Spark比MR快是因为在内存中计算?错!
- 2019 年 10 月 3 日
- 筆記
MapReduce 就像一台又慢又稳的老爷车,虽然距离 MapReduce 面市到现在已经过去了十几年的时间,但它始终没有被淘汰,任由大数据技术日新月异、蓬蓬勃勃、花里胡哨地发展,这个生态圈始终有它的一席之地。
不过 Spark 的到来确实给了 MapReduce 不小的冲击,它比 MapReduce 理论上要快两个数量级,所以近几年不断有人讨论 Spark 是否可以完全替代 MapReduce ,但是为什么说是不断有人讨论呢?因为这些年 Spark 始终是无法完全取代 MapReduce 。
我们今天关注的问题是Spark为什么比 MapReduce 快?如果没有看文章的标题,你是不是会脱口而出:
“因为 Spark 是在内存中计算,而 MapReduce 是基于磁盘。”
这话乍一听没毛病,但是作为一个对技术很严谨的人,这让我忍不住想杠一下,
“那么 MapReduce 计算的时候不需要把数据加载到内存,在内存中计算吗?”
其实要对数据做计算,必然得把数据加载到内存, MapReduce 也不例外,Spark只是在计算模型和调度上做了更多的优化,不需要过多地和磁盘交互。
说到这里不得不提的就是 Spark 的 DAG(有向无环图),这个 DAG 就相当于改进版的 MapReduce,它可以说是由多个 MapReduce 组成,当数据处理流程中存在多个map和多个Reduce操作混合执行时,MapReduce只能提交多个Job执行,而Spark可以只提交一次,在一个任务中完成。
这就导致了 MapReduce 会存在多次耗时的资源申请和资源释放,另外 MapReduce 每次shuffle 操作后,必须写到磁盘,而 Spark 在 shuffle 后不一定落盘,如果Shuffle后的数据是需要反复用到的,则可以cache到内存中,方便迭代时使用,所以Spark对于需要对数据进行反复迭代的操作(比如跑机器学习算法或者有中间结果的复杂计算等)是非常友好的。
这里还有一个误区,很多人会认为 Spark 在计算时的所有过程都是在内存中完成的不用写磁盘,但是实际上不是这样的,在 shuffle 过程中 Spark 同样需要写磁盘,研究过 Sorted-Based Shuffle 的同学对这个写盘操作一定不陌生,如下图。
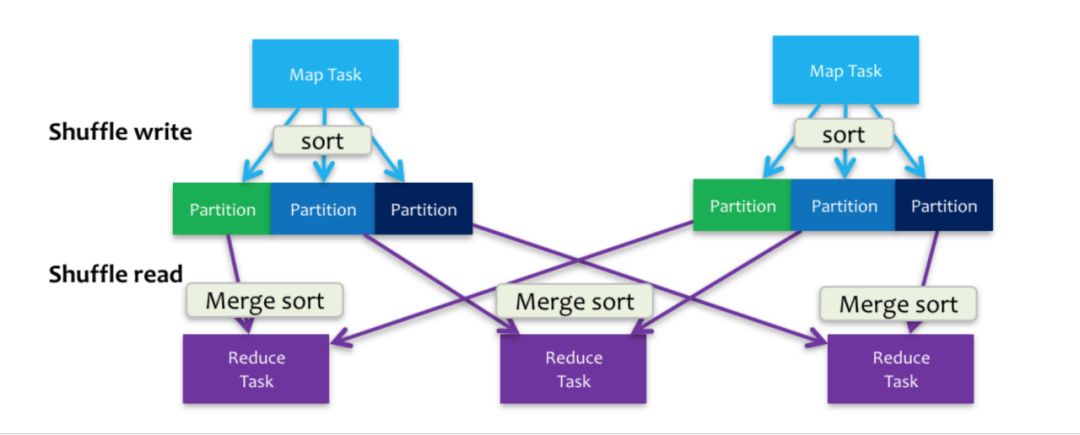
简单地说下,shuffle分成write和read两个阶段,write的过程不仅会写需要发向下一个Stage的数据到磁盘,还需要写一份数据的Index记录下游每个分区获取的数据范围。这里就不详细说了,有兴趣的同学可以去研究下。

另外,刚才提到了Spark尽管比MapReduce快两个数量级但是它始终没有被淘汰,这是因为它在每个阶段都落盘,虽然慢但是可以保证计算过程的稳定性,不会像Spark一样,一旦中间结果太大,内存装不下整个计算任务就崩了,这对于不讲究时效性的后台任务来说无疑是增加了维护成本,所以现在构建数据仓库的主要SQL工具还是Hive(Hive的底层是MapReduce),你见过用SparkSQL来跑数据量大的数仓任务的吗?
看完这篇,希望下次有人问你 Spark 为什么比 MapReduce 快的时候不要再说 Spark 在内存中计算了。
觉得有价值请关注 ▼

