【论文阅读】ConvNeXt:A ConvNet for the 2020s 新时代卷积网络
- 2022 年 4 月 24 日
- 筆記
一、ConvNext Highlight
核心宗旨:基于ResNet-50的结构,参考Swin-Transformer的思想进行现代化改造,知道卷机模型超过trans-based方法的SOTA效果。
启发性结论:架构的优劣差异没有想象中的大,在同样的FLOPs下,不同的模型的性能是接近的。
意义:这篇文章可以作为很好的索引,将一些从卷积网络演进过程中的重要成果收录,适合新手。
二、背景介绍(Related Work)
2.1 一句话回顾ResNet-50
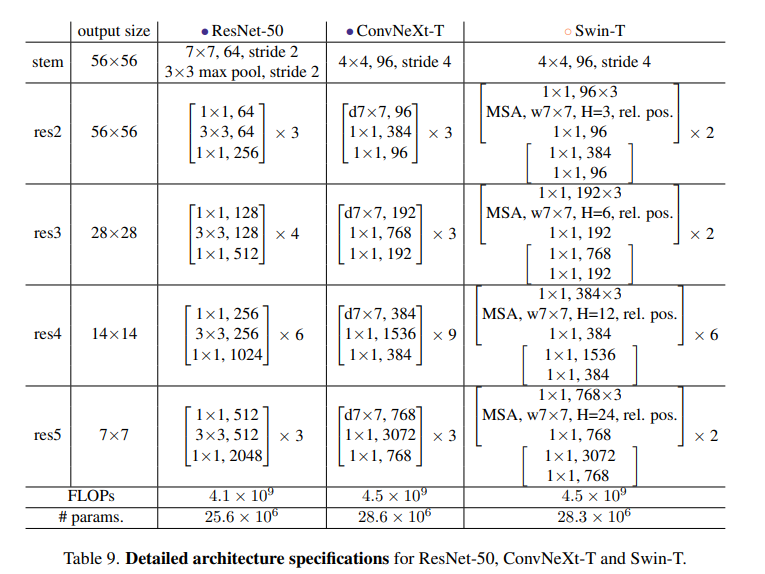
由48层卷积 + 1个maxpool + 1个 avgpool构成。1 个early downsampling的stem + 4个block,每个block的配比是3:4:6:3

2.2 Trans-based?为什么好?
- 为什么Transformer强:归纳偏置小,A Survey of Transformers
- CNN的先验:局部相关性、全局共享性
- RNN的先验:时间依赖
- Trans的先验:只有position、先验小、模型上线高 大数据下表现更好 -> 小数据下只能增加正则项 / 引入结构偏置
- 这么好,为啥前几年在NLP里用,CV领域从20年才开始用
- Trans模型的核心计算在自注意力机制,平方复杂度
- 在NLP领域把 字/词作为最小力度单元,在图像上使用像素作为最小力度单元? -> 复杂度高、单像素信息含量太小
2.3 Trans-based这么好 要怎么用到CV(ViT Swin-T)
- 一个Naive的想法:不把像素当做最小单元,把图像拆成若干小块(称作patch),把小块视作基本单元?
- 上面Naive的想法真的可行!把小patch串起来变成embedding-> ViT
- ViT的两个理解视角:
- DNN的视角:把图像切割img2patch,再把patch通过仿射变换 patch2embedding
- CNN的视角:先通过全图的二维卷积(stride = kenerl size),再flatten the feature map
- 更多细节:position embedding可学习, + classification head + 无trans decoder

- 不引入先验的确让模型理论上限更高了,但学习难度也加大了,而且 O(n2)的复杂度还是很难顶 -> Swin-Transformer
- Swin-T核心:采用层次化的设计,将复杂度从O(n^2)降到了O(n)、引入了CNN的局部性先验


三、Convnext又做了哪些事
3.1 超级详尽的实验 和 模型改造
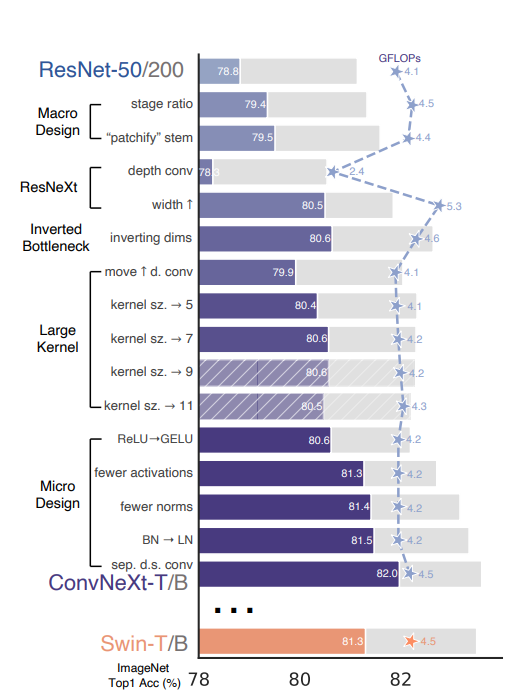
3.2 在实验之前,先在小数据集上获得好的优化器参数
- AdamW, 300epoch,预训练学习率4e-3,weight decay= 0.05,batchsize = 4096;微调学习率 5e-5, weight decay= 1e-8 ,batchsize = 512
- 准确率直接从76.1升到了78.8
3.3 宏观设计
- 修改区块占比:将[3,4,6,3]的区块比例改为了[3,3,9,3] -> 79.4
- RegNet和EfficientNetV2论文中都指出,后面的stages应该占用更多的计算量。
- patchy化:将底层的7*7卷积替换成了4*4 stride=4的卷积,相当于进行原图上的分块 ->79.5
- 深度可分离卷积:参考ResNext的结论,将普通卷积替换成深度可分离卷积(群卷积的一种),参数量降低可以让channel提高到96,达到与Swin-T相同。
- ResNext的指导性建议:use more groups, expand width

- inverted bottleneck:引入了mobilenetV2中的结构,并且探索了更好的setting -> 80.6

- 为了尝试不同的kernel size,调整了卷积的位置(这使得FLOPS降低、精度发生了降低),调整后的结构如figure3-(c)
- 这样调整之后可以实验不同kernel size。Swin-T的窗口是7*7,ConvNext也发现7*7最好


3.4 微观设计
- 更换激活:ReLU替换为GeLU(+0.1)
- 减少激活的数量(+0.7)、减少batchnorm(+0.1),整体设置与Swin-T相同
- 为了跟Swin-T一致,在block开始添加1*1卷积(无效)
- 更换归一化:用LayerNorm替换BatchNorm(+0.1)
- 更换下采样:下采样从 3*3 stride=2,代替为2*2 stride=2(可分离下采样)-> 训练不收敛
- 在stem之后,每个下采样层之前以及global avg pooling之后都增加一个LayerNom (+0.5)

3.4 最终的模型
四、实验结论
在 分类、检测、分割任务上效果都好,具体请移步论文原文看。
五、碎碎念
最近我们有一篇工作也是设计了一个全卷积的网络,也是用了深度可分离、inverted bottleneck、LN代替BN,但远远没有这篇论文做得细致。实验过程中遇到的难收敛问题或许是更值得探索的内容,可惜志不在此,希望学弟能够更细致得探索吧。


