Python爬虫系列(一)入门教学
- 2020 年 2 月 25 日
- 筆記
大家好,我是新来的小编小周。今天给大家带来的是python爬虫入门,文章以简为要,引导初学者快速上手爬虫。话不多说,我们开始今天的内容。
在初步学习爬虫之前,我们先用一个例子来看看爬虫是什么。

A同学想要了解python是一种怎样的语言,于是打开了某度搜索引擎,却发现占据屏幕的是各类python学习课程的广告,而真正介绍python的内容却被放在了后面。
事实上,在大多数时候,我们用浏览器获得的信息是十分繁冗的,因此筛选提取网页中对我们有用的数据就显得十分必要了。
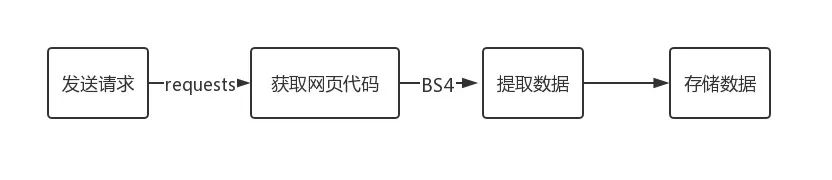
我们的爬虫程序要做的便是:
模拟浏览器发送请求–>获取网页代码–>筛选提取数据–>存放数据。
~前期准备~
爬虫程序中需要用到一些第三方库,我们这里使用的是requests库和BeautifulSoup4库。话不多说,让我们先来做好这些准备。(笔者使用的是IDLE3.8版本编辑器,及win系统)
requests 2.22.0下载地址:
https://pypi.org/project/requests/#files
BeautifulSoup4 4.8.2下载地址:
https://pypi.org/project/beautifulsoup4/#files
python3.0以上版本一般自带pip(可提供对第三方库的下载安装等),故第三方库下载后可直接进行安装。
1. 打开cmd

2. 若python安装在启动盘(一般是C盘)直接键入“pip install requests”命令即可。

3. 若python不在启动盘则键入“d:”然后“cd python.exe所在目录”,直接键入 ”python -m pip install requests”命令即可。

(BeautifulSoup4库安装步骤相同)
~发送请求~
模拟浏览器发送请求时,我们可以使用requests库帮助我们。下面给出requests库的7个主要方法:
|
requests.request() |
构造一个请求,支撑以下各方法的基础方法 |
|---|---|
|
requests.get() |
获取HTML网页的主要方法,对应HTTP的GET |
|
requests.head() |
获取HTML网页头信息的方法,对应HTTP的HEAD |
|
requests.post() |
向HTML网页提交POST请求方法,对应HTTP的POST |
|
requests.put() |
向HTML网页提交PUT请求的方法,对应HTTP的RUT |
|
requests.patch() |
向HTML网页提交局部修改请求,对应于HTTP的PATCH |
|
requests.delete() |
向HTML页面提交删除请求,对应HTTP的DELETE |
发送请求后,服务器会接受请求,并返回一个response。
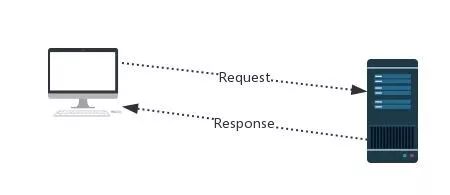
response作为一个对象,具有如下常用属性:
|
r.status_code |
HTTP请求的返回状态,200表示连接成功,404表示失败 |
|---|---|
|
r.text |
HTTP响应内容(字符串形式) |
|
r.content |
HTTP响应内容(二进制形式) |
接下来,我们以访问百度主页的代码为例来看看吧!
import requests url="http://www.baidu.com/" res=requests.get(url) print(res.status_code) 200
其中,我们介绍一下requests.get()函数的带参数形式。params是字典或字节序列,可以添加到url中;headers是HTTP的定制头等等。我们以headers为例,headers是HTTP的定制头,一些服务器在处理requests请求时会识别请求头,并拦截python爬虫。
import requests url="http://www.zhihu.com/" res=requests.get(url) print(res.status_code) 400 print(res.request.headers) {'User-Agent': 'python-requests/2.22.0', 'Accept-Encoding': 'gzip, deflate', 'Accept': '*/*', 'Connection': 'keep-alive'}
可以看到我们通过python访问知乎首页被拦截了,查看请求头时发现User-agent是python—-requests/2.22.0。下面我们尝试修改请求头伪装成浏览器:

import requests pre={'User-agent':'Mozilla/5.0'} res=requests.get("https://www.zhihu.com/billboard",headers=pre) print(res.status_code) 200
可见,修改请求头后访问成功。
利用requests的get方法和response的content属性(图片以二进制形式保存),我们可以下载网络上的一些图片,下面以获取新浪新闻的一张图片为例:
import requestsurl="http://www.sinaimg.cn/dy/slidenews/5_img/2015_48/30939_1300019_688168.jpg"path="D://pics//"+"maomi.jpg"try: res=requests.get(url) with open(path,'wb') as pic: pic.write(res.content) pic.close() print("文件保存成功")except: print("爬取失败")文件保存成功
~解析内容~
Beautiful Soup库是解析、遍历、维护文档树的功能库。
简单地说,BeautifulSoup能够帮助用户将response中的html内容解析,得到一个BeautifulSoup的对象,并且能够以标准的缩进格式输出。我们以知乎热榜网页为例(注意B和S要大写哦):
import requests from bs4 import BeautifulSoup pre={'User-agent':'Mozilla/5.0'} res=requests.get("https://www.zhihu.com/billboard",headers=pre) rep=res.text soup=BeautifulSoup(rep,"html.parser") print(soup)
运行代码后可以看见,已经产生标准缩进格式输出。(截取部分如下图)

这里,我们来认识一下BeautifulSoup类的部分元素:
|
Tag |
标签,最基本的信息组织单元,分别用<>和</>标明开头和结尾 |
|---|---|
|
Name |
标签的名字,<p>…</p>的名字是’p’,格式: <tag>. name |
|
Attributes |
标签的属性,字典形式组织,格式: <tag>. attrs |
|
NavigableString |
标签内非属性字符串,<>…</>中字符串,格式: <tag>.string |
在代码运行返回的html内容中,可以看见a标签里包含了<div><span>等子孙标签,其中包含了我们需要的热榜话题,利用这段代码我们可以获取热榜第一的信息进而获取榜单全部话题。
import requests from bs4 import BeautifulSoup pre={'User-agent':'Mozilla/5.0'} try: res=requests.get("https://www.zhihu.com/billboard",headers=pre) res.raise_for_status rep=res.text except: print("连接失败") try: soup=BeautifulSoup(rep,"html.parser") con=soup.find_all('div',class_="HotList-itemTitle") for i in range(len(con)): print(con[i].text) except: print("获取失败")
我们观察到所有热榜话题所在标签name都是div,属性中都包含class="HotList- itemTitle"。我们使用bs4的find_all函数,返回一个包含许多元素的列表,然后利用text属性提取有用的字符逐个输出。

今天的爬虫入门我们就先讲到这里哦,小周下期继续给大家带来爬虫分享哦!
最后,祝大家新年快乐,身体健康。


