es的查询、排序查询、分页查询、布尔查询、查询结果过滤、高亮查询、聚合函数、python操作es
今日内容概要
- es的查询
- Elasticsearch之排序查询
- Elasticsearch之分页查询
- Elasticsearch之布尔查询
- Elasticsearch之查询结果过滤
- Elasticsearch之高亮查询
- Elasticsearch之聚合函数
- Python操作es
内容详细
1、es的查询
1.1 准备数据
# 准备数据
PUT lqz/_doc/1
{
"name":"顾老二",
"age":30,
"from": "gu",
"desc": "皮肤黑、武器长、性格直",
"tags": ["黑", "长", "直"]
}
PUT lqz/_doc/2
{
"name":"大娘子",
"age":18,
"from":"sheng",
"desc":"肤白貌美,娇憨可爱",
"tags":["白", "富","美"]
}
PUT lqz/_doc/3
{
"name":"龙套偏房",
"age":22,
"from":"gu",
"desc":"mmp,没怎么看,不知道怎么形容",
"tags":["造数据", "真","难"]
}
PUT lqz/_doc/4
{
"name":"石头",
"age":29,
"from":"gu",
"desc":"粗中有细,狐假虎威",
"tags":["粗", "大","猛"]
}
PUT lqz/_doc/5
{
"name":"魏行首",
"age":25,
"from":"广云台",
"desc":"仿佛兮若轻云之蔽月,飘飘兮若流风之回雪,mmp,最后竟然没有嫁给顾老二!",
"tags":["闭月","羞花"]
}
1.2 match和term
match 和 term 中必须要加条件,但是我们有时候需要查询所有,不带条件,需要用到 match_all
1.3 match_all
# 查询所有
GET lqz/_search
{
"query": {
"match_all": {}
}
}
1.4 前缀查询match_phrase_prefix
# 查英文 beautiful --->be开头的---》能查到
GET lqz/_search
{
"query": {
"match_phrase_prefix": {
"name": "顾"
}
}
}
1.5 match_phrase
# 会分词,分词完成后,如果写了slop,会按分词之间间隔是slop数字去抽
GET t1/doc/_search
{
"query": {
"match_phrase": {
"title": {
"query": "中国世界",
"slop": 2
}
}
}
}
1.6 多条件查询,或的关系
# 只要name或者desc中带龙套就查出来
GET lqz/_search
{
"query": {
"multi_match": {
"query": "龙套",
"fields": ["name", "desc"]
}
}
}
2、Elasticsearch之排序查询
# 结构化查询
GET lqz/_search
{
"query": {
"match": {
"name": ""
}
}
}
# 排序查询---》可以按多个排序条件-->sort的列表中继续加
GET lqz/_search
{
"query": {
"match": {
"from": "gu"
}
},
"sort": [
{
"age": {
"order": "asc"
}
}
]
}
# 不是所有字段都可以排序--->只能是数字字段
3、Elasticsearch之分页查询
# from 和 size
GET lqz/_search
{
"query": {
"match_all": {}
},
"sort": [
{
"age": {
"order": "desc"
}
}
],
"from": 3,
"size": 2
}
4、Elasticsearch之布尔查询
# must(and) should(or) must_not(not) filter
# must条件 and条件
GET lqz/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"from": "sheng"
}
},
{
"match": {
"age": 18
}
}
]
}
}
}
"""
# 咱们认为的and查询,但是实际不行
GET lqz/_search
{
"query": {
"match": {
"from": "sheng",
"age":18
}
}
}
# 查询课程标题或者课程介绍中带python的数据
"""
# shoud or 条件---》搜索框,就是用它
GET lqz/_search
{
"query": {
"bool": {
"should": [
{
"match": {
"from": "sheng"
}
},
{
"match": {
"age": 22
}
}
]
}
}
}
# must_not 既不是也不是
GET lqz/_search
{
"query": {
"bool": {
"must_not": [
{
"match": {
"from": "gu"
}
},
{
"match": {
"tags": "可爱"
}
},
{
"match": {
"age": 18
}
}
]
}
}
}
# 查询 from为gu,age大于25的数据怎么查 filter /gt> lt< lte=
GET lqz/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"from": "gu"
}
}
],
"filter": {
"range": {
"age": {
"lt": 25
}
}
}
}
}
}
5、Elasticsearch之查询结果过滤
# 只查某几个字段
GET lqz/_search
{
"query": {
"match": {
"name": "顾老二"
}
},
"_source": ["name", "age"]
}
6、Elasticsearch之高亮查询
# 默认高亮
GET lqz/_search
{
"query": {
"match": {
"name": "石头"
}
},
"highlight": {
"fields": {
"name": {}
}
}
}
# 自定义高亮
GET lqz/_search
{
"query": {
"match": {
"from": "gu"
}
},
"highlight": {
"pre_tags": "<b class='key' style='color:red'>",
"post_tags": "</b>",
"fields": {
"from": {}
}
}
}
7、Elasticsearch之聚合函数
# avg max min sum
# avg 求平均年龄
GET lqz/_search
{
"query": {
"match": {
"from": "gu"
}
},
"aggs": {
"my_avg": {
"avg": {
"field": "age"
}
}
},
"_source": ["name", "age"]
}
8、Python操作es
# 官方提供了python操作es包,基础包--》建议你用---》类似于pymysql
pip install elasticsearch
'''
# 如果官方没提供,使用requests模块,发送http请求即可
# 例如:
PUT lqz/_doc/2
{
"name":"大娘子",
"age":18,
"from":"sheng",
"desc":"肤白貌美,娇憨可爱",
"tags":["白", "富","美"]
}
# 用python操作
import requests
data = {
"name": "大娘子",
"age": 18,
"from": "sheng",
"desc": "肤白貌美,娇憨可爱",
"tags": ["白", "富", "美"]
}
res=requests.put('//127.0.0.1:9200/lqz/_doc/6', json=data)
print(res.text)
'''
### 使用官方的包:
from elasticsearch import Elasticsearch
# Instantiate a client instance
client = Elasticsearch("//localhost:9200")
# Call an API, in this example `info()`
# resp = client.info()
# print(resp)
# 创建索引(Index)
# result = client.indices.create(index='user')
# print(result)
# 删除索引
# result = client.indices.delete(index='user')
# 插入数据
# data = {'userid': '1', 'username': 'lqz','password':'123'}
# result = client.create(index='news', doc_type='_doc', id=1, body=data)
# print(result)
# 更新数据
'''
不用doc包裹会报错
ActionRequestValidationException[Validation Failed: 1: script or doc is missing
'''
# data ={'doc':{'userid': '1', 'username': 'lqz','password':'123ee','test':'test'}}
# result = client.update(index='news', doc_type='_doc', body=data, id=1)
# print(result)
# 删除数据
# result = client.delete(index='news',id=1)
# 查询
# 查找所有文档
# query = {'query': {'match_all': {}}}
# 查找名字叫做jack的所有文档
# query = {'query': {'term': {'username': 'lqz'}}}
# 查找年龄大于11的所有文档
query = {'query': {'range': {'age': {'gt': 28}}}}
allDoc = client.search(index='lqz', body=query)
# print(allDoc['hits']['hits'][0]['_source'])
print(allDoc)
# python操作es的包---》类似于django的orm包
# 用的最多的是查询
# 写个脚本,把课程表的数据,同步到es中(建立索引---》插入数据)
# High level Python client for Elasticsearch
# //github.com/elastic/elasticsearch-dsl-py
from datetime import datetime
from elasticsearch_dsl import Document, Date, Nested, Boolean,analyzer, InnerDoc, Completion, Keyword, Text,Integer
from elasticsearch_dsl.connections import connections
connections.create_connection(hosts=["localhost"])
class Article(Document):
title = Text(fields={'title': Keyword()})
author = Text()
class Index:
name = 'myindex' # 索引名
if __name__ == '__main__':
# Article.init() # 创建映射
# 保存数据
# article = Article()
# article.title = "测试测试"
# article.author = "刘清政"
# article.save() # 数据就保存了
# 查询数据
# s=Article.search()
# s = s.filter('match', title="测试")
# results = s.execute()
# print(results)
# 删除数据
# s = Article.search()
# s = s.filter('match', title="测试").delete()
# 修改数据
s = Article().search()
s = s.filter('match', title="测试")
results = s.execute()
print(results[0])
results[0].title="xxx"
results[0].save()
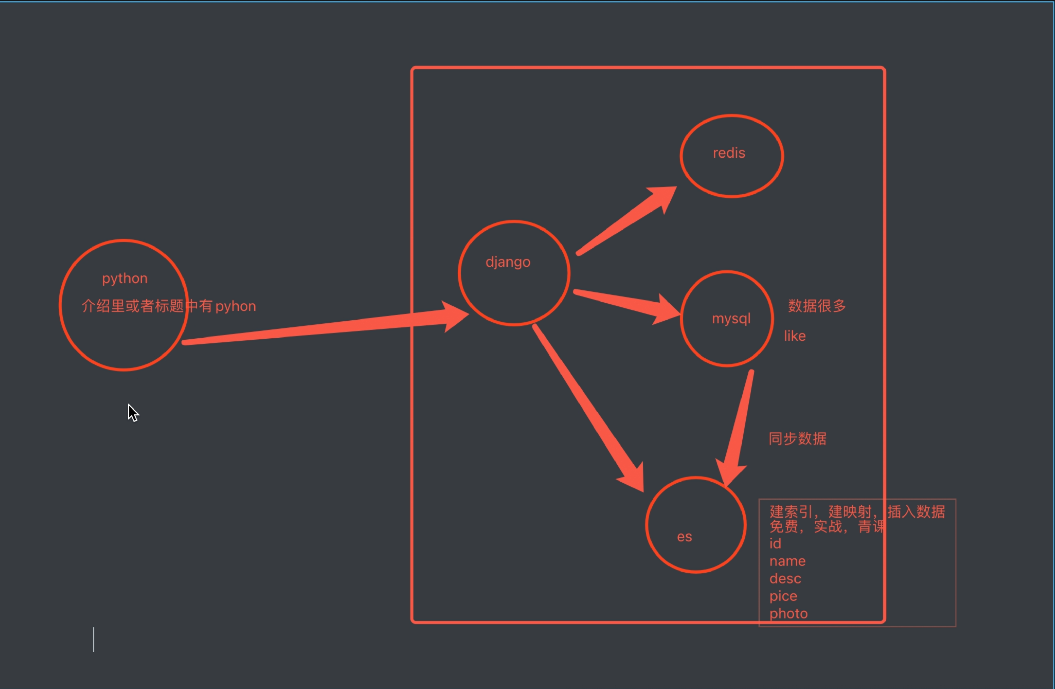
# es数据和mysql数据同步
-方案一:第三方同步脚本,实时同步mysql和es数据,软件运行,配置一下就可以了,后台一直运行
-//github.com/go-mysql-org/go-mysql-elasticsearch
-编译成可执行文件,启动就行----》linux上编译,go sdk---》跨平台编译
-方案二:(简历里说---》es和mysql的同步工具)
-自己用python写---》三个表,pymysql---》es中---》后台一直运行
-三个表,删除数据呢?公司里的数据都不删,都是软删除
-三个表增加---》记录每个表同步到的位置id号---》
-pymysql es
-免费课表(id,name,price),实战课表(id,name,price,teacher)
id_1=0
id_2=0
pymyql打开免费课,查询id如果大于id_1,把大于id_1的取出来组装成字典,存入es
pymyql打开实战课,查询id如果大于id_2,把大于id_2的取出来,存入es
-同步到es中---》es中只存id,name,price
-方案三:使用celery,只要mysql相应的表里插入一条数据,就使用celery的异步,把这条记录插入到es中去
-方案四:信号---》监控到哪个表发生了变化---》只要xx表发生变化,就插入es


