初学者系列:Attentional Factorization Machines(AFM)详解
- 2019 年 10 月 4 日
- 筆記
导读
本文通过学习论文《Attentional Factorization Machines: Learning the Weight of Feature Interactions via Attention Networks》介绍一种可以区分特征交互的重要性的模型——Attentional Factorization Machines(AFM)。下文主要分为两个部分来讲解,包括AFM原理以及源码解析。
论文地址:
http://staff.ustc.edu.cn/~hexn/papers/ijcai17-afm.pdf
No.0
核心思想
因子分解机(FM)是一种监督学习方法,通过结合二阶特征交互来增强线性回归模型,通过学习每个特征的嵌入向量(embedding vector),FM可以估计任何交叉特征的权重。但是FM缺乏区分特征交互重要性的能力(并非所有特征都包含用于估计目标的有用的)。
注意力因子分解机AFM是对FM的改进,解决了FM对于所有的特征权重都是一样的,不能区分特征交互重要性的问题。注意因子分解机(AFM)通过神经注意网络(neural attention network)从数据中自动地学习每个特征交互的重要性,从而实现特征交互对预测的贡献不同。
No.1
AFM
下图为AFM的框架(省略了线性回归部分),主要由输入层、嵌入层、成对交互层( pair-wise interaction layer)与基于注意力的池化层。其中输入层与嵌入层与FM是一致的,都是将输入特征的稀疏表示的非零特征嵌入到密集矢量中。下面主要介绍成对交互层( pair-wise interaction layer)和基于注意力的池化层。

Pair-wise Interaction 层
成对交互层是将FM中的二阶交叉特征使用神经网络层来实现,FM中的交叉项计算为:

成对交互层是将m个向量扩展为 m(m – 1)/ 2个相互作用(interacted vector)的向量。成对交互层的输出可以表示为一组向量:

其中:
- R_x = { (i,j) } i ∈ X, j ∈ X, j>i
- 嵌入层的输出为E = { vixi } i∈X
- X为x中的非零特征集合
若在交互层后使用全连接层进行预测,则得到的预测得分为:

其中:
- p∈R_k和b∈R分别表示预测层的权重和偏差。
- 在p=1,b=0时,变为FM
pair-wise interaction layer与NFM中的BI-Interaction层的操作是相似的的,都是实现FM 中的二阶特征交互。
Attention-based PoolingLayer
为了解决FM不能区分特征交互重要性的问题,论文中在二阶交互特征计算完成后加入了注意力网络(Attention Net),使用多层感知器(MLP)参数化注意力得分。注意力网络的输入是两个特征的交互向量,经过注意力网络可以在将特征交互压缩到同一表示式时,不同的特征交互有不同的贡献。注意力网络定义为:

注意力得分需要通过softmax函数(一个元素的softmax值,就是该元素的指数与所有元素指数和的比值)归一化,结果如下:

其中:
- W∈ R_{t×k},b∈R_t,h∈R_t是模型参数,t表示注意网络的隐藏层大小(注意因子)
- a_{ij}是特征交互wij的注意力得分
在此,没有使用通过最小化预测损失来学习注意力得分(a_{ij}),是因为对于在训练数据中从未共同出现的特征,无法估计其交互的注意力得分。
因此,AFM模型的可以表示为:

学习
AFM可以应用于包括回归,分类和排名在内的各种预测任务。文中以回归任务为例,选择平方损失作为目标函数,使用梯度下降法(SGD)进行优化:

为了防止过拟合,文中使用了Dropout与L2正则化。
- dropout:仅在成对交互层上使用,随机丢弃成对交互层上的神经元。
- L2正则化:在注意力网络的权重矩阵W上加入。

No.2
代码详解
代码链接:
https://github.com/hexiangnan/attentional_factorization_machine
代码框架如下,主要包括数据处理(LoadData.py)与AFM模型构建(AFM.py)

环境
- Python 2.7
- Tensorflow 1.0.1
数据
源码中提供了 MovieLens 1 Million (ml-1m) 和 frappe两个数据集, 原始数据格式与LibFM工具包格式一致。原始数据形式如下(以MovieLens数据为例)

其中红色框内为标签,黄色框内为特征(包括用户id,项目id)。在经过LoadData.py(与NFM中的数据处理源码相同,请点击NFM查看)处理之后,得到训练数据集、验证数据集、测试数据集。经过处理后的数据示例如下:

训练
AFM模型的训练主要通过调用函数 train()实现,在函数 train()中主要包括加载数据、加载模型、训练这三部分,并且在训练结束后输出验证集中均方根误差(RMSE)最小的的epoch值。
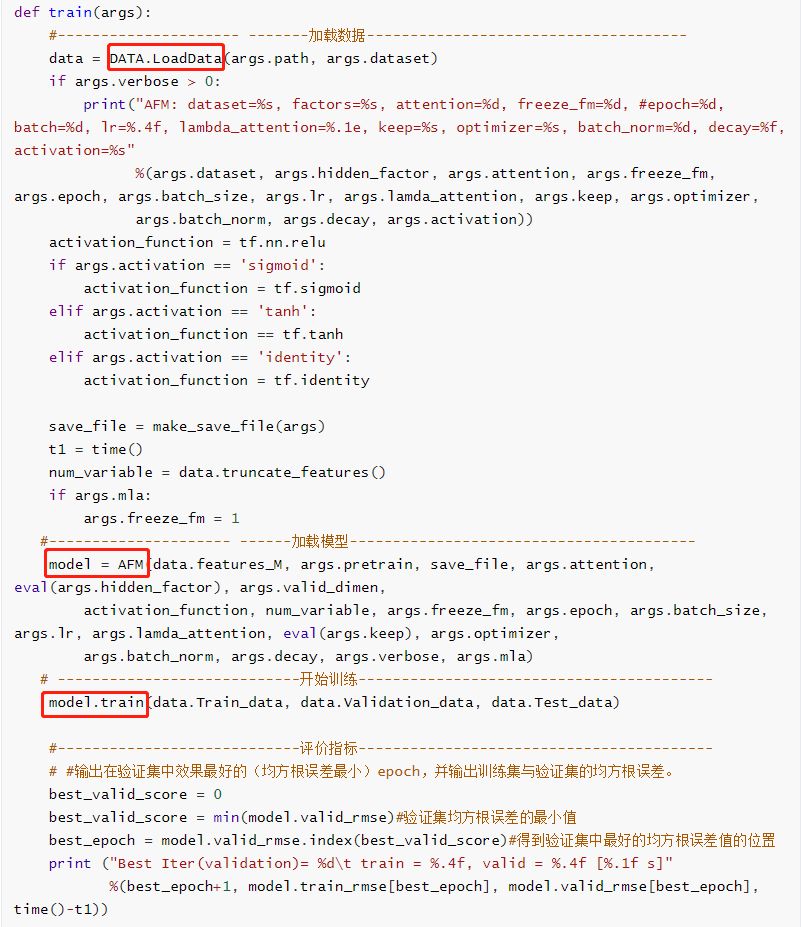
模型
AFM模型的实现主要通过AFM类中的 _init_graph函数。模型主要包括Embedding层、成对交互层( pair-wise interaction layer)、基于注意力的池化层、输出层这四部分。并且在 _init_graph()中定义了损失函数与优化器。
- Embedding层:跟之前的其它模型中Embedding层的实现是一样的,通过函数tf.nn.embedding_lookup()根据输入特征的索引号找到对应权重中的一行。

- 成对交互层:相当于FM中二阶交叉项特征交互的计算。

- 基于注意力的池化层:主要是通过注意力网络计算得到注意力得分 a_{ij},来学习每个特征交互的重要性。

- 输出层

训练
在加载完模型之后,训练部分主要是通过调用AFM类中的 train ()函数实现。在训练过程中除了计算损失之外,还输出了训练集以及验证集数据的预测值与真实值之间的均方根误差(RMSE)。

评价
评价函数evaluate主要是计算数据集中预测值与真实值之间的均方根误差。


测试
测试部分主要是通过调用函数evaluate()来实现,计算了测试集数据的均方根误差,并且进行了AFM与FM的对比,分别输出了两个模型的总输出,并计算了二者的差值。


-END-
