机器学习回顾篇(6):KNN算法
- 2019 年 10 月 4 日
- 筆記
1 引言
本文将从算法原理出发,展开介绍KNN算法,并结合机器学习中常用的Iris数据集通过代码实例演示KNN算法用法和实现。
2 算法原理
KNN(kNN,k-NearestNeighbor)算法,或者说K近邻算法,应该算是机器学习中众多分类算法最好理解的一个了。古语有云:物以类聚,人以群分。没错,KNN算法正是这一思想为核心,对数据进行分类。
而所谓K近邻,意思是对于每一个待分类样本,都可以以与其最近的K个样本点的多数分类来来进行划分。举个例子,办公室新来了一个同事,他的位置边上坐着的10个(K=10)同事都是大多是Python程序员,我们会猜测这个新同事是Python程序员;如果把判断依据扩大的整个办公室,假设办公室有50个人(K=50),其中java程序员35个,那么我们就会认为这个新同事是java程序员。
回到KNN算法,对数据进行分类的思想和流程与我们判断新同事的工作是一样的:
(1)计算待分类样本与所有已知分类的样本之间的距离;
(2)对多有距离进行按升序排序;
(3)取前K个样本;
(4)统计前K个样本中各分类出现的频数;
(5)将待分类样本划分到频数最高的分类中。
好了,我想现在你应该对KNN算法有了基本的认识了。不过有几个问题还得明确一下:
K值如何确定?
如何度量距离?
先来说说如何确定K值。对于K值,从KNN算法的名称中,我们可以看出K值得重要性是毋庸置疑的。我们用下图的例子来说一说K值得样本分类的重要性:

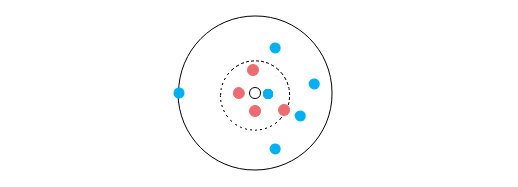
图中所有圆点构成一个数据集,圆点颜色代表分类,那么,图中无色圆点划分到哪个类呢?
当K=1时,离透明点最近的点是蓝点,那么我们应该将透明圆点划分到蓝点所在类别中;
当K=5时,离透明点最近的5个点中有4个红点,1个蓝点,那么我们应该将透明圆点划分到红点所属的类别中;
当K=10时,离透明点最近的10个点中有4个红点,6个蓝点,那么我们应该将透明圆点划分到蓝点所属的类别中。
你看,最终的结果因K值而异,K值过大过小都会对数据的分类产生不同程度的影响:
当K取较小值时,意味着根据与待测样本距离较小的小范围内样本对待测样本的类别进行预测,这么做的优点是较远范围的样本数据不会对分类结果产生影响,训练误差(机器学习模型在训练数据集上表现出的误差叫做训练误差)较小。但却容易导致过拟合现象的产生,增大泛化误差(在任意一个测试数据样本上表现出的误差的期望值叫做泛化误差)模型变得复杂,一旦带测验本附近有异常数据存在,分类经过就可能会产生较大的影响,例如上图上K=1时,如果最近的蓝点是异常数据,那么对透明圆点的预测结果就因此变得异常。
当K较大值时,意味着综合更大范围的样本对待测验本类别进行预测,优点是可以减少泛化误差,但训练误差随之增大,模型变得简单。一个极端的例子就是如上图所示,当K取值为整个数据集规模时,整个预测过程就没有太大价值,所有待测样本类别都会被预测为数据集中样本数量多的一类。
对于K值的确定,目前并没有专门的理论方案,一个较普遍的做法就是将数据集分为两部分,一部分用作训练集,一部分用作测试集,从K取一个较小值开始,逐步增加K值,最终去准确率最高的一个K值。
一般而言,K取值不超过20,上限是n的开方,随着数据集的增大,K的值也要增大。另外,K的取值尽量要取奇数,以保证在计算结果最后会产生一个较多的类别,如果取偶数可能会产生相等的情况,不利于预测。
关于距离度量,我们最熟悉的、使用最广泛的就是欧式距离了。对于$d$维数据点$x$和$y$之间的欧氏距离定义为:
除了欧氏距离外,距离度量方法还有余弦距离、哈曼顿距离、切比雪夫距离等,但使用不多,不介绍了。
最后总结一下KNN算法:
KNN的主要优点有:
1) 理论成熟,思想简单,既可以用来做分类也可以用来做回归
2) 可用于非线性分类
3) 和朴素贝叶斯之类的算法比,对数据没有假设,准确度高,对异常点不敏感
4) 由于KNN方法主要靠周围有限的邻近的样本,而不是靠判别类域的方法来确定所属类别的,因此对于类域的交叉或重叠较多的待分样本集来说,KNN方法较其他方法更为适合
5)该算法比较适用于样本容量比较大的类域的自动分类,而那些样本容量较小的类域采用这种算法比较容易产生误分
KNN的主要缺点有:
1)计算量大,尤其是特征数非常多的时候
2)样本不平衡的时候,对稀有类别的预测准确率低
3)使用懒散学习方法,基本上不学习,导致预测时速度比起逻辑回归之类的算法慢
4)相比决策树模型,KNN模型可解释性不强