【机器学习基础】无监督学习(1)——PCA
前面对半监督学习部分作了简单的介绍,这里开始了解有关无监督学习的部分,无监督学习内容稍微较多,本节主要介绍无监督学习中的PCA降维的基本原理和实现。
PCA
0.无监督学习简介
相较于有监督学习和半监督学习,无监督学习就是从没有标签的数据中进行知识发现的过程。
更具体地说,无监督学习可以分成两个方面,一:称之为化繁为简,二称之为无中生有。
所谓化繁为简,就是将比较复杂的数据进行“简单化”,此时将数据作为输入,输出则是从数据中所发现更为“简单”的内容,如下图所示:
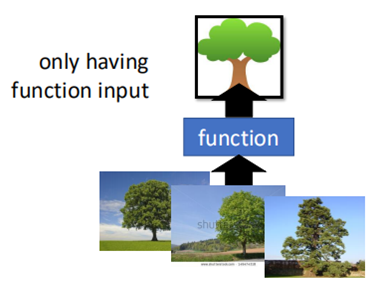
图片数据中各种各样的树,经过function后,被“概括”为统一的“树”表示,此时就是一个化繁为简的过程。
而所谓无中生有,则是与上面的过程相反,给定一个“简单”的输入,将输出复杂的数据(这个复杂的数据就是原数据)的过程,如图所示:
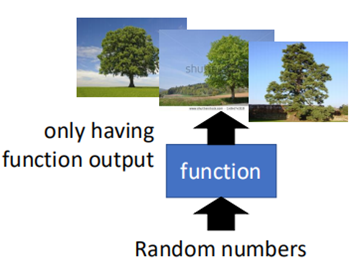
假设这个“简单”的数字,经过function之后,则生成一系列的图片的过程,这个过程称之为无中生有。
上面两个方面,原数据均是没有标签的,不同的是一个是将数据作为“输入”,一个是将数据作为“输出”(这里输入输出是相对的,在训练中其实都是输入),
这个找出function的过程就是无监督学习的过程,这些经过function之后(之前)的简单的数据,就是从数据中所发现的知识。
在理解了化繁为简之后,那么就可以轻易想到常见的无监督学习中,聚类、降维就属于这一类。
而无中生有中,则包括了一些深度自编码(AutoEncoder)和深度生成模型。
下面我们对上面的内容一一进行介绍,前面已经对聚类进行过总结,本节主要是降维算法中最著名的PCA。
1.降维的简单介绍
降维是机器学习中一种常见的方法,说到降维,其原理大概可以用下图描述:

一个高维的数据,经过function之后,变成一个低维的数据,而这个低维的数据仍能保留原数据的信息。那么为什么数据要进行降维呢?先看两组图片:
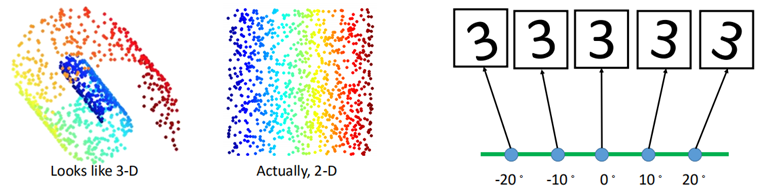
图1中,一个3D的图经过降维转化为2D之后,变得更容易分类;
而图2中,假设原数据全是不同角度的“3”,那么在进行这组数据时,我们不必再用28*28表示每一条数据,只需要用一个角度来描述每一条数据即可。
因此,我们希望找到这样一个function使得高维数据降到低维数据后还能保持原来数据的信息。
可以说,降维就是将数据从一个高维坐标系降到一个新的低维的坐标系的过程(不属于同一坐标系),而在新的坐标系中,这些数据也能够用来描述原数据。
除了找出function之外,降维还有一种简单的方法,就是直接选择特征,如下图:
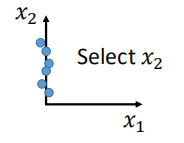
如上图所示,假设二维数据像上面那样子的分布情况,则在图中可以看到,只有在x2维有关,因此此时可以直接选择x2维作为降维后的数据。
但是当数据维度过大,且维度之间无法直接观察出来时,就无法直接进行特征的选择。
下面介绍另一种降维方法,也是本节的主要内容PCA。
2.PCA基本原理
2.1 PCA基本原理的一般描述
前面说到要找一个function对数据进行降维,并且降维后的数据还能保存原来的信息。假设变换前的数据为X,变换后的数据为Z,并且假设这个function是线性的,那么:
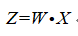
Z表示降维后的数据,X表示降维前的数据,高维数据通过线性变换之后得到低维数据。
PCA的任务就是找到一个W,对原数据进行降维,并尽可能保留更多的信息。那么这个W是如何找到呢?
现在首先假设原数据X为二维的,我们希望降维后数据Z降到一维,原数据如下图:
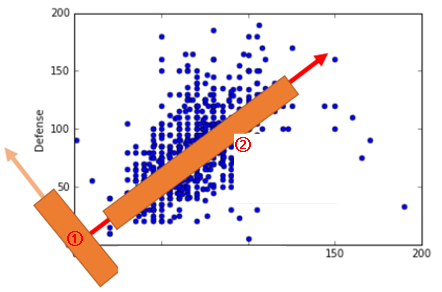
图中蓝色的点是原数据,现在我们想要找到一个新的坐标系,将数据降到一维,也就是说,找一个一维的坐标系,把这些数据放到新的坐标系中,有尽可能保留原数据中的信息。
假设任意两个一维坐标系①和②,分别将原来的数据投影到①和②上,那么投影到上面之后,究竟①和②哪一个能够更好地描述原来的数据信息呢?
显然②对于原数据的信息保留的更多,因为当把这么数据投影到①上之后,会有更多的数据会发生重合,导致数据的辨识度不高。
当原数据投影到②上之后,数据显得更加散开,而在①上则更集中。
那么,到这里我们用来描述好坏的指标变成了“散乱”还是“集中”,也就是方差Variance。
好了,总结一下,现在我们想要找一个W,对X进行降维,使得降维之后的数据Z的方差越大越好。接下来就是如何求解这个问题了:
假设降维降到一维(注意这里X并一定是2维,因为上面为了更好地说明问题和画图,假设X是二维),一条数据x降维后变成一个值(因为是1维)z1:
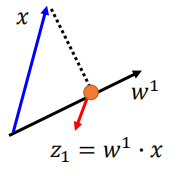
也就是说x在新的坐标系的坐标轴w1(注意这里的表述,)上的投影就是z1,那么降维后Z的方差表示为:
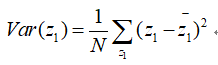
如果要把数据降维到二维(这时X就是大于2维的数据),那么也就是我们需要在找一个坐标轴w2,还要把原来的数据同时降到w2这条轴上(这里我的理解是,想象成把原数据分别全都降到一维),那么也就有:
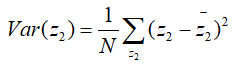
但是这里我们说过,w1和w2是同属于同一坐标系,因此还得保证两个轴是相互垂直的,即:
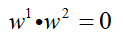
同时还要保证每一个坐标轴的长度为1,即:
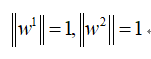
同理,如果要是降维到三维,四维…则就可以把w串成一个“向量”的形式:
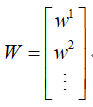
因此,只要我们找到了这个W,那么就可以对数据进行降维了。接下来就是如何求出每一个小w了。
首先看w1,w1的方差上面已经给出了:
现在我们的目的是要最大化这个式子,并且有|w1|=1的约束条件,即:
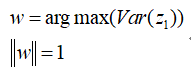
接下来就是数学运算过程:
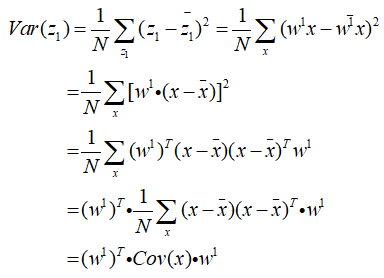
这里Cov(x)为x的协方差,令其为S,那么为题就变为:
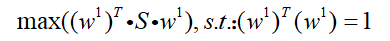
这个问题用拉格朗日乘子进行求解,令g(x):
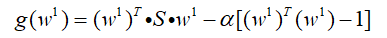
为了求解w1,这里要对w1的每一个元素进行求导并令其为0:
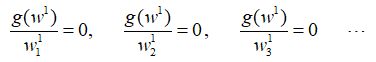
最终再合并,得到:
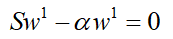
也就是:
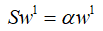
这里S是一个矩阵,w1是一个向量,α是一个值,那么根据线性代数内容,w1是S的一个特征向量。
对上式再同时左乘一个(w1)T,得到:
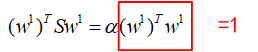
因此要是其最大,需要找到最大的那个特征值。
综上w1就是矩阵S最大的特征值α所对应的特征向量。
然后再看w2,同理对w2进行同样的处理,可以得到求解w2所需要的原问题:
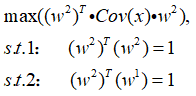
这里和上边求w1是一样的,不过多了w1*w2=0的约束条件,同样的方法,利用拉格朗日进行求解:
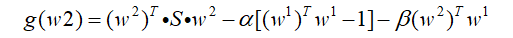
然后分别对w2中的每一个元素进行求导并令其为0:
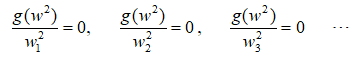
得到:
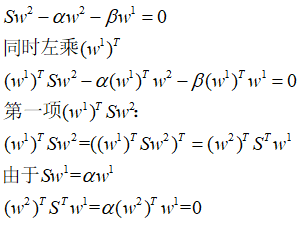
于是:
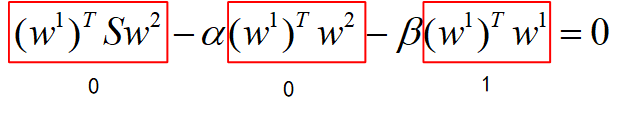
得到β=0,带回第一个式子:
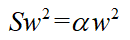
同寻找w1一样,这里要想使得最大,需要找到最大的特征值α,但由于w1已经占了最大一个特征值,那么此时α为第二大的特征。
因此,w2为矩阵S的第二大特征值α所对应的特征向量。
以此类推,如果找w3则就是S第三大特征值所对应的特征向量,如果降到n维,则W就是矩阵S前n大特征值所对应的特征向量所组成的一个矩阵。
上面就是求解W的过程,找到了W就可以对数据进行降维了,降维后的数据Z:
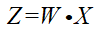
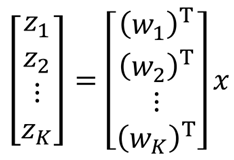
那么Z的协方差矩阵Cov(Z)则是一个对角矩阵。即降维后的数据的每一个维度将会是线性无关的。
证明如下:
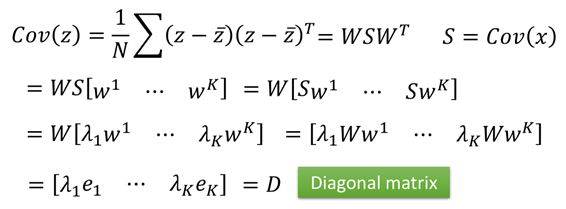
2.2 另一个角度看待PCA
上面是PCA的原理的一般说明,也是通常很多资料所描述的原理,为了弄清PCA究竟是在做什么,下面从另一个角度来看PCA。
首先,假设一个元素x是由一些基本的“零件”构成的,类似汉字的写法等,假设在数字识别时,每一个数字是由多个笔画所组成的,如下图:

先忽略右上角的0和1数字,我们假设手写数字识别的基本元素为u1、u2、u3…,可以看到每一个组成部分是一个简单的笔画,称之为basic component。
那么一个手写数字我们可以认为是由这些笔画组合而成的,比如说:
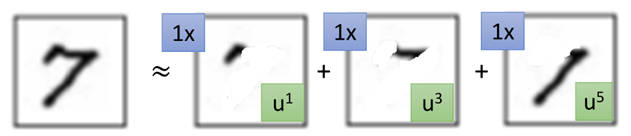
“7”这个数据可以看成是由u1、u3、u5构成的,那么“7”我们用向量表示为:[1, 0, 1, 0, 1….]
原本“7”的表示维度为28*28维的,也就是说现在我们只需要找到这些component就可以用更低维度的数据来表示“7”这个数字了。那么,这个过程就称为降维。
而上述的basic component即为上一节中的W,降维后的数据Z就是我们用这些component所表示成的向量。
那么上面的过程,一般性地,我们描述成如下这样:
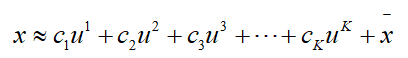
其中u表示basic component,c表示用basic component所组成的数据,即降维后的数据,x平均表示去中心化。
移项一下,得到:
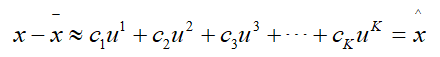
于是,这里问题就是我们想要找到一组{u1,u2,u3……}来对x进行变换,把原来的式子每一个元素都表示出来:
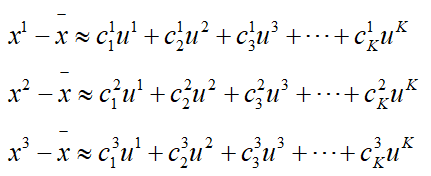
上标数字表示数量,下标表示维度。x1(上标)表示第一个样本,c11(上标1,小标1)表示样本x1对应u1上的那一个值。那么上面的式子,写成矩阵的形式:
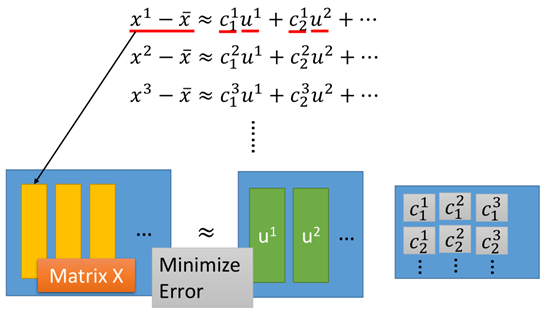
每个矩阵对应的维度为:
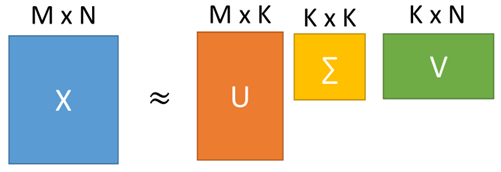
因此,上面的U、Σ、V即是U和C的解,这也是PCA的一般解法,即奇异值分解。由此可以得到{u1、u2、u3…}就是Cov(X)的前K个特征向量。
上面根据奇异值分解已经求出了W,那么可以求c,c就是降维后的数据,对于每一笔数据,我们希望它进行降维后与原来的越接近越好:

其实PCA可以看成是一个神经网络,假设K=2,降维前数据有3维,降到2维,那么可以表示成下面这样子:
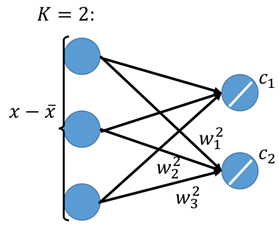
如果,现在我们想要通过c1、c2再解回x(hat),也就是:
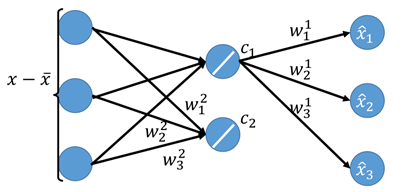
从上边来看,整件事情我们可以把它当做一个神经网络来看,上面的式子则称之为reconstruction error。也就是使这个损失越小越好。用数学的方式描述上面的问题:
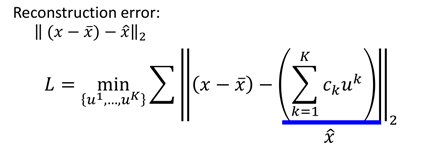
这里通过最小化L利用梯度下降进行训练和求解:
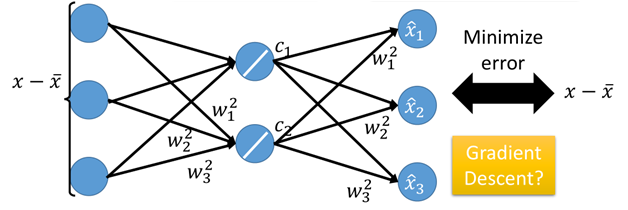
这个其实就是AutoEncoder的数据重构。通过损失函数最小化,可以一同训练参数W和c,当然中间也可以添加多个隐藏层,就成为了Deep AutoEncoder。
通过这种方式也可以实现PCA的全部降维过程,只是不同于PCA的是,利用NN所求解得到的w并不能保证是垂直的,即没有了约束条件w1*w2=0。因此得到的解与奇异值分解是不一样的。
小结:上面就是PCA的基本原理,从PCA的一般解法进行了与NN的联系的扩展理解,能够更好地理解PCA是在做什么事情,下面举个PCA的实例进一步说明。
3 PCA的实例
3.1 简单数据Pokémon实例
例子来源于李宏毅老师课程,假设现在有800个宝可梦数据集,每个数据有6个维度的特征,每一条数据代表一只宝可梦,那么现在对数据进行PCA降维。
首先这个6维的数据,我们要降到多少维合适呢?
一个方法就是计算协方差矩阵的6个特征值,然后分别计算每个特征值所占的比例,即主成分的贡献的程度大小:
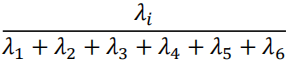
特征值的大小也就是主成分方差的大小,准确来说协方差的特征值也就是主成分的方差(这点是可以进行证明的),特征值越大说明主成分的贡献程度就越大。那么计算得到的6个特征值如下:

可以看到,当选择前四个特征值(已排序)已经占了大部分的比例,那么此时可以将数据降维到4维。
降维时所用的转换矩阵W如下(注意这里不是降维后的数据,而是四个特征值所对应的特征向量,也就是主成分,4个向量PC1、PC2、PC3、PC4,每个向量是6维):
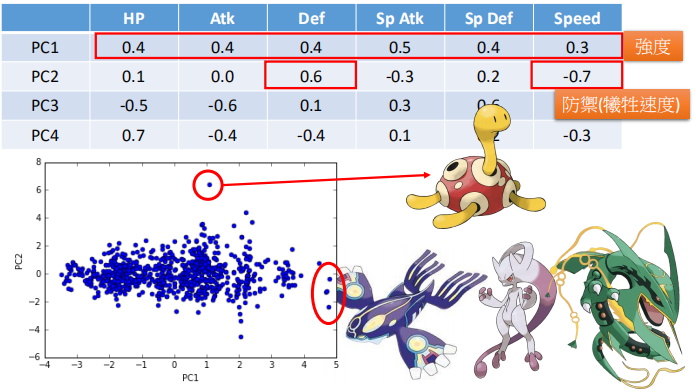
可以看到主成分PC1全是正值,可能代表的是表示战斗力,主成分PC2在speed上是负的,在防御上是正的,表示一种牺牲速度来换取防御的属性,以此类推。下面点云图是经降维后的数据,其中两个维度及其所代表的的宝可梦(其实我没怎么看过),比如最上边那个海龟,防御力很强,但是对应的速度就很慢。
从上面的例子可以看出,PCA可以从数据中抽取一些内在的无法直观看到的一些特征,用这些特征来重新表示数据,形成新的数据。
3.2 PCA在手写数字辨识上的实例
下面我们来看一下PCA在手写数字辨识上的例子,数据跟前面深度学习中的数据集一致,先读取一部分数据来看:
from sklearn.datasets import fetch_openml
import numpy as np
from PIL import Image
import matplotlib.pyplot as plt
import matplotlib as mpl
# 读取数据
data_x, data_y = fetch_openml('mnist_784', version=1, return_X_y=True)
# 画图的函数
def plot_digits(instances, image_per_row=10, **options):
size = 28
image_per_row = min(len(instances), image_per_row)
images = [instance.reshape(28, 28) for instance in instances]
n_rows = (len(instances) - 1)//image_per_row + 1
row_images = []
n_empty = n_rows * image_per_row - len(instances)
images.append(np.zeros((size, size * n_empty)))
for row in range(n_rows):
rimages = images[row*image_per_row:(row+1)*image_per_row]
row_images.append(np.concatenate(rimages, axis=1))
image = np.concatenate(row_images, axis=0)
plt.imshow(image, cmap=mpl.cm.binary, **options)
plt.axis("off")
data_x = np.array(data_x.values.tolist())
# 取前100个数字
example_images = []
for idx in range(100):
example_images.append(data_x[idx])
plot_digits(example_images, image_per_row=10)
上面是原数据的图片内容,下面开始写一个PCA的函数,这里主要为了理解PCA的步骤,实现以下PCA,并没有封装和规范化:
def pca(data, top_n_feature=9999):
"""
:param data: 原始数据
:param top_n_feature: 保留前n个特征
:return: 降维后的数据和变换矩阵w
"""
# 去中心化,减去每一列的均值
mean_vals = data.mean(axis=0)
mean_std = data - mean_vals
# 计算X的协方差矩阵
cov_x = np.cov(mean_std, rowvar=0)
# 计算特征值,及其对应的特征向量,返回的特征值有784个,特征向量784*784
eig_vals, eig_vectors = np.linalg.eig(np.mat(cov_x))
eig_vals = eig_vals.astype(float)
eig_vectors = eig_vectors.astype(float)
# 对特征值进行排序,返回索引
eig_vals_idx = np.argsort(eig_vals)
# 找出前n大特征值的索引
eig_vals_idx_max_n = eig_vals_idx[:-(top_n_feature + 1): -1]
# 找到前n大特征值对应的特征向量, 一个特征向量是1列,返回维度(784, top_n)
eig_vals_max_vec = eig_vectors[:, eig_vals_idx_max_n]
# 前n个特征向量为w,对高维数据进行降维z=wx, z = (100, 784) * (784, top_n)
new_data = mean_std * eig_vals_max_vec
# 数据的重构,根据前n个特征重构回原数据 (100, top_n) * (top_n, 784) + (784)
data_reconstruction = (new_data * eig_vals_max_vec.T) + mean_vals
return new_data, eig_vals_max_vec, data_reconstruction
data = data_x[:100, :]
new_data, eig_vals_max_vec, data_reconstruction = pca(data, 40)
# 重构后的数据,即降维后再原路返回的数据
plt.figure()
plot_digits(data_reconstruction, image_per_row=10)
# 主成分
plt.figure()
plot_digits(eig_vals_max_vec.T, image_per_row=10)

上面将数据降到40维,再将这40维数据 进行还原,可以看到,重构回的数字已经相当的清晰可辨识;
同时第2张图是主成分,也就是basic component,除了前两张勉强可以辨识出来笔画之外,后面几乎看不出来,这也是机器所提取出来的特征。
这里注意,前面说到一个图片可以看做是这些basic component的叠加组成的,但现在根据这些主成分似乎很难拼出一张图片,这主要是因为不仅仅是叠加,还有可能主成分之间相减。
如果单纯做笔画的识别,可以用非负矩阵分解NMF,还有一种方法叫Nonnegative PCA,即约束这些降维后的c值均为正值,文献参考//machinelearning.wustl.edu/mlpapers/paper_files/NIPS2006_415.pdf,这里暂时不多说了。而且这个NSPCA效果比一般PCA效果好。
当然对于Python而言,PCA有对应的工具包可以实现,sklearn中有可以调用的PCA工具,下面是利用sklearn进行PCA的代码,有关主要参数和说明已在注释中给出。
from sklearn import decomposition
model = decomposition.PCA(n_components=40)
"""
//scikit-learn.org/stable/modules/generated/sklearn.decomposition.PCA.html
参数:
n_components: 可以指定降维后的维度数目,此时为大于等于1的整数;
也可以是指定主成分的方差和所占的最小比例阈值,让PCA根据样本方差决定降维的维数,此时参数为(0, 1];
也可以指定参数为"mle",此时PCA会根据MLE算法根据方差特征的分布情况,自主选择一定的主成分数量;
当不输入任何时,即默认n_components=min(n_examples, n_features).
copy: bool,True或者False,缺省时默认为True。表示是否在运行算法时,将原始训练数据复制一份。
whiten: bool,True或者False, 是否对降维后的每一维特征进行归一化。
属性:
components_: 降维所用的转换矩阵W,即主轴方向
explained_variance_: 降维后各主成分的方差值,方差越大,越是主成分;
explained_variance_ratio_: 降维后的主成分的方差值占总方差的比例;
方法:
fit(X): 用X训练模型;
fit_transform(X): 用X训练模型,并在X上进行降维;
transform(X): 对X进行降维,前提要先fit;
inverse_transform: 将降维后的数据返回原来的空间;
"""
mew_data = model.fit_transform(data)
transform_matrix = model.components_4.PCA的局限性
PCA由于是无监督学习,无法完全保留样本的信息。比如说,下面一组数据:
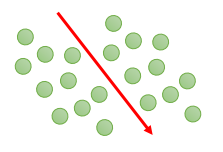
当采用PCA降维降到1维时,为红色的线,而加入这两边的数据分别属于两个不同的类别的话,那么同时投影到红色的线上时,则会产生混淆的情况,难以区分。
另外PCA是线性的,无法对空间的数据进行“拉直”,比如:

如果用在数字辨识上面,最终形成的结果由于其线性的原因,可能不会很好:
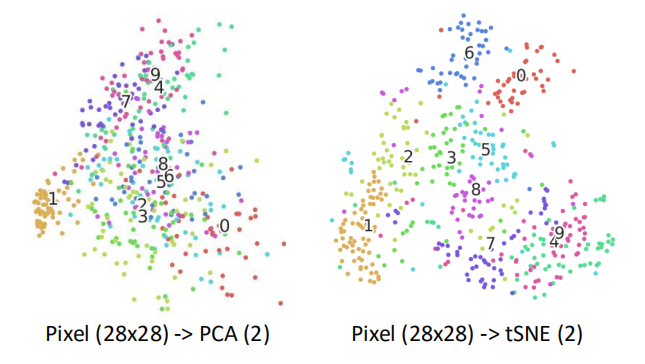
图1是利用PCA降维的结果,图2是一种非线性降维的方法(TSNE)这个后面会继续说这种方法。明显利用非线性降维的效果好于线性降维。
有关PCA的内容就先到这里了,后面继续对降维的方法进行总结,关于非线性的降维方法等。


