SQLFlow使用中的注意事项–设置篇
- 2021 年 5 月 16 日
- 筆記
- Oracle, SQLflow 血缘关系, 大数据
SQLFlow 是用于追溯数据血缘关系的工具,它自诞生以来以帮助成千上万的工程师即用户解决了困扰许久的数据血缘梳理工作。
数据库中视图(View)的数据来自表(Table)或其他视图,视图中字段(Column)的数据可能来自多个表中多个字段的聚集(aggregation)。 表中的数据可能通过ETL从外部系统中导入。这种从数据的源头经过各个处理环节,到达数据终点的数据链路关系称为数据血缘关系(data lineage)。
SQLFlow 通过分析各种数据库对象的定义(DDL)、DML 语句、ETL/ELT中使用的存储过程(Proceudre,Function)、 触发器(Trigger)和其他 SQL 脚本,给出完整的数据血缘关系。
在大型数据仓库中,完整的数据血缘关系可以用来进行数据溯源、表和字段变更的影响分析、数据合规性的证明、数据质量的检查等。
本文主要介绍SQLFlow中的Setting,下图展示了Setting的主要选项。其中,dataflow和show intermediate recordset是默认开启选项。
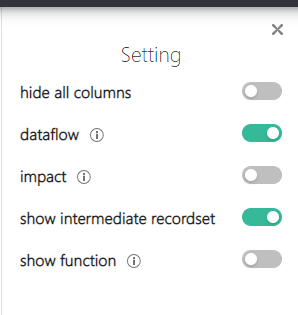

- hide all columns:隐藏列,仅显示对象间的逻辑关联关系;
- dataflow:显示数据流的方向;
- impact:显示对象间的关联逻辑,使用虚线显示,并新增虚拟关联字段;
- show intermediate recordset:显示中间记录集;
- show function:在逻辑关系中显示调用的函数。
备注:dataflow和impact属性可以同时存在,任何情况下,他们两者至少选择一种,不可均不选择。
下面,展示主要属性的使用:
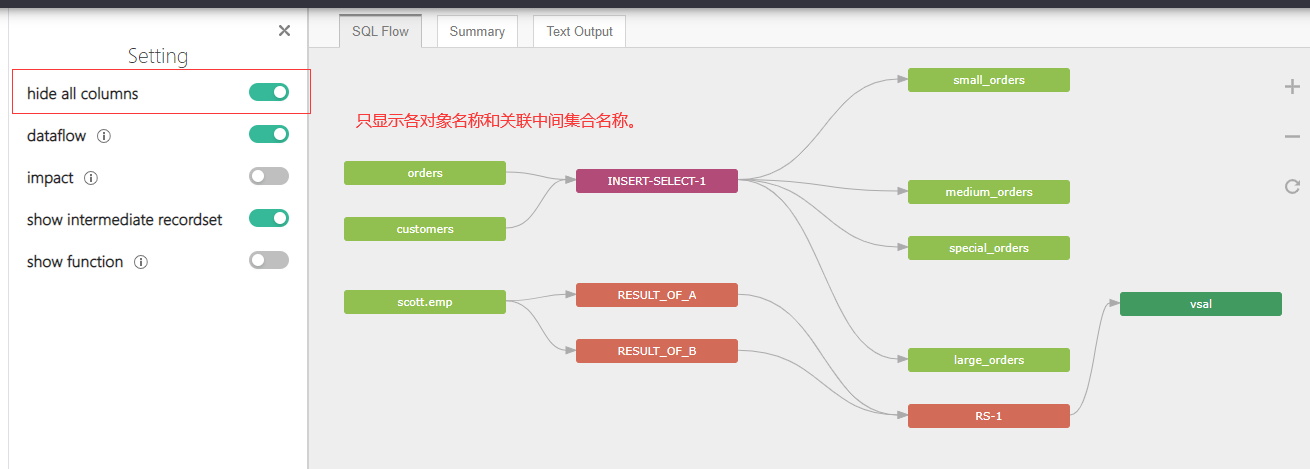
开启:hide all columns

开启Impact选项:

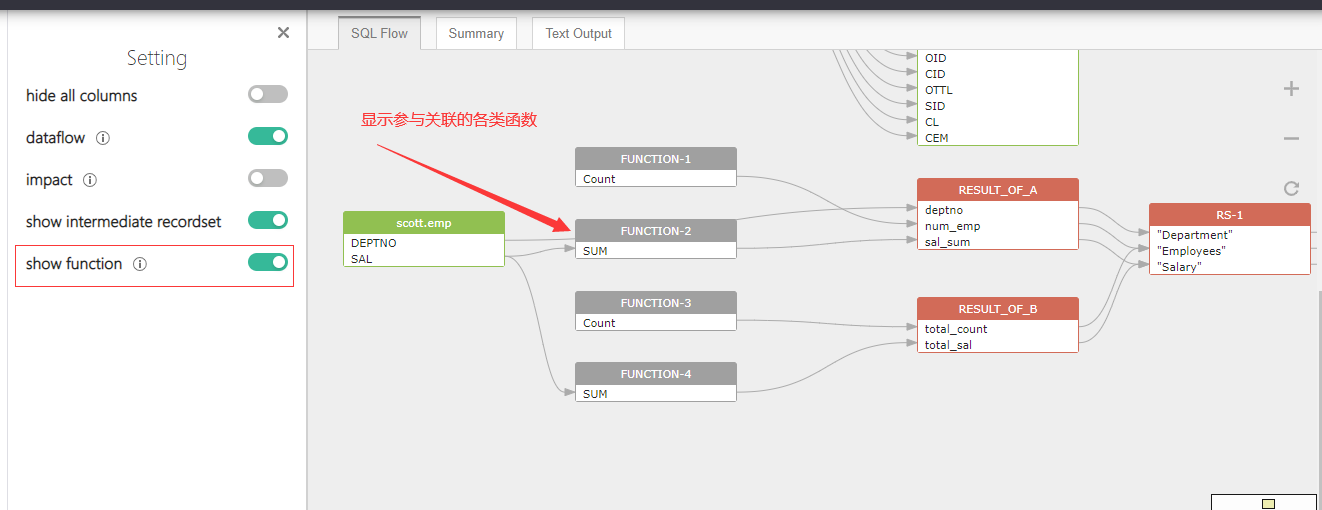
开启show function选项:
好了,篇幅关系,Setting部分今天就先介绍到这里,以后会持续更新。



