搜索系统核心技术概述【1.5w字长文】
前排提示:本文为综述性文章,梳理搜索相关技术,如寻求前沿应用可简读或略过
搜索引擎介绍
搜索引擎(Search Engine),狭义来讲是基于软件技术开发的互联网数据查询系统,用户通过搜索引擎查询所需信息,如日常使用的Baidu、Google等;广义上讲,搜索引擎是信息检索(Information Retrieval,IR)系统的重要组成部分,完整的信息检索系统包含搜索引擎、信息抽取(Information Extraction)、信息过滤(Infomation Filtering)、信息推荐(Information Recommending)等。
搜索技术已经经过很长时间迭代完善,目前整体上搜索引擎主要分为:爬取(Crawl)、解析(Analyze)、索引(Index)、检索(Search)和排序(Rank)几个阶段。
- 爬取:也叫搜寻器、连接器等,常见的应用实现即爬虫程序。本阶段通过初始指定的种子Web页面出发,以深度或广度的方式扩展搜索结果并进行元数据的保存。
- 解析:也叫转换器、清洗器等,用于将初始阶段爬取到的数据进行格式化处理、过滤、重建等工作。复杂的解析器还会进行如标题抽取、摘要生成、关键词提取、内容标签等工作。
- 索引:索引器将基于元数据、解析数据构建索引表,索引表可以帮助搜索引擎快速检索相关信息,如我们查询字典都会先通过拼写查看词语位置。常见的索引建立方式如正排索引、倒排索引等。
- 检索:当用户键入查询内容(Query)后,搜索引擎会通过一系列技术分解用户Query,再通过对索引的查找返回一系列Query关联的查询结果。这个阶段通常也被称为初筛或召回。
- 排序:在检索结果的基础上,搜索引擎会基于算法模型对检索结果进行排序,在这个阶段通常会引入用户特征、内容特征等信息,以便在最终展示上能够更加符合用户的搜索期望。完善的搜索引擎通常会包含多个排序阶段如粗排、精排等等。
有些文章对组成部分会有其它定义,但整体功能流程是相同的。

搜索引擎整体架构流程如上图,数据爬取、解析及索引生成通常作为离线系统模块为搜索引擎持续抓取新的数据并生成索引,不直接体现在用户搜索过程中;召回和排序通常作为在线模块,直接为用户搜索提供服务。
搜索引擎分类
根据搜索场景一般可以将搜索引擎分为四类:
- 全文搜索引擎:全文搜索引擎爬取互联网上的网页并记录生成索引,这种搜索方式使用户易于获取相关信息,但搜到的结果也过于杂乱,需要用户筛选甄别,如Baidu、Google均属于该类别。参考第五篇文章,笔者认为称之为Crawler-Based Search Engines更为贴切。
- 元搜索引擎:元搜索引擎将其他搜索引擎的结果汇总展示,本身不会进行数据爬取和索引记录,只需将用户Query分发到不同的搜索引擎再整合结果即可。因此与元搜索引擎对比,其他类引擎也称为独立搜索引擎。
- 垂直搜索引擎:垂直搜索引擎用于领域信息搜索,是搜索引擎的行业细分应用,通常只对特定机构、人群提供服务,其特点是搜索结果的专业和精确。譬如购房者搜索房产信息,希望获取的是相关售卖内容和交易内容,而不是房产新闻。
- 目录搜索引擎:目录搜索引擎依靠人工编辑维护网页目录并呈现给用户,用户的检索结果也基本由人工整理来决定,如过去的一些门户网站。目录引擎方式由于人工维护成本高、内容更新缓慢,因此应用场景有限,已经少有应用。
上文对搜索引擎的整体流程架构做了简单说明,下面将分为离线和在线两部分介绍搜索引擎的核心技术。
搜索引擎核心技术—离线部分
数据爬取
爬取阶段包括并不限于数据库接入、日志接入、线下导入及网络爬虫等方式,由于除爬虫外通常为定制化开发对接,因此不做介绍。
网络爬虫是搜索引擎最基础也是最关键的组件,爬虫也称为”Wanderers”、”Robots”、”Spiders”,爬虫程序从一组种子站点出发,以深度、广度或其他一些遍历算法漫游到其他链接网站,抓取并存储网页链接和内容。

爬虫程序整体结构流程如图所示,通常爬虫程序会维护自己的DNS服务器,避免频繁发起DNS解析请求。
Robots协议:Robots协议是Web站点和爬虫交互的协议,站点会将robots.txt放在站点的根目录上,表明爬虫可以访问和禁止访问的内容,爬虫程序应当严格遵从协议进行数据爬取。
爬虫质量评估一般有三个标准:抓取网页的覆盖率、时效性及重要性,简单来说就是抓的全、抓的快、抓的准。爬虫系统有很多优秀的开源实现如Heritrix、crawler4j等,感兴趣的读者可以自行深入学习。
数据解析
爬取到的信息大部分是非结构化或半结构化内容,对于数据解析系统来说,最主要的工作就是完成对这些内容的过滤清洗、信息提取以及权重排序。
对于爬取到的内容,首先需要进行过滤清洗,去除重复内容、失效内容等,最大限度降低搜索系统的噪音数据,该阶段通常使用一些基本的相似性算法或者规则等粗略手段进行过滤;然后通过结构化转换、信息抽取、内容分类等算法对爬取内容的价值信息进行细分,如提取网页中的关键词、生成网页信息摘要、为网页内容打上类别标签等;权重排序为同类网页进行重要度排序,由于互联网信息繁杂,内容质量参差不齐,因此对于爬取的网页内容必须有可量化的手段区分网页的好坏,如著名的PageRank算法通过分析网页间的引用关系划分网页质量。
整体来说,该环节通常包含很多如定制化规则编写、数据标注类的Dirty Work,但数据解析是整个搜索系统中十分必要的一环,为搜索系统的后续环节提供数据有效性的基础保障。
索引
面对海量文档,如何快速找到包含用户查询的内容,索引是必不可少的核心模块之一。索引本质上就是目录,例如书本目录、字典目录等等,方便用户快速完成查找,下面对搜索引擎中的索引应用进行简单介绍。
倒排索引
| 文档ID | 文档内容 |
|---|---|
| 1 | 谷歌地图之父跳槽Facebook |
| 2 | 谷歌公司在搜索市场拥有最高的市场占用率 |
| 3 | 苹果公司发布了IPhone13手机 |
假设当前有如上3篇文档集合,以文档ID建立索引关系,如果用户输入”苹果公司”进行检索,当前以文档ID为索引项的结构无法满足查询需求,只能遍历所有文档才能查询出包含”苹果公司”的内容,检索效率极低,为了解决该问题,倒排索引(Inverted Index)被提出用于反向建立文档内容和文档ID的索引关系,前者即可称为正向索引。
对上3篇文档进行分词、去停用词,假设得到结果为:
| 文档ID | 文档内容 | 分词结果 |
|---|---|---|
| 1 | 谷歌地图之父跳槽Facebook | [谷歌,1][地图,2][跳槽,3][Facebook,4] |
| 2 | 谷歌公司在搜索市场拥有最高的市场占用率 | [谷歌,1][公司,2][搜索,3][市场,4][拥有,5][市场,6][占有率,7] |
| 3 | 苹果公司发布了IPhone13手机 | [苹果,1][公司,2][发布,3][IPhone13,4][手机,5] |
对分词后的结果按照单词维度进行统计,记录每个词条出现的文档ID、词频、位置等信息,便构成了倒排列表,如下表所示:
| 单词ID | 单词 | 文档频率 | 倒排列表(文档ID、词频、位置) |
|---|---|---|---|
| 1 | 谷歌 | 2 | (1,1,<1>),(2,1,<1>) |
| 2 | 地图 | 1 | (1,1,<2>) |
| 3 | 搜索 | 1 | (2,1,<3>) |
| 4 | 跳槽 | 1 | (1,3,<1>) |
| 5 | 1 | (1,1,<4>) | |
| 6 | 拥有 | 1 | (1,1,<5>) |
| 7 | 市场 | 1 | (2,2,<4,6>) |
| 8 | 占有率 | 1 | (2,1,<7>) |
| 9 | 苹果 | 1 | (3,1,<1>) |
| 10 | 公司 | 2 | (2,1,<2>),(3,1,<2>) |
| 11 | 发布 | 1 | (3,1,<3>) |
| 12 | IPhone13 | 1 | (3,1,<4>) |
| 13 | 手机 | 1 | (3,1,<5>) |
依照倒排表可以构建完善的倒排索引系统,借助倒排索引,搜索系统可以迅速检索出用户搜索的内容,如输入”谷歌”即可根据索引查到相关文档ID,进一步可依照文档频率、词频等值对文档进行排序,如典型的TF-IDF、BM25。
工业场景中倒排索引的实际应用本质上与上表相似,实际场景的倒排索引规模往往很大,更多需要考虑如索引的分布式存储、更新时效等问题,基于开源Lucene的ElasticSearch、Solr都对此提供了完善的解决方案,业界也大多以开源方案进行索引构建,有能力的公司会在此基础上进行优化和二次开发。
向量索引
向量索引(vector index)是通过某种数学模型,将待检索的内容转化为数学向量,并对向量构建的一种时间和空间上比较高效的数据结构,借助向量索引可以高效地查询与目标向量相似的若干向量。
常见的向量度量方式有:欧式距离、余弦相似度、向量内积、海明距离,向量检索不同于基于二分、哈希等传统查找算法的精确检索,如需达到精确结果,需要对所有候选向量进行线性度量计算,计算消耗较大,因此目前的向量检索大都属于ANNS(Approximate Nearest Neighbors Search,近似最近邻检索)。ANNS的核心思想是不局限于返回最精确的结果项,而是搜索向量空间上临近的数据项,在可接受的范围内牺牲精度提高范围检索效率,因此与搜索系统的属性也十分契合,ANNS向量索引从实现上主要分为:
-
基于树的索引
基于树的索引根据向量的分布特征采用一系列超平面将高维向量空间划分为多个子空间,并采用树形结构维护空间层次关系,如向量\((1,0,1)\)依据维度进行构建,除去根节点,第一层节点记录取值为\(1\),第二层取值为\(0\),第三层取值为\(1\),由此除根节点外的每一个节点均对应其父节点空间被划分后的子空间,再通过树形结构搜索到若干距离目标向量较劲的叶子节点,节点路径即为候选向量。随着向量维度的提高,划分空间的超平面开销将显著增大,从而影响树形结构的构建效率。
-
基于哈希的索引
向量索引使用的哈希是局部敏感哈希,局部敏感哈希简单来说就是对内容相近的输入计算出来的哈希值也很相近,通过局部敏感哈希将向量划分为若干区间,从而使每个向量均属于特定哈希函数的值域区间。搜索时可先通过哈希函数计算选择相近的向量空间,然后再依次对所属区间内的向量进行度量计算。但如果实际场景中向量分布不均,那么哈希函数划分的区域大小也不平衡,无法有效提升搜索的准确率和效率。
-
基于向量量化的索引
基于向量量化的索引通常采用如k-means等聚类方式对向量集合进行划分,记录各个聚类的中心坐标,在搜索时首先选取相近的中心坐标,然后再对相近的个聚类空间中的向量进行度量计算。该方法在高维向量中容易遗漏部分潜在与目标相近的向量,难以达到较高的准确度。
-
基于图的索引
前面的几种索引都属于空间划分的方法,每个向量存在与划分好的区域,基于图的方法将所有向量间的相似度预先计算好,并以图的形式维护向量间的距离关系,由于图的连通性,邻居的邻居也可能是邻居,这样就将最近邻计算转化为图的遍历,在搜索时从一个或多个节点出发,探索当前节点的所有邻居节点与目标向量的相似度,并进一步通过深度或广度的方式进行遍历探索。基于图的方法在准确率和效率上都有较好的表现,但在构建图的过程需要进行大量的向量距离计算,且在新增向量时需重新对图进行构建,均会产生很大开销。
目前,用于向量检索的热门工具有Facebook开源的FAISS、微软的SPTAG,但这些都是基础的工具库,国内开源的Milvus集成了主流的开源能力,提供了完整的向量索引框架。
搜索引擎核心技术—在线部分
Query理解
一般情况下,用户通过自然语言描述想要搜索的内容,因此Query理解是用户搜索的第一道环节。Query理解的结果在召回和排序阶段提供基础特征支撑,因此Query理解很大程度影响召回和排序的质量,换句话说,如果搜索系统无法正确理解用户的搜索意图,必然无法为用户展示准确的搜索结果。Query理解主要包含Query预处理、Query纠错、Query扩展、Query归一、联想词、Query分词、意图识别、term重要性分析、敏感Query识别、时效性识别等,实际应用中会构建一个可插拔的pipeline完成Query理解流程。

-
Query预处理
Query预处理比较简单,主要是对用户Query作如大小写转换、简繁转换、无意义符号去除等操作,方便后续模块进行分析。
-
Query改写
纠错、扩展、归一都属于Query改写的范畴。
- Query纠错:顾名思义,即检测并纠正用户搜索的错误输入如错字、多字、漏字等。
- Query扩展:通过挖掘Query的语义关系扩展出与原Query相关的候选Query列表。一方面,Query扩展通过推荐候选Query帮助用户澄清搜索需求;另一方面,通过扩展提高搜索系统对长尾词条的搜索利用率。目前Query扩展主要基于语义相关性、话题相关性、用户画像等维度进行扩展。
- Query归一:Query归一是将用户Query在语义不变的情况下将搜索内容标准化,如”华仔是啥时候生的”归一化为”刘德华的出生日期”。
-
Query分词
Query分词就是将自然语言的Query内容切分为多个term(词语),如”手机淘宝”切分成”手机””淘宝”两个term。分词作为基础的词法分析组件,其准确性很大程度影响搜索后续各阶段的处理。
除分词准确性外,分词的粒度在搜索系统中也需进行控制,如”王者荣耀”作为一个term,在后续搜索环节中带来的准确度、计算复杂度的影响相较于切分成”王者”和”荣耀”两个term更具优势。
分词技术相对来说已经较为成熟,主要结合基于词典匹配的方法、基于统计的方法以及序列标注等机器学习模型或深度学习模型进行实现,如Hanlp、IKAnalyzer、Jieba等。目前分词更多的痛点在于新词不能及时识别覆盖,如领域性强的专业词汇、网络新起的热门词汇等。
-
term重要性分析
考虑不同term在同一文本中重要性不同,在做Query理解和Doc内容理解时均需要挖掘分词后的term重要性。term重要性可以通过分等级或0.1~1.0的量化分值来衡量,如搜索”适合女生玩的游戏app”,按照重要度排序应当是”游戏-女生-app”,那么在搜索时便可以按照重要度组合调整查询条件。Doc内容方面可以通过LDA主题模型、TextRank等方法来挖掘term重要性;Query侧可以通过用户点击量等信息训练分类模型,判断词条的重要性。
-
意图识别
意图识别是Query理解的重要模块,由于用户输入Query不规范以及词语本身的歧义,如何根据用户Query的上下文准确定位用户想要搜索的意图范围对于搜索效果起到重要作用。比如”苹果和小米对比”,通常用户是想比较手机而非食物的差别。
意图识别可以归为短文本多标签分类任务,在进行分类之前,需要先对Query侧和内容侧的意图标签进行统一,以便预测出Query的意图分布后直接召回相关标签的内容。模型方面如传统的SVM模型、浅层网络模型Fasttext、深度神经网络模型TextRNN、TextCNN等
-
敏感Query识别
敏感识别主要对Query进行内容审核,检查内容是否涉政、涉恐、涉暴等,如果识别出敏感Query则进行定向引导、回复等处理。敏感识别可归为分类问题,简单的做法可以通过敏感关键词表匹配,复杂点可以基于SVM等方法训练分类模型进行处理。
-
时效性识别
用户Query可能带有一定时效性要求,如搜索”疫情进展”、”新上映的电影”隐式地表达了对内容时效性的要求。针对Query时效性的需求,引擎在做后续搜索工作时就可以针对性地做一些过滤或者排序。
上述内容仅对Query理解做了概要介绍,详细可参考文章《全面理解搜索Query:当你在搜索引擎中敲下回车后,发生了什么》
召回
召回是根据Query获取相关候选Doc的过程,召回阶段要求覆盖的内容足够广,如果相关Doc不能在召回阶段被检索出来,即使后续的排序算法效果再好也是徒劳。
在搜索场景中,召回通常主要包含两类方法:基于词的传统召回和基于向量的语义召回。前者依赖传统的倒排索引实现,后者基于语义embedding的向量索引实现。倒排索引和向量索引在前文的索引章节中已经做了相关介绍,召回阶段对检索结果的关注点主要是召回的性能和结果的多样性,基于词的传统召回虽然可以通过同义词归一化解决部分相似问场景,但仍然有很大的局限性;语义召回把Query和Doc分别向量化,将其映射到同一向量空间作最近邻搜索,可以在语义层面上提升召回的结果范围,embedding就是向量化的过程。
语义召回可以分为基于Interaction的深度语义模型和基于Representation的深度语义模型:
- Representation based也称为基于表征的匹配方法,采用深度学习模型分别表征Query和Doc,再通过计算向量相似度来作为语义匹配分数,通常Doc的表征计算会离线提前计算好以节省搜索时间消耗。典型Representation方法如双塔DSSM模型,所谓双塔及Query塔和Doc塔分别对两个内容进行表征计算。

-
Interaction based也称为基于交互的匹配方法,这种方法不直接学习Query和Doc的语义表示向量,而是在神经网络底层让Query和Doc交互从而获得基础的匹配表示,再引入如CNN将基础表示融合得到相似度结果,典型如Bert。
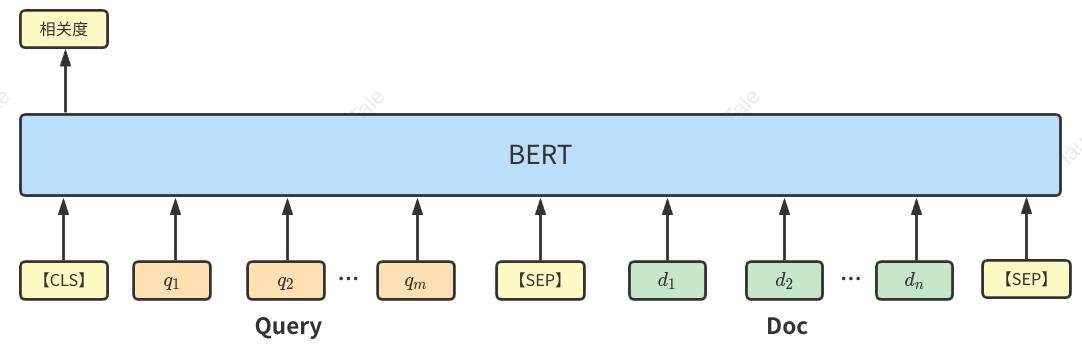

交互式由于可以深层考虑Query和Doc之间的关系,在相似度匹配的准确率方面较表征式会高一些;而表征式可以提前计算好所有Doc的向量记录到向量索引中,接收到Query时只需对Query进行表征计算并通过向量索引进行浅层计算即可得出得到候选Doc列表,因此会有更好的性能。在召回任务中,如果待召回的Doc库量级较大,那么使用表征式方法提前记录好向量索引更适合在不影响性能的前提下提升召回率;反之可使用交互式方法适当提升召回阶段的内容准确率。
词条召回和语义召回在搜索系统中一般都会得到应用,参照文章《Query 理解和语义召回在知乎搜索中的应用》,两种召回产生的Doc列表都将送入到排序环节进行过滤筛选,在商品搜索、内容推荐等领域,还会引入如用户行为特征、时空间特征等维度来构成多路召回。

排序
排序本质上是给召回的候选Doc列表打分,以决定对用户的内容呈现顺序。排序通常分为粗排和精排两个两个环节,一些精度要求高或者考虑业务属性特征的搜索场景还会有重排,如著名的竞价排名。

如上图所示,召回->粗排->精排->重排的流程就好比漏斗,逐层筛选使用户的搜索结果逐步精确化。召回是漏斗的最上游,采用一些全而快的方法对Doc进行初步筛选;排序是漏斗下游,对筛选后的Doc做小而准的精细化排序过滤。
排序是搜索的核心组成,排序结果的好坏直接影响用户体验及相关场景的业务转化率。早期的排序基于专家规则,手动识别并组合内容特征,专家系统解释性强,但在大数据场景下专家系统显然无法满足搜索内容的多样性。在搜索引擎特别是互联网相关产品中,如何解决排序是重要研究的问题,使用机器学习参数化排序特征、规范化排序规则目前在各大搜索引擎中都得到了良好的实践应用。
机器学习排序方法称为LTR(Learning to Rank),由人工标注训练数据、文档特征抽取、学习分类函数、搜索系统模型集成4个步骤构建,学习排序工作流程示意图如下:

目前LTR主要分为三种:单文档方法Pointwise、文档对方法Pairwise、文档列表方法(Listwise)。
Pointwise
Pointwise将单一文档作为训练数据,不考虑文档间的关系,文档转化为特征向量后将排序问题转换为分类或回归问题,如CTR问题的数学表达式为\(y=f(x)\),其中y的范围是\([0,1]\),即\(y\)的值越大表示用户点击概率越高。下面对常见的几种Pointwise方法进行介绍:
-
LR
逻辑回归(Logistics Regression,LR)是互联网领域最基础最广泛的分类算法,LR可以处理大规模离散化特征、易于并行化、可解释性强,LR是CTR预估应用最基本的模型,工业界排序模型的首选。但LR假设各特征之间是相互独立的(LR的函数形式决定),忽略的特征间的关系,且对非线性拟合能力较差,限制了模型的上线,通常作为Baseline版本,LR模型定义如下:
\[f(x) = logistics(linear(X))
\\
其中:\quad logistics(x) = \frac {1}{1+e^{-x}}\quad\quad\quad\quad linear(x) = \theta^TX
\] -
FM/FFM
FM在LR的基础上作出改进,模型定义为:
\[f(x) = logistics(linear(X) + \sum\limits_{i=1}^{n} \sum\limits_{j=i+1}^{n} w_{ij}x_ix_j)
\]函数前半部分与LR定义相同,在LR的基础上增加\(\sum\limits_{i=1}^{n} \sum\limits_{j=i+1}^{n} w_{ij}x_ix_j\),该项为二次交叉项,表达了特征两两之间的交互作用,其中\(w_{ij}\)表示\(x_i\)和\(x_j\)两两特征间的交互权重。从公式可以看出,用\(n\)表示特征数量,那么组合特征参数共有\(n(n+1)/2\)个,使用二阶矩阵存储\(w\),在大规模离散特征的情况下会导致矩阵维度很大;且在多项式模型中,特征\(x_i\)和\(x_j\)的组合采用\(x_i x_j\)表示,只有两者都非零时,组合特征才有意义,而在样本数据稀疏的情况下,满足\(x_i\)和\(x_j\)都非零的样本将非常少,训练样本的不足也容易导致参数\(w_{ij}\)求解不准确,影响模型整体效果。
由于\(w_{ij}\)和\(w_{ji}\)表示的交互权重是相等的,那么所有二次想参数\(w_{ij}\)可以组成一个对称矩阵\(W\),进一步矩阵可以分解为\(W = V^T V\),\(V\)的第\(j\)列便是第\(j\)维特征的隐含向量,进而每个权重参数可表示为\(w_ij=<v_i,v_j>\),因此FM的模型方程可定义为:
\[f(x) = logistics(linear(X) + \sum\limits_{i=1}^{n} \sum\limits_{j=i+1}^{n} <v_i,v_j>x_i x_j)
\]同一特征对其它特征的权重作用是不同的,如天气特征对时间特征和性别特征的作用是不一样的,使用同样的向量计算内积会导致明显的偏差。在FM的权重基础上引入\(field(域)\)概念,令\(w_{ij} = <v_{if_j},v_{jf_i}>\),表示不同特征在计算权重参数时采取的向量也不同,该方法称为\(FFM\)算法,公式如下:
\]
-
GBDT
LR、FM/FFM更加适合处理离散化特征,GBDT(梯度提升决策树)适合计算连续特征,但如果单独使用GBDT需要通过归一化等措施将离散特征统计为连续特征,无法很好的处理高维度稀疏特征,并且在离散化特征归一化的过程需要耗费比较多的时间,因此将连续型特征和值空间不大的特征给GBDT,其他高维度稀疏特征和GBDT的叶子节点一并给LR、FM/FFM进行处理,组成GBDT+LR、GBDT+FM的组合应用。

Pairwise
Pointwise只考虑单个Doc和Query的相关性,没有考虑文档间的关系,而排序问题注重的是排序结果,并不要求对相似度做精确打分。Pairwise考虑的是两两样本之间的顺序关系,将文档对作为输入,输出是局部的优先顺序。如一个Query对应的检索结果为\({doc_1,doc_2,doc_3}\),文档可组成的文档关系集合为\({(doc_1,doc_2),(doc_1,doc_3),(doc_2,doc_3)}\),以每一个关系对\((doc_i,doc_j)\)作训练实例,如果\(doc_i > doc_j\),则标记\(+1\),反之标记\(-1\),于是便将排序问题转换为二分类问题。预测时模型可以得到所有文档对的偏序关系如\({<doc_1,doc_2,+1>,<doc_1,doc_3,-1>,<doc_2,doc_3,-1>}\),那么最终排序结果即\({doc_3,doc_1,doc_2}\)。

在二分类问题上,机器学习的方法就很多了,如Boost、SVM、神经网络等,典型在Pairwise上的应用如RankSVM、RankNet。
Listwise
Pairwise将文档对作为训练实例,仅考虑文档间的偏序关系,负相关文档无法得到体现,且局部文档对偏序关系预测错误会导致整体排序结果的错误。Listwise是将整个Doc排序序列作为训练样本得到最优评分函数\(F()\),对候选Doc集合的所有排序序列作预测,输出排序后的列表,常用方法如LambdaRank、LambdaMART。

Listwise考虑模型整体的排序结果,训练样本基于标注好的文档有序列表,理想情况下,确实更容易满足真实用户需求,但该方法前期的标注工作所需成本显然更高,其次训练成本也要高于前两种方法,且除专业领域外个人很难代表整体对排序结果的期望,因此Listwise在实际应用场景中有明显的限制。
| LTR | 优点 | 缺点 | 输入 | 时间复杂度 | 典型算法 |
|---|---|---|---|---|---|
| Pointwise | 算法简单,只以每个文档作为单独训练数据 | 只考虑单文档同Query的相关性,忽略文档间的影响 | \((x,y)\) | \(O(n)\) | LR、FM、FFM、GBDT、DNN |
| Pairwise | 对文档对进行分类,得到文档集合的偏序关系 | 只考虑文档对的偏序关系,局部偏序错误影响整体结果,且无法体现负相关文档 | \((x_1,x_2,y)\) | \(O(n^2)\) | RankSVM、RankNet |
| Listwise | 直接对文档集合结果进行优化,理论效果最好 | 算法成本高,应用场景受限 | \((x_1,x_2,…,x_n,y)\) | \(O(n!)\) | LambdaRank、LambdaMART |
上表对LTR的三种典型方法进行总结,虽然在理论效果上Listwise > Pairwise > Pointwise,但在实际工业场景中的应用是相反的,出于成本、可解释性、鲁棒性等一系列问题的考虑,Pointwise往往是实际应用的首选方案。
文章未对Pairwise和Listwise进行展开,详细可参考文章《LTR精排序笔记整理》
精排和粗排
粗排和精排都是排序阶段的环节,排序的核心目标是对召回的内容做进一步过滤筛选,按照用户搜索的相关度为用户返回排序后的搜索结果。精排阶段会采用排序准确度较高的模型,此类模型复杂度也较高,受算力限制一般在性能上不容易满足大规模Doc排序,因此在召回和精排之间会插入粗排对召回结果做初步过滤,如排序章节开篇的漏斗图。
粗排阶段的核心目标是满足整体搜索性能的前提下为精排缩小候选排序集,与精排的不同点主要有两个:算力和RT约束更严格,排序候选集更大;因此粗排阶段采用的算法模型通常计算特征少、计算效率高,也会引入如TF-IDF、BM25、向量匹配等较为轻量级的方法,一定程度上会与召回有所重合,且目前召回阶段使用的一些框架算法也具备一定的排序能力,因此有些文章会将召回和粗排放在一起,划分为粗召回和精排序两个阶段。
虽然粗排和召回在模型上有重合,但由于目标不同,在样本构造上也不一样,以DSSM为例,在召回阶段以召回率为主,关键是不遗漏,可以从全体Doc库中负采样;在粗排阶段以准确率为主,可以用线上曝光的负样本或者从召回候选中负采样。
如果算力充足可以对全库Doc排序,是否还要保留召回?
召回是必要的,排序关注的是准确度,只有排序阶段就限制了冷门Doc的曝光机会,召回为系统提升了结果的多样性,避免用户陷入信息茧房,在推荐系统中多样尤为重要。
随着技术迭代和算力提升,粗排、精排的边界划分也逐渐模糊,有时也会将一些新的模型方法放置到精排阶段进行验证和优化,待模型优化或算力提升再将其应用到粗排阶段,精排技术向粗排的迁移也是粗排精排化的趋势过程,未来不再区分粗排精排也不是没有可能。
深度学习在搜索的应用
传统机器学习方法极度依赖输入特征数据的前期处理,即人工的特征工程,在模型的泛化能力上有所欠缺。为了降低人工干预,使模型在特征扩展和效果泛化上具备更好的效果,深度学习模型被引入解决搜索中的一些任务,并取得了不错的效果,下文对深度学习中应用比较广泛的模型做出简单阐述。
-
DNN
DNN(Deep Neural network,深度神经网络)也叫多层感知机(MLP,Multilayer Perceptron),是经典的深度神经网络模型,DNN能够对原始特征进行学习,抽取出深层信息,提高模型准确率和泛化能力。
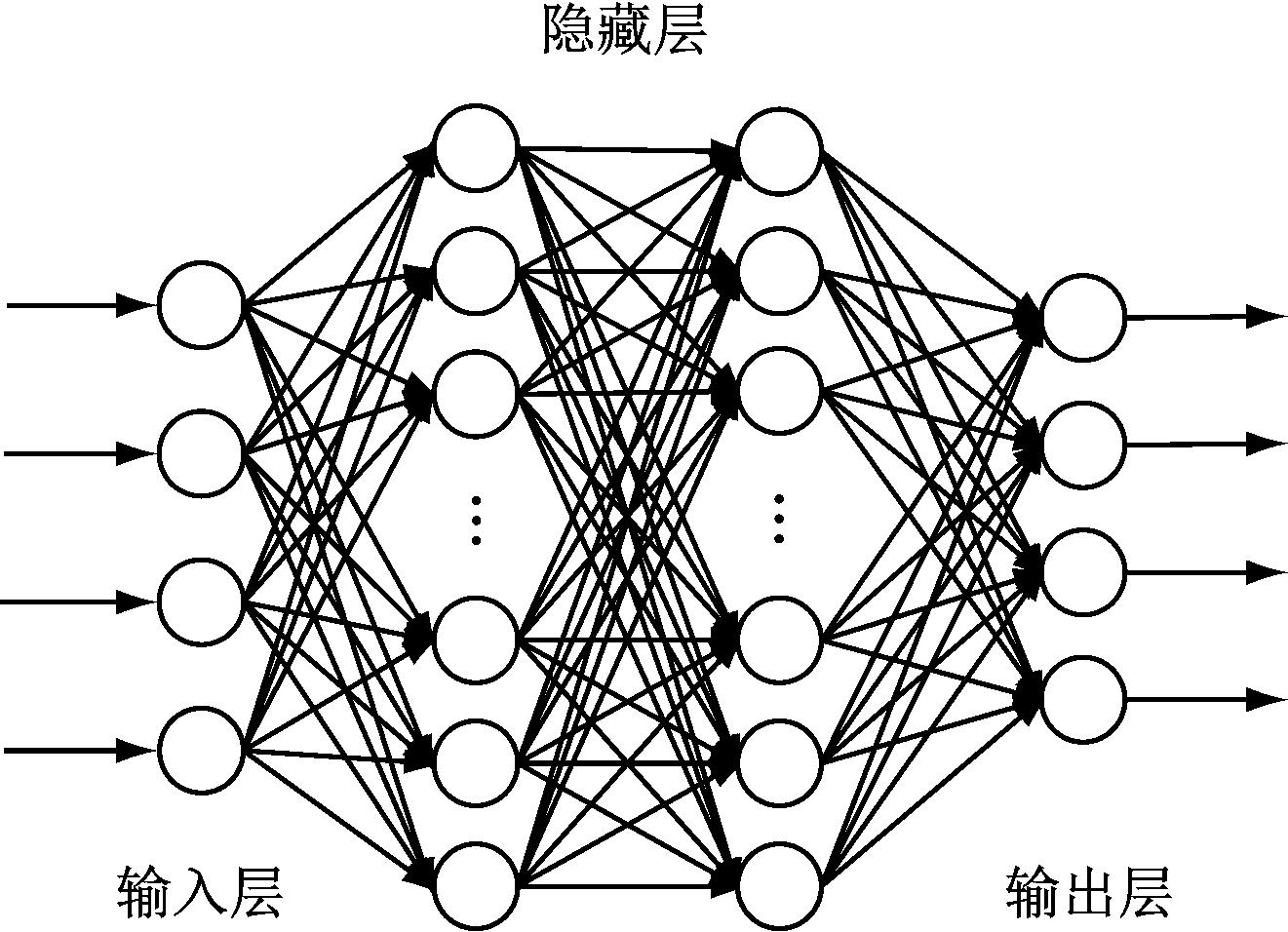
DNN模型如图,层与层之间是全连接的,因此对于非线性特征处理有很大优势,特别是在搜索推荐系统中,很多特征与训练目标的关系并不清晰,使用DNN可以很好提取高维度特征。DNN在召回和排序环节都可应用,只是在最后的输出层选择使用$softmax$还是$sigmoid$的区别。召回使用$softmax$是因为召回面向的是全量内容,使用$softmax$更能保证结果的多样性;排序阶段输入也可以进一步加入精细特征,使用$sigmoid$转化为分类问题对结果进行排序校准。

-
Wide&Deep
Wide&Deep是Google 2016的一篇论文提出,该模型将线性模型和深度神经网络融合,结合线性模型的记忆能力和深度模型的泛化能力,从而提升整体效果。
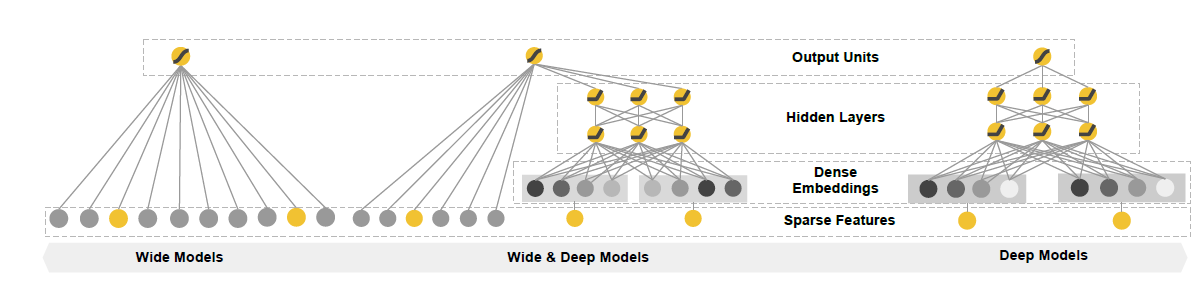
如图所示,左侧是宽线性模型,右侧是深度模型,中间的Wide&Deep可以看做两个模型的组合:
- Wide部分为LR模型,优点是模型记忆性好,对于样本出现的高频低阶特征能够使用少量参数学习,缺点是泛化能力差,用于学习样本中的高频部分。
- Deep部分为DNN模型,优点是泛化能力强,对于少量出现的样本甚至没出现过的样本都可以走出预测,缺点是对低阶特征的学习需要较多参数才能达到Wide部分效果,且泛化能力强也会导致一定程度的过拟合。
通过两者的结合,平衡两种方法的优缺点,形成一个end-to-end的宽深度学习框架,数学表达式如下:
\[f(x) = logistics(linear(X) + DNN(X))
\]是不是很眼熟,和GBDT+LR的形式如出一辙
-
DeepFM
DeepFM实在Wide&Deep的基础上,将Wide部分的LR替换成FM,由于LR对低阶特征利用简单,在实际使用中还需要人为构建交叉特征,FM在前文介绍过可自动进行特征交叉计算,对低阶特征的利用更加合理,克服了W&D线性部分依然需要对低阶特征做复杂特征工程的缺点。
-
DSSM
DSSM在召回部分提到过,下面简单进行展开介绍。
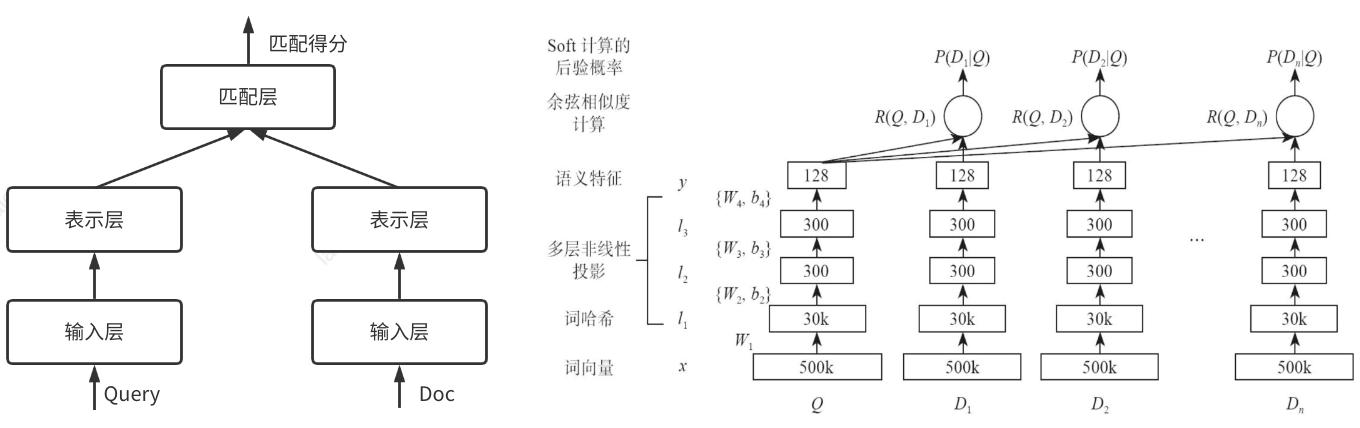
上图是DSSM三层结构,图右侧是DSSM表示层的结构。输入层的作用是将文本转化成向量提供给深度学习网络,如英文可通过Word Hashing方式处理、中文可以使用一些预训练模型做转换;表示层通过多层非线性转换将输入的高维向量转换为低维向量,如图中所示从原始的50万维转化为128维;匹配层将Query和Doc得到的两个128维向量,通过余弦公式计算其相似度。
-
Transformer
Transformer由Google论文《Attention is All You Need》提出,宏观上是由encoder和decoder组成的模型,用于解决如机器翻译、对话生成等seq2seq的问题,如下图所示,左侧是模型展开,原文中由6个encoder和decoder组成,右侧是单层encoder和decoder的网络结构。
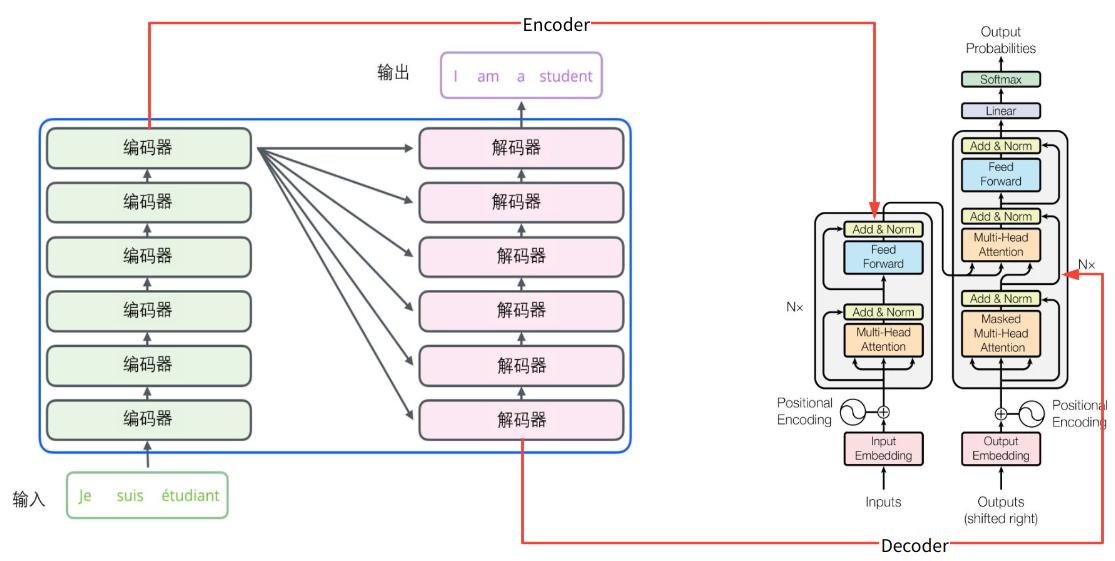
自注意机制(Self Attention)是Transformer的核心机制,什么是自注意呢?假如我们现在要翻译下面的句子
the animal didn’t cross the street because it was too tired
其中的it指代的是animal还是street对算法而言是很难区分的,通过注意力机制,当算法对it这个单词进行编码时,attention层会在其他单词上都分配注意力,即计算句子中每一个单词的注意力向量时,其他的词都会对当前计算的单词打分,这样对当前单词的编码就会考虑其他单词的影响。Transformer通过增加”多头注意力”(Multi-Head Attention),扩展模型对不同位置的关注能力(如某个头更关注前两个单词,某个头更关注结尾两个单词),进一步完善了Self Attention层。
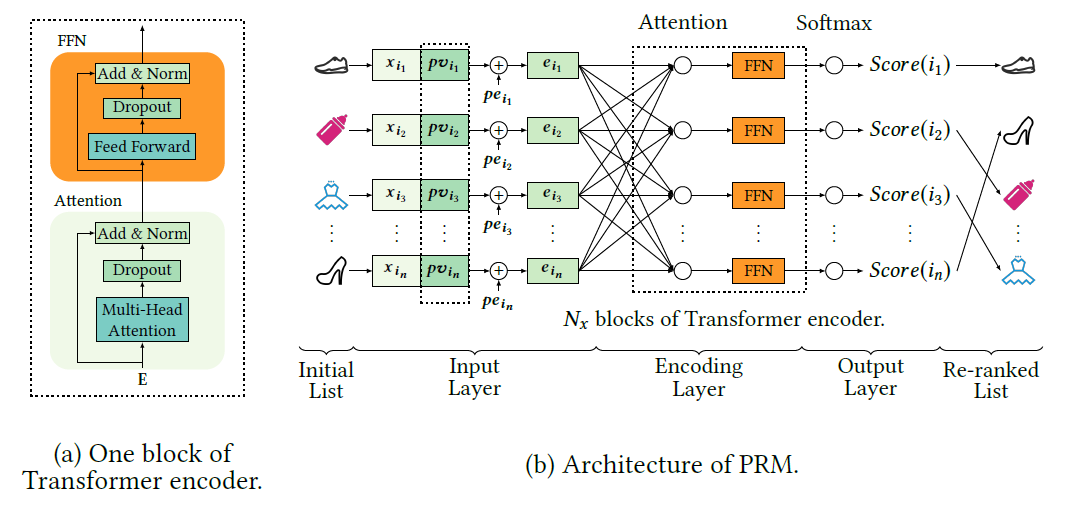
上图是阿里在商品重排环节提出的《Personalized Re-ranking for Recommendation》模型细节,其中输入层\(x_{i_n}\)和\(pv_{i_n}\)分别是原始商品的原始特征和个性化特征,\(pe_{i_n}\)是精排输出的排序位置特征;图中可以看出该模型的编码层采用多层Transformer编码层实现,再经过\(softmax\)输出重排后的打分。参考文章《Transformer 在美团搜索排序中的实践》也采用的同样的方式构建了商户重排环节,该文章同时还介绍了Transformer在特征构建的应用,感兴趣的读者可通过参考文章列表的链接查看。




深度学习模型的应用就简单介绍这么多,在具体应用上模型并不局限于召回或排序阶段,使用不同的采样方式、输出函数都可产生不同的结果,本质上是深度模型是为我们带来更多的交叉特征表征,挖掘除人工统计外的潜在特征交互关系,不可形成简单的思维定式认为某种模型只能用于解决某个问题。
深度模型对特征交叉的应用整体处于黑盒状态,可解释性差,这也是为什么算法工程师自嘲”炼丹”的原因。
搜索引擎评估方法
搜索引擎评价指标大体分为两个方面:效率和效果。效率方面与传统计算机系统评价方式类似,如考虑时间开销、空间开销、并发量及可靠性等,此处不做展开。效果评价针对搜索引擎属性,主要对搜索结果的质量进行量化评估,效果评价指标整体分为两方面:单条查询的效果评估和多条查询的平均效果评估。
单条查询的评价指标
-
准确率和召回率
准确率(Precision)也叫查准率,召回率(Recall)也叫查全率,在搜索引擎乃至机器学习中都是最常用,也是最受认可的指标。在搜索引擎中,准确率与召回率的定义如下
\[P = 检出的相关文档数 / 检出的全部文档数
\\
R = 检出的相关文档数 / 数据库中所有的相关文档数
\]假设数据库中某个Query的相关文档有\(60\)篇,单次检索得到\(50\)篇,其中\(40\)篇是Query相关文档、\(10\)篇是不相关文档,那么准确率等于\(40/50\),召回率等于\(40/60\)。
理想的搜索引擎\(P\)&\(R\)都应当等于\(1\),但实际上不存在这样的引擎,且\(P\)和\(R\)之间事实上存在一定反变关系,即一方提高另一方下降。如果追求过高的准确率,那么算法模型就需要更高的拟合度,导致相关度不明显或新文档无法被检索出来,即过拟合问题;如追求过高的召回率,模型就需要放松拟合度的要求,容易导致不相关的文档也被检出,即欠拟合问题。在生产环境中,优质的搜索引擎应当结合具体业务场景来决定应该偏重哪方面,垂域搜索引擎应当偏重准确率,保证领域信息检索的准确性;综述类的搜索引擎应当适当偏向召回率,保证信息能得到全面呈现。
追求高召回率就是”宁可错杀,绝不漏过”
-
F值
\(F\)值综合衡量准确率和召回率,定义为准确率和召回率的调和平均值,\(F\)值一般也称为\(F1\)值,计算公式如下
\[F1 = 2 * \frac{P*R} {P+R}
\]假如某个查询召回率是\(1\),准确率是\(0\),那么公式计算\(F1\)值为\(0\)。
为什么不直接计算\(PR\)的平均数?
如果采用算数平均数,那一个返回全部文档的搜索引擎都将有50%以上的分数。
-
Precision@N
不考虑召回率的情况下,\(Precision@N\)用于衡量截止到位置\(N\)的准确率,一般写作\(P@N\),由于用户比较关心排序靠前的搜索质量,最常用的指标如\(P@10\)、\(P@20\),即仅计算前\(10\)条、\(20\)条结果的准确率。

-
AP
平均正确率(Average Precision,AP):对不同召回率点上的准确率进行平均。
- 未插值的\(AP\):某个Query共有\(6\)个相关结果,某系统排序返回\(5\)篇相关文档,位置分别是\(1、2、5、10、20\),则\(AP=(1/1+2/2+3/5+4/10+5/20+0)/6\)
- 只对返回的相关文档计算\(AP\):如第一个例子,\(AP=(1/1+2/2+3/5+4/10+5/20)/5\)
- 插值的\(AP\):在召回率分别为\(0、0.1、0.2…1.0\)的十一个点上求的正确率均值
什么是插值
在搜索结果的不同位置上,准确率和召回率也是不同的,假如某个Query的标准答案是{\(d_3\),\(d_5\),\(d_9\),\(d_{25}\),\(d_{39}\),\(d_{44}\),\(d_{56}\),\(d_{71}\),\(d_{89}\),\(d_{123}\)},该Query的\(15\)条检索结果及对应未知的\(PR\)值分布如下:
1. \(d_{123}\) \(P = 1,R=0.1\) 6. \(d_9\) \(P = 0.5,R=0.3\) 11. \(d_{38}\) 2. \(d_{84}\) 7. \(d_{511}\) 12. \(d_{48}\) 3. \(d_{56}\) \(P = 0.67, R=0.2\) 8. \(d_{129}\) 13. \(d_{250}\) 4. \(d_6\) 9. \(d_{187}\) 14. \(d_{113}\) 5. \(d_8\) 10. \(d_{25}\) \(P=0.4, R=0.4\) 15. \(d_5\) \(P=0.33,R=0.5\) 根据上表绘制\(PR\)曲线如下图左:
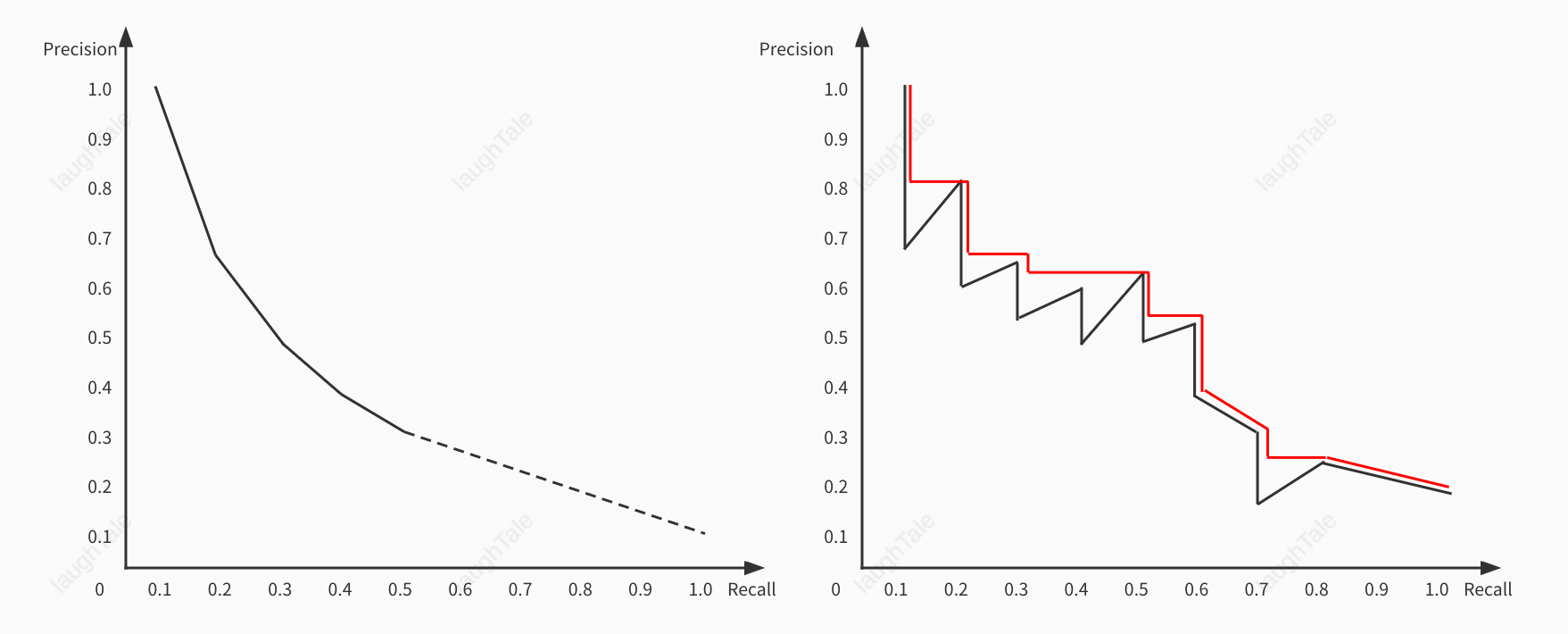
事实上\(PR\)曲线常常呈锯齿状,如上图右,因为假设第\(K+1\)篇文档不相关,那么位置\(K+1\)和\(K\)上的召回率相同、准确率降低,所以曲线会下降;如果\(K+1\)位置文档相关,那么准确率和召回率都会上升,因此整条曲线会呈现锯齿状。为了平滑曲线,采用插值准确率(interpolated precition)记录召回率为\(r\)的插值准确率
\[p_{interp}(r) = MAX_{r’ \geq r} p(r’)
\]表示为不小于\(r\)的召回率位置上准确率的最大值,即从当前召回率位置往右数可取得的最大准确率。
-
NDCG
每个文档不仅只有相关和不相关两种情况,而是有相关度的比如定义为0、1、2、3,我们希望在结果中相关度越高的文档越多、排位越靠前越好。\(NDCG\)(Normalized Discounted Cumulative Gain,归一化折损累计增益)用于表示位置在\(P\)处的搜索效果,通常也记做\(NDCG@P\),如\(NDCG@5、NDCG@10\)等。
\(i\) \(rel_i\) \(CG = \sum\limits_{i=1}^{p} rel_i\) \(log_2(i+1)\) \(DCG=\sum\limits_{i=1}^{p} \frac{rel_i}{log_2(i+1)}\) \(rel_{i理想}\) \(IDCG=\sum\limits_{i=1}^{p} \frac{rel_{i理想}}{log_2(i+1)}\) \(NDCG\) 1 3 3 1 3 3 3 1 2 2 3+2 1.58 3+1.26 3 3+1.89 0.87 3 3 3+2+3 2 3+1.26+1.5 3 3+1.89+1.5 0.90 4 0 3+2+3+0 2.32 3+1.26+1.5+0 2 3+1.89+1.5+0.86 0.79 5 1 3+2+3+0+1 2.58 3+1.26+1.5+0+0.38 2 3+1.89+1.5+0.86+0.77 0.76 6 2 3+2+3+0+1+2 2.8 3+1.26+1.5+0+0.38+0.71 1 3+1.89+1.5+0.86+0.77+0.35 0.81 假设某个Query有6个相关文档,相关度为\((3、3、3、2、2、1)\),实际搜索结果中得到5个相关文档,上表\(i\)列表示文档在搜索结果中的位置,\(rel_i\)表示实际文档结果的相关度,\(rel_{i理想}\)表示理想情况下前6个结果的文档相关度。
\(CG\)(Cumulative Gain,累计收益)表示搜索结果列表中所有文档的相关度得分总和,位置\(p\)的\(CG\)定义为:
\[CG_p = \sum\limits_{i=1}^{p} rel_i
\]\(DCG\)(Discounted cumulative gain,折损累计收益)提出在搜索结果列表的较低位置上出现相关性较高的文档时,应该对评测得分施加惩罚。惩罚比例与文档的所在位置的对数值相关,位置\(p\)的\(DCG\)定义为:
\[DCG_p=\sum\limits_{i=1}^{p} \frac{rel_i}{log_2(i+1)}
\]\(IDCG\)即理想的\(DCG\)值,取\(rel_{i理想}\)列代入公式进行计算,再使\(DCG\)除以\(IDCG\)就得到\(NDCG\)。
\[NDCG_p=\frac{DCG_p}{IDCG_p}
\]\(DCG\)还有一种广泛的计算公式为\(DCG=\sum\limits_{i=1}^{p} \frac{2^{rel_i} – 1}{log_2(i+1)}\),增强相关度在效果评估中的影响。

多条查询的评价指标
-
MAP
MAP(Mean Average Precision):对所有查询的\(AP\)求算数平均,如Query1有\(4\)个相关文档,Query2有\(5\)个相关文档,Query1检索出\(4\)个相关文档位置分别为\(1、2、4、7\),Query2检索出\(3\)个相关文档位置为\(1、3、5\),那么Query1的平均准确率\(AP=(1/1+2/2+3/4+4/7)/4=0.83\),Query2的\(AP=(1/1+2/3+3/5+0+0)/5=0.45\),则\(MAP=(0.83+0.45)/2=0.64\)。
-
MMR
MMR(Mean Reciprocal Rank):对于某些IR系统(如问答系统或主页发现系统),只关心第一个标注答案的位置,这个位置的倒数称为\(RR\),对问题集合求平均即得到\(MRR\)。例如两个Query,系统对第一个Query返回的正确答案位置为\(2\),第二个Query答案位置为\(4\),那么\(MRR=(1/2+1/4)/2=3/8\)。
总结
搜索引擎是一个结合了多种工程技术和算法模型的系统,本文仅对搜索引擎的整体组成和技术范围做了概况性介绍,其中每个技术点都可以展开作单独的文章阐述,受限于篇幅和个人粗浅认知,文章不对各个技术细节做深入解析,感兴趣的读者可进一步阅读参考列表中的文章,如文中存在观点错误,欢迎在评论区指出。
参考
- 《智能搜索和推荐系统:原理、算法与应用》
- 《走进搜索引擎》
- 搜索引擎
- What Is A Search Engine
- Types of Search Engine
- 与技术有关:关于搜索引擎索引的这些概念
- 向量检索算法
- 全面理解搜索Query:当你在搜索引擎中敲下回车后,发生了什么
- Query 理解和语义召回在知乎搜索中的应用
- DeepNLP的表示学习·词嵌入来龙去脉·深度学习(Deep Learning)·自然语言处理(NLP)·表示(Representation)
- BERT在美团搜索核心排序的探索和实践
- 用Bert做语义相似度匹配任务:计算相似度的方式
- 知乎搜索排序模型的演进
- 策略算法工程师之路-排序模型LTR及应用
- LTR精排序笔记整理
- 如何理解FM、FFM
- 深入FFM原理和实践
- 阿里粗排技术体系与最新进展分享
- 粗排扮演的角色和算法发展历程
- 推荐系统技术演进趋势:从召回到排序再到重排
- 图解Transformer
- LTR中Transformer的应用
- Transformer 在美团搜索排序中的实践
- 信息检索中的各项评价指标
- Ranking算法评测指标之CG、DCG、NDCG

