java nio 写一个完整的http服务器 使用Reactor模式 提升性能 支持文件上传 chunk传输 gzip 压缩 使用过程 和servlet差不多
- 2021 年 12 月 21 日
- 筆記
java nio 写一个完整的http服务器 支持文件上传 chunk传输 gzip 压缩
使用了Reactor模式 提升性能
也仿照着 netty处理了NIO的空轮询BUG
本项目并不复杂 代码不多 我没有采用过多的设计模式 和套娃 使其看着比较简单易懂
先附上gitHub 链接://github.com/pupansheng/pps-web
起因:
想自己写一个web服务器 不使用tomcat 有时候想轻量级一点 代码量很少
成果:
现在已经支持文件上传下载,分块传输协议 gzip压缩 使用过程和java Servlet差不多 我封装两个对象 一个HttpRequest 一个Response 可以仿照这servlet来对http做出响应与接收 后续有空 可能会对原生的Servlet做出支持。
图:下面是我给出的示例
首先这是我写的按照我的规则 写的一个普通servlet(不是javax 里面的那个 是我自己写的一个接口)

访问效果:
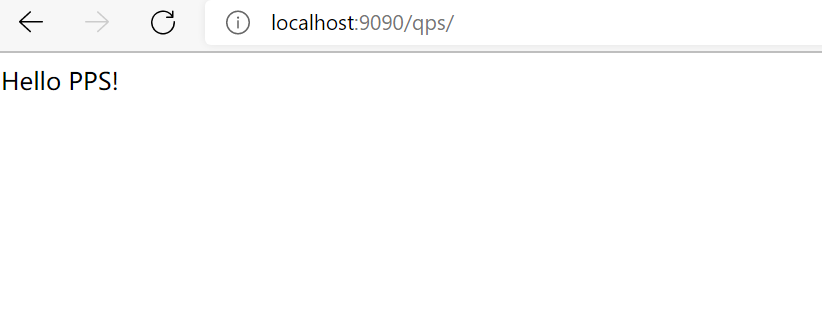
我也写了几个 默认的servlet
分别处理 404 500 和 icon 和静态资源请求
下面是 静态资源的servlet
import com.pps.web.constant.ContentTypeEnum; import com.pps.web.constant.PpsWebConstant; import com.pps.web.data.HttpRequest; import com.pps.web.data.Response; import com.pps.web.servlet.model.PpsHttpServlet; import java.io.File; import java.io.FileInputStream; import java.io.IOException; import java.util.HashMap; import java.util.Map; /** * 讲静态资源的默认处理 * @author Pu PanSheng, 2021/12/20 * @version OPRA v1.0 */ public class DefaultStaticResourceServlet extends PpsHttpServlet { private volatile Map<String, String> resource; public void scanFile(String root){ //检索资源目录 String context =(String) serverParams.get("context"); String mapUrl=(String) serverParams.get(PpsWebConstant.RESOUCE_MAPPING_DIR_KEY); String dir=(String) serverParams.get(PpsWebConstant.RESOUCE_DIR_KEY); File file=new File(root); if(file==null){ return; } for (File listFile : file.listFiles()) { if(listFile.isDirectory()){ scanFile(listFile.getPath()); }else if(listFile.isFile()){ String path = listFile.getPath(); String s = context + mapUrl; path=path.replace(dir,s); path=path.replace(File.separator,"/"); resource.put(path, listFile.getAbsolutePath()); } } } @Override public boolean isMatch(String url) { if(resource==null){ synchronized (this) { resource = new HashMap<>(); scanFile((String) serverParams.get(PpsWebConstant.RESOUCE_DIR_KEY)); } } return resource.containsKey(url); } @Override public void get(HttpRequest request, Response response) { String url = request.getUrl(); String u = resource.get(url); try { int i = url.lastIndexOf("."); String suffix = url.substring(i + 1); ContentTypeEnum contentTypeEnum=null; for (ContentTypeEnum value : ContentTypeEnum.values()) { String type = value.getType(); if(type.endsWith(suffix)||suffix.equals(value.getDesc())){ contentTypeEnum=value; break; } } //下载 if(contentTypeEnum==null){ contentTypeEnum=ContentTypeEnum.applicationstream; } response.setContentType(contentTypeEnum.getType()); try (FileInputStream fileInputStream = new FileInputStream(u)) { byte[] bu = new byte[1024]; int read = fileInputStream.read(bu); while (read != -1) { response.write(bu, 0, read); read = fileInputStream.read(bu); } response.flush(); } } catch (IOException e) { e.printStackTrace(); throw new RuntimeException("静态资源映射过程出错"); } } }
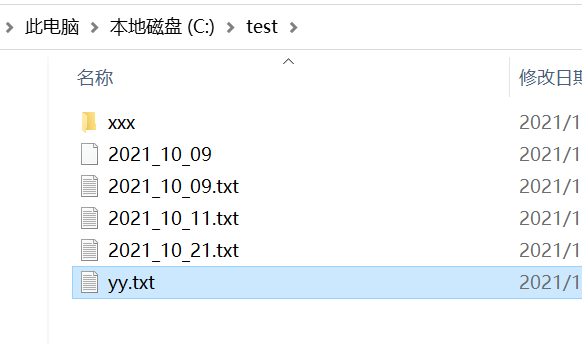
静态资源需要配置一下参数 :
/**
* 静态资源映射设置
*/
webServer.setStaticResourceDir("c:\\test");
webServer.setResourceMapping("/resource");
对应电脑情况
效果:
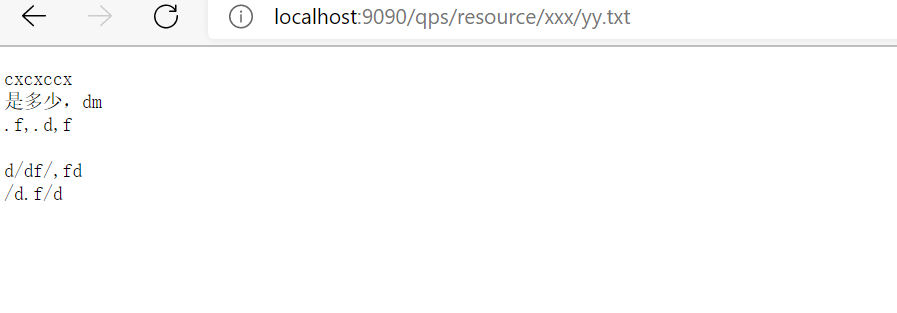
好了下面上硬菜:怎么实现的 用原生的java nio 类实现这种效果:
预备知识:
1 了解reactor模式
2 熟悉http报文规范 因为后面要解析http报文
3 了解nio socket等知识
本web服务采用reactor模式 和netty类似 会有一个专门处理连接的bosser 和 处理普通的读写的worker
当配置 bosser等于 0的时候 worker也会承担 bosser的职责 处理socket连接
当配置bosser大于0 那么bosser 会处理连接 把连接好的socket分发到 worker众多线程里面
所有 根据参数的不同 reactor模式也会发生变化
下面作者带着大家看下我写的服务器实现
首先定义工作者worker:
它是非常核心的一个类
他来处理Socket事件 其实现了 Runnable对象 把他提交到线程池 它的run 方法将会执行 继而会一直轮询处理Socket的事件
后面将详细介绍 怎么处理Socket 不同的事件的:
package com.pps.web; import com.pps.web.constant.PpsWebConstant; import com.pps.web.hander.EventHander; import java.io.IOException; import java.nio.channels.*; import java.util.Iterator; import java.util.concurrent.BlockingDeque; import java.util.concurrent.Executor; import java.util.concurrent.LinkedBlockingDeque; /** * @author Pu PanSheng, 2021/12/17 * @version OPRA v1.0 */ public class Worker implements Runnable{ protected Selector selector; /** * 测试bug的计数器限制 */ private int testBugSize=PpsWebConstant.TEST_BUG_COUNT; private BlockingDeque<Runnable> task; private Executor executor; private WebServer webServer; public Worker(Executor executor){ try { this.selector=Selector.open(); this.executor=executor; this.task=new LinkedBlockingDeque<>(); } catch (IOException e) { e.printStackTrace(); } } void init(WebServer webServer){ this.webServer=webServer; } protected void registerEvent(SelectableChannel selectableChannel, int type) throws ClosedChannelException { //如果该Selector 此时已经被阻塞在select()中了 那么这里会被阻塞住 请注意 if(selectableChannel.isOpen()) { selectableChannel.register(chooseSelector(), type); } } /** * 向工作者 注册 同步执行任务 * @param runnable */ public void registerTask(Runnable runnable){ task.addLast(runnable); } /** * 向工作者 注册 异步执行任务 * @param runnable */ public void registerAsyncTask(Runnable runnable){ executor.execute(runnable); } protected Selector chooseSelector(){ return selector; } protected void wakeUp(){ selector.wakeup(); } @Override public void run() { EventHander instance = EventHander.getInstance(webServer); int count=0; long startTime=System.nanoTime(); int timeOut= PpsWebConstant.TIMEOUT; while (true){ try { //同步任务执行 runTask(); /** * 如果不设置超时时间 那么如果线程已经运行了 且阻塞在select() 上面 * 这个时候再注册事件 那么注册线程会一直阻塞在注册方法上 * 远无法注册成功 * 所以必须加个超时时间 */ int select = selector.select(timeOut); if(select<=0){ /** * nio bug 当某些因为poll和epoll对于突然中断的连接socket * 会对返回的eventSet事件集合置为POLLHUP或者POLLERR,eventSet事件集合发生了变化, * 这就导致Selector会被唤醒,进而导致CPU 100%问题。 * 根本原因就是JDK没有处理好这种情况, * 比如SelectionKey中就没定义有异常事件的类型。 * * 所以需要处理下这种情况: */ count++; if(count>testBugSize) { long endTime = System.nanoTime(); long distance = endTime - startTime; //如果小于正常情况下 该限制次数下的事件间隔 说明触发了bug if(distance<((testBugSize+1)*1000*1000*timeOut)){ //重建selector Selector newSelector = Selector.open(); for (SelectionKey key : selector.keys()) { key.channel().register(newSelector, key.interestOps()); } this.selector=newSelector; } count=0; startTime=System.nanoTime(); } continue; } Iterator<SelectionKey> iterator = selector.selectedKeys().iterator(); while (iterator.hasNext()){ try { SelectionKey next = iterator.next(); if(!next.isValid()){ next.cancel(); continue; } SelectableChannel channel = next.channel(); if (next.isReadable()) { SocketChannel channelRead = (SocketChannel) channel; instance.read(channelRead, next, this); registerEvent(channelRead,SelectionKey.OP_READ); }else if(next.isAcceptable()){ ServerSocketChannel connectChannel = (ServerSocketChannel)channel; SocketChannel accept = connectChannel.accept(); accept.configureBlocking(false); registerEvent(accept,SelectionKey.OP_READ); }else if(next.isConnectable()){ }else if (next.isWritable()) { //应当不会出现这种情况 } }catch(Exception e){ e.printStackTrace(); } finally { iterator.remove(); startTime=System.nanoTime(); count=0; } } } catch (Exception e) { e.printStackTrace(); } } } private void runTask() { while (!task.isEmpty()){ Runnable poll = task.poll(); if(poll!=null){ poll.run(); } } } }
对于socket 连接事件处理:
ServerSocketChannel connectChannel = (ServerSocketChannel)channel;
SocketChannel accept = connectChannel.accept();
accept.configureBlocking(false);
registerEvent(accept,SelectionKey.OP_READ);
Worker的
registerEvent(accept,SelectionKey.OP_READ);
就是向当前的 work注册事件
而 BosserWorker 重载了
registerEvent(accept,SelectionKey.OP_READ);
方法
会挑选一个 工作者worker 来注册:
如下:
@Override
protected void registerEvent(SelectableChannel selectableChannel, int type) throws ClosedChannelException {
if(type == SelectionKey.OP_ACCEPT){
super.registerEvent(selectableChannel,type);
return;
}
int cU= count.addAndGet(1);
int workL=cU%workers.length;
Worker worker=workers[workL];
worker.registerEvent(selectableChannel, type);
worker.wakeUp();
}
那么 对于 read事件 是怎么处理的呢 这一块 牵扯的内容 就很多了
因为涉及到 http报文的读取 和解析 以及对一些异常的处理 特别是http报文的解析 针对http 上传文件的的报文 还有点复杂
首先read事件 会调用 EventHander 的 read 方法
public void read(SocketChannel socketChannel, SelectionKey selectionKey, Worker worker) throws IOException {
Response response=null; try {
//构造自己的输入流 方便后面读取
PpsInputSteram ppsInputSteram=new PpsInputSteram(socketChannel,selectionKey); HttpRequest request= null;
//解析Http报文 request = new HttpRequest(ppsInputSteram, worker); /** * 假如 服务器 context 为 / * 1 servlet / 匹配 / * 2 servlet /key 匹配 /key * 3 servlet /* 匹配 * 假如 服务器 context 为 /context * * servlet /context 匹配 url /context/context * servlet / 匹配 url /context * servlet /key 匹配 url /context/key * servlet /* 匹配 */ try {
//封装Response 方便我们的程序写Http报文响应
response=new Response(socketChannel,webServer.getServerParms()); response.setRequestHeader(request.getHeaderParam()); String matchUrl=request.getUrl(); if(matchUrl==null){ return; } if(matchUrl.endsWith("/")){ matchUrl=matchUrl.substring(0,matchUrl.length()-1); }
//作者定义的规范 类似于 java 的servlet HttpServlet httpServlet = mappingServlet.get(matchUrl); if(httpServlet==null){ //是否满足静态资源 if(resourceServlet.isMatch(matchUrl)){ httpServlet=resourceServlet; } //全局servlet是否存在 if(httpServlet==null){ httpServlet=allServlet; } //一个都没 那么就用系统默认的了 也就是404 if(httpServlet==null){ httpServlet=defualtServlet; } }
//这一步会调用到我们自己写的处理程序 httpServlet.get(request,response);
//一些后置任务 假如一个http请求是文件上传 那么肯定是要把这个文件放在 暂存文件里面的 当访问结束后 需要删掉它 不然会越来越多
if(request.isSavleFile()){ //删除临时文件 HttpRequest finalRequest = request;
//向工作者提交任务 worker.registerTask(()->{ for (Application__multipart_form_dataHttpBodyResolve.FileEntity fromDatum : finalRequest.getFromData()) { String urlF = fromDatum.getInfo(PpsWebConstant.TEMP_FILE_KEY); if (urlF != null) { try { Files.deleteIfExists(Paths.get(urlF)); } catch (IOException e) { e.printStackTrace(); } } } }); } }catch (Exception e){
//如果是这种异常 那么说明客户端 关闭了连接 if(e instanceof ChannelCloseException){ selectionKey.cancel(); socketChannel.close(); }else {
//这种异常就是我们自己的程序 异常了 需要打印 和返回500错误 e.printStackTrace(); errorServlet.get(request, response); } } } catch (Exception e) { if(!(e instanceof IOException)&&!(e instanceof ChannelCloseException)){ e.printStackTrace(); } selectionKey.cancel(); socketChannel.close(); } }
以上就是非常核心的socketc处理了
下面就进入怎么到解析Http报文
看下 我的HttpRquest类 当构造它是 根据传入的socketChannel 他就会开始解析了 并把数据封装到这个对象里面
解析http报文的方法体 非常复杂 根据不同的Content-Type 需要采取不同的算法 所以笔者采用工厂模式+策略方法模式+java的SPI 能够灵活的添加自己的算法
作者默认写了 三种解析算法 分别解析
application/x-www-form-urlencoded
multipart/form-data
application/json
三种请求体的数据:
请读者自己看吧 就不一一介绍了
package com.pps.web.data; import com.pps.web.Worker; import com.pps.web.constant.PpsWebConstant; import com.pps.web.exception.ChannelReadEndException; import com.pps.web.servlet.entity.PpsInputSteram; import java.io.InputStream; import java.io.UnsupportedEncodingException; import java.net.URLDecoder; import java.util.ArrayList; import java.util.HashMap; import java.util.List; import java.util.Map; /** * @author Pu PanSheng, 2021/12/18 * @version OPRA v1.0 */ public class HttpRequest { private String protocol; private String method; private Map<String,String> urlParams=new HashMap<>(); private Map<String,String> headerParam=new HashMap<>(); private Map<String,Object> httpBodyData=new HashMap<>(); private boolean isSavleFile; private PpsInputSteram inputStream; private String url; private Worker worker; public HttpRequest(PpsInputSteram inputStream, Worker worker) throws Exception { this.worker=worker; this.inputStream = inputStream; httpResolve(); inputStream.returnBuffer(); } public boolean isSavleFile() { return isSavleFile; } public void setSavleFile(boolean savleFile) { isSavleFile = savleFile; } public void addTask(Runnable task){ worker.registerTask(task); } public InputStream getInputStream() { return inputStream; } void putHttpBody(String key,Object v){ httpBodyData.put(key,v); } public List<Application__multipart_form_dataHttpBodyResolve.FileEntity>getFromData(){ Object body = httpBodyData.get("body"); if(body instanceof ArrayList){ return (List<Application__multipart_form_dataHttpBodyResolve.FileEntity>)body; } return new ArrayList<>(0); } public String getBodyContent(){ Object body = httpBodyData.get("body"); return (String)body; } private void httpResolve() throws Exception { //http报文 请求行和请求头 List<String> httpReportHead=new ArrayList<>(); byte [] line=new byte[PpsWebConstant.BUFFER_INIT_LENGTH]; int index=0; while (true) { try{ byte data = (byte) inputStream.read(); line[index]=data; if(data=='\n'&&index!=0&&line[index-1]=='\r'){ String s = new String(line, 0, index+1, "utf-8"); //如果s==\r\n 那么说明这个就是请求体和请求头的那个分隔标记 下面的字节就是请求体了 if(s.equals("\r\n")){ break; } httpReportHead.add(s); for (int i = 0; i < line.length; i++) { line[i]=0; } index=0; continue; } index++; //扩容 if(index>=line.length){ byte[] newLine=new byte[line.length*2]; System.arraycopy(line,0,newLine,0,index); line=newLine; } }catch (ChannelReadEndException e){ break; } } //解析请求头 resolveHttpHead(httpReportHead); //请求体解析 String content_type = getHeader("content-type"); if(content_type==null){ content_type=getHeader("Content-Type"); } if(content_type!=null){ content_type=content_type.trim(); if(content_type.contains("multipart/form-data")){ content_type="multipart/form-data"; } } HttpBodyResolve factory = HttpAlgoFactory.getHttpBodyResoveAlgo(content_type); if(factory!=null){ factory.resolve(this); } } private void resolveHttpHead(List<String> httpReportHead) throws UnsupportedEncodingException { //解析请求头 if(!httpReportHead.isEmpty()) { //请求行 String requestLine= httpReportHead.get(0); String[] lineArr = requestLine.split(" "); setMethod(lineArr[0]); setProtocol(lineArr[2]); String url=lineArr[1]; int i1 = url.indexOf("?"); if(i1!=-1) { String pureUrl = url.substring(0, i1); String endUrl = url.substring(i1+1); setUrl(pureUrl); endUrl= URLDecoder.decode(endUrl, PpsWebConstant.CHAR_SET); String[] split1 = endUrl.split("&"); for (String s : split1) { String[] split2 = s.split("="); if(split2.length==2){ putUrlParam(split2[0], split2[1]); } } }else { setUrl(url); } //解析请求头 for (int i = 1; i < httpReportHead.size(); i++) { String[] split1 = httpReportHead.get(i).split(":"); if(split1.length==2){ putHeaderParam(split1[0],split1[1]); } } } } public String getProtocol() { return protocol; } public void putUrlParam(String key,String v){ urlParams.put(key,v); } public void putHeaderParam(String key,String v){ headerParam.put(key,v); } public String getHeader(String k){ return headerParam.get(k); } public Map<String, String> getHeaderParam() { return headerParam; } public void setHeaderParam(Map<String, String> headerParam) { this.headerParam = headerParam; } public void setProtocol(String protocol) { this.protocol = protocol; } public String getMethod() { return method; } public void setMethod(String method) { this.method = method; } public Map<String, String> getUrlParams() { return urlParams; } public void setUrlParams(Map<String, String> urlParams) { this.urlParams = urlParams; } public String getParam(String key){ return urlParams.get(key); } public String getUrl() { return url; } public void setUrl(String url) { this.url = url; } }
对于 content-type
multipart/form-data
的请求体解析:
package com.pps.web.data; import com.pps.web.constant.ContentTypeEnum; import com.pps.web.constant.PpsWebConstant; import java.io.*; import java.util.*; /** * @author Pu PanSheng, 2021/12/19 * @version OPRA v1.0 */ public class Application__multipart_form_dataHttpBodyResolve implements HttpBodyResolve { private Map<String, Object> serverParam; @Override public void init(Map<String, Object> serverParam) { this.serverParam=serverParam; } @Override public void resolve(HttpRequest httpRequest) throws Exception { InputStream ppsInputSteram = httpRequest.getInputStream(); List<FileEntity> list=new ArrayList<>(); byte[] spline = getSpline(ppsInputSteram); while (true) { if (spline == null||spline[spline.length-1]=='-') { break; } FileEntity fileEntity = new FileEntity(); String desc = getDesc(ppsInputSteram); String[] split = desc.split("\r\n"); for (String s : split) { String[] split1 = s.split(";"); for (String s1 : split1) { String[] split2 = s1.split("="); if (split2.length == 2) { String key = split2[0].trim(); String v = split2[1].trim(); fileEntity.putInfo(key, v); } } } //具体的内容 byte[] lineBuff = new byte[3*1024]; int indexL = 0; while (true) { byte data = (byte) ppsInputSteram.read(); if (data != -1) { lineBuff[indexL] = data; //如果\r\n 那么说明下面 可能 就是其他文件了 但是还不一定 if (data == '\n' && indexL != 0 && lineBuff[indexL - 1] == '\r') { //看看下一段是否位分隔 byte[] spline2 = getSpline2(ppsInputSteram, spline.length); boolean f = true; if (spline2 != null && spline2.length != spline.length) { f = false; } if (f && spline2 != null && spline2.length == spline.length) { for (int i = 0; i < spline.length - 2; i++) { if (spline2[i] != spline[i]) { f = false; break; } } } //是分割线 表示确实结束了 这一段的内容就是文件了 if (f) { spline = spline2; break; } else {//没有结束 那么 for (int i = 0; i < spline2.length; i++) { indexL++; //扩容 if (indexL >= lineBuff.length) { lineBuff = resize(lineBuff, indexL); } lineBuff[indexL] = spline2[i]; } } } indexL++; //扩容 if (indexL >= lineBuff.length) { lineBuff = resize(lineBuff, indexL); } } else { break; } } int size=indexL-1; if(size<=0){ break; } String filename = fileEntity.getInfo("filename"); //说明是文件 if(filename!=null){ String tempDir =(String) serverParam.get(PpsWebConstant.TEMP_DIR_KEY); String tempFileName=tempDir+File.separator+UUID.randomUUID().toString(); try(BufferedOutputStream fileOutputStream=new BufferedOutputStream(new FileOutputStream(tempFileName))) { fileOutputStream.write(lineBuff, 0, size); fileOutputStream.flush(); fileEntity.putInfo(PpsWebConstant.TEMP_FILE_KEY, tempFileName); httpRequest.setSavleFile(true); } }else { byte [] t=new byte[size]; System.arraycopy(lineBuff,0,t,0,size); fileEntity.setData(t); } list.add(fileEntity); } httpRequest.putHttpBody("body",list); } @Override public String getType() { return ContentTypeEnum.multipartformdata.getType(); } public byte[] getSpline2(InputStream inputStream, int len) throws IOException { byte [] bytes=new byte[len]; for (int i = 0; i < len; i++) { byte data = (byte) inputStream.read(); if(data==-1){ break; } } return bytes; } public byte[] getSpline(InputStream inputStream) throws IOException { //取第一行的标志位 byte[] splitLine=new byte[1024]; int k=0; while (true) { byte data = (byte) inputStream.read(); if(data!=-1) { splitLine[k] = data; if (data == '\n' && k != 0 && splitLine[k - 1] == '\r') { //----------------343434--\r\n 表示结束了 if (splitLine[k - 2] == '-' && splitLine[k - 3] == '-') { return null; } k++; if (k >= splitLine.length) { splitLine = resize(splitLine, k); } break; } k++; if (k >= splitLine.length) { splitLine = resize(splitLine, k); } }else { break; } } byte[] newL=new byte[k]; System.arraycopy(splitLine,0,newL,0,k); splitLine=newL; return splitLine; } public String getDesc(InputStream inputStream) throws IOException { StringBuilder stringBuilder=new StringBuilder(); byte[] lineBuff=new byte[1024]; int indexL=0; while (true) { byte data = (byte) inputStream.read(); if(data!=-1) { lineBuff[indexL] = data; if (data == '\n' && indexL != 0 && lineBuff[indexL - 1] == '\r') { String s = new String(lineBuff, 0, indexL + 1, "utf-8"); //如果s==\r\n 那么说明这个下面就是具体的请求体字节内容 if (s.equals("\r\n")) { break; } stringBuilder.append(s); for (int i = 0; i < lineBuff.length; i++) { lineBuff[i] = 0; } indexL = 0; continue; } indexL++; //扩容 if (indexL >= lineBuff.length) { lineBuff = resize(lineBuff, indexL); } }else { break; } } return stringBuilder.toString(); } public byte[] resize(byte[] lineBuff,int indexL){ int resizeL = lineBuff.length * 2; if(resizeL>(Integer) serverParam.get("maxDataSize")){ throw new RuntimeException("超过服务器 最大可支持数据大小!"); } byte[] newLine=new byte[resizeL]; System.arraycopy(lineBuff,0,newLine,0,indexL); return newLine; } public static class FileEntity{ private Map<String,String> info=new HashMap<>(); private byte [] data; private InputStream inputStream; public InputStream getInputStream() { if(inputStream!=null){ return inputStream; } String url = info.get("pps-file-url"); if(url==null){ return null; } try { inputStream=new FileInputStream(url); return inputStream; } catch (FileNotFoundException e) { e.printStackTrace(); throw new RuntimeException(e); } } void putInfo(String k,String v){ info.put(k,v); } public String getInfo(String k){ return info.get(k); } public void setData(byte[] data) { this.data = data; } public byte[] getData() { return data; } } }
其他的就不举例了 对于上传文件的请求 服务器会将这个文件存到临时目录 当我们想要拿到这个文件流时 可以调用Request的相关方法 西面是我写的一个上传的servletDemo
import com.pps.web.data.Application__multipart_form_dataHttpBodyResolve; import com.pps.web.data.HttpRequest; import com.pps.web.data.Response; import com.pps.web.servlet.model.PpsHttpServlet; import java.io.InputStream; import java.util.List; /** * @author Pu PanSheng, 2021/12/21 * @version OPRA v1.0 */ public class UploadServlet extends PpsHttpServlet { @Override public void get(HttpRequest request, Response response) { List<Application__multipart_form_dataHttpBodyResolve.FileEntity> fromData = request.getFromData(); fromData.forEach(f->{ f.getInfo("name"); String filename = f.getInfo("filename"); //说明时文件流 if(filename!=null) { //得到文件流 InputStream inputStream = f.getInputStream(); }else { //普通key 那么直接转成字符 byte[] data = f.getData(); String s = new String(data); } }); } }
接下来看下 是怎么处理Response 当我们在自己的程序里 写入数据 是如何返回给服务器的
搜先我们需要的知道 我们的数据想要让浏览器任务 那么必须告诉浏览器如下信息:
什么文件类型(也就是content-Type)
数据量多大(不告诉这个 浏览器就会一直转圈 因为它不知到结束没有 但是有时候 我们并不知道我们要发送的数据有多大 那么就需要使用到分块传输 Chunck)
还有Http报文的那些规范 请求头 请求行
我们的程序应该只需要关心发送的数据 以上对于使用者应该是透明的 所以Response的重点就在这里 下面请看Response 的Write等重点方法
package com.pps.web.data; import com.pps.web.WebServer; import com.pps.web.constant.PpsWebConstant; import com.pps.web.exception.ChannelCloseException; import com.pps.web.util.BufferUtil; import java.io.IOException; import java.nio.channels.SocketChannel; import java.util.HashMap; import java.util.HashSet; import java.util.Map; import java.util.Set; /** * @author Pu PanSheng, 2021/12/18 * @version OPRA v1.0 */ public class Response { private SocketChannel socketChannel; private String protocol="HTTP/1.1"; private String code="200"; private String contentType="text/html"; private String charset="utf-8"; private Map<String,String> headerParams=new HashMap<>(); private Map<String,String> requestHeader=new HashMap<>(); /** * 客户端可支持压缩格式 */ private String[] acceptEncoding; /** * 应用的压缩算法 */ private ContentEncoding applyEncoding; /** * 压缩文件支持类型 */ private Set<String> compressContentType=new HashSet<>(); /** * 是否开启压缩 */ private boolean cancompress=false; private boolean flag; private Map<String, Object> serverParam; public Response(SocketChannel socketChannel,Map<String, Object> serverParam) { this.serverParam=serverParam; this.socketChannel = socketChannel; headerParams.put("Connection","keep-alive"); cancompress= (Boolean)serverParam .getOrDefault(PpsWebConstant.OPEN_CONPRECESS_KEY,false); String[] ss=(((String)serverParam .get(PpsWebConstant.CONPRECESS_TYPE_KEY)).split(",")); for (String s : ss) { compressContentType.add(s); } } public void setRequestHeader(Map<String, String> requestHeader) { String s = requestHeader.get("Accept-Encoding"); if(s==null){ s=requestHeader.get("accept-encoding"); } if(s!=null){ acceptEncoding=s.split(","); for (int i = 0; i < acceptEncoding.length; i++) { acceptEncoding[i]=acceptEncoding[i].trim(); } } this.requestHeader = requestHeader; } public void setCode(int code){ this.code=String.valueOf(code); } public void setCharset(String charset){ this.charset=charset; } public void setContentType(String contentType){ this.contentType=contentType; } public void putHeaderParam(String key,String v){ headerParams.put(key,v); } public void write(byte [] bytes){ write(bytes,0,bytes.length); } public void write(String s){ write(BufferUtil.strToBytes(s,charset)); } public void write(byte [] bytes,int offset, int len){ if(!flag){//第一次 那么需要写入 http报文头 byte[] messageChunckHead = createMessageChunckHead(); doWrite(messageChunckHead); flag=true; } //写入chunk 内容 byte[] content = createChunckBody(bytes,offset,len); doWrite(content); } /** * 结束发送 如果是write 那么必须要用flush 结束发送 不然浏览器无法结束 */ public void flush(){ byte[] encoding = createEndChunckBody(); doWrite(encoding); } /** * 压缩编码 * @param bytes * @return */ private byte[] encoding(byte[] bytes,int offset,int len){ if(isSupportCompress()){ return applyEncoding.convert(bytes,offset,len); } return bytes; } /** * 当前应用是否支持压缩 * @return */ private boolean isSupportCompress(){ boolean f1=cancompress &&applyEncoding!=null &&acceptEncoding!=null &&acceptEncoding.length>0; if(f1) { String s = headerParams.get("content-type"); if (s == null) { s = headerParams.get("Content-Type"); } return compressContentType.contains(s); } return false; } /** * 直接发送 一次发送完毕 只能调用一次 不必调用flush * @param content */ public void writeDirect(String content){ byte[] co=createMessage(content); doWrite(co); } /** * 直接发送 一次发送完毕 只能调用一次 不必调用flush * @param bytes */ public void writeDirect(byte [] bytes) { bytes=createMessage(bytes); doWrite(bytes); } private void doWrite(byte [] ccc){ BufferUtil.write(ccc,(byteBuffer)->{ try { socketChannel.write(byteBuffer); } catch (IOException e) { throw new ChannelCloseException(e); } }); } /** * 构造 普通的响应头 带有content_length * @param httpr * @return */ private byte[] createMessage(String httpr) { return createMessage(BufferUtil.strToBytes(httpr,charset)); } /** * 构造 普通的响应头 带有content_length * @param httpr * @return */ private byte[] createMessage(byte [] httpr) { StringBuilder returnStr = new StringBuilder(); //请求行 appendResponLine(returnStr,String.format("%s %s ok" ,protocol ,code));//增加响应消息行 //请求头 compreHander(returnStr,true); /** * 可能会被压缩 */ httpr=encoding(httpr,0,httpr.length); String contentLen=String.valueOf(httpr.length); appendResponseHeader(returnStr,"Content-Type: "+contentType+";charset=" + charset); appendResponseHeader(returnStr,String.format("Content-Length: %s",contentLen)); headerParams.forEach((k,v)->{ appendResponseHeader(returnStr,k +": "+v); }); returnStr.append("\r\n"); //请求体 byte[] bytes = BufferUtil.strToBytes(returnStr.toString(),charset); int i = httpr.length + bytes.length; byte[] newC=new byte[i]; System.arraycopy(bytes,0,newC,0,bytes.length); System.arraycopy(httpr,0,newC,bytes.length,httpr.length); return newC; } /** * 压缩头添加 * @param stringBuilder */ private void compreHander(StringBuilder stringBuilder, boolean force){ if(applyEncoding==null&&acceptEncoding!=null){ for (String s : acceptEncoding) { ContentEncoding contentEncodingAlgo = HttpAlgoFactory.getContentEncodingAlgo(s); if(contentEncodingAlgo !=null){ applyEncoding= contentEncodingAlgo; break; } } } if(force&&isSupportCompress()){ appendResponseHeader(stringBuilder,String.format("content-encoding: %s",applyEncoding.support())); } } /** * 构造http 分块请求头 不带有content_length * * 压缩算法例如gizp 和 chunck分块传输 如何组合呢 * * 答: * 只能先要把发送的数据 用gzip 组合起来 然后再分块传输 * 而不是 对每一块分别进行压缩后 再发送 * @return */ private byte[] createMessageChunckHead() { StringBuilder returnStr = new StringBuilder(); //请求行 appendResponLine(returnStr,String.format("%s %s ok" ,protocol ,code));//增加响应消息行 //请求头 appendResponseHeader(returnStr,"Content-Type: "+contentType+";charset=" + charset); appendResponseHeader(returnStr,String.format("Transfer-Encoding: %s","chunked")); headerParams.forEach((k,v)->{ appendResponseHeader(returnStr,k +": "+v); }); returnStr.append("\r\n"); byte[] bytes =null; bytes = BufferUtil.strToBytes(returnStr.toString(),charset); return bytes; } private byte [] createChunckBody(byte [] bytes,int offset,int lenA){ String len = Integer.toHexString(lenA); String h=len+"\r\n"; byte[] bytes1 = BufferUtil.strToBytes(h); int i = lenA + bytes1.length; byte[] n=new byte[i+2]; System.arraycopy(bytes1,0,n,0,bytes1.length); System.arraycopy(bytes,offset, n,bytes1.length,lenA); n[i]='\r'; n[i+1]='\n'; return n; } private byte [] createEndChunckBody(){ String end="0\r\n\r\n"; byte[] bytes = BufferUtil.strToBytes(end); return bytes; } private void appendResponLine(StringBuilder stringBuilder,String line){ stringBuilder.append(line+"\r\n"); } private void appendResponseHeader(StringBuilder stringBuilder,String line){ stringBuilder.append(line+"\r\n"); } }
对于http压缩算法 作者只是简单提供了gzip的压缩算法
首先我们需要知道的是 当客户端访问的时候 accept-type 包含了客户端可支持的压缩数据格式 我们获取到这个请求
然后判断 它请求的资源是否可以压缩 如果可以 我们就把资源压缩了 返回客户端
并且要在请求头带上
content-encoding
标识 标识这些数据我们压缩了 你需要解压再渲染处理
对于解压算法 作者只是简单写了下 并不成熟 因为它耗费机器cpu 有时候得不偿失 应该在一些静态资源上开启压缩 并且缓存起来 而作者的只是拿到数据马上压缩
然后返回而已 不太成熟
以上大体就介绍完毕了 我的WebServer
最后附上gitHub 链接 里面lib目录包含了jar 包 可以直接导入项目使用
pupansheng/pps-web (github.com)
记得帮我点赞哦!谢谢

