATOMIC -> block.startCoroutine(receiver, completion)
UNDISPATCHED -> block.startCoroutineUndispatched(receiver, completion)
LAZY -> Unit // will start lazily
}
@InternalCoroutinesApi
public fun <T> (suspend () -> T).startCoroutineCancellable(completion: Continuation<T>): Unit = runSafely(completion) {
createCoroutineUnintercepted(completion).intercepted().resumeCancellableWith(Result.success(Unit))
}
最终回调到Continuation的resumeWith()恢复函数中。
public fun <T> Continuation<T>.resumeCancellableWith(
result: Result<T>,
onCancellation: ((cause: Throwable) -> Unit)? = null
): Unit = when (this) {
is DispatchedContinuation -> resumeCancellableWith(result, onCancellation)
else -> resumeWith(result)
}
我们再深入kotlin源码看一下其内部实现。
public actual fun <R, T> (suspend R.() -> T).createCoroutineUnintercepted(
receiver: R,
completion: Continuation<T>
): Continuation<Unit> {
val probeCompletion = probeCoroutineCreated(completion)
return if (this is BaseContinuationImpl)
create(receiver, probeCompletion)
else {
createCoroutineFromSuspendFunction(probeCompletion) {
(this as Function2<R, Continuation<T>, Any?>).invoke(receiver, it)//1
}
}
}
private inline fun <T> createCoroutineFromSuspendFunction(
completion: Continuation<T>,
crossinline block: (Continuation<T>) -> Any?
): Continuation<Unit> {
val context = completion.context
// label == 0 when coroutine is not started yet (initially) or label == 1 when it was
return if (context === EmptyCoroutineContext)
object : RestrictedContinuationImpl(completion as Continuation<Any?>) {
private var label = 0
override fun invokeSuspend(result: Result<Any?>): Any? =
when (label) {
0 -> {
label = 1
result.getOrThrow() // Rethrow exception if trying to start with exception (will be caught by BaseContinuationImpl.resumeWith
block(this) // run the block, may return or suspend
}
1 -> {
label = 2
result.getOrThrow() // this is the result if the block had suspended
}
else -> error("This coroutine had already completed")
}
}
else
object : ContinuationImpl(completion as Continuation<Any?>, context) {
private var label = 0
override fun invokeSuspend(result: Result<Any?>): Any? =
when (label) {
0 -> {
label = 1
result.getOrThrow() // Rethrow exception if trying to start with exception (will be caught by BaseContinuationImpl.resumeWith
block(this) // run the block, may return or suspend
}
1 -> {
label = 2
result.getOrThrow() // this is the result if the block had suspended
}
else -> error("This coroutine had already completed")
}
}
}
-
createCoroutineUnintercepted(receiver, completion)方法在Kotlin源码中是通过suspend关键字修饰的扩展方法。
-
suspend关键字修饰(suspend R.() -> T)对象实际被编译成为一个Function2<r, continuation, Any?>接口对象,而关键字suspend实际编译成了Continuation接口。
所以:
-
协程体本身就是Continuation,即必须在协程内调用suspend挂起函数。
-
suspend关键字并不具备暂停、挂起代码块或者函数方法功能。
5.2.2 状态机CPS
协程实际挂起是如何实现的?
这里首先通过一个示例来演示一下状态机。
suspend fun main() {
log(1)
log(returnSuspended())
log(2)
delay(1000)
log(3)
log(returnImmediately())
log(4)
}
suspend fun returnSuspended() = suspendCoroutineUninterceptedOrReturn<String>{
continuation ->
thread {
Thread.sleep(1000)
continuation.resume("Return suspended.")
}
COROUTINE_SUSPENDED
}
suspend fun returnImmediately() = suspendCoroutineUninterceptedOrReturn<String>{
log(5)
"Return immediately."
}
这里我们定义了两个挂起函数,一个会真正挂起,一个会直接返回结果,其运行结果为:
[main]:1
[Thread-2]:Return suspended.
[Thread-2]:2
[kotlinx.coroutines.DefaultExecutor]:3
[kotlinx.coroutines.DefaultExecutor]:5
[kotlinx.coroutines.DefaultExecutor]:Return immediately.
[kotlinx.coroutines.DefaultExecutor]:4
前述代码的实际实现情况大致如下:
public class ContinuationImpl implements Continuation<Object> {
private int label = 0;
private final Continuation<Unit> completion;
public ContinuationImpl(Continuation<Unit> completion) {
this.completion = completion;
}
@Override
public CoroutineContext getContext() {
return EmptyCoroutineContext.INSTANCE;
}
@Override
public void resumeWith(@NotNull Object o) {
try {
Object result = o;
switch (label) {
case 0: {
LogKt.log(1);
result = SuspendFunctionsKt.returnSuspended( this);
label++;
if (isSuspended(result)) return;
}
case 1: {
LogKt.log(result);
LogKt.log(2);
result = DelayKt.delay(1000, this);
label++;
if (isSuspended(result)) return;
}
case 2: {
LogKt.log(3);
result = SuspendFunctionsKt.returnImmediately( this);
label++;
if (isSuspended(result)) return;
}
case 3:{
LogKt.log(result);
LogKt.log(4);
}
}
completion.resumeWith(Unit.INSTANCE);
} catch (Exception e) {
completion.resumeWith(e);
}
}
private boolean isSuspended(Object result) {
return result == IntrinsicsKt.getCOROUTINE_SUSPENDED();
}
}
-
首先定义了一个ContinuationImpl,即一个Continuation的实现。
-
可以在 Kotlin 的标准库当中找到一个名叫 ContinuationImpl 的类,其 resumeWith 最终调用到了 invokeSuspend,而这个 invokeSuspend 实际上就是我们的协程体,通常也就是一个 Lambda 表达式。
-
通过 launch启动协程,传入的那个 Lambda 表达式,实际上会被编译成一个 SuspendLambda 的子类,而它又是 ContinuationImpl 的子类。
public class RunSuspend implements Continuation<Unit> {
private Object result;
@Override
public CoroutineContext getContext() {
return EmptyCoroutineContext.INSTANCE;
}
@Override
public void resumeWith(@NotNull Object result) {
synchronized (this){
this.result = result;
notifyAll(); // 协程已经结束,通知下面的 wait() 方法停止阻塞
}
}
public void await() throws Throwable {
synchronized (this){
while (true){
Object result = this.result;
if(result == null) wait(); // 调用了 Object.wait(),阻塞当前线程,在 notify 或者 notifyAll 调用时返回
else if(result instanceof Throwable){
throw (Throwable) result;
} else return;
}
}
}
}
接着,定义了一个RunSuspend,用来接收结果。
public static void main(String... args) throws Throwable {
RunSuspend runSuspend = new RunSuspend();
ContinuationImpl table = new ContinuationImpl(runSuspend);
table.resumeWith(Unit.INSTANCE);
runSuspend.await();
}
作为 completion 传入的 RunSuspend 实例的 resumeWith 实际上是在 ContinuationImpl 的 resumeWtih 的最后才会被调用,因此它的 await() 一旦进入阻塞态,直到 ContinuationImpl 的整体状态流转完毕才会停止阻塞,此时进程也就运行完毕正常退出了。
这段代码的运行结果为:
/******打印结果******/
[main]:1
[Thread-2]:Return suspended.
[Thread-2]:2
[kotlinx.coroutines.DefaultExecutor]:3
[kotlinx.coroutines.DefaultExecutor]:5
[kotlinx.coroutines.DefaultExecutor]:Return immediately.
[kotlinx.coroutines.DefaultExecutor]:4
-
协程体的执行就是一个状态机,每一次遇到挂起函数,都是一次状态转移,就像我们前面例子中的 label 不断的自增来实现状态流转一样
-
状态机即代码中每一个挂起点和初始挂起点对应的Continuation都会转化为一种状态,协程恢复只是跳转到下一种状态。
-
挂起函数将执行过程分为多个 Continuation 片段,并且利用状态机的方式保证各个片段是顺序执行的,所以异步逻辑也可以用顺序的代码来实现。
5.3 协程运行原理
前述相关示例更多是为了验证分析协程的一些特性,这里从协程的创建、启动、恢复、线程调度,协程切换等详细解析协程的实现。
5.3.1 协程创建与启动
首先创建一个协程并启动,最常见的莫过于CoroutineScope.launch{},其源码实现为:
public fun CoroutineScope.launch(
context: CoroutineContext = EmptyCoroutineContext,
start: CoroutineStart = CoroutineStart.DEFAULT,
block: suspend CoroutineScope.() -> Unit
): Job {
val newContext = newCoroutineContext(context)
val coroutine = if (start.isLazy)
LazyStandaloneCoroutine(newContext, block) else
StandaloneCoroutine(newContext, active = true)
coroutine.start(start, coroutine, block)
return coroutine
}
我们如果不指定start 参数,所以它会使用默认的 CoroutineStart.DEFAULT,最终 coroutine 会得到一个 StandaloneCoroutine。其实现自AbstractCoroutine,实现了Continuation。
前述分析suspend本质时已知,其最终会调用到createCoroutineUnintercepted,主要是创建了一个新的可挂起计算,通过调用resume(Unit)启动协程,返回值为Continuation,Continuation提供了resumeWith恢复协程的接口,用以实现协程恢复,Continuation封装了协程的代码运行逻辑和恢复接口。
将协程代码进行反编译,再看一下其字节码和java实现,例如
suspend fun test() {
CoroutineScope(Dispatchers.IO).launch {
delay(11)
}
}
查看其字节码实现时,可知其编译生成内部类。
协程的计算逻辑封装在invokeSuspend方法中,而SuspendLambda的继承关系为 ,
SuspendLambda -> ContinuationImpl -> BaseContinuationImpl -> Continuation
其中BaseContinuationImpl 部分关键源码如下:
internal abstract class BaseContinuationImpl(...) {
// 实现 Continuation 的 resumeWith,并且是 final 的,不可被重写
public final override fun resumeWith(result: Result<Any?>) {
...
val outcome = invokeSuspend(param)
...
}
// 由编译生成的协程相关类来实现
protected abstract fun invokeSuspend(result: Result<Any?>): Any?
}
前述的协程示例代码反编译为:
public static final Object test(@NotNull Continuation $completion) {
Job var10000 = BuildersKt.launch$default(CoroutineScopeKt.CoroutineScope((CoroutineContext)Dispatchers.getIO()), (CoroutineContext)null, (CoroutineStart)null, (Function2)(new Function2((Continuation)null) {
int label;
@Nullable
public final Object invokeSuspend(@NotNull Object $result) {
//挂起标识
Object var2 = IntrinsicsKt.getCOROUTINE_SUSPENDED();
switch(this.label) {
case 0:
ResultKt.throwOnFailure($result);
//设置挂起后恢复,进入的状态
this.label = 1;
if (DelayKt.delay(11L, this) == var2) {
return var2;
}
break;
case 1:
// 是否需要抛出异常
ResultKt.throwOnFailure($result);
break;
default:
throw new IllegalStateException("call to 'resume' before 'invoke' with coroutine");
}
return Unit.INSTANCE;
}
@NotNull
public final Continuation create(@Nullable Object value, @NotNull Continuation completion) {
Intrinsics.checkNotNullParameter(completion, "completion");
Function2 var3 = new <anonymous constructor>(completion);
return var3;
}
public final Object invoke(Object var1, Object var2) {
return ((<undefinedtype>)this.create(var1, (Continuation)var2)).invokeSuspend(Unit.INSTANCE);
}
}), 3, (Object)null);
return var10000 == IntrinsicsKt.getCOROUTINE_SUSPENDED() ? var10000 : Unit.INSTANCE;
}
所以,协程的启动流程为:resume(Unit)->resumeWith()->invokeSuspend()。
协程的挂起通过suspend挂起函数实现,协程的恢复通过Continuation.resumeWith实现。
5.3.2 协程线程调度
协程的线程调度是通过拦截器实现的,前面提到了协程启动调用到了startCoroutineCancellable,关于协程调度在前述的协程调度器部分已详细介绍了,这里再简单过一下。
@InternalCoroutinesApi
public fun <T> (suspend () -> T).startCoroutineCancellable(completion: Continuation<T>): Unit = runSafely(completion) {
createCoroutineUnintercepted(completion).intercepted().resumeCancellableWith(Result.success(Unit))
}
看一下其intercepted()的具体实现:
@SinceKotlin("1.3")
public actual fun <T> Continuation<T>.intercepted(): Continuation<T> =
(this as? ContinuationImpl)?.intercepted() ?: this
internal abstract class ContinuationImpl(
......
) : BaseContinuationImpl(completion) {
constructor(completion: Continuation<Any?>?) : this(completion, completion?.context)
public override val context: CoroutineContext
get() = _context!!
@Transient
private var intercepted: Continuation<Any?>? = null
public fun intercepted(): Continuation<Any?> =
intercepted
?: (context[ContinuationInterceptor]?.interceptContinuation(this) ?: this)
.also { intercepted = it }
// context[ContinuationInterceptor] 就是协程的 CoroutineDispatcher
......
}
public abstract class CoroutineDispatcher :
AbstractCoroutineContextElement(ContinuationInterceptor), ContinuationInterceptor {
public final override fun <T> interceptContinuation(continuation: Continuation<T>): Continuation<T> =
DispatchedContinuation(this, continuation)
......
}
intercepted()最终会使用协程的CoroutineDispatcher的interceptContinuation方法包装原来的 Continuation,拦截所有的协程运行操作。
DispatchedContinuation拦截了协程的启动和恢复,分别是resumeCancellableWith和重写的resumeWith(Result)。
internal class DispatchedContinuation<in T>(
@JvmField val dispatcher: CoroutineDispatcher,
@JvmField val continuation: Continuation<T>
) : DispatchedTask<T>(MODE_UNINITIALIZED), CoroutineStackFrame, Continuation<T> by continuation {
@Suppress("NOTHING_TO_INLINE")
inline fun resumeCancellableWith(
result: Result<T>,
noinline onCancellation: ((cause: Throwable) -> Unit)?
) {
val state = result.toState(onCancellation)
//判断是否需要线程调度
if (dispatcher.isDispatchNeeded(context)) {
_state = state
resumeMode = MODE_CANCELLABLE
//将协程运算分发到另一个线程
dispatcher.dispatch(context, this)
} else {
executeUnconfined(state, MODE_CANCELLABLE) {
if (!resumeCancelled(state)) {
//直接在当前线程执行协程运算
resumeUndispatchedWith(result)
}
}
}
}
override fun resumeWith(result: Result<T>) {
val context = continuation.context
val state = result.toState()
//判断是否需要线程调度
if (dispatcher.isDispatchNeeded(context)) {
_state = state
resumeMode = MODE_ATOMIC
//将协程的运算分发到另一个线程
dispatcher.dispatch(context, this)
} else {
executeUnconfined(state, MODE_ATOMIC) {
withCoroutineContext(this.context, countOrElement) {
//直接在当前线程执行协程运算
continuation.resumeWith(result)
}
}
}
}
}
internal abstract class DispatchedTask<in T>(
@JvmField public var resumeMode: Int
) : SchedulerTask(){
public final override fun run() {
//封装了 continuation.resume 逻辑
}
......
}
5.3.3 协程挂起与恢复
编译器会生成继承自SuspendLambda的子类,协程的真正运算逻辑都在invokeSuspend中。这里我们先再次回到startCoroutineCancellable函数中。
internal fun <R, T> (suspend (R) -> T).startCoroutineCancellable(
receiver: R, completion: Continuation<T>,
onCancellation: ((cause: Throwable) -> Unit)? = null
) =
runSafely(completion) {
createCoroutineUnintercepted(receiver, completion).intercepted().resumeCancellableWith(Result.success(Unit), onCancellation)
}
看一下其中的resumeCancellableWith方法。
public fun <T> Continuation<T>.resumeCancellableWith(
result: Result<T>,
onCancellation: ((cause: Throwable) -> Unit)? = null
): Unit = when (this) {
is DispatchedContinuation -> resumeCancellableWith(result, onCancellation)
else -> resumeWith(result)
}
这是Continuation的扩展方法,最后都会调用到Continuation的resumeWith,这里的Continuation就是前述所说的SuspendLambda,它继承了 BaseContinuationImpl
internal abstract class BaseContinuationImpl(
public val completion: Continuation<Any?>?
) : Continuation<Any?>, CoroutineStackFrame, Serializable {
// This implementation is final. This fact is used to unroll resumeWith recursion.
public final override fun resumeWith(result: Result<Any?>) {
// This loop unrolls recursion in current.resumeWith(param) to make saner and shorter stack traces on resume
var current = this
var param = result
while (true) {
probeCoroutineResumed(current)
with(current) {
val completion = completion!! // fail fast when trying to resume continuation without completion
val outcome: Result<Any?> =
try {
//执行invokeSuspend内的代码块
val outcome = invokeSuspend(param)
//如果代码块内执行了挂起方法,协程挂起,resumeWith执行结束,再次调用resumeWith时协程挂起点之后的代码才能继续执行
if (outcome === COROUTINE_SUSPENDED) return
Result.success(outcome)
} catch (exception: Throwable) {
Result.failure(exception)
}
releaseIntercepted() // this state machine instance is terminating
if (completion is BaseContinuationImpl) {
// 如果完成的completion也是BaseContinuationImpl,就会进入循环
current = completion
param = outcome
} else {
// 执行completion resumeWith方法
completion.resumeWith(outcome)
return
}
}
}
}
protected abstract fun invokeSuspend(result: Result<Any?>): Any?
.....
}
下面看一下invokeSuspend的实现逻辑。
fun main(args: Array<String>) {
val coroutineDispatcher = newSingleThreadContext("ctx")
// 启动协程 1
GlobalScope.launch(coroutineDispatcher) {
println("the first coroutine")
async (Dispatchers.IO) {
println("the second coroutine 11111")
delay(100)
println("the second coroutine 222222")
}.await()
println("the first coroutine end end end")
}
// 保证 main 线程存活,确保上面两个协程运行完成
Thread.sleep(500)
}
前述示例编译成SuspendLambda子类的invokeSuspend方法为:
public final Object invokeSuspend(@NotNull Object $result) {
//挂起函数返回标识SUSPEND_FLAG
Object var5 = IntrinsicsKt.getCOROUTINE_SUSPENDED();
String var3;
boolean var4;
//label默认初始值为0
switch(this.label) {
case 0:
ResultKt.throwOnFailure($result);
CoroutineScope $this$launch = (CoroutineScope)this.L$0;
var3 = "the first coroutine";
var4 = false;
System.out.println(var3);
//新建并启动 async 协程
Deferred var10000 = BuildersKt.async$default($this$launch, (CoroutineContext)Dispatchers.getIO(), (CoroutineStart)null, (Function2)(new Function2((Continuation)null) {
int label;
@Nullable
public final Object invokeSuspend(@NotNull Object $result) {
//挂起标识
Object var4 = IntrinsicsKt.getCOROUTINE_SUSPENDED();
String var2;
boolean var3;
switch(this.label) {
case 0:
ResultKt.throwOnFailure($result);
var2 = "the second coroutine 11111";
var3 = false;
System.out.println(var2);
this.label = 1;
//判断是否执行delay挂起函数
if (DelayKt.delay(100L, this) == var4) {
//挂起,跳出该方法
return var4;
}
break;
case 1:
ResultKt.throwOnFailure($result);
// 恢复协程后再执行一次 resumeWith(),然后无异常的话执行最后的 println()
break;
default:
throw new IllegalStateException("call to 'resume' before 'invoke' with coroutine");
}
var2 = "the second coroutine 222222";
var3 = false;
System.out.println(var2);
return Unit.INSTANCE;
}
@NotNull
public final Continuation create(@Nullable Object value, @NotNull Continuation completion) {
Intrinsics.checkNotNullParameter(completion, "completion");
Function2 var3 = new <anonymous constructor>(completion);
return var3;
}
public final Object invoke(Object var1, Object var2) {
return ((<undefinedtype>)this.create(var1, (Continuation)var2)).invokeSuspend(Unit.INSTANCE);
}
}), 2, (Object)null);
//设置挂起后恢复时,进入的状态
this.label = 1;
//调用await()挂起函数
if (var10000.await(this) == var5) {
return var5;
}
break;
case 1:
ResultKt.throwOnFailure($result);
break;
default:
throw new IllegalStateException("call to 'resume' before 'invoke' with coroutine");
}
var3 = "the first coroutine end end end";
var4 = false;
System.out.println(var3);
return Unit.INSTANCE;
}
如果async线程未执行完成,await()返回为IntrinsicsKt.getCOROUTINE_SUSPENDED(),就会 return,launch 协程的invokeSuspend方法执行完成,协程所在线程继续往下运行,此时 launch 协程处于挂起状态。
所以协程的挂起在代码层面来说就是跳出协程执行的方法体,或者说跳出协程当前状态机下的对应状态,然后等待下一个状态来临时在进行执行。
关于协程挂起有三点注意事项:
-
启动其他协程并不会挂起当前协程,所以launch和async启动线程时,除非新协程运行在当前线程,则当前协程只能在新协程运行完成后继续执行,否则当前协程都会马上继续运行。
-
协程挂起并不会阻塞线程,因为协程挂起时相当于执行完协程的方法,线程继续执行其他之后的逻辑。
-
挂起函数并一定都会挂起协程,例如await()挂起函数如果返回值不等于IntrinsicsKt.getCOROUTINE_SUSPENDED(),则协程继续执行挂起点之后逻辑。
看完invokeSuspend,我们再次回到startCoroutineCancellable函数中,其调用的createCoroutineUnintercepted 方法中创建的 SuspendLambda 实例是 BaseContinuationImpl 的子类对象,其 completion 参数为下:
launch: if (isLazy) LazyStandaloneCoroutine else StandaloneCoroutine
async: if (isLazy) LazyDeferredCoroutine else DeferredCoroutine
上面这几个类都是 AbstractCoroutine 的子类。而根据 completion 的类型会执行不同的逻辑:
BaseContinuationImpl: 执行协程逻辑
其它: 调用 resumeWith 方法,处理协程的状态,协程挂起后的恢复即与它有关
前述的示例中async启动的协程,也会调用其invokeSuspend方法执行async协程,假设async 返回的结果已经可用时,即非 COROUTINE_SUSPENDED 值,此时 completion 是 DeferredCoroutine 对象,因此就会调用 DeferredCoroutine.resumeWith 方法,然后返回,父协程的恢复逻辑便是在这里。
public final override fun resumeWith(result: Result<T>) {
val state = makeCompletingOnce(result.toState())
if (state === COMPLETING_WAITING_CHILDREN) return
afterResume(state)
}
在 makeCompletingOnce 方法中,会根据 state 去处理协程状态,这里最终会走到ResumeAwaitOnCompletion.invoke 来恢复父协程,必要的话还会把 async 的结果给它。
private class ResumeAwaitOnCompletion<T>(
private val continuation: CancellableContinuationImpl<T>
) : JobNode() {
override fun invoke(cause: Throwable?) {
val state = job.state
assert { state !is Incomplete }
if (state is CompletedExceptionally) {
// Resume with with the corresponding exception to preserve it
continuation.resumeWithException(state.cause)
} else {
// resume 被挂起的协程
@Suppress("UNCHECKED_CAST")
continuation.resume(state.unboxState() as T)
}
}
}
这里的 continuation 就是 launch 协程体,也就是 SuspendLambda 对象,于是 invoke 方法会再一次调用到 BaseContinuationImpl.resumeWith 方法,接着调用 SuspendLambda.invokeSuspend, 然后根据 label 取值继续执行接下来的逻辑!
launch 协程恢复的过程,从 async 协程的SuspendLambda的子类的completion.resumeWith(outcome) -> AbstractCoroutine.resumeWith(result) ..-> JobSupport.tryFinalizeSimpleState() -> JobSupport.completeStateFinalization() -> state.list?.notifyCompletion(cause) -> node.invoke,最后 handler 节点里面通过调用resume(result)恢复协程。
await()挂起函数恢复协程的原理:
-
将 launch 协程封装为 ResumeAwaitOnCompletion 作为 handler 节点添加到 aynsc 协程的 state.list
-
然后在 async 协程完成时会通知 handler 节点调用 launch 协程的 resume(result) 方法将结果传给 launch 协程,并恢复 launch 协程继续执行 await 挂起点之后的逻辑。
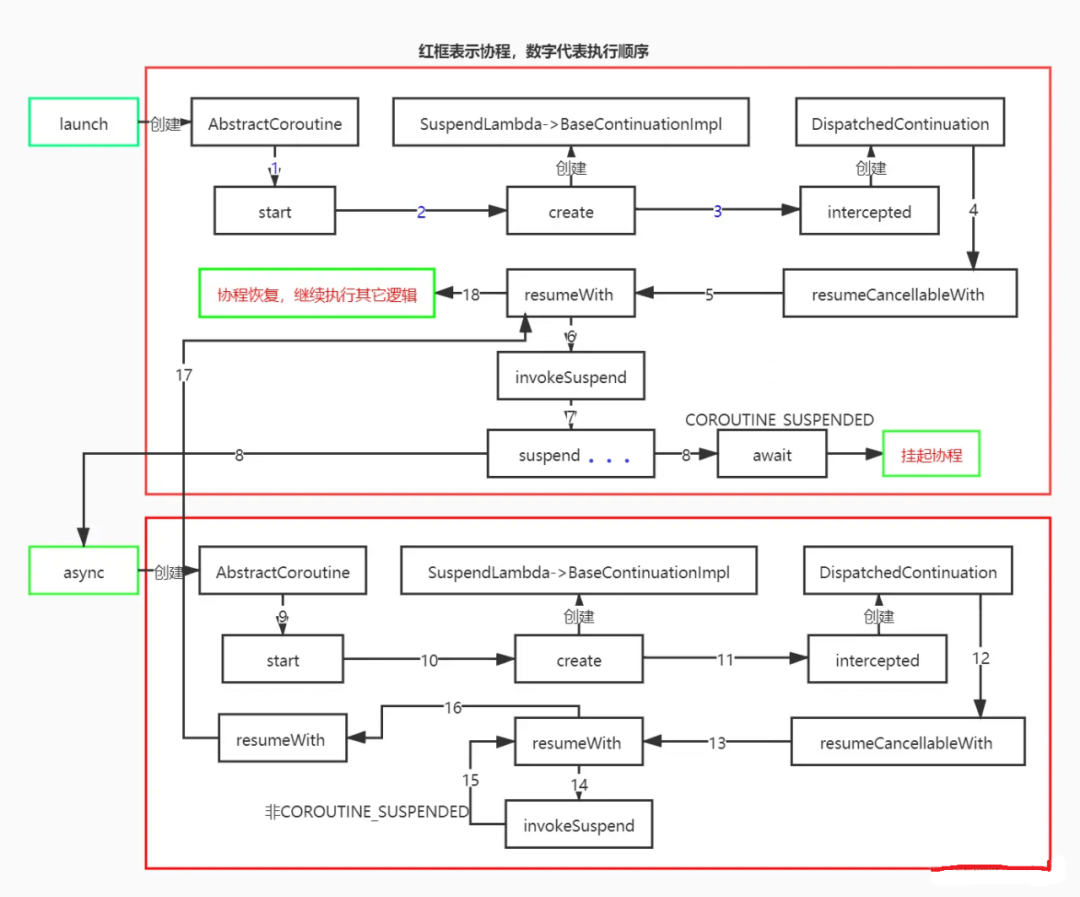
5.3.4 协程三层封装
通过前述的一系列分析可知,协程有三层封装:
常用的launch和async返回的Job、Deferred,里面封装了协程状态,提供了取消协程接口,而它们的实例都是继承自AbstractCoroutine,它是协程的第一层包装。
第二层包装是编译器生成的SuspendLambda的子类,封装了协程的真正运算逻辑,继承自BaseContinuationImpl,其中completion属性就是协程的第一层包装。
第三层包装是前面分析协程的线程调度时提到的DispatchedContinuation,封装了线程调度逻辑,包含了协程的第二层包装。
协程其实就是一段可以挂起和恢复执行的运算逻辑,而协程的挂起通过挂起函数实现,挂起函数用状态机的方式用挂起点将协程的运算逻辑拆分成不同的片段,每次运行协程执行不同的逻辑片段。
所以协程有两个很大的好处:
简化异步编程,支持异步返回;
挂起不阻塞线程,提供线程利用率
六、总结
本文通过为什么使用协程,协程如何创建启动,协程的调度原理和协程的挂起原理几个方面对协程进行了初步剖析,下面一起回顾一下全文重点内容,对全文内容进行一个总结
协程引入:
协程可以让异步代码同步化,降低程序涉及的复杂度
协程本质是轻量级线程,单个线程可以运行多个协程,协程的运行不会导致线程阻塞
协程启动:
协程启动需要三部分:上下文、启动模式、协程体。创建协程的方式有runBlocking、launch和async,推荐使用CoroutineScope.launch的方式创建协程,使用async的方式创建并发执行,同步等待获取返回值的情况。
Job是launch构建协程返回的一个协程任务,完成时没有返回值,可看成协程对象本身。其提供相关方法可用于观察协程执行情况。Deferred继承自Job,是async构建协程返回的一个协程任务,可通过调用await()方法等待执行完成获取结果。
启动协程需要作用域,作用域在协程创建过程中产生,常见的协程作用域有GlobalScope、coroutineScope等,协程配合Jetpack Lifecycle相关组件提供的lifecycleScope等作用域进行使用,异常丝滑好用。
协程的启动模式有DEFAULT、ATOMIC、UNDISPATCHED、LAZY四种,注意不同启动模式的区别。
如果要在父协程中进行子协程切换操作,可以使用withContext。
协程调度:
协程上下文是一个元素的集合,其定义是递归的,自己包含若干个自己,其结构介于set 和 map 之间。
协程实现的本质是回调,这个回调即Continuation。协程拦截器的实现就是拦截Continuation,可在此处进行缓存、日志打印等拦截处理
调度器即确认相关协程在哪个线程上执行,调度的本质是解决挂起恢复后协程逻辑在哪里运行的问题,其继承自拦截器。
调度器的是实现原理即在协程启动时通过拦截器进行拦截,返回一个Continuation,再在协程恢复进行resumeWith操作时,进行线程切换判断和线程切换。
协程挂起:
挂起函数是一个可启动、暂停和恢复的函数,被suspend修饰的函数在协程运行时不是一定会被挂起的。
挂起函数的挂起实现原理就是状态机的状态转移。协程体的执行就是一个状态机,每遇到一次挂起函数就是一次状态转移,而协程的恢复不过是从一种状态跳转到下一种状态。挂起函数将整个执行过程划分为多个Continuation片段,利用状态机的方式保证各个片段时顺序执行的,从而实现了用顺序的代码实现异步逻辑。
参考资料:
- 【1】破解Kotlin协程
- 【2】Kotlin Jetpack 实战 | 09.图解协程原理
- 【3】一文看透 Kotlin 协程本质
- 【4】抽丝剥茧Kotlin – 协程
- 【5】Kotlin协程实现原理
- 【6】kotlin 协程-Android实战
- 【7】kotlin 协程 官方指导文档


