【计理05组01号】R 语言基础入门
- 2022 年 1 月 5 日
- 筆記
- 【计理05号】R语言
R 语言基本数据结构
首先让我们先进入 R 环境下:
sudo R
赋值
R 中可以用 = 或者 <- 来进行赋值 ,<- 的快捷键是 alt + - 。
> a <- c(2,5,8)
> a
[1] 2 5 8
筛选
我们可以用下标来筛选,例如:
> a[1:2]
[1] 2 5
注意 R 语言的下标是从 1 开始的。
当然我们也可以用逻辑进行筛选,例如:
> a[a>4]
[1] 5 8
为了了解这个式子的原理,我们先看看 a>4 是什么:
> a>4
[1] FALSE TRUE TRUE
我们可以看到这是一个布尔值构成的向量,我们在用这个布尔值做下标时只会选出答案为 TRUE 的值。
另外,负数下标表示不选这个这些下标,例如:
> a[-2]
[1] 2 8
合并向量
c() 可以合并向量,例如:
> c(a[1] , 3 , a[2:3] , 1)
[1] 2 3 5 8 1
循环补齐
向量有个比较有趣的性质,当两个向量进行操作时,如果长度不等,长度比较短的一个会复制自己直到自己和长的一样长。
> a <- c(3,4)
> b <- c(1,2,5,6)
> a+b
[1] 4 6 8 10
a 自动变成了 c(3,4,3,4) 然后与 b 相加,得到了这个结果。
矩阵
矩阵,从本质上来说就是多维的向量,我们来看一看我们如何新建一个矩阵。
> a <- matrix(c(1,2,3,4) , nrow = 2)
> a
[,1] [,2]
[1,] 1 3
[2,] 2 4
可以看到向量元素变为矩阵元素的方式是按列的,从第一列到第二列,如果我们想按行输入元素,那么需要加入 byrow = TRUE 的参数:
> a <- matrix(c(1,2,3,4) , nrow = 2 , byrow = TRUE)
> a
[,1] [,2]
[1,] 1 2
[2,] 3 4
筛选矩阵
与向量相似,我们可以用下标来筛选矩阵,例如:
> a[1:2,2]
[1] 2 4
可以看到结果退化成了一个向量。
线性代数
当我们对两个矩阵相乘,我们得到的结果是对应元素两两相乘的结果,例如:
> a * a
[,1] [,2]
[1,] 1 4
[2,] 9 16
而这不是我们想要的矩阵乘法,在 R 中我们在乘法旁边加两个百分号来做矩阵乘法:
> a%*%a
[,1] [,2]
[1,] 7 10
[2,] 15 22
此外,我们可以用 t() 来求矩阵的转置,用 solve() 来求矩阵的逆。
数据框
数据框类似矩阵,与矩阵不同的是,数据框可以有不同的数据类型。一般做数据分析,我们把一个类似 excel 的表格读入 R ,默认的格式就是数据框,可见数据框是一个非常重要的数据结构。一般来说我们需要分析的数据,每一行代表一个样本,每一列代表一个变量。
下面我们用 R 内置的数据集 iris 来看一看数据框的使用。
> data("iris")
> head(iris)
Sepal.Length Sepal.Width Petal.Length Petal.Width Species
1 5.1 3.5 1.4 0.2 setosa
2 4.9 3.0 1.4 0.2 setosa
3 4.7 3.2 1.3 0.2 setosa
4 4.6 3.1 1.5 0.2 setosa
5 5.0 3.6 1.4 0.2 setosa
6 5.4 3.9 1.7 0.4 setosa
我们用 data() 函数调入了 iris 这个数据集 , 然后用 head() 函数来看一看这个数据的前几行,可以看到有 sepal 的长度,宽度,petal 的长度和宽度,还有一个变量 Species 来描述样本的类别。
我们可以用 summary() 函数来对数据集做大致的了解:
> summary(iris)
Sepal.Length Sepal.Width Petal.Length Petal.Width Species
Min. :4.300 Min. :2.000 Min. :1.000 Min. :0.100 setosa :50
1st Qu.:5.100 1st Qu.:2.800 1st Qu.:1.600 1st Qu.:0.300 versicolor:50
Median :5.800 Median :3.000 Median :4.350 Median :1.300 virginica :50
Mean :5.843 Mean :3.057 Mean :3.758 Mean :1.199
3rd Qu.:6.400 3rd Qu.:3.300 3rd Qu.:5.100 3rd Qu.:1.800
Max. :7.900 Max. :4.400 Max. :6.900 Max. :2.500
可以直观地看到每个变量的信息,对于几个数值变量,我们可以看到最小值,中位数等等统计信息。而对于 Species 这个分类变量,我们看到的是计数信息。
筛选数据框与矩阵相似,都可以通过数字下标来获取子集,不同地是因为数据框有不同的列名,我们也可以通过列名来获取某一特定列,例如:
> iris$Species
[1] setosa setosa setosa setosa setosa setosa setosa setosa setosa setosa setosa setosa setosa setosa setosa setosa setosa setosa ...
我们可以用 names() 函数来获取数据框的列名,并可以通过为其赋值改变列的名字。
> names(iris)
[1] "Sepal.Length" "Sepal.Width" "Petal.Length" "Petal.Width" "Species"
列表
列表是一种递归式的向量,我们可以用列表来存储不同类型的数据,比如:
> l <- list(name="jiawen" , pigu_num=2 , is_handsome = TRUE)
> l
$name
[1] "jiawen"
$pigu_num
[1] 2
$is_handsome
[1] TRUE
列表有多种索引方式,可以用如下方式获取:
> l$name
[1] "jiawen"
> l[[2]]
[1] 2
> l[["is_handsome"]]
[1] TRUE
R 语言学习优秀资源
网络资源
DataCamp:一个提供云端 R 语言解释器的网站,提供了多门与数据科学有关的课程,可以借助此网站快速上手。
统计之都:国内质量最高的统计网站,有一些关于统计和 R 语言的优秀博客以及与 R 有关的会议通知。
肖凯博客:很有质感的博客,有大量 R 语言应用的案例。
数据科学相关书籍
-
R for data science:由 Hadley Wickham 合作编写的 2017 年出版的书籍 ,主要介绍的 tidyverse 生态 tidyverse 中包括了 dplyr(用于数据处理),ggplot(用于画图)等包,大幅增强了 R 语言的表现力,有免费的在线版本。
-
R 语言实战:一本从统计角度介绍 R 语言的书籍,较为简单,适合快速翻阅。
-
An Introduction to Statistical Learning:斯坦福统计系几位教授出版的统计学习书籍,对统计学习进行了清晰细致的讲解,书有开源版本,并且在 Stanford Lagunita 上有配套课程。
-
Machine Learning For Hackers : 使用机器学习解决问题的一本书,有很多有趣的案例 。
编程相关书籍
-
The Art of R Programming : 介绍 R 语言的编程,在数据结构,面向对象,性能等等话题上不乏深入的见解和精妙的案例。
-
Advanced R : Hadley Wickham 编写关于 R 语言高级编程的书籍,同样有免费的在线版本。
tidyverse 生态链概述
技术的进化衍生出新的生产工具,而新的生产工具改变我们的工作方式和认知结构。蒸汽机,计算机,互联网等等发明对社会造成了深远的影响。人们总是认为这些伟大发明的来源是 Eureka 式从天而降的,但我们去深入挖掘一下就可以知道,任何发明都不是凭空而来的,而是在先前的理论与技术的基础上,发现新的需求或者新的原理,组合它们创造出来的。
今天我们实验的对象就是一组从原始 R 进化出来的工具链 Tidyverse,它是由 Hadley Wickham 主导开发的一系列 R 包的集合。Tidyverse 继承了 R 语言进行快速统计分析的优势,并实现了一些新的理念,例如 magrittr 包中的管道操作,让线性嵌套的函数组合变得更加清晰易懂。可视化方面中的 ggplot 使绘图变成搭积木式的图层叠加。
这样的小发明有的改变了分析的运作方式,有的改变了使用者的认知方式,聚在一起形成了一种新的数据分析的生态链。具体来看,Tidyverse 有如下核心组件:
- readr:读取数据
- tidyr:整理数据
- dplyr:数据转换
- ggplot:可视化
- purrr:函数式编程
这些组件与一些其他工具配合,形成了一套完整的数据分析流程,如下图所示:
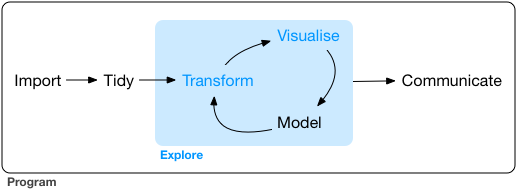
从图中可以看到,整个流程包括读取数据,整洁数据,数据探索和交流部分。经过前两部分,我们可以得到一个整理好的数据,它的每一行都是一个样本,每一列是一个变量。
然后我们就可以进入最核心的数据探索部分,数据探索包括数据转换,可视化,建模三部分。数据转换的内容包括构建新的变量,选出子集,对数据进行分组并获取统计量,进而可以通过可视化把变量或变量之间关系用图形表示出来。在对数据有大体上的认知后,可以尝试用精确的数学语言来对数据进行建模。模型的结果会给我们一些新的洞察和知识,驱动我们去提出新的问题,构成一个反馈循环。
数据探索完成后我们要把所做的工作借助文章清晰地表达出来,从而与其他人沟通。
分析汽车排放数据集
首先载入 tidyverse 包,并观察 mpg 数据的头部:
library(tidyverse)
mpg
## # A tibble: 234 × 11
## manufacturer model displ year cyl trans drv cty hwy
## <chr> <chr> <dbl> <int> <int> <chr> <chr> <int> <int>
## 1 audi a4 1.8 1999 4 auto(l5) f 18 29
## 2 audi a4 1.8 1999 4 manual(m5) f 21 29
## 3 audi a4 2.0 2008 4 manual(m6) f 20 31
## 4 audi a4 2.0 2008 4 auto(av) f 21 30
## 5 audi a4 2.8 1999 6 auto(l5) f 16 26
## 6 audi a4 2.8 1999 6 manual(m5) f 18 26
## 7 audi a4 3.1 2008 6 auto(av) f 18 27
## 8 audi a4 quattro 1.8 1999 4 manual(m5) 4 18 26
## 9 audi a4 quattro 1.8 1999 4 auto(l5) 4 16 25
## 10 audi a4 quattro 2.0 2008 4 manual(m6) 4 20 28
## # ... with 224 more rows, and 2 more variables: fl <chr>, class <chr>
mpg 数据集是刻画不同汽车的排放状况的一个数据集,总过有 234 个样本,11 个变量。这 11 个变量分别是:
- manufacture: 制造商
- model: 车型
- displ: 汽车排放量
- year: 制造年度
- cyl: 排气管数量
- trans: 排放类型
- drv: 驱动方式
- cty: 每公里耗油量(城市道路)
- hwy: 每公里耗油量(高速路)
- fl: 油的种类
- class: 车的类型
更多数据相关信息可以通过 help(mpg) 指令获取。
可视化:ggplot
先提出一个问题,汽车排放量和高速路上的每公里耗油量有什么关系?这两个变量都是数值变量可以先用散点图的形式将它们的关系展示出来:
ggplot(data = mpg) + geom_point(mapping = aes(x = displ, y = hwy))
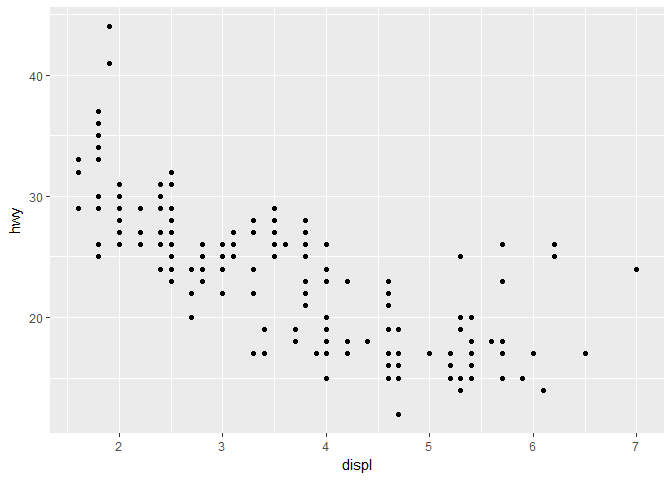
这是我们第一次接触 ggplot 的语法,这行代码虽然很短,却已经包含几个绘图的核心要素:
- 数据:ggplot 的数据集必须是一个数据框,这里我们的数据是 mpg。
- 图形属性映射:将数据变量映射到图形中,我们这里使用
aes(x = displ, y = hwy)把 x 坐标映射到排气量,y 坐标映射到每公里耗油量。 - 几何对象:geom 代表几何对象,比如我们这里想画散点图,就用
geom_point来生成散点图。
从这张图我们可以发现排气量与耗油成反向关系,排气量越大,耗油越少。它们的关系大致是线性的,但也有一些例外,比如左上和右上的一些点。很容易想到,耗油量不仅与排气量有关,还与车的类型有关,我们可以尝试把车型的信息加入到图中:
ggplot(data = mpg) + geom_point(mapping = aes(x = displ, y = hwy, color = class))
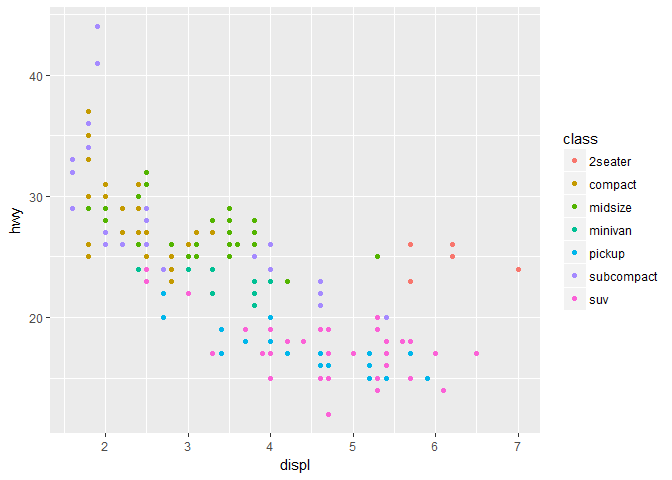
在属性映射中加入 color=class 参数后,我们可以看到每个点的汽车对应的类型被用不同颜色表现了出来,对于散点图还有 size(大小) , shape(形状)等等参数可以用于确定点的属性。
这样我们就成功地在一个二维的图形上展示了三个变量之间的关系,可以看到排气量较大但耗油量也大的大多属于 2seater (2 个座位的跑车)这一类型,类型与耗油确实有很大关系。
为了进一步地分析类型与耗油的关系,我们会想到把不同的类型的车的数据分离开来,而不是画在一张图上,我们可以使用 facet_wrap 把他们分离开来:
ggplot(data = mpg) +
geom_point(mapping = aes(x = displ, y = hwy)) +
facet_wrap(~ class)
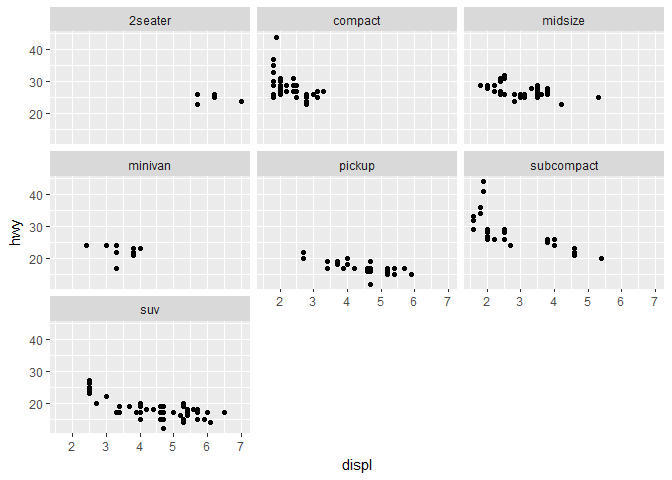
简单的一句话就将不同类型分离开来 , ggplot 的绘画能力真是令人惊叹。
现在我们回到最初的地方,分析排气量和耗油量的关系,来看一看不同的图层是如何叠加的。从原来的图上我们可以看到一种强烈的线性关系,能不能拟合一条曲线并把它画到图上呢?
ggplot(data = mpg) +
geom_point(mapping = aes(x = displ, y = hwy)) +
geom_smooth(mapping = aes(x = displ, y = hwy))
## `geom_smooth()` using method = 'loess'
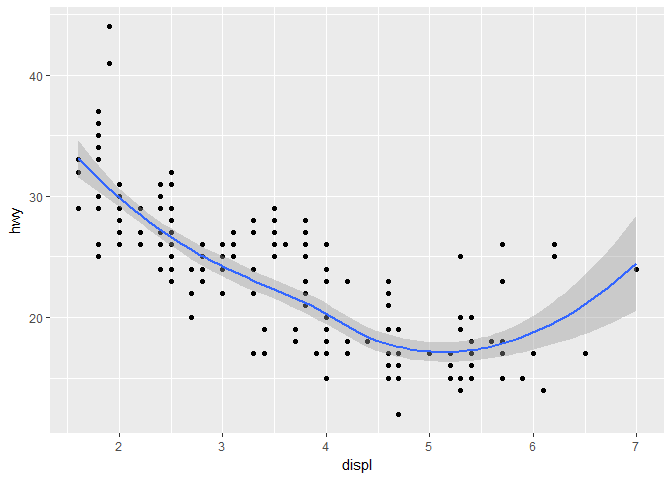
上面拟合所用的方法是 loess,翻译成中文就是近邻多项式回归,是一种非参数方法,所以由于几种跑车的存在,曲线右边翘了起来。曲线的阴影部分是置信区间的上下界。
如果我们想拟合普通的线性回归,我们可以改变 method 参数:
ggplot(mpg , aes(x = displ, y = hwy)) +
geom_point() +
geom_smooth(method = "lm")
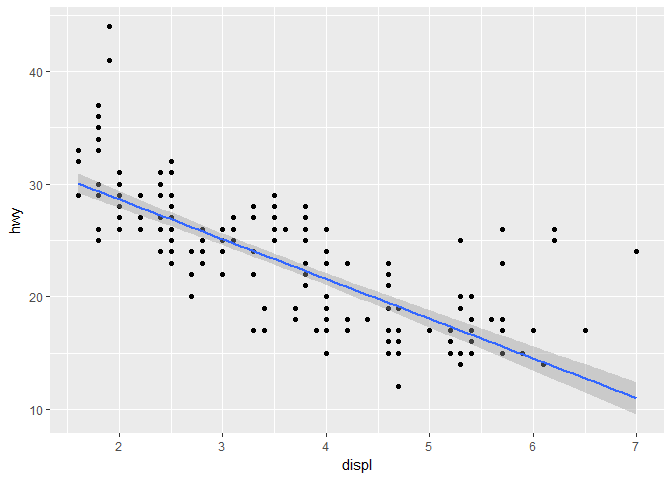
在这个语句中,我们把数据映射写到了第一个括号里,意思是后面的所有的几何对象都共享 这一映射,这样代码得到了简化。
通过上面的一系列的分析,我们基本掌握了 ggplot 的核心思想。如果想了解更多的几何对象,可以参考 ggplot 的 cheatsheet,如果要进一步了解 ggplot 背后的图层理论,可以参考书籍 ggplot2。
数据转换:dplyr
- 管道操作
在介绍 dplyr 前,首先应了解管道操作 %>% 的含义,管道由是由 Stefan Milton Bache 制作的 magrittr 包介绍的,主要作用在于简化多次线性操作。
例如我们有一个多层嵌套的操作:
func_3(func_2(func_1(data, arg1 = haha),arg2 = huhu), arg3 = hoho)
这样书写看起来一团糟,而且容易弄混,如果我们用管道操作,可以表达为:
data %>% func_1(arg1 = haha) %>% func_2(arg2 = huhu) %>% func_3(arg3 = hoho)
逻辑链条变得清晰易懂。
filter()
filter() 是一个用于筛选行的函数,例如我们想筛出排量大于等于 5,高速路每公里耗油小于 20 的车:
mpg %>% filter(displ >=5 , hwy < 20)
## # A tibble: 29 × 11
## manufacturer model displ year cyl trans drv
## <chr> <chr> <dbl> <int> <int> <chr> <chr>
## 1 chevrolet c1500 suburban 2wd 5.3 2008 8 auto(l4) r
## 2 chevrolet c1500 suburban 2wd 5.7 1999 8 auto(l4) r
## 3 chevrolet c1500 suburban 2wd 6.0 2008 8 auto(l4) r
## 4 chevrolet k1500 tahoe 4wd 5.3 2008 8 auto(l4) 4
## 5 chevrolet k1500 tahoe 4wd 5.3 2008 8 auto(l4) 4
## 6 chevrolet k1500 tahoe 4wd 5.7 1999 8 auto(l4) 4
## 7 chevrolet k1500 tahoe 4wd 6.5 1999 8 auto(l4) 4
## 8 dodge dakota pickup 4wd 5.2 1999 8 manual(m5) 4
## 9 dodge dakota pickup 4wd 5.2 1999 8 auto(l4) 4
## 10 dodge durango 4wd 5.2 1999 8 auto(l4) 4
## # ... with 19 more rows, and 4 more variables: cty <int>, hwy <int>,
## # fl <chr>, class <chr>
arrange()
arrange() 是一个用于排序的函数,例如我们得到了这些排量较大,耗油较小的车,想按照生产日期降序排列,耗油量升序排列。
mpg %>% filter(displ >=5 , hwy < 20) %>% arrange(desc(year) , hwy)
## # A tibble: 29 × 11
## manufacturer model displ year cyl trans drv cty
## <chr> <chr> <dbl> <int> <int> <chr> <chr> <int>
## 1 chevrolet k1500 tahoe 4wd 5.3 2008 8 auto(l4) 4 11
## 2 jeep grand cherokee 4wd 6.1 2008 8 auto(l5) 4 11
## 3 chevrolet c1500 suburban 2wd 5.3 2008 8 auto(l4) r 11
## 4 chevrolet c1500 suburban 2wd 6.0 2008 8 auto(l4) r 12
## 5 dodge ram 1500 pickup 4wd 5.7 2008 8 auto(l5) 4 13
## 6 ford f150 pickup 4wd 5.4 2008 8 auto(l4) 4 13
## 7 dodge durango 4wd 5.7 2008 8 auto(l5) 4 13
## 8 ford expedition 2wd 5.4 2008 8 auto(l6) r 12
## 9 jeep grand cherokee 4wd 5.7 2008 8 auto(l5) 4 13
## 10 lincoln navigator 2wd 5.4 2008 8 auto(l6) r 12
## # ... with 19 more rows, and 3 more variables: hwy <int>, fl <chr>,
## # class <chr>
select()
这 11 个变量太多,我们只关心车型,那么可以通过 select() 函数把这一个变量单独提出来:
mpg %>% filter(displ >=5 , hwy < 20) %>% arrange(desc(year) , hwy) %>% select(model)
## # A tibble: 29 × 1
## model
## <chr>
## 1 k1500 tahoe 4wd
## 2 grand cherokee 4wd
## 3 c1500 suburban 2wd
## 4 c1500 suburban 2wd
## 5 ram 1500 pickup 4wd
## 6 f150 pickup 4wd
## 7 durango 4wd
## 8 expedition 2wd
## 9 grand cherokee 4wd
## 10 navigator 2wd
## # ... with 19 more rows
mutate()
我们回到原来的 mpg 数据集,按照常识,排气管越多,排量越大,我们想生成一个新变量来看一看每根排气管的平均排气量是不是很接近。
mpg %>% mutate(ave_displ= displ / cyl) %>% select(ave_displ)
## # A tibble: 234 × 1
## ave_displ
## <dbl>
## 1 0.4500000
## 2 0.4500000
## 3 0.5000000
## 4 0.5000000
## 5 0.4666667
## 6 0.4666667
## 7 0.5166667
## 8 0.4500000
## 9 0.4500000
## 10 0.5000000
## # ... with 224 more rows
var(mpg %>% mutate(ave_displ= displ / cyl) %>% select(ave_displ))
## ave_displ
## ave_displ 0.007758093
可以发现我们的猜想大致正确, 多数车的平均排气量都在 0.5 到 0.7 之间,计算出来的方差也非常小。
group_by()
有的时候我们不想看单个样本,而是想按照某个标准把数据分成几组,再来分别看这些组的统计特征有什么差异,那么我们可以先用 group_by() 按照条件分组,再用 summarise() 算出每组组内的统计特征。
例如我们想看不同车型的平均排气量和平均耗油量:
mpg %>% group_by(class) %>% summarise(mean(displ) , mean(hwy))
## # A tibble: 7 × 3
## class mean(displ) mean(hwy)
## <chr> <dbl> <dbl>
## 1 2seater 6.160000 24.80000
## 2 compact 2.325532 28.29787
## 3 midsize 2.921951 27.29268
## 4 minivan 3.390909 22.36364
## 5 pickup 4.418182 16.87879
## 6 subcompact 2.660000 28.14286
## 7 suv 4.456452 18.12903
上面的几个函数是 dplyr 包的核心函数,如果要进一步了解 dplyr 的其他函数可以参考 dplyr 的 cheatsheet。
总结
今天的实验围绕 ggplot 和 dplyr 两个工具对 mpg 数据集进行了简单的分析,我们看到了 ggplot 强大的表现力以及 dplyr 链式表达的简洁,熟练掌握这两个工具使得分析中的可视化和数据转换变得轻松愉快。
tidyverse 中的其他工具大多上手容易或使用面较少,有兴趣的同学可以阅读 R for data science 做进一步地了解。

