【面试普通人VS高手系列】HashMap是怎么解决哈希冲突的?
- 2022 年 4 月 15 日
- 筆記
- JAVA, 面试, 面试普通人vs高手系列
常用数据结构基本上是面试必问的问题,比如HashMap、LinkList、ConcurrentHashMap等。
关于HashMap,有个学员私信了我一个面试题说: “HashMap是怎么解决哈希冲突的?”
关于这个问题,我们来模拟一下普通人和高手对于这个问题的回答。
普通人:
嗯…. HashMap我好久之前看过它的源码,我记得好像是通过链表来解决的!
高手:
嗯,这个问题我从四个方面来回答。
1.要了解Hash冲突,那首先我们要先了解Hash算法和Hash表。


(1)Hash算法,就是把任意长度的输入,通过散列算法,变成固定长度的输出,这个输出结果是散列值。
(2)Hash表又叫做“散列表”,它是通过key直接访问在内存存储位置的数据结构,在具体实现上,我们通过hash函数把key映射到表中的某个位置,来获取这个位置的数据,从而加快查找速度。
2.所谓hash冲突,是由于哈希算法被计算的数据是无限的,而计算后的结果范围有限,所以总会存在不同的数据经过计算后得到的值相同,这就是哈希冲突。
3.通常解决hash冲突的方法有4种。
(1)开放定址法,也称为线性探测法,就是从发生冲突的那个位置开始,按照一定的次序从hash表中找到一个空闲的位置,然后把发生冲突的元素存入到这个空闲位置中。ThreadLocal就用到了线性探测法来解决hash冲突的。
向这样一种情况
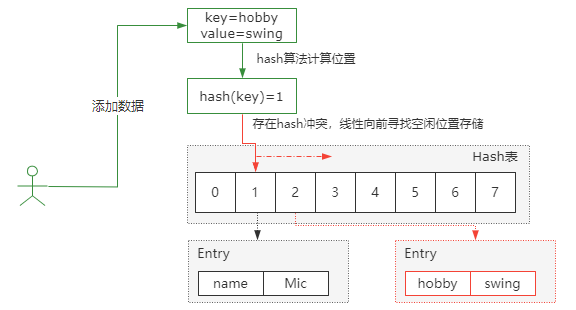
在hash表索引1的位置存了一个key=name,当再次添加key=hobby时,hash计算得到的索引也是1,这个就是hash冲突。而开放定址法,就是按顺序向前找到一个空闲的位置来存储冲突的key。
(2)链式寻址法,这是一种非常常见的方法,简单理解就是把存在hash冲突的key,以单向链表的方式来存储,比如HashMap就是采用链式寻址法来实现的。
向这样一种情况
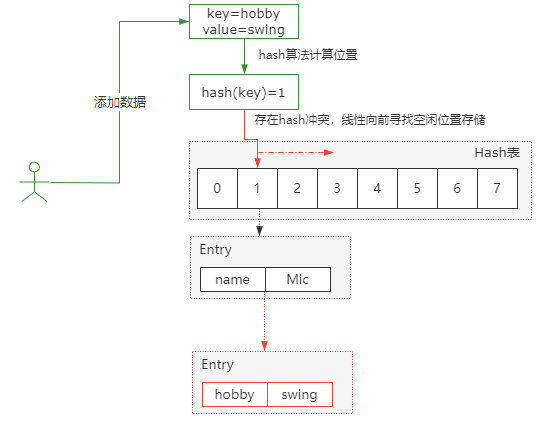
存在冲突的key直接以单向链表的方式进行存储。
(3)再hash法,就是当通过某个hash函数计算的key存在冲突时,再用另外一个hash函数对这个key做hash,一直运算直到不再产生冲突。这种方式会增加计算时间,性能影响较大。
(4)建立公共溢出区, 就是把hash表分为基本表和溢出表两个部分,凡事存在冲突的元素,一律放入到溢出表中。
4.HashMap在JDK1.8版本中,通过链式寻址法+红黑树的方式来解决hash冲突问题,其中红黑树是为了优化Hash表链表过长导致时间复杂度增加的问题。当链表长度大于8并且hash表的容量大于64的时候,再向链表中添加元素就会触发转化。
以上就是我对这个问题的理解!
总结
这道面试题主要考察Java基础,面向的范围是工作1到5年甚至5年以上。
因为集合类的对象在项目中使用频率较高,如果对集合理解不够深刻,容易在项目中制造隐藏的BUG。
所以,再强调一下,面试的时候,基础是很重要的考核项!!
本期的普通人VS高手面试系列的就到这里结束了,需要面试资料或者面试问题咨询欢迎私信和评论区留言。
我是Mic,一个工作了14年的Java程序员,咱们下期再见。


