Kafka从入门到放弃(三) —— 详说生产者
上一篇对Kafka做了简单介绍,还没看的朋友可以点击下方链接。
消息中间件必须与生产者和消费者一起存在才有意义,这次先来聊聊Kafka的生产者。
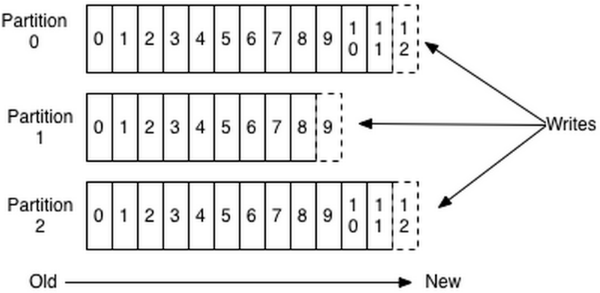
在开始之前,先了解一下消息在Kafka中是如何存储的,如下图所示,一般我们称那些数字为offset(偏移量)一般来说,消息在持久化后应该是有序的,这里的有序是针对分区的,而不是针对 Topic 的。
而且,生产者写入消息时,是往 Leader 写入,Follower 从 Leader 进行复制。
别看生产者只是发消息,调用 API 也是几行代码,但它的学问多着呢。为更好地理解后面的内容,请带着以下问题阅读:
- 生产者发送消息前会做什么准备?
- 生产者发送消息怎么保证数据不丢失?
- 生产者发送消息如何保证消息有序性?
- 生产者发送的消息是怎么分区的?
生产者设计了一个缓冲池,可以通过修改 buffer.memory 参数设置其大小;缓冲池内又有多个 Batch,当有多个消息需要写入同一个分区时,消息会先往 Batch 里面写入,等消息达到 batch.size 的时候开始发送,如果 batch.size 设置太小,生产者会频繁发送消息,带来更多的网络开销;
有些读者可能有这个疑问,如果有时候生产者生产的消息很少很小,一直达不到批次的大小,而消费者对时效性要求比较高,这种情况怎么办?其实,默认情况下,只要有线程,即使批次里只有一条消息,也会直接发送出去。但是,可以设置参数 linger.ms 来指定等待消息加入批次的时间,只要当批次消息达到 batch.size 或者等待时间达到 linger.ms 的时候,消息就会发送。
除此之外,生产者可以对消息进行压缩,以降低网络开销以及存储开销,通过设置参数 compression.type 设置相应的压缩算法。
先抛开 Kafka 现有确认机制,假如一条消息发到对应分区后,没有任何确认就紧接着发送第二条,很难不造成数据丢失。
于是我们让分区在收到消息后返回确认消息给生产者,生产者收到后发送下一条。
就这样,消息很顺利地发着,正好在 Leader 拿到最新的消息并返回确认给生产者的时候,Leader 挂了,此时,Follower 还没同步最新的消息,而生产者已经接收到了分区返回的确认,这时候还是丢了数据。
因此我们让 Leader 以及参与复制的 Follower 都收到消息后返回确认,这样就能最大程度保证消息不丢失,不过延迟较高。
针对上述的情况,Kafka 设置了一个 acks 参数,指定了必须有几个副本收到消息生产者才认为是写入成功了。
- acks=0,生产者只管写入,不会等待 Broker 返回响应,默认成功。这种情况最容易造成数据丢失,不过吞吐量最高;
- acks=1,Leader 收到消息后响应,生产者才认为写成功,这种也会造成丢失;
- acks=all,Kafka 集群内部会维护一个副本清单 ISR(后续会写,再此不做描述),当 ISR 里的所有副本都收到消息,才认为写入成功,最大程度保证消息不丢失,不过可能会造成延迟较高。
另外,Kafka 还有一个参数 retries,表示当消息发送失败后,生产者重试的次数,默认为0,如果对丢失消息零容忍,那就不能设置为0.
事实上,生产者在收到分区返回的确认消息前,还是可以持续发送消息的,这个可以通过设置 max.in.flight.requests.per.connection 参数进行修改,这个参数指定了生产者在收到响应前可以发送多少个消息。
这里需要注意的是,如果这个参数不为1,而 retries 参数也不为 0 的时候,当发生重试的时候,有可能造成分区数据顺序错乱。在有些场景下,顺序是很重要的,比如分析交易流水的过程,某个第一次存款的客户先存1块钱再取1块钱是正常的,但反过来可能就有点奇怪了。
所以,如果要保证数据不丢失,同时要保证数据有序性,就需要将 retries 设置为非 0 整数,max.in.flight.requests.per.connection 设置为 1,注意不是 0.
生产者可以指定键作为分区键,如果不指定,生产者会使用轮询算法将消息均匀的发到各个分区上
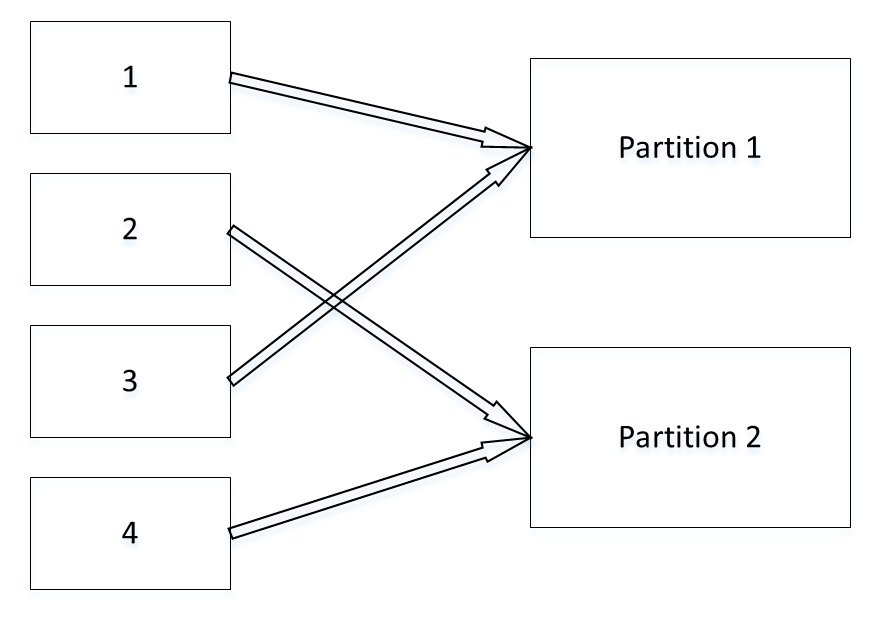
但如果指定了分区键,Kafka 会使用自己的 hash 算法获得 hash 值,然后根据 hash 值发到相应的分区。
到这,回顾一下前面的几个问题,是不是有点豁然开朗了?
如果觉得写得不错,对你有帮助,麻烦点个小小的赞,谢谢!
转载请注明出处:工众号“大数据的奇妙冒险”,博客园 Lyu_zt


