ZooKeeper学习之集群搭建
- 2019 年 10 月 3 日
- 筆記
本篇由鄙人学习ZooKeeper亲自整理的一些资料
包括:ZooKeeper的介绍,我们要学习ZooKeeper的话,首先就要知道他是干嘛的对吧.
其次教大家如何去安装这个精巧的智慧品!
相信你能研究到ZooKeeper一定也会对Linux有一定了解了吧!
下面的介绍内容全部经过精心整理,内容会很枯燥,但是一定要坚持看一遍,大概心中有个印象,要接下来的学习里面,根本不会理解是做什么的!!理论的东西也是非常重要的,因为学习是个沉淀的过程…
start…
ZooKeeper原理篇
一、 ZooKeeper 简介
顾名思义 zookeeper 就是动物园管理员,他是用来管 hadoop(大象)、Hive(蜜蜂)、pig(小
猪)的管理员, Apache Hbase 和 Apache Solr 的分布式集群都用到了 zookeeper;Zookeeper:
是一个分布式的、开源的程序协调服务,是 hadoop 项目下的一个子项目。它提供的主要功能包括:配置管理、名字服务、分布式锁、集群管理
二、ZooKeeper的作用
1.1配置管理
在我们的应用中除了代码外,还有一些就是各种配置。比如数据库连接等。一般我们都
是使用配置文件的方式,在代码中引入这些配置文件。当我们只有一种配置,只有一台服务
器,并且不经常修改的时候,使用配置文件是一个很好的做法,但是如果我们配置非常多,
有很多服务器都需要这个配置,这时使用配置文件就不是个好主意了。这个时候往往需要寻
找一种集中管理配置的方法,我们在这个集中的地方修改了配置,所有对这个配置感兴趣的
都可以获得变更。Zookeeper 就是这种服务,它使用 Zab 这种一致性协议来提供一致性。现
在有很多开源项目使用 Zookeeper 来维护配置,比如在 HBase 中,客户端就是连接一个
Zookeeper,获得必要的 HBase 集群的配置信息,然后才可以进一步操作。还有在开源的消
息队列 Kafka 中,也使用 Zookeeper来维护 broker 的信息。在 Alibaba 开源的 SOA 框架 Dubbo中也广泛的使用 Zookeeper 管理一些配置来实现服务治理
1.2名字服务
名字服务这个就很好理解了。比如为了通过网络访问一个系统,我们得知道对方的 IP
地址,但是 IP 地址对人非常不友好,这个时候我们就需要使用域名来访问。但是计算机是
不能是域名的。怎么办呢?如果我们每台机器里都备有一份域名到 IP 地址的映射,这个倒
是能解决一部分问题,但是如果域名对应的 IP 发生变化了又该怎么办呢?于是我们有了
DNS 这个东西。我们只需要访问一个大家熟知的(known)的点,它就会告诉你这个域名对应
的 IP 是什么。在我们的应用中也会存在很多这类问题,特别是在我们的服务特别多的时候,
如果我们在本地保存服务的地址的时候将非常不方便,但是如果我们只需要访问一个大家都
熟知的访问点,这里提供统一的入口,那么维护起来将方便得多了。
1.3分布式锁
其实在第一篇文章中已经介绍了 Zookeeper 是一个分布式协调服务。这样我们就可以利
用 Zookeeper 来协调多个分布式进程之间的活动。比如在一个分布式环境中,为了提高可靠
性,我们的集群的每台服务器上都部署着同样的服务。但是,一件事情如果集群中的每个服
务器都进行的话,那相互之间就要协调,编程起来将非常复杂。而如果我们只让一个服务进
行操作,那又存在单点。通常还有一种做法就是使用分布式锁,在某个时刻只让一个服务去
干活,当这台服务出问题的时候锁释放,立即 fail over 到另外的服务。这在很多分布式系统
中都是这么做,这种设计有一个更好听的名字叫 Leader Election(leader 选举)。比如 HBase
的 Master 就是采用这种机制。但要注意的是分布式锁跟同一个进程的锁还是有区别的,所
以使用的时候要比同一个进程里的锁更谨慎的使用。
1.4集群管理
在分布式的集群中,经常会由于各种原因,比如硬件故障,软件故障,网络问题,有些
节点会进进出出。有新的节点加入进来,也有老的节点退出集群。这个时候,集群中其他机
器需要感知到这种变化,然后根据这种变化做出对应的决策。比如我们是一个分布式存储系
统,有一个中央控制节点负责存储的分配,当有新的存储进来的时候我们要根据现在集群目
前的状态来分配存储节点。这个时候我们就需要动态感知到集群目前的状态。还有,比如一
个分布式的 SOA 架构中,服务是一个集群提供的,当消费者访问某个服务时,就需要采用
某种机制发现现在有哪些节点可以提供该服务(这也称之为服务发现,比如 Alibaba 开源的
SOA 框架 Dubbo 就采用了 Zookeeper 作为服务发现的底层机制)。还有开源的 Kafka 队列就
采用了 Zookeeper 作为 Cosnumer 的上下线管理。
三、ZooKeeper存储结构
下面用图文的形式在表示下:
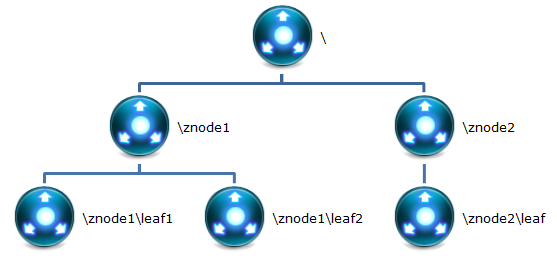
1 Znode
在 Zookeeper 中,znode 是一个跟 Unix 文件系统路径相似的节点,可以往这个节点存储
或获取数据。
Zookeeper 底层是一套数据结构。这个存储结构是一个树形结构,其上的每一个节点,
我们称之为“znode”
zookeeper 中的数据是按照“树”结构进行存储的。而且 znode 节点还分为 4 中不同的类
型。
每一个 znode 默认能够存储 1MB 的数据(对于记录状态性质的数据来说,够了)
可以使用 zkCli 命令,登录到 zookeeper 上,并通过 ls、create、delete、get、set 等命令
操作这些 znode 节点
2 Znode节点类型
(1)PERSISTENT 持久化节点:所谓持久化节点,是指在节点创建后,就会一直存在,诉我诶的保存到了Hard Disk硬盘当中,直到有删除的操作来主动清除这个节点。苟泽不会因为创建该节点的客户端会话失效而消失
(2)PERSISTENT_SEQUENTIAL 持久化顺序节点:这类节点的基本特性和上面的节PERSISTENT类型一致。额外的特性是,在ZK中,每个节点会为他的第一季子节点维护一份时序,会记录每个子节点的创建的先后顺序。基于这个特性,在创建子节点的时候,可以设置这个属性,那么在创建节点的过程中,ZK会自动给节点名加上一个数字的后缀,作为新的节点名。这个数字后缀的范围是整数型的最大值,树的每个分支的后缀都会重新开始计算,也就是从0开始,。在创建节点的时候只需要传入节点“/leaf_”,这样之后,zookeeper自动会给leaf_后面补充数字
(3)EPHEMERAL临时节点:和持久节点不同的是,临时节点的声明周期和客户端会话绑定。也就是说,如果客户端的会话失效,退出本次的会话,那么这个节点就会被清除掉。注意:这里提到的是会话失效,而非连接断开。另外,是不能在临时节点下面创建子节点的
这里还需要注意的一件事,就是当你客户端会话失效后,所产生的的节点也不是一下子就是小了,也需要过一段时间,大概是10秒钟以内,可以尝试,本机操作生成节点,在服务器端用命令来查看当前的节点数目,会发现,客户端已经stop,但是产生的节点还在。
(4)EPHEMERAL_SEQUENTIAL 临时自动编号节点:此节点是属于临时节点,不过带有顺序,客户端会话结束节点就消失
ZooKeeper环境搭建篇
考虑到大家初学者,肯定不会去装好几台虚拟机,所以我们就以单台虚拟机作为测试环境简称:伪集群
看不懂?没关系,后面慢慢来跟着敲
首先准备环境:
Linux
–JDK
–ZooKeeper(ZooKeeper自己百度去下载一下就好了,我这里用的为3.4.6版本)
1 单机环境安装ZooKeeper
首选解压的你ZooKeeper并复制到一个目录上(并无大碍,解压即可)
[root@localhost temp]# tar -zxf zookeeper-3.4.6.tar.gz [root@localhost temp]# cp zookeeper-3.4.6 /usr/local/zookeeper -r
1.1ZooKeeper的目录结构
bin:防止运行脚本和工具脚本,如果是Linux环境还会有zookeeper的运行日志zookeeper.out
conf:zookeeper默认读取配置的目录,里面会有默认的配置文件
contrib:zookeeper的扩展功能
dist-maven:zookeeper的mavnen打包目录
docs:zookeeper相关的文档
lib:zookeeper核心jar
recipes:zookeeper分布式相关的jar包
src:zookeeper源码
1.2配置ZooKeeper
注意:*大概扫一眼整个步骤字后再来做!!以免你懂得*
Zookeeper在启动的时候默认去他的conf目录下查找一个名称为zoo.crf的配置文件,
在zookeeper应用目录中有子目录conf,其中配置文件模板:zoo_sample.cfg
我们可以cp zoo_sample.cfg zoo.cfg 这样就复制了一份所需要的zoo.cfg,
因为zookeeper启动需要用到配置文件为conf/zoo.cfg,
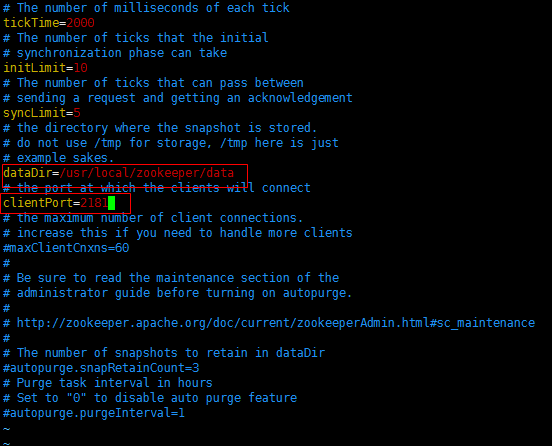
接下来修改文件zoo.cfg 设置数据缓存路径dataDir
数据缓存目录我们可以随意创建,我这里边就创建到了zookeeper的子目录中data
clientPort为zookeeper的监听端口,可以随意改动所需要且没有被占用的端口,一般默认即可
1.3 启动ZooKeeper
没错就是这么简单,你现在已经可以启动ZooKeeper啦!
启动文件在Zookeeper的bin目录下面
默认加载配置文件(zoo.cfg): ./zkServer.sh start:默认回去conf目录下加载zoo.cfg配置文件
指定加载配置文件: ./zkServer.sh start 配置文件的路径,这样就不会使用默认的conf/zoo.cfg.
注意:我们下边要安装集群,那么首先要关闭这个ZooKeeper,否则占用端口!
./zkServer.sh stop关闭即可
2 ZooKeeper集群环境搭建(伪集群)
前方高能:首先我们又要来了解下原理性的东西了!!
2.1 Zookeeper集群中的角色
共分为下面的三大类
领导者、学习者、客户端


2.2设计的目的
1.最终一致性:client不论连接到哪个Server,展示给它的都是同一个视图,这是Zookeeper最重要的特性
2.可靠性:具有简单、简装、良好的性能,如果消息m被发送到一台服务器并接受,那么它将被所有的服务器接受
3.实时性:Zookeeper保证客户端将在一个时间间隔范围内获得服务器的更新信息,或者服务器试失效的信息。但由于网络延时等原因,Zookeeper不能保证两个客户端能同时得到刚刚更新的数据,如果需要最新数据,应该i在读取数据之前调用sync()接口
4.等待无关(wait-free):慢的或者失效的client不得干预快速的client的请求,使得每个client都能有效的等待
5.原子性:额更新只能成功或者失败,没有中间状态
6.顺序性:包括全局有序和偏序两种:全局有序是指如果在一台服务器上消息a在消息b发布前,则在所有Server上消息a都将在消息b前辈发布:偏序是指如果一个消息b在消息a后被同一个发送者发布,a必将排在b前面,
2.3集群安装
我们本次安装的集群是伪集群,也就是在一台Linux上搭建,根真实的集群的原理都是一样的,性能好的话,有三台服务器,也可以在不同的服务器上进行实验!
使用3个Zookeeper应用搭建一个伪集群。应用部署的位置是:ip地址。服务器监听的端口分别为:
2181、2182、2183.投票选举端口分别为1881/3881、1883/3883、1883/3883
2.3.1准备步骤
还是要提醒:先大略的看完所有步骤,然后在继续你的操作!!
首先创建了一个文件夹,用于管理存放所有的伪集群 mkdir zookeeperCluster 然后解压一个Zookeeper并复制到这个目录 例如: tar -zxvf zookeeper-3.4-6 - C /usr/local/soft/zookeeperCluster 然后我们给它改一个名字 mv zookeeper-3.4.6 zookeeper01 也就是第一个Zookeeper2.3.1提供数据缓存目录
我们在第一个Zookeeper01里面创建这个 mkdir data
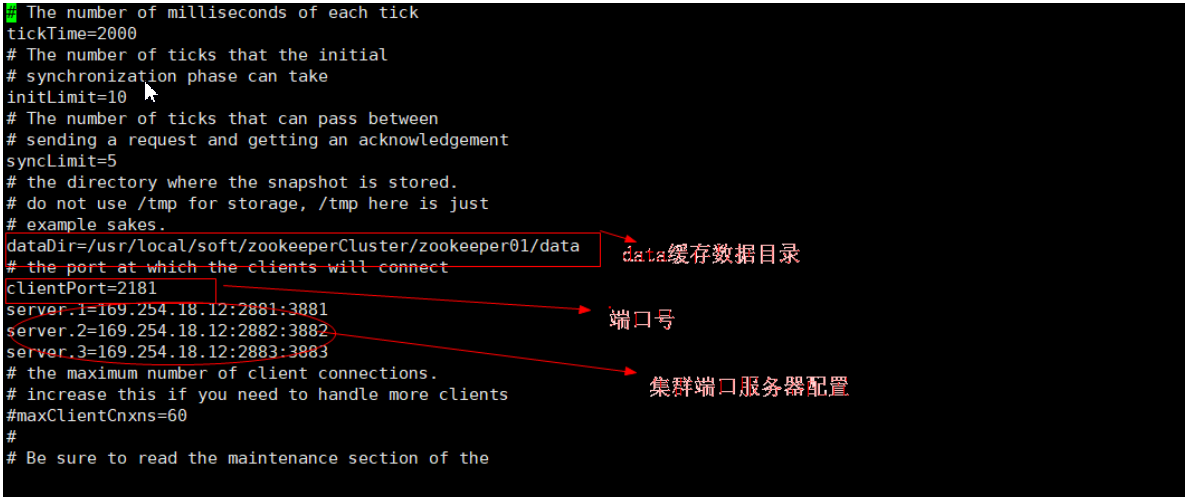
2.3.2修改配置文件zoo.cfg
首先到Zookeeper01的conf目录 然后把zoo_sample.cfg改名为zoo.cfg mv zoo_sample.cfg zoo.cfg 然后进去编辑 vi zoo.cfg
*
需要注意:当我们在修改配置文件 zoo.cfg 设置访问、投票、选举端口的时候 要如下这样设置,相信你认真看完前边的图文会很清晰的知道思路的!
server.1=Zookeeper所在的ip地址:2881:3881
server.2=Zookeeper所在的ip地址:2882:3882
server.3=Zookeeper所在的ip地址:2883:3883
*
2.3.3 提供Zookeeper的唯一标识
在Zookeeper集群中,每个节点需要一个唯一标识。这个唯一标识要求是自然数,且唯一标识保存位置是:$dataDir/myid 。其中dataDir为配置文件zoo.cfg中配置参数的data数据缓存目录
接下来,我们在data数据缓存目录创建文件:myid touch myid 然后编辑这个文件添加一个标识数字比如:vi myid 比如这是在第一个Zookeeper里面就那就添加一个 1。
简化方式写法:echo[唯一标识]>>myid . echo命令为回声命令,系统会讲命令发送的数据返回。“>>”为定位,代表系统回声数据指定发送到什么位置。此命令代表系统回声数据发送到myid文件里面。如果没有这个文件则创建文件
例如:echo 1 >>myid
这样第一个Zookeeper集群的第一个Zookeeper节点就已经配置完毕了,还剩其余两个,
那么我们就可以直接复制Zookeeper01然后分别复制为Zookeeper02和Zookeeper03
2.3.4最终配置
之后我们分别进入Zookeeper01和Zookeeper02里面的conf/zoo.cfg文件,然后进行编辑,我们只需要把clientPort端口号改变还有dataDir数据缓存地址改变为本集群节点即可,最后一步,在给这两个集群分别创建一个Zookeeper的唯一标识,按照上面的方法,分别为 2 、3(这个其实是可以随意的,只要别重复即可)
2.3.5启动ZooKeeper集群应用
分别进入zookeeper01、zookeeper02、zookeeper03的bin目录,然后输入
./zkServer.sh start启动他们
ZooKeeper集群搭建后,至少需要启动两个集群节点应用才能提供服务。因需要选出主服务节点。启动所有的ZooKeeper节点后,可以使用命令在bin目录下,
./zkServer.sh status 来查看节点状态
如下:
Mode:leader 主机
Model:follower -备用机
2.3.6 关闭ZooKeeper应用
还是在bin目录下
./zkServer.sh stop
搭建完毕了,那么你的ZooKeeper向你问候了吗?
