程序分析与优化 – 10 指令级并行
本章是系列文章的第十章,主要介绍CPU流水线、超标量体系架构等硬件设计,和编译器怎么使能这些功能来减少计算的时钟周期。
本文中的所有内容来自学习DCC888的学习笔记或者自己理解的整理,如需转载请注明出处。周荣华@燧原科技
10.1 概念
- 指令级并行是是让一个程序中的多个操作同时执行的方法
- 指令级并行对原生的顺序程序也能带来并行效果
- 使能指令级并行的方法:
- 指令流水线,一起触发一条指令,但多条指令的执行时间可以重叠
- 超标量体系架构执行:一条指令里面由多条标量指令打包而成触发的并行执行
10.2 热身
对下面的c代码:
1 void swap(int v[], int k) { 2 int temp; 3 temp = v[k]; 4 v[k] = v[k + 1]; 5 v[k + 1] = temp; 6 }
有两种汇编编译结果。A1:
1 lw $t0, 0($t1) # reg $t0 (temp) = v[k] 2 lw $t2, 4($t1) # reg $t2 = v[k + 1] 3 sw $t2, 0($t1) # v[k] = reg $t2 4 sw $t0, 4($t1) # v[k + 1] = reg $t0 (temp)
A2:
1 lw $t0, 0($t1) 2 lw $t2, 4($t1) 3 sw $t0, 4($t1) 4 sw $t2, 0($t1)
哪种性能更好?
其实上面两种结果主要体现在第3条指令和第4条指令,是相反的。
要弄清这个问题,还得从CPU的指令流水线说起。
10.3 指令流水线
Instruction pipelining – Wikipedia中对指令流水线的概念做了一些扫盲,总结下来就是下面这张图:
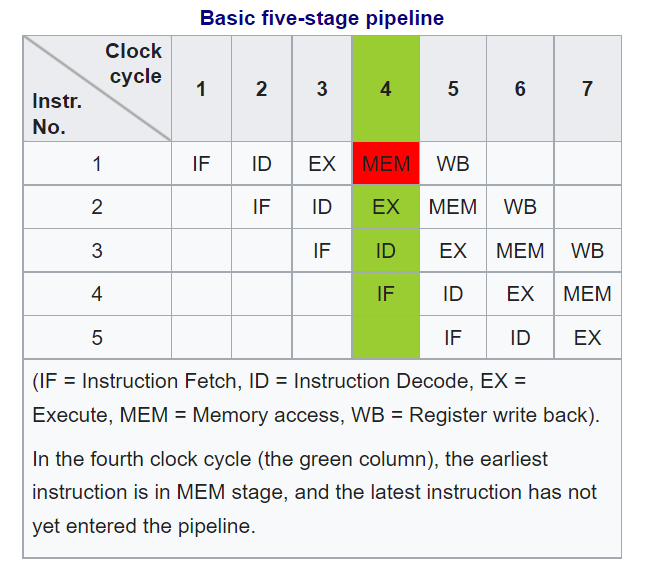
10.3.1 指令流水线的原理
常见的指令流水线的前提是一个指令执行过程中能被切割成好几块,当前主流的做法是切分成5个时钟周期来执行,也称为经典RISC流水线。在这个流水线中一条执行时间是5个时钟周期,但执行5个指令也只需要7个时钟周期,相对不做指令级并行的时候5*5=25个时钟周期而言,并行效果不言而喻。
10.3.1.1 IF
指令获取,Instruction Fetch,从代码段中获取指令。
10.3.1.2 ID
指令解码,Instruction Decode,计算机体系架构设计上,除了软件接口指令集外,最核心的就是微架构,所以一般软件生成的指令,还需要翻译成机器能识别的微指令,这样才能真正执行。
10.3.1.3 EX
执行,Execute。
10.3.1.4 MEM
访问内存,Memory Access。
10.3.1.5 WB
寄存器回写。
有很多处理器的流水线不是固定的,例如 Intel Pentium 4,由于x86是CISC,每个指令的长度本身就不一样,实际实现是指令的执行周期也不完全一样,Pentium 4的指令执行周期有的要7步,甚至最长20步的,但设计原理是类似的Recap13.ppt (live.com):

这些的并行的步骤,每个CPU(核)每次只能执行每类小步骤中的一步,不同类的小步骤是可以并发执行的,靠着将指令执行过程中的每个小步骤错开并行起来,就实现了指令流水线的功能。
如果指令的总的执行时间是固定的,那么切分出来的步骤越多,那并行效果就会越好,性能越好。
但是步骤越多,让程序能指令级并行起来,编译器的逻辑就越复杂,这种20步的流水线,估计得被编译器团队给喷死,所以后面x86体系架构再也没有突破20步 :)。
10.3.2 数据冲突
指令流水线能并发执行的前提是指令间没有数据冲突。如果指令I1的输入依赖指令I2的输出,那在I2执行完之前I1是没法执行的,这就是数据冲突的含义。数据冲突太多,就会造成编译器无法生成并行度很高的指令流水线序列,这种情况就会造成指令流水线熄火。
回到上面的例子,如果把$t2寄存器的读指令和写指令放到一起,那这2个指令就会造成指令流水线熄火:
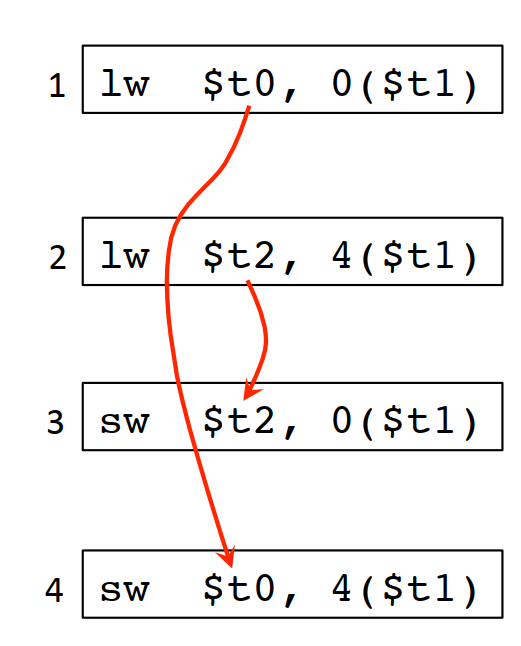
相反,如果把t0和t2寄存器的读写操作插花式排列开来,如果是2步的流水线,可以完全不熄火,对3步的流水线,最多只会熄火一步,所以后面这种插花的方式性能更好:
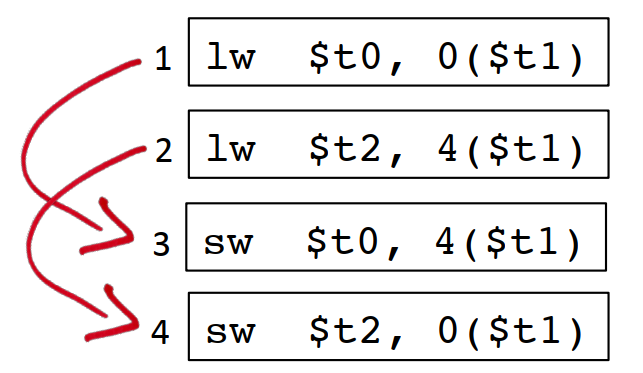
10.3.3 数据转发
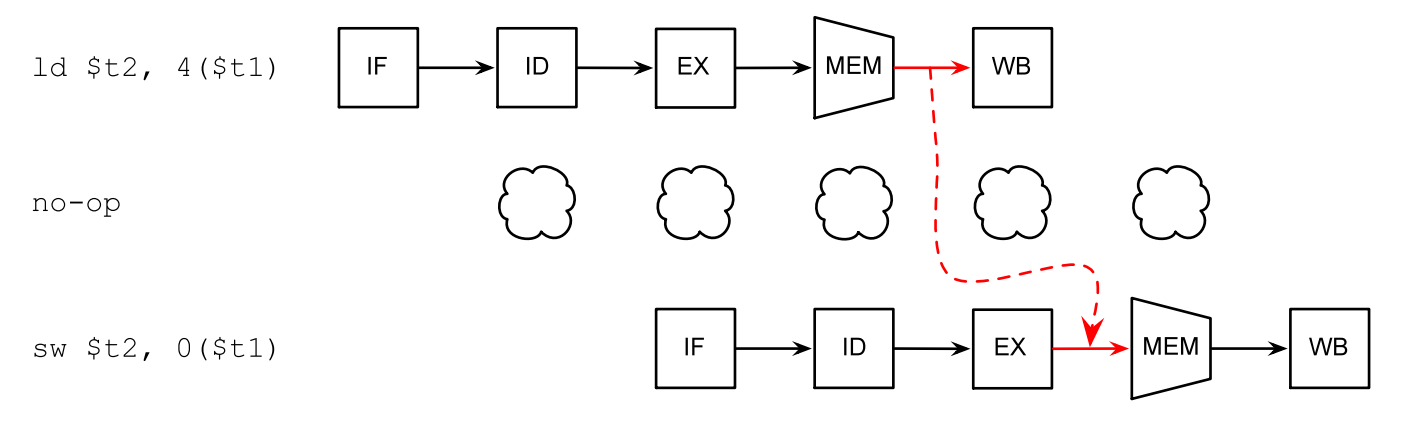
如果某条指令的输出正好是后面指令的输入,处理器可以直接将结果转发给后面的指令:
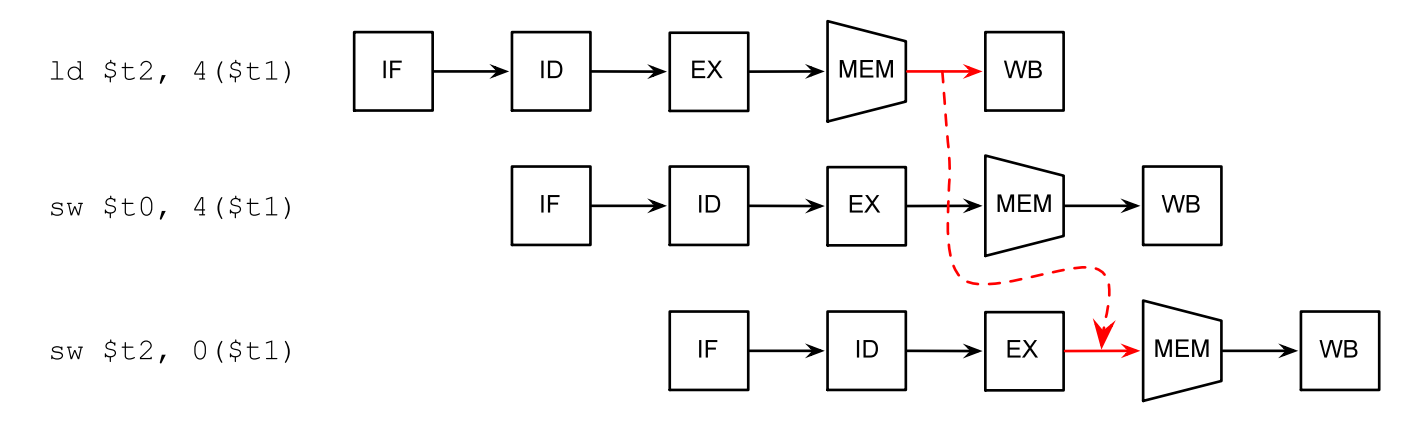
如果实在没办法,编译器会插入一些no-op指令,让处理器“怠速”一个时钟周期:
10.4 超标量体系架构
除了指令之间的流水线,超标量体系架构依赖指令内部的多条子指令之间的流水线来达到并行的效果。超标量体系架构其实依赖的是单个处理器中的多个IP(这里的IP不是TCP/IP协议栈里面的ip地址,是intellectual property的简称,是处理器里面可以用来拼装成一个大的处理的积木块,也是可以独立运行的处理单元)相互独立执行来实现的。例如一个VLIW(Very Long Instruction Words,超长指令字)里面可能既有主cpu的操作命令,也有DMA处理器的操作指令。一条GPU的指令里面,可能既有控制指令,也有数据指令。
10.5 寄存器和并行
寄存器导致的依赖分三种(下面的读、写都是相对于寄存器来说的):
- 真实依赖,先写后读
lw $t0, 0($t1)
st $t0, 4($t1)
-
反依赖,先读后写
st $t0, 4($t1)
lw $t0, 0($t1)
- 输出依赖,连续写
lw $t0, 0($t1)
lw $t0, 4($t1)
除了第一种,后面两种如果寄存器数量足够的情况下,可以通过分配额外的寄存器来消除依赖。
寄存器分配算法让我们尽可能的少用寄存器,但多个变量复用同一个寄存器的做法又会额外注入数据依赖,使相关代码无法并行执行。
以(a + b) + c + (d + e)为例,默认寄存器分配算法结果是这样的:
1 LD r1, a 2 LD r2, b 3 ADD r1, r1, r2 4 LD r2, c 5 ADD r1, r1, r2 6 LD r2, d 7 LD r3, e 8 ADD r2, r2, r3 9 ADD r1, r1, r2
这样分配的结果,导致这些指令能并行的可能性非常小,仅1/2和6/7这种连续的LD指令可以并行,其他都必须等上一行执行完才能开始执行,9条指令需要7条指令顺序执行的时间。
但我们通过抽象语法树的分析看,d+e的计算,其实和这之前的两次加法也是不相干的,也可以并行;5个变量的LD指令,如果寄存器数量足够的情况下,也可以并行。
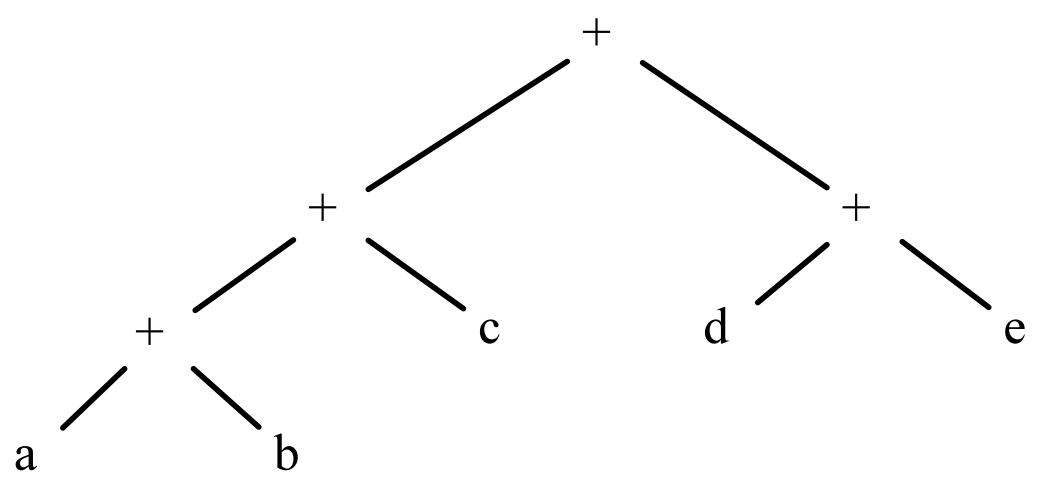
理想的并行结果是这样,只需要4条指令的执行时间就可以把这个计算完成:

怎么样尽可能并行的前提下,减少寄存器的使用?
10.6 基本块调度
基本块调度(Basic Block Scheduling)也称本地调度(Local Scheduling)。主要使用指令依赖图(有的地方也称为数据依赖图)来进行分析,程序中的每条指令是一个节点,如果节点i1使用节点i0定义的变量,则存在一条边(i0, i1)。指令依赖图IDG中的每条边是一个delay,决定了最终至少需要多少个时钟周期才能完成程序执行。
以下面的程序为例:
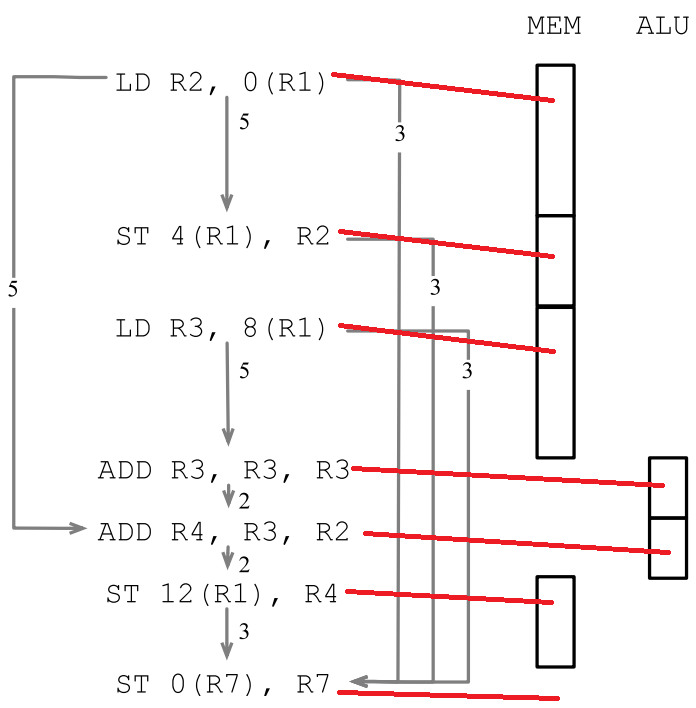
1 LD R2, 0(R1) 2 ST 4(R1), R2 3 LD R3, 8(R1) 4 ADD R3, R3, R3 5 ADD R4, R3, R2 6 ST 12(R1), R4 7 ST 0(R7), R7
假定每条LD/ST指令需要5个时钟周期(除非LD指令紧接着ST指令,并且两个指令操作同一个内存地址,这种情况下ST指令只需要3个时钟周期),每条算术运行需要2个时钟周期,算一下该程序需要多少时钟周期?指令依赖图可以这样画:

但即使不存在数据依赖,如果多个指令使用同一个资源,也需要排队,所以如果先调度LD R2, 0(R1)的话,需要的时钟周期是5+3+5+2+2+3+1=21个:
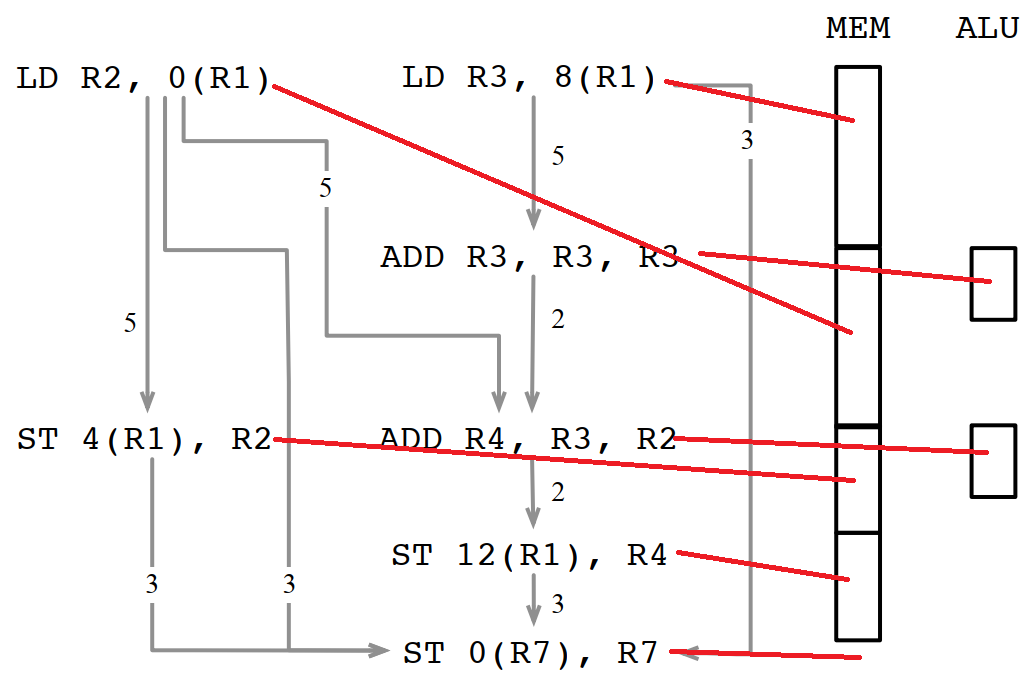
而先调度LD R3, 8(R1)的话,需要的时钟周期是5+5+3+3+1=17个。
算法描述如下:
1 RT = empty reservation table 2 foreach vn ∈ V in some topological order: 3 s = MAX {S(p) + de | e = p→n ∈ E} // 对所有n的前驱p,求p的执行开始时间和p到n之间的delay,并在其中取最大值,也就是节点n的执行开始时间 4 let i = MIN {x | RT(n, j, x) ∈ RT} in 5 s' = s + MAX(0, i – s) 6 RT(n, j, s') = vn // 在所有可获得的RT资源中,取高度最小的一个资源申请表,来调度n
下面是龙书上的算法描述,可以对照起来看:

生成的资源调度图如下:
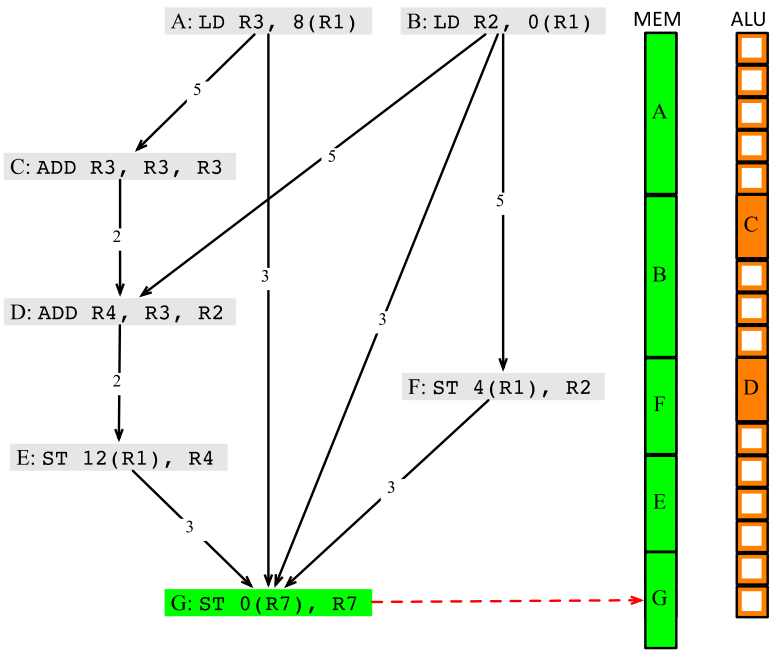
10.7 全局代码调度
先看一个简单的例子:
1 if (a != 0) { 2 c = b 3 } 4 e = d + d
优化前后的指令如下,红色部分是做了指令移动的代码:

上面每个框里面有个灰色的线,将两块指令放在了一起,在普通体系架构下,只是简单的将他们进行流水线排序,如果在VLIW体系架构下,实际上是可以真正并发执行的,带来的效果类似这样:
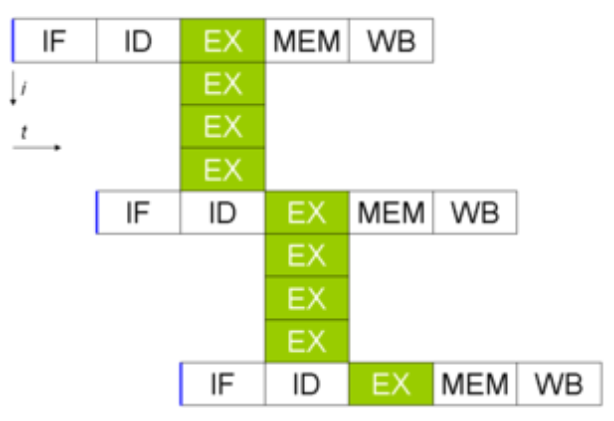
实际上全局代码调度相对于一个基本块内的调度要复杂得多,主要涉及代码移动,不安全的决策,额外执行了可能不需要的指令等问题。
后支配(Postdominate):如果一个节点dst到程序终止的所有路径都要经过节点src,则称为src对dst有后支配关系。
控制流一致性(Control Equivalence):如果dst支配src,并且src后支配dst,则说明src和dst是控制一致的。
如果代码移动前后对应的位置具有控制流一致性,则这种迁移理论上是安全的。
10.7.1 代码上移
相应的,如果上移的代码不具备后支配性,则可能在某些场景下会多执行代码。
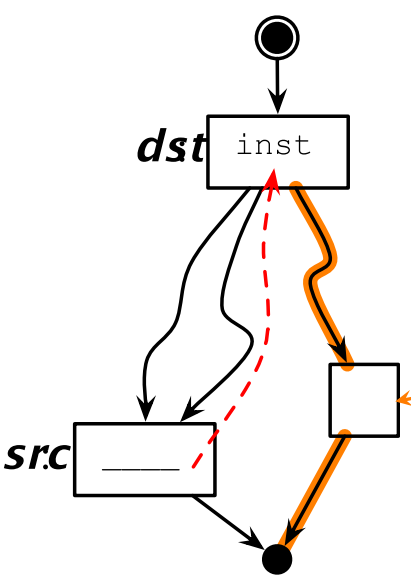
同样的,如果上移的代码不是源位置的支配节点,则需要在其他路径上插入补偿代码,来确保上移的代码在各种场景下都能执行到。
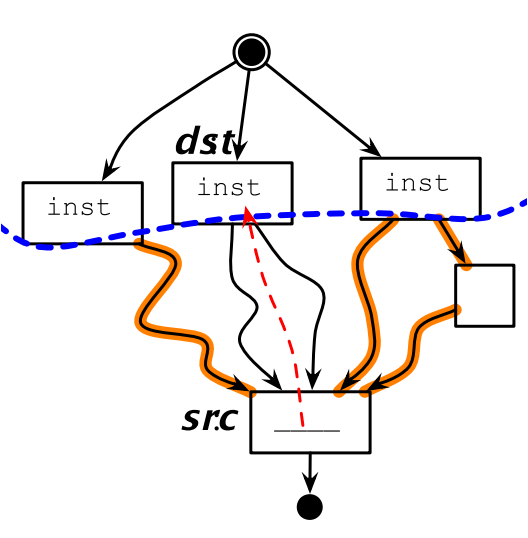
10.7.2 代码下移
如果src不是dst的支配节点的话,下移代码可能会覆盖另外一个分支的值:
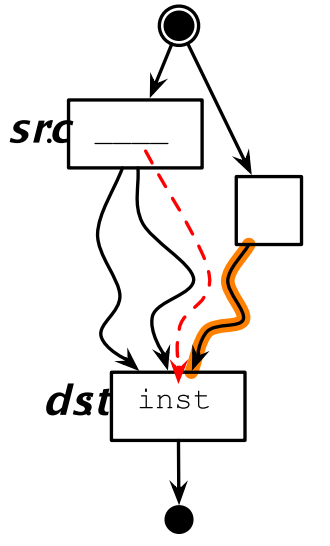
下行代码迁移也会有补偿代码的问题:
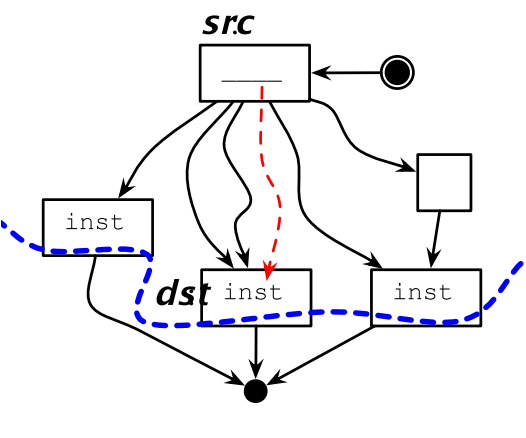
10.7.3 超级块
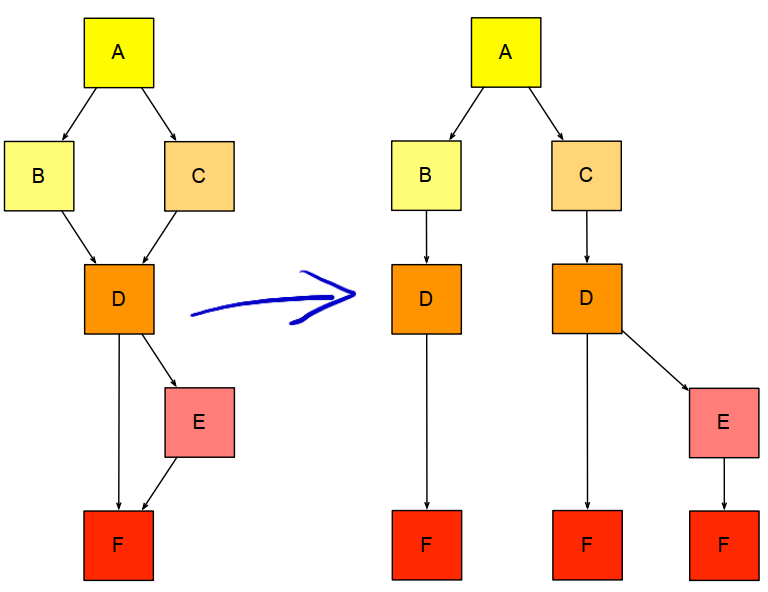
超级块是将多个基本块合并成的一个新的基本块。
例如对下面4个基本块:
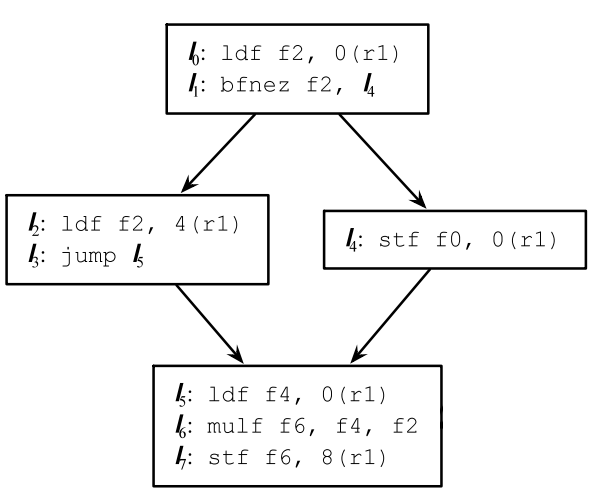
通过合并可以变成2个基本块,少了3次跳转指令,流水线就能更快的优化运行:
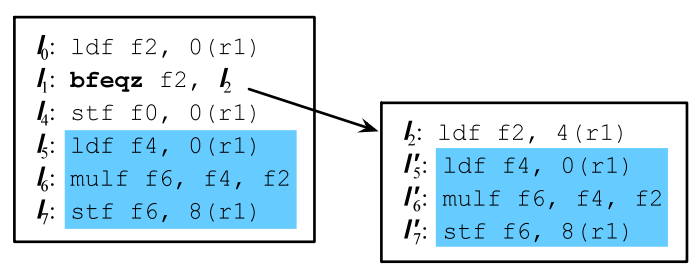
超级块的生成过程更通用一点的做法就是把DAG转换成树的过程:
10.7.4 静态profiling技术
通过一些先验的概率,推断某些分支走到的可能性,来优化概率更高的分支执行速率的方法。
但多个先验概率有可能是相互矛盾的,有时需要在多个先验概率直接做一些妥协,或者计算加权概率,最有名的是Dempster-Shafer定理:
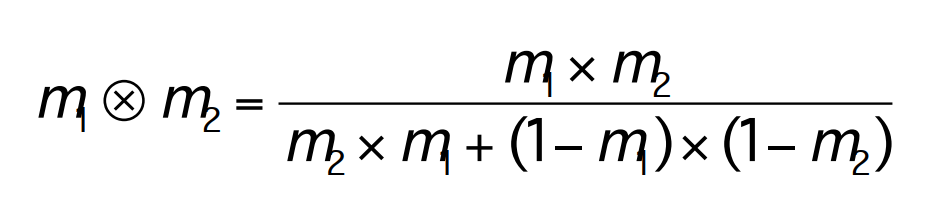
10.8 指令级并行研究历史
- Hennessy, J. L. and D. A. Patterson, Computer Architecture: A Quantitative Approach, Third Edition, 2003. 计算机体系架构的经典书,学编译器必看系列,本章的大多数描述来自这本书
- Kuck, D., Y. Muraoka, and S. Chen, On the number of operations simultaneously executable in Fortran-like programs and their resulting speedup. IEEE Transactions on Computers, pp. 1293-1310, 1972.
- Bernstein, D. and M. Rodeh, Global instruction scheduling for super-scalar machines, PLDI, pp. 241-255, 1991.


