Rank & Sort Loss for Object Detection and Instance Segmentation 论文解读(含核心源码详解)
- 2021 年 12 月 31 日
- 筆記
- CV, Deep Learning, Object Detection
♥ 第一印象
Rank & Sort Loss for Object Detection and Instance Segmentation 这篇文章算是我读的 detection 文章里面比较难理解的,原因可能在于:创新的点跟普通的也不太一样;文章里面比较多公式。但之前也有跟这方面的工作如 AP Loss、aLRPLoss 等。它们都是为了解决一个问题:单阶段目标检测器分类和回归在训练和预测不一致的问题。那么 Rank & Sort Loss 又在以上的工作进行了什么改进呢?又解决了什么问题呢?
关于训练预测不一致的问题
简单来说,就是在分类和回归在训练的时候是分开的训练,计算 loss 并进行反向优化。但是在预测的时候却是用分类分数排序来进行 nms 后处理。这里可能导致一种情况就是分类分数很高,但是回归不好(这个问题在 FCOS 中有阐述)。
之前的工作
常见的目标检测网络一般会使用 nms 作为后处理,这时我们常常希望所有正样本的得分排在负样本前面,另外我们还希望位置预测更准确的框最后被留下来。之前的 AP Loss 和 aLRP Loss 由于需要附加的 head 来进行分类精度和位置精度综合评价(其实就是为了消除分类和回归的不一致问题,如 FCOS 的 centerness、IoU head 之类的),确实在解决类别不均衡问题(正负样本不均衡)等有着不错的效果,但是需要更多的时间和数据增强来进行训练。
Rank & Sort Loss
Rank & Sort Loss (RS Loss) 并没有增加额外的辅助 head 来进行解决训练和预测不一致的问题,仅通过 RS Loss 进行简单训练:
- 通过 Sort Loss 加上 Quality Focal Loss 的启发(避免了增加额外的 head),使用 IoU 来作为分类 label,使得可以通过连续的数值 (IoU) 来作为标签给预测框中的正样本进行排序。
- 通过 Rank Loss 使得所有正样本都能排序在负样本之前,并且只选取了较高分数的负样本进行计算,在不使用启发式的采样情况下解决了正负样本不均衡的问题。
- 不需要进行多任务的权重或系数调整。
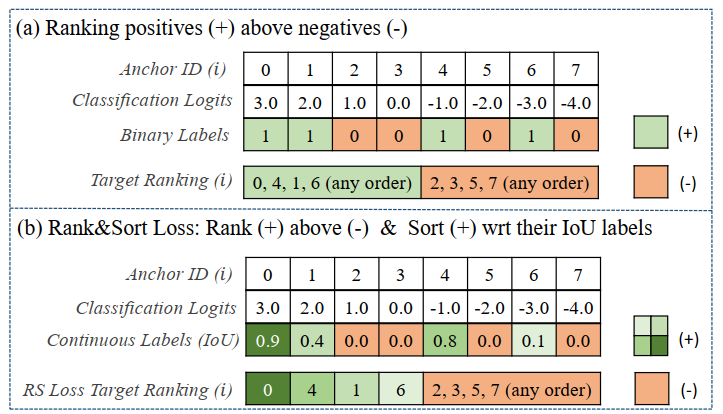
由上图可以看出,一般的标签分配正样本之间是没有区分的,但是在 RS Loss 里面正样本全部大于负样本,然后在正样本之间也会有排序,排序的依据就是 Anchor 经过调整后跟 GT 的 IoU 值。
♠ 对基于 rank 的 loss 的回顾
由于基于排序的特性,它不是连续可微。因此,常常采用了误差驱动的方式来进行反向传播。以下来复习一下如何将误差驱动优化融进反向传播:
-
Loss 的定义
\(\mathcal{L} = \frac{1}{Z} \underset{i \in \mathcal{P}}{\sum} \ell(i)\) ,其中 \(Z\) 是用来归一化的常数,\(\mathcal{P}\) 则是所有正样本的集合,\(\ell(i)\) 是计算正样本 \(i\) 的误差项。
-
Loss 的计算

-
Step 1. 如上图所示,误差 \(x_{ij}\) 的值为样本 \(i\) 与样本 \(j\) 的预测概率值之差。
-
Step 2. 用每一对样本的误差值 \(x_{ij}\) 来计算这对样本对样本 \(i\) 产生的 loss 值,由下述公式计算得到:
\[L_{ij} = \begin{cases}
\ell(i)p(j|i),\quad for\ i \ \in \mathcal{P},j \ \in \ \mathcal{N} \\
0,\qquad \qquad \ otherwise,
\end{cases}
\]其中 \(p(j|i)\) 是 \(\ell(i)\) 分布的概率
密度质量函数,\(\mathcal{N}\) 则是所选负样本的集合。一般借鉴了感知学习(感知机)来进行误差驱动,因此使用了阶跃函数 \(H(x)\) 。对于第 \(i\) 个样本,\(rank(i)=\underset{j \in \mathcal{P\cup N}}{\sum} H(x_{ij})\) 为该样本在所有样本的位次,\(rank^{+}(i)=\underset{j \in \mathcal{P}}{\sum} H(x_{ij})\) 为该样本在所有正样本中的位次,\(rank^{-}(i)=\underset{j \in \mathcal{N}}{\sum} H(x_{ij})\) 为该样本在较大概率分数负样本中的位次,这个位次真值应该为 0 ,否则将产生 loss (因为所有正样本需要排在所有负样本之前),对于 AP Loss 来说 \(\ell(i)\) 和 \(p(j|i)\) 可以分别表示为 \(\frac{rank^{-}(i)}{rank(i)}\) 和 \(\frac{H(x_{ij})}{rank^{-}(i)}\) 。其中可以推断出 \(L_{ij}=\frac{H(x_{ij})}{rank(i)}\) 即样本 \(j\) 对 \(i\) 产生的 loss,这里只会在其概率分数大于样本 \(i\) 时会产生 loss。 -
Step 3. 计算最终的 Loss,\(\mathcal{L}=\frac{1}{Z}\underset{i \in \mathcal{P}}{\sum} \ell(i)=\frac{1}{Z}\underset{i \in \mathcal{P}}{\sum} \underset{j \in \mathcal{N}}{\sum} L_{ij}\) 。
-
-
Loss 的优化
优化其实就是一个求梯度的过程,这里我们可以使用链式求导法则,然而 \(L_{ij}\) 是不可微的,因此其梯度可以使用 \(\Delta x_{ij}\) ,我们可以结合上图进行以下推导:
\[\begin{aligned}
\frac{\partial \mathcal{L}}{\partial s_i} &= \sum_{j} \frac{\partial \mathcal{L}}{\partial L_{ij}} \Delta x_{ij} \frac{\partial x_{ij}}{\partial s_i} + \sum_{j} \frac{\partial \mathcal{L}}{\partial L_{ji}} \Delta x_{ji} \frac{\partial x_{ji}}{\partial s_i}\\
& = -\frac{1}{Z}\sum_{j} \Delta x_{ji} + \frac{1}{Z}\sum_{j} \Delta x_{ij} \\
& = \frac{1}{Z} \Big( \sum_{j}\Delta x_{ji} – \sum_{j}\Delta x_{ij}\Big)
\end{aligned}
\]其中 \(\Delta x_{ij}\) 可以由 \(-(L^{*}_{ij} – L_{ij})\) 计算得到并进行误差驱动更新值,其中 \(L^{*}_{ij}\) 是 GT。AP Loss 和 aLRP Loss 都是通过这种方式进行优化的。
-
文章对以上的部分一些改进
RS Loss 认为:
-
\(L^{*}_{ij}\) 不为 0 时解释性比较差(因为 \(L\) 为排序误差产生的 loss,按理来说应该没有误差是最好的,也就是 loss 为 0,那么 GT 应该为 0 才对)
-
关于 \(L_{ij}\) 的计算来说,只有样本 \(i\) 为正样本,\(j\) 为负样本的时候才会产生非零值,其忽略了其他情况的一些误差。
因此对 Loss Function 进行了重定义为:
\[\mathcal{L}=\frac{1}{Z}\underset{i \in \mathcal{P \cup N}}{\sum} (\ell(i) – \ell^{*}(i))
\]其中 \(\ell^{*}(i)\) 是期望的误差,这里其实考虑了 \(i\) 属于正负样本的不同情况,另外直接使用与期望的误差之间差值作为 loss 的值,使得目标 loss 只能向着 0 优化,解决了上述两个问题。
关于 Loss 的计算则改为:
\[\mathcal{L}=\frac{1}{Z}\underset{i \in \mathcal{P \cup N}}{\sum} (\ell(i) – \ell^{*}(i))p(j|i)
\]最后的 Loss 的优化,由于我们的最终 loss 目标是 0,所以 \(\Delta x_{ij} = -(L^{*}_{ij} – L_{ij}) = L_{ij}\) ,最终优化可以简化为:
\[\frac{\partial \mathcal{L}}{\partial s_i} = \frac{1}{Z} \Big( \sum_{j}L_{ji} – \sum_{j}L_{ij} \Big)
\] -

♦ Rank & Sort Loss
Loss 的定义
\]
其中 \(\ell(i)_{RS}\) 是当前 rank error 和 sort error 的累积起来的和,其可以用下式表示
\]
前一项为 rank error,后一项为 sort error,后一项对分数大于 \(i\) 的样本乘以了一个 \(1-y\) 的权重,这里的 \(y\) 是分数标签(即该样本与 GT 的 IoU 值)。这里其实使得那些分数比样本 \(i\) 大,但是分数的标签又不是特别大(回归质量不是特别好)的样本进行了惩罚使其产生较大的 error。对于误差的标签,首先 rank error 我们希望所有正样本都排在负样本之前,而这时 rank error 为 0,而对于 sort error 我们则希望只有标签分数大于样本 \(i\) 的预测分数可以比它大,从而产生 error,此时产生期望的误差(也就是回归比 \(i\) 好的样本,我们是可以容忍分数比它高的),这部分样本由于有期望的误差,在计算 loss 时会产生更小的 loss。那些分数的标签不行,但预测分数又比较大的会产生更大的 loss:
\]
同时论文还将 \(H(x_{ij})\) 平滑进入区间 \([-\delta_{RS},\delta_{RS}]\) 中,其中 \(x_{ij} = x_{ij}/2\delta_{RS} + 0.5\) 。
Loss 的计算
关于 loss 的计算同上面也是进行三部曲,最后得到:
(\ell_{R}(i) – \ell_{R}^{*}(i))p_{R}(j|i),\quad for\ i \in \mathcal{P},j\ \in \mathcal{N} \\
(\ell_{S}(i) – \ell_{S}^{*}(i))p_{S}(j|i),\quad for\ i \in \mathcal{P},j\ \in \mathcal{P} \\
0, \quad \qquad \qquad \qquad \qquad \ ohterwise
\end{cases}
\]
其中
p_{R}(j|i)&=\frac{H(x_{ij})}{\underset{k \in \mathcal{N}}{\sum} H(x_{ik})} =\frac{H(x_{ij})}{rank^{-}(i)} \\
p_{S}(j|i)&=\frac{H(x_{ij})[y_j < y_i]}{\underset{k \in \mathcal{P}}{\sum} H(x_{ik})[y_k < y_i]}
\end{aligned}
\]
这里对于 rank 的概率质量函数只会统计分数大于 \(i\) 的样本,这里其实和之前没有什么区别;对于 sort 而言概率质量函数只会统计分数大于 \(i\) 且分数的标签小于 \(i\) 的样本。
以上的 loss 计算则变为:
\frac{rank^{-}(i)}{rank(i)}\frac{H(x_{ij})}{rank^{-}(i)},\quad \qquad \qquad \ \qquad \qquad \ \qquad \qquad \qquad \quad \ for\ i \in \mathcal{P},j\ \in \mathcal{N} \\
\Big(\frac{\underset{j \in \mathcal{P}}{\sum} H(x_{ij})(1 – y_j)}{rank^{+}(i)} – \frac{\underset{j \in \mathcal{P}}{\sum} H(x_{ij})[y_j\ge y_i](1 – y_j)}{H(x_{ij})[y_j\ge y_i]}\Big)\frac{H(x_{ij})[y_j < y_i]}{\underset{k \in \mathcal{P}}{\sum} H(x_{ik})[y_k < y_i]},\quad for\ i \in \mathcal{P},j\ \in \mathcal{P} \\
0, \qquad \qquad \qquad \qquad \qquad \qquad \qquad \qquad \qquad \qquad \qquad \ ohterwise
\end{cases}
\]
Loss 的优化
对于 \(i \in \mathcal{N}\) 时,
根据上式中的 \(L_{ij}\) 的计算规则,实际上我们只需要计算 rank 产生的 loss 就好,因为 sort 产生的 loss 只会在正样本之间计算,而 rank 产生的 loss 需要正样本对所有负样本的计算,因此只有 \(j\ \in \mathcal{P}, i \ \in \mathcal{N}\) 符合(注意这里的顺序噢,\(i,j\) 就不行噢):
\frac{\partial L_{RS}}{\partial s_i} &= \frac{1}{|\mathcal{P}|} \Big(-\underset{j \in \mathcal{P}}{\sum}L_{ij}+\underset{j \in \mathcal{P}}{\sum}L_{ji}-\underset{j \in \mathcal{N}}{\sum}L_{ij}+\underset{j \in \mathcal{N}}{\sum}L_{ji}\Big) \\
&= \frac{1}{|\mathcal{P}|}\underset{j \in \mathcal{P}}{\sum}\Big(\ell_{R}(i)-\ell^{*}_{R}(i)\Big)p_{R}(i|j) \\
&= \frac{1}{|\mathcal{P}|}\underset{j \in \mathcal{P}}{\sum}\ell_{R}(i)p_{R}(i|j)
\end{aligned}
\]
对于 \(i \in \mathcal{P}\) 时,
这时候只有 \(j\ \in \mathcal{N}, i \ \in \mathcal{P}\) 这种情况是不行的(因为这样就是计算每一个负样本与所有正样本的 loss 了):
\frac{\partial L_{RS}}{\partial s_i} &= \frac{1}{|\mathcal{P}|} \Big(-\underset{j \in \mathcal{P}}{\sum}L_{ij}+\underset{j \in \mathcal{P}}{\sum}L_{ji}-\underset{j \in \mathcal{N}}{\sum}L_{ij}+\underset{j \in \mathcal{N}}{\sum}L_{ji}\Big) \\
&= \frac{1}{|\mathcal{P}|}\Big(-\underset{j \in \mathcal{P}}{\sum}(\ell_{S}(i) – \ell_{S}^{*}(i))p_{S}(j|i)+\underset{j \in \mathcal{P}}{\sum}(\ell_{S}(j) – \ell_{S}^{*}(j))p_{S}(i|j)-\underset{j \in \mathcal{P}}{\sum}(\ell_{R}(i) – \ell_{R}^{*}(i))p_{R}(j|i)+0\Big) \\
&= \frac{1}{|\mathcal{P}|}\Big(-(\ell_{S}(i) – \ell_{S}^{*}(i))\underset{j \in \mathcal{P}}{\sum}p_{S}(j|i)+\underset{j \in \mathcal{P}}{\sum}(\ell_{S}(j) – \ell_{S}^{*}(j))p_{S}(i|j)-(\ell_{R}(i) – \ell_{R}^{*}(i))\underset{j \in \mathcal{P}}{\sum}p_{R}(j|i)+0\Big) \\
&=\frac{1}{|\mathcal{P}|}\Big(-(\ell_{S}(i) – \ell_{S}^{*}(i))+\underset{j \in \mathcal{P}}{\sum}(\ell_{S}(j) – \ell_{S}^{*}(j))p_{S}(i|j)-(\ell_{R}(i) – \ell_{R}^{*}(i))+0\Big) \\
&=\frac{1}{|\mathcal{P}|}\Big((\ell_{RS}^{*}(i) – \ell_{RS}(i))+\underset{j \in \mathcal{P}}{\sum} \big(\ell(i)_{S} – \ell_{S}^{*}(i)\big)p_{S}(i|j)\Big)
\end{aligned}
\]
需要记住的是,rank 中的 loss \(L_{kl}\) 其中必须满足 \(k \in \mathcal{P},l\ \in \mathcal{N}\) ,sort 中的 loss \(L_{kl}\) 其中必须满足 \(k \in \mathcal{P},l\ \in \mathcal{P}\) 其余情况均为 0,因此一对样本要么产生 rank loss(一正样本一负),要么产生 sort (两正)
关于多任务的权重,使用下述方法避免了人工设置权重:
\]
其中 \(\lambda_{box} = \left|\mathcal{L}_{RS}/\mathcal{L}_{box} \right|\)
算法的表现
RS Loss 解决训练预测不一致以及类别不均衡等问题,思路还是挺新颖的,而且具有较好的表现。
-
单阶段网络的性能

-
两阶段网络的性能
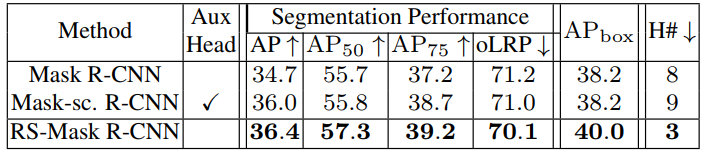


可以看到还是在下游任务上还是又不小的提升的,只得大家借鉴其思路,创新自己的工作。


