日常问题排查-调用超时
日常问题排查-调用超时
前言
日常Bug排查系列都是一些简单Bug排查,笔者将在这里介绍一些排查Bug的简单技巧,同时顺便积累素材_。
Bug现场
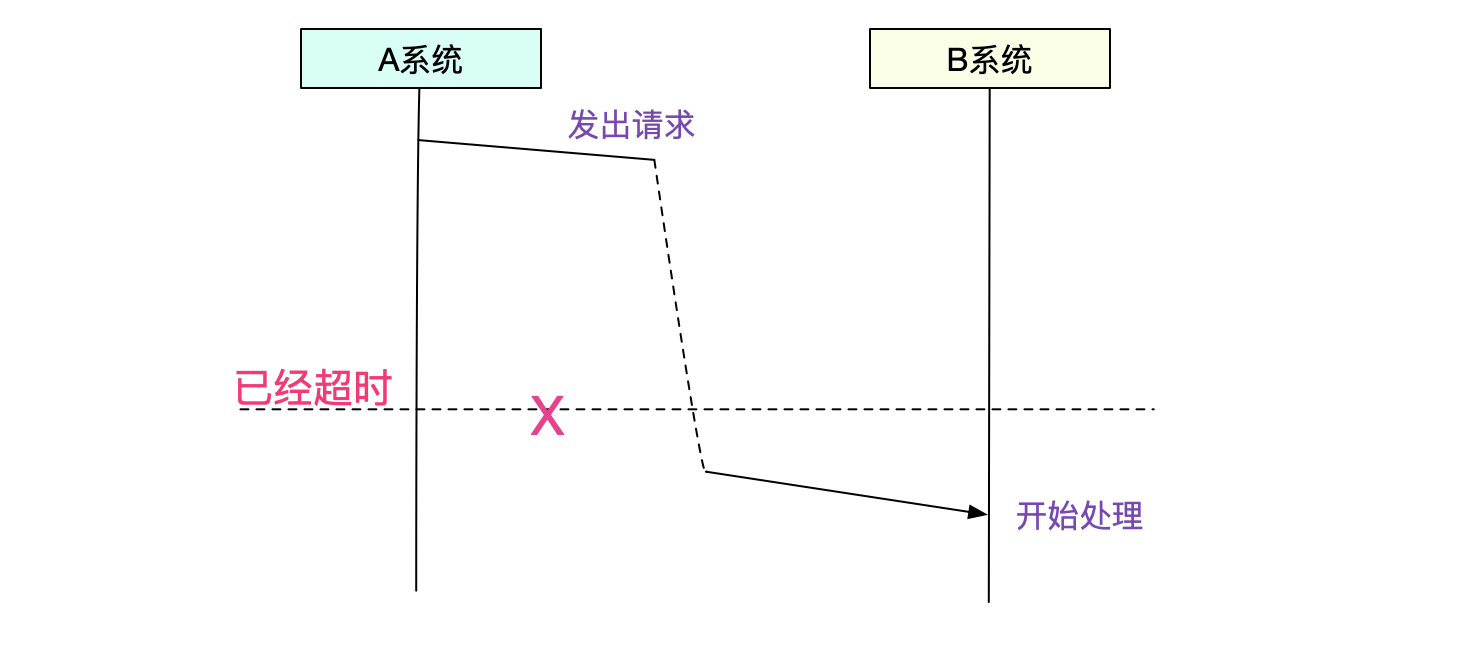
这次的Bug是大家喜闻乐见的调用超时。即A调用B超过了5s

搜索一下日志,发现A系统在发出5s后超时。B系统在将近8s后才收到请求,也就是说B系统还没开始处理,A系统就超时了。
开始排查
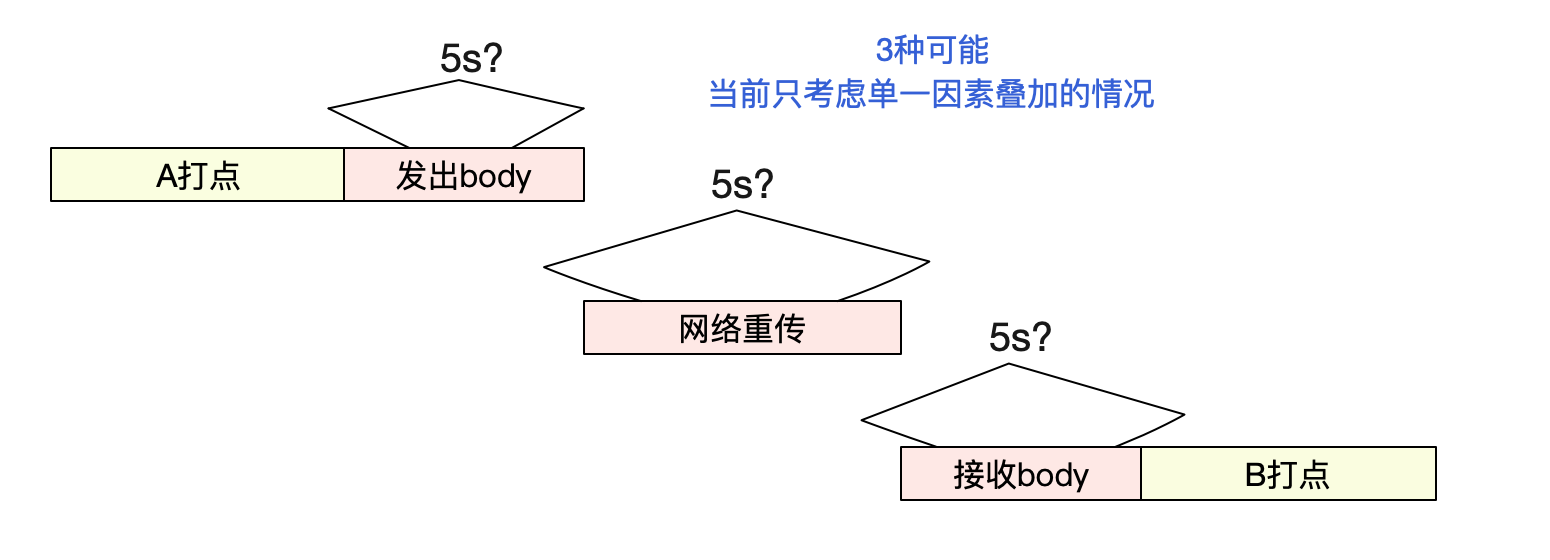
那么这5秒钟时间到底消失在哪里呢?有3个可能的点:
1)A日志打点到真正发出请求包
2)网络上
3)B真正接收请求包到B日志打点。
网络check
首先笔者检查了当时此机器的Net Traffic,发现非常平稳,考虑不是网络的锅。
Full GC
对于Java应用,第二个考虑的点应该是GC,毕竟是Stop The World!笔者于是翻了下对应
A/B系统两台
发现A系统okay,B系统在当时有Full GC,而且长达6s:
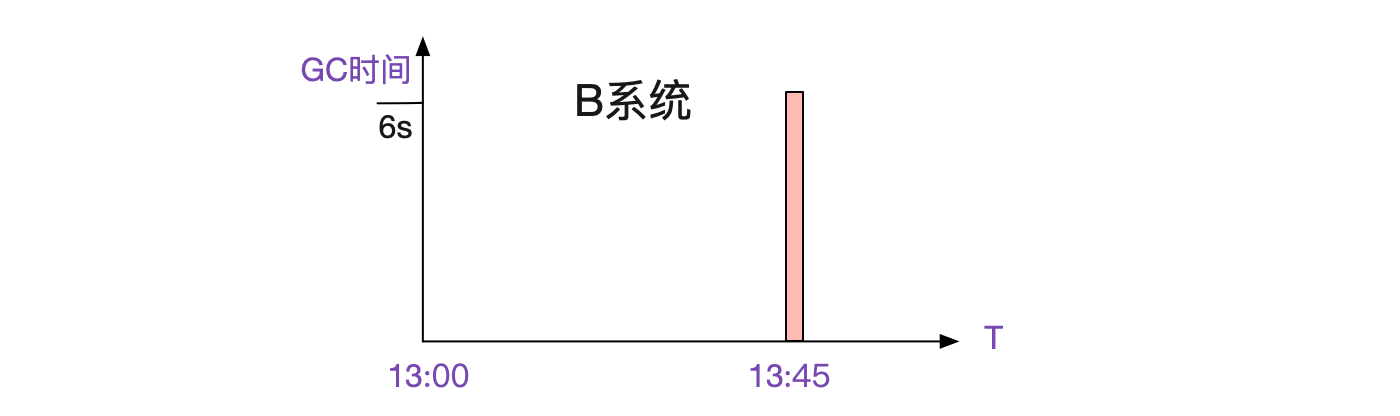
既然监控到了,那么问题基本就是B系统的Full GC了,这个长达6s的full gc让B系统5s后才打印出请求。可是这又引入了一个新的问题,为什么一次Full GC能达到6s之巨。
为什么这么慢
观察监控,笔者发现Full GC有时候快有时候慢。翻出对应6s的那条gc监控日志。
B系统
[Full GC(Metadata GC Thresold) ...... (class unloading,5.5285249 secs]......[Times: user=0.85 sys=0.07 real=6.26 secs]
class unloading...
发现class unloading竟然会有将近5s。再进一步用awk过滤,最高有10s的,最短有0.1s的,而他们回收的内存大小确差不多。正常Full GC应该不会有这么久,那个0.1s才感觉是正常的,难道当时机器有什么事情发生?带着疑问,笔者继续观察监控曲线,看看能不能找到些蛛丝马迹,找到当时的时间点,发现:

GC慢的时候,对应机器内存的swap in很高。紧接着找了其它慢的Full GC。发现非常有规律,只要swap in很高Full GC就慢!
于是笔者,就尝试着搜索了一下
//blogs.oracle.com/poonam/long-class-unloading-pauses-with-jdk8
发现,官方也发现了这个问题,并给予了解释。
为什么会有swap
实际上对应机器的内存使用率并不高,一共8G的内存,JVM只占用到了4G左右。但swap的逻辑并仅仅是内存吃紧了才使用swap分区。如果有一块内存长期不用,也有可能被交换到swap分区。
例如,JVM的class信息,如果一个class MetaData仅仅是存在那里,并不被用到的话。
可能被kernel扔到swap里面。但这时候在GC可达性分析的时候,又会去访问这个MetaData信息,就导致虽然内存利用率不高,但依旧发生使用swap导致慢的情况!
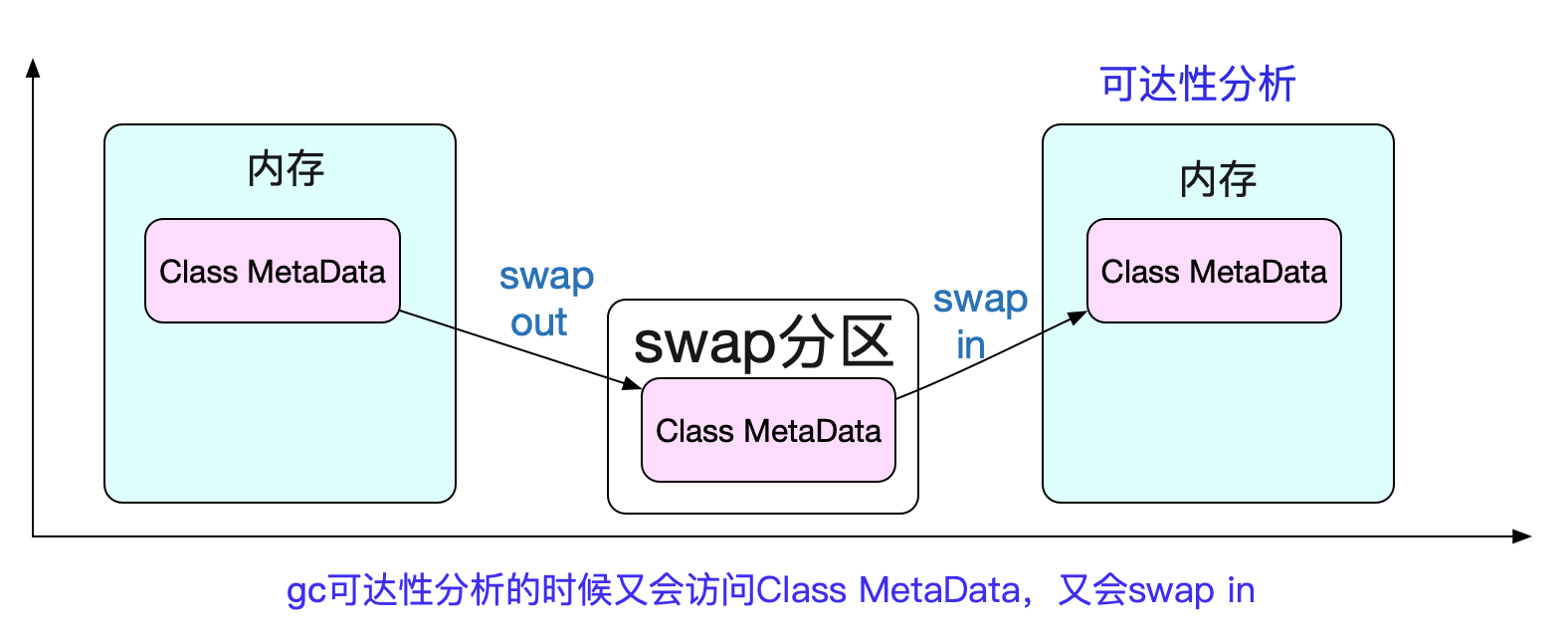
但是swap里面到底是什么内容,是不是和jvm相关就很难知晓了。所以看上去是概率上出现GC慢的问题。
另一个机房没出问题
这时候巧的是,业务开发向笔者反映,另一个机房的相同应用确不会出现此问题。捞了下对应日志,发现其class unloading只有0.9s左右。笔者观察了下,发现另一个机房的机器并没有用swap。于是笔者比较了一下两个机房关于swap相关的内核参数:
GC慢机器 cat /proc/sys/vm/swappiness 60
GC正常机器 cat /proc/sys/vm/swappiness 1
发现我们新建机房的,我们SA已经预先把swappiness调成了1,意思是告诉kernel尽量不要使用swap,这样就不会有这种swap导致的坑爹问题了。
总结
对于非内存瓶颈的应用,我们应该基于实际情况决定是否把swap禁用掉,以免因swap造成卡顿!另外,
对于一个偶发性的问题,我们应该通过监控等手段去寻找规律,这样就很容易找到突破点。


