深入理解和运用Pandas的GroupBy机制——理解篇
GroupBy是Pandas提供的强大的数据聚合处理机制,可以对大量级的多维数据进行透视,同时GroupBy还提供强大的apply函数,使得在多维数据中应用复杂函数得到复杂结果成为可能(这也是个人认为在实际业务分析中,数据量没那么大的情况下,Pandas相较于Excel透视表最有优势的一点)。
也正是因为它如此强大,所以对于很多初涉猎这部分内容的学习者来说,深入理解并熟练掌握GroupBy机制的运用有些困难,这篇文章力求基于我对“老鼠书”的理解,对GroupBy机制做一个初步的梳理。
本文是机制上的理解篇,代码层面的运用会在运用篇中涉及。
# GroupBy使用的三种基本形式,先看看,结合后面的梳理一起有助于理解 #1 data.groupby([分组键1,分组键2……]).函数 #2 data.groupby([分组键1,分组键2……]).agg(参数) #3 data.groupby([分组键1,分组键2……]).apply(参数)
深入理解GroupBy机制的底层逻辑:“分拆-应用-聚合”
先说结论:(1)“分拆-应用-聚合”是GroupBy机制的核心,其中“应用”又是整个流程的核心;(2)理解“应用”的关键在于,脑子里要有对于分拆之后一个个小group的抽象印象。
1、分拆
- 分拆:之所以叫GroupBy,正是因为有“Group”这个概念。我们用到Group,是因为需要按某个属性(字段)将数据区分为不同的Group,这个属性,我们通常称之为“分组键”,对每个Group进行操作(如 求和、求平均),否则直接对整个数据集进行操作就好,干嘛要麻烦到用GroupBy呢?
比如公司到年终要给表现最好的部门发激励,就需要计算不同部门今年的总收益,这时“部门”就是我们的“分组键”,不同的部门及其每个员工的收益就构成了一个个小的group。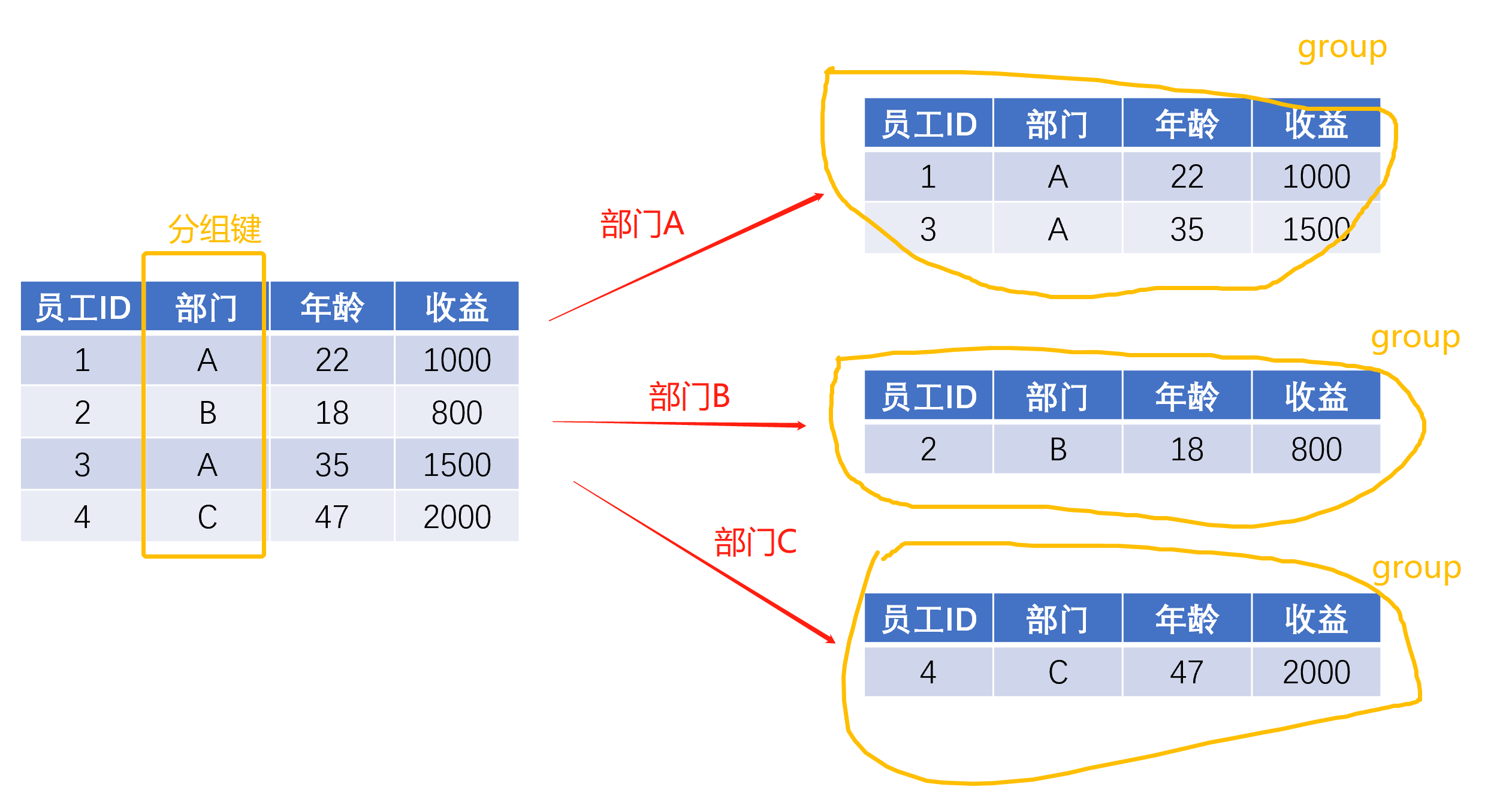
抽象理解的话,代码中的前半部分,也就是data.groupby([分组键1,分组键2……]),所起到的作用就是将原数据集data按照你传入的分组键,切分为一个一个小小的group,每一个group都是原数据集的子集。
当看到data.groupby([分组键1,分组键2……])时,你可以理解为:“分拆”的步骤已经执行好啦,现在我们已经有了一个个小的group(在pandas中,data.groupby([分组键1,分组键2……])返回的是一个grouped对象)。
2、应用
- 应用:将数据切分为不同的Group并不是最终的目的,我们的目标是针对每个小的group执行一个操作,得到一个结果,这个过程就是”应用”,也是整个GroupBy中最复杂、发挥coder聪明才智的空间最大的部分。这里的操作:
- 可以是最简单的描述性统计和汇总统计,比如 求和、求最大值、求最小值、求平均,得到的结果通常是一个标量值,也就是一个数。
- 还可以加入略复杂的要求,比如 同时返回每组最大值和最小值,得到的结果可以是一个Series / 列表 / 字典 / DataFrame / 甚至是任意你定义的对象类型了,在“运用篇”中我们会介绍一些看起来颇为复杂的操作。
继续前面公司年终发奖励的例子,老板提出了以下要求:(1)看看每个部门的总收益;(2)想看看每个部门的平均年龄和人均收益。
对于总收益,每个部门只返回一个数字就可以了,但是平均年龄和人均收益,对于每个部门来说,这两个数字构成的就是一个列表或者一个Series了。很多初学者往往就卡着这个地方,我个人认为还是对groupby的抽象理解不够。
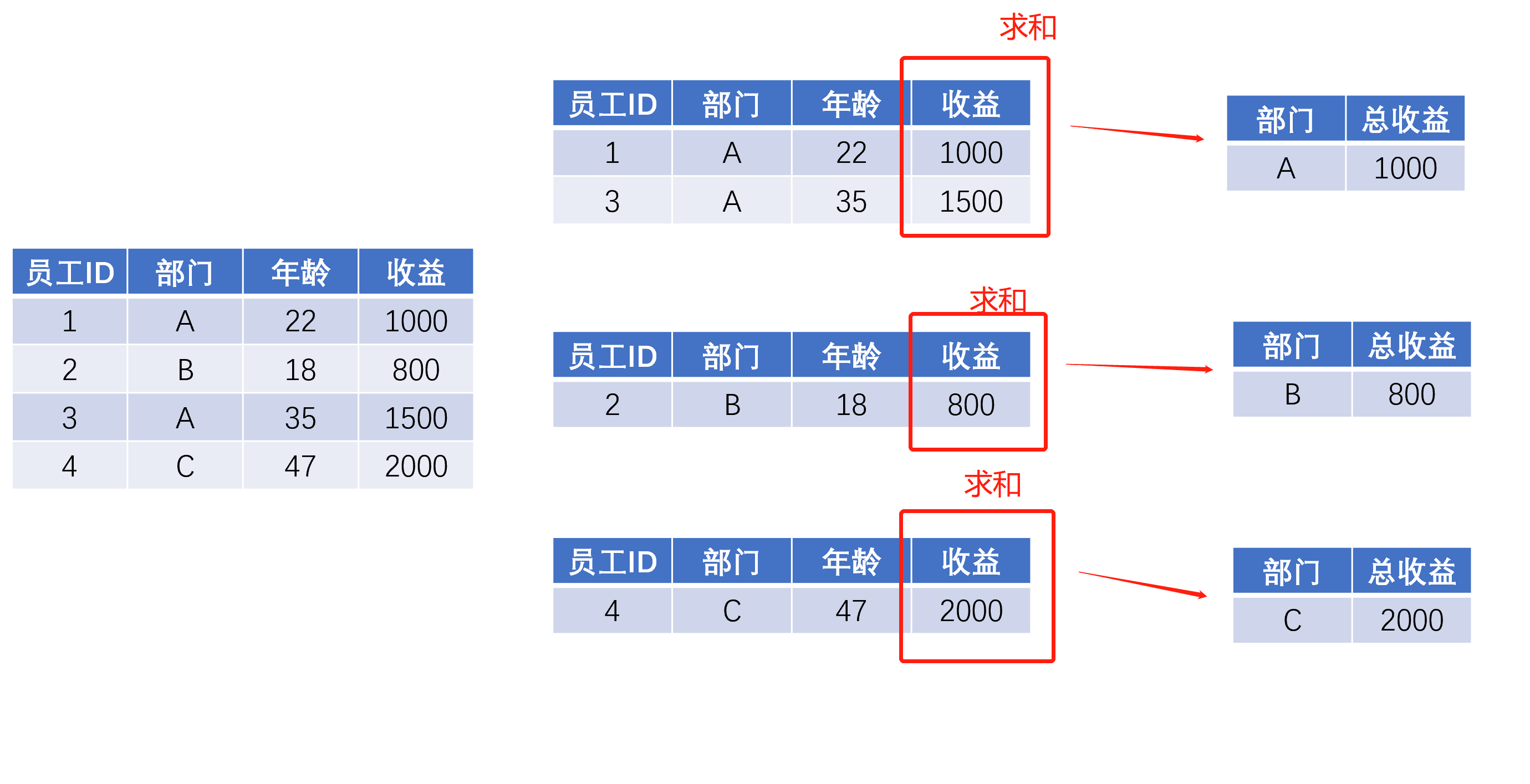
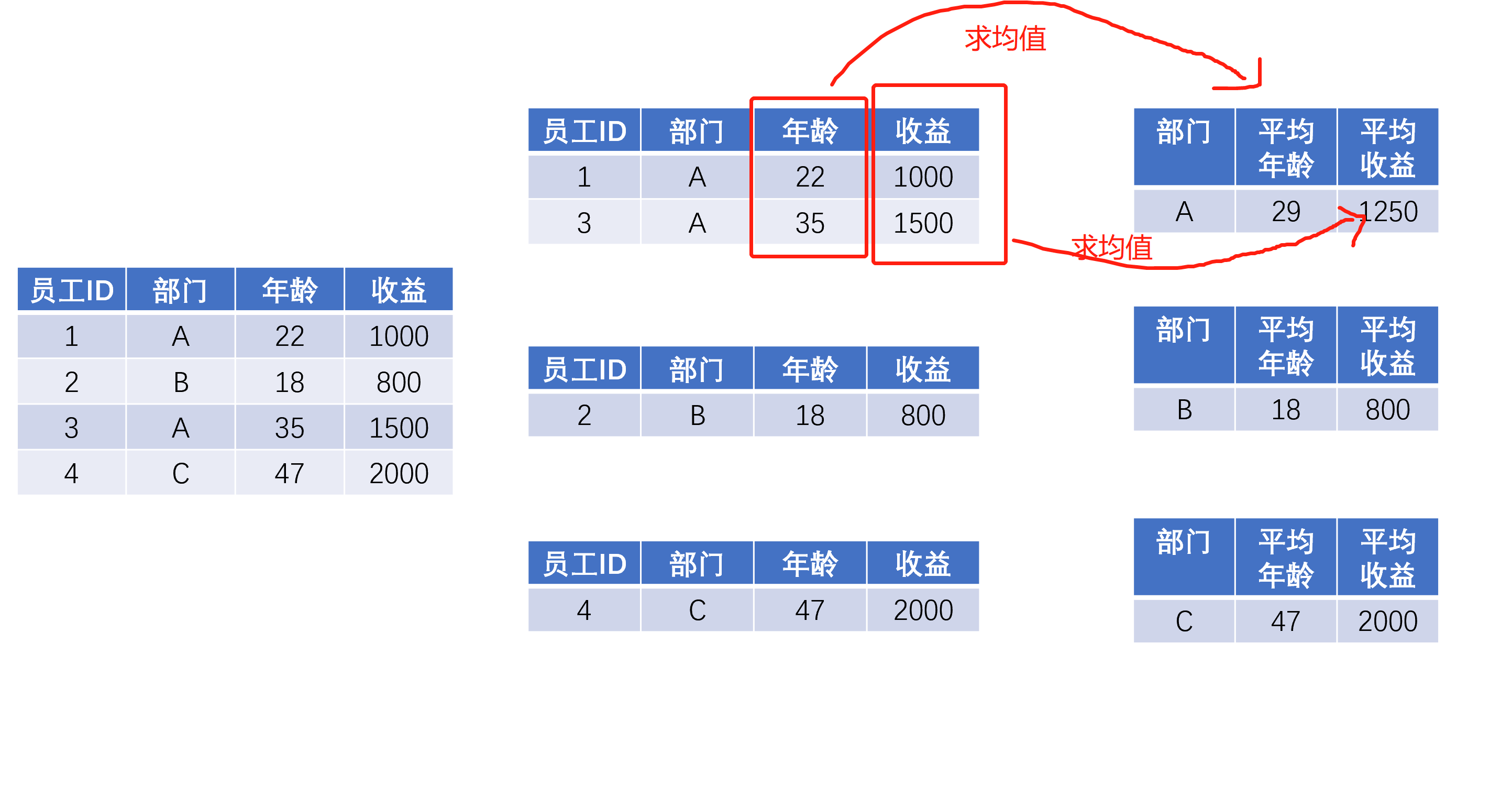
对“应用”操作的理解,如果脑子里有这么一个小group的集合,运用的难度会小很多,同时我们可以发现一些对“分拆”步骤的更深层次理解,能帮助我们更好地掌握“应用”:
- 分拆后的小group的列(columns)和原数据集是一样的;
- 分拆后的小group的分组键对应的列的值都是相等的,比如 第一个小group里面,部门都是A;第二个则部门都是B
- 分拆形成的小group的个数,取决于原数据集中分组键对应的列的值去重后的个数,比如 上图中 原数据集中有4个数据,但是只有A、B、C 3个部门,所以最终拆出来的小group就有3个。
3、聚合
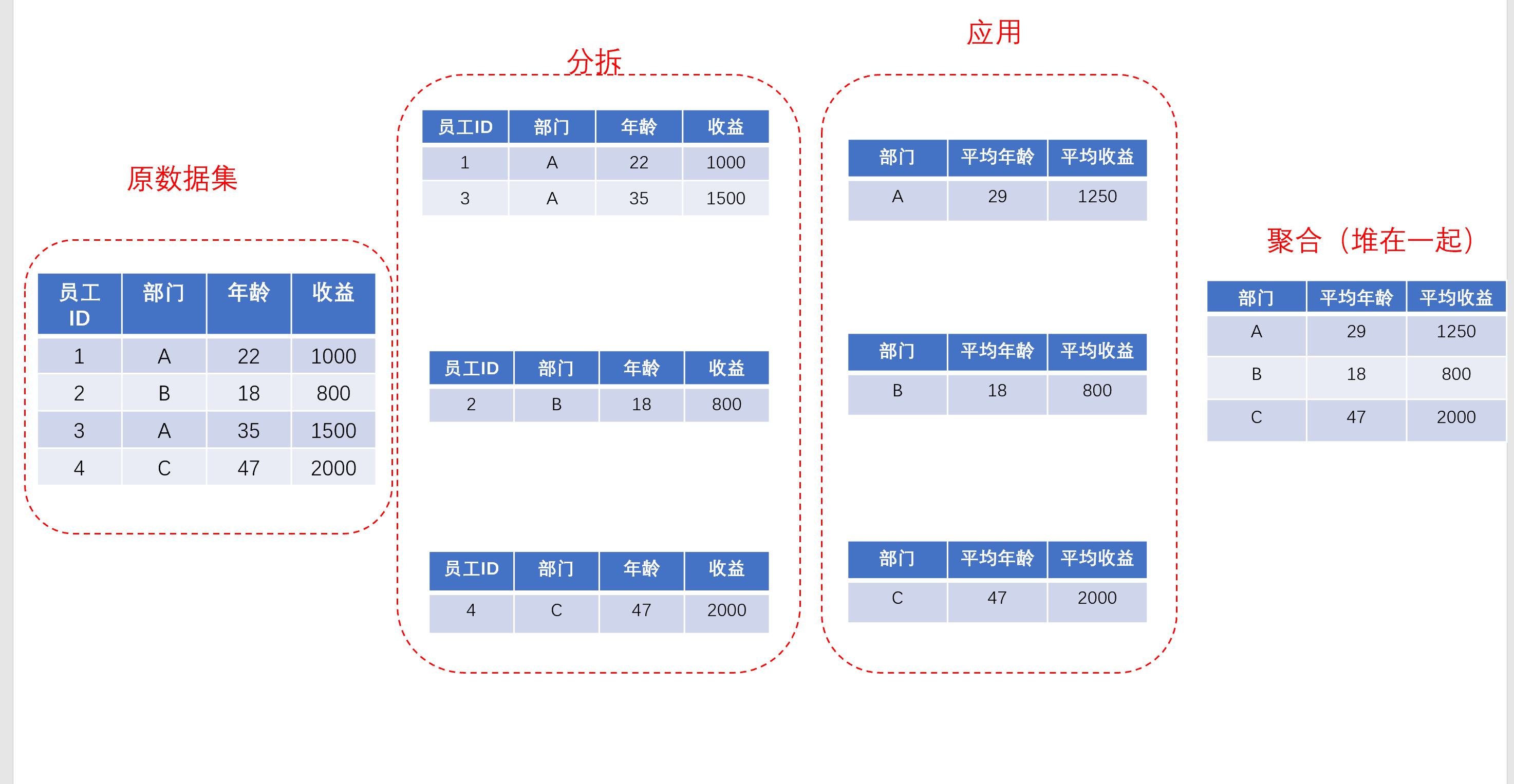
- 聚合:聚合相对来说比较好理解一些了,从前面的图中我们可以看到,“应用”是对每一个小group执行了一种或简单或复杂的操作,但是不可能就这么返回给你,所以需要把这些数据给聚合起来,构成一个可读性更高的数据形式给你。
简单来说,你可以认为,在这里,pandas对“应用”完成后的每个小group的操作结果,做了一个concat,也就是轴向上的聚合,也就是从上到下把他们像“堆俄罗斯方块”一样堆起来(如果不熟悉pd.concat,先回去复习下吧~)
在pandas中,堆叠起来的数据要么是Series,要么是DataFrame,也就是说,无论中间对每个小group的操作操作有多复杂,最后返回的结果无外乎就是Series和DataFrame,对于做数据处理的我们还是颇为友好的。
总结
总结一下,从抽象的“道”层面,在不涉及具体代码的情况下,我们去理解groupby主要是通过“分拆-应用-聚合”三个环节。
在最开始使用groupby的时候,每次能够先在脑海中将这三个环节模拟一遍,能够帮助你更快速地掌握“术”层面的代码语法;
在这三个环节中,最重要的是应用环节,而应用环节的关键在于,你要能清楚的感知到你要处理的一个个小的group是什么样子的;其次是分拆环节,分拆环节是源头,而且在实际应用的过程中还涉及到多种多样的生成分组键的方式,对于初学者来说也很容易头皮发麻;最后是聚合,像俄罗斯方块一样(准确的来说就是pd.concat)把每一个小group的结果堆起来。
理解篇就先到这里,咱们运用篇再见~~~


