go实现pdf电子签名-自动识别签名位置
- 2021 年 12 月 24 日
- 筆記
一. 技术选型
由于要识别签名位置,所以得要能解析pdf的文本布局,要能得到每个布局元素的文本位置坐标。而最终的签名需要合成到pdf上,所以还需要有编辑pdf的需求。
pdf布局分析:pdfminer.six
github://github.com/pdfminer/pdfminer.six
官网://pdfminersix.readthedocs.io/en/latest
关于go的pdf解析库,大多都只是提取纯文本,解析不了布局。而能满足要求的 unidoc/unipdf 库,需要收费且费用昂贵。于是把目光投向了生态丰富的python,果不其然,找到了pdfminer.six , 一个专注于PDF内容解析的包。关于它的布局结构分析模式可以参考下图,详情参考 //pdfminersix.readthedocs.io/en/latest/topic/converting_pdf_to_text.html#topic-pdf-to-text-layout
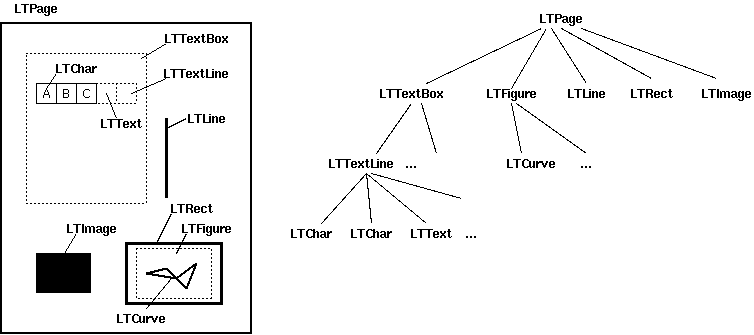
由于签名位置的元素一般都是与文本相关的,所以我们只用考虑LTPage的LTTextBox分支。
pdf编辑:pdfcpu
github://github.com/pdfcpu/pdfcpu
官网://pdfcpu.io/
一个强大的PDF 处理库,功能很全面,我们只需要用到 Stamp 功能
既然要识别签名位置,那么首先得让程序有一个判断依据,来确定某个位置是否需要签名。而文档签名位置的左方都会有 签名提示文本 ,它的格式通常为”XXX签字:“,所以可以用 签名提示文本 的格式作为判断依据。

由于签名提示文本普遍都是单行,所以在 pdfminer.six 解析的布局结构中,对所有的LTTextLine中的文本进行格式正则匹配,就能得到文档中所有的 签名提示文本 四个角的坐标点。而签名位置只需要知道左上角坐标即可(对应 签名提示文本 右上角坐标)。解析demo如下:
点击查看代码
from pdfminer.converter import PDFPageAggregator
from pdfminer.layout import LAParams, LTTextBoxHorizontal, LTTextLineHorizontal
from pdfminer.pdfinterp import PDFResourceManager, PDFPageInterpreter
from pdfminer.pdfparser import PDFParser
from pdfminer.pdfdocument import PDFDocument
from pdfminer.pdfpage import PDFPage
import re
match_text = ".+签字|名[::]$" # 签名提示文本格式
def pdfSearchSignLocation(pdfpath, passwd=""):
praser = PDFParser(open(pdfpath, 'rb'))
doc = PDFDocument(praser, passwd)
# 检测文档是否支持提取
if not doc.is_extractable:
print("non-supported")
return
# 创建资源管理器
rsrcmgr = PDFResourceManager()
# 创建页面聚合器
laparams = {} # 布局分析参数,具体参考//pdfminersix.readthedocs.io/en/latest/reference/composable.html#laparams
device = PDFPageAggregator(rsrcmgr, laparams=LAParams(**laparams))
# 生成页面解释对象
interpreter = PDFPageInterpreter(rsrcmgr, device)
cnt = 0
# 获取page内容列表
for page in PDFPage.create_pages(doc):
interpreter.process_page(page)
# 获取该页的LTPage对象
lt_page = device.get_result()
# 循环布局结构
for lt_tbox in lt_page:
if not isinstance(lt_tbox, LTTextBoxHorizontal):
continue
for line in lt_tbox._objs:
if not isinstance(line, LTTextLineHorizontal):
continue
# 获取行文本
line_text = line.get_text().strip()
# 匹配签名提示文本
result = re.search(match_text, line_text)
if result:
cnt += 1
print("签名{} 第{}页 左下点、右上点坐标:({line.x0},{line.y0})、({line.x1},{line.y1})".format(cnt, lt_page.pageid, line=line))
if __name__ == "__main__":
pdfSearchSignLocation("tt10.pdf")
三. pdf签名图片合成
使用 pdfcpu 的 Stamp add 命令(详情参考//pdfcpu.io/core/stamp):
pdfcpu stamp add -p 页数 -m image “签名图片路径” “详细配置” pdf文件输入路径 pdf文件输出路径
需要设置的详细配置有四个:
1. position(坐标原点位置)
应与 pdfminer.six 统一,为 “bl“(左下角)
2. rot(旋转角度)
本是不需要设置的,文档说明中默认也为0,但实际测试默认会逆时针旋转45度(pdfcpu可能认为你进行的是类似加水印的操作),所以主动设置为0即可
3. offset(坐标偏移)
即签名图片的定点坐标(当position位于左下角时,图片定点位于自身左下角),对应 签名提示文本 右下角
4. scalef(缩放比例)
一般来说,线下签字时,签字的文字大小与文档中不会相差太大,但线上签名时,我们通过用户书写的画布获取到的签名图片,与文档文字大小相差甚大,所以需要进行缩放处理。
-
-
- 缩放比例可以通过 文档文字大小 / 签名图片高度 得出
- 文档文字大小 可以通过 签名提示文本 布局的两个对角点坐标 的Y轴差值得出
- 签名图片高度 顾名思义,值得一提的是,最好将签名图片四周的空白区域剪裁掉
-
最终命令如下:
pdfcpu stamp add -p 页数 -m image “签名图片路径” “position:bl, rot:0, offset:偏移x 偏移y, scalef:缩放比例 abs” pdf文件输入路径 pdf文件输出路径
四. Demo演示
demo地址://175.24.203.88:9001/
首先需要上传一个pdf文本文件(或直接使用准备好的demo文件),上传完成后自动进入签名界面,左方是当前预览的pdf,右方是识别出来的需要签名信息的列表。点击签名信息可在跳转至对应签名处,点击签名按钮可以进行签名操作。签名提交后,左方预览会加载出合成签名后的pdf,可以点击下载按钮下载当前的预览的pdf文件。


至此,没有任何法律效应的电子签名功能完成 ٩(◕‿◕。)۶


