Java JFR 民间指南 – 事件详解 – jdk.ObjectAllocationSample
- 2021 年 4 月 22 日
- 筆記
- JAVA, JVM, 通过JFR详解JVM
对象分配采样:jdk.ObjectAllocationSample
引入版本:Java 16
相关 ISSUE:Introduce JFR Event Throttling and new jdk.ObjectAllocationSample event (enabled by default)
各版本配置:
Java 16:
默认配置(default.jfc):
| 配置 | 值 | 描述 |
|---|---|---|
| enabled | true | 默认启用 |
| throttle | 150/s | 每秒最多采集 150 个 |
| stackTrace | true | 采集事件的时候,也采集堆栈 |
采样配置(profile.jfc):
| 配置 | 值 | 描述 |
|---|---|---|
| enabled | true | 默认启用 |
| throttle | 300/s | 每秒最多采集 300 个 |
| stackTrace | true | 采集事件的时候,也采集堆栈 |
为何需要这个事件?
对于大部分的 JVM 应用,大部分的对象是在 TLAB 中分配的。如果 TLAB 外分配过多,或者 TLAB 重分配过多,那么我们需要检查代码,检查是否有大对象,或者不规则伸缩的对象分配,以便于优化代码。对于 TLAB 外分配和重分配分别有对应的事件:jdk.ObjectAllocationOutsideTLAB和jdk.ObjectAllocationInNewTLAB。但是这两个事件,如果不采集堆栈,则没有什么实际参考意义,如果采集堆栈的话,这两个事件数量非常大,尤其是出现问题的时候。那么采集堆栈的次数也会变得非常多,这样会非常影响性能。采集堆栈,是一个比较耗性能的操作,目前大部分的 Java 线上应用,尤其是微服务应用,都使用了各种框架,堆栈非常深,可能达到几百,如果涉及响应式编程,这个堆栈就更深了。JFR 考虑到这一点,默认采集堆栈深度最多是 64,即使是这样,也还是比较耗性能的。并且,在 Java 11 之后,JDK 一直在优化获取堆栈的速度,例如堆栈方法字符串放入缓冲池,优化缓冲池过期策略与 GC 策略等等,但是目前性能损耗还是不能忽视。所以,引入这个事件,减少对于堆栈的采集导致的消耗。
事件包含属性
| 属性 | 说明 | 举例 |
|---|---|---|
| startTime | 事件开始时间 | 10:16:27.718 |
| objectClass | 触发本次事件的对象的类 | byte[] (classLoader = bootstrap) |
| weight | 注意,这个不是对象大小,而是该线程距离上次被采集 jdk.ObjectAllocationSample 事件到这个事件的这段时间,线程分配的对象总大小 | 10.0 MB |
| eventThread | 线程 | “Thread-0” (javaThreadId = 27) |
| stackTrace | 线程堆栈 | 略 |
测试这个事件
package com.github.hashjang.jfr.test;
import jdk.jfr.Recording;
import jdk.jfr.consumer.RecordedEvent;
import jdk.jfr.consumer.RecordingFile;
import sun.hotspot.WhiteBox;
import java.io.File;
import java.io.IOException;
import java.nio.file.Path;
import java.util.concurrent.TimeUnit;
public class TestObjectAllocationSample {
//对于字节数组对象头占用16字节
private static final int BYTE_ARRAY_OVERHEAD = 16;
//分配对象的大小,1MB
private static final int OBJECT_SIZE = 1024 * 1024;
//要分配的对象个数
private static final int OBJECTS_TO_ALLOCATE = 20;
//分配对象的 class 名称
private static final String BYTE_ARRAY_CLASS_NAME = new byte[0].getClass().getName();
private static final String INT_ARRAY_CLASS_NAME = new int[0].getClass().getName();
//测试的 JFR 事件名称
private static String EVENT_NAME = "jdk.ObjectAllocationSample";
//分配的对象放入这个静态变量,防止编译器优化去掉没有使用的分配代码
public static byte[] tmp;
public static int[] tmp2;
public static void main(String[] args) throws IOException, InterruptedException {
//使用 WhiteBox 执行 FullGC,清楚干扰
WhiteBox whiteBox = WhiteBox.getWhiteBox();
whiteBox.fullGC();
Recording recording = new Recording();
//设置 throttle 为 1/s,也就是每秒最多采集一个
//目前 throttle 只对 jdk.ObjectAllocationSample 有效,还不算是标准配置,所以只能这样配置
recording.enable(EVENT_NAME).with("throttle", "1/s");
recording.start();
//main 线程分配对象
for (int i = 0; i < OBJECTS_TO_ALLOCATE; ++i) {
//由于 main 线程在 JVM 初始化的时候分配了一些其他对象,所以第一次采集的大小可能不准确,或者采集的类不对,后面结果中我们会看到
tmp = new byte[OBJECT_SIZE - BYTE_ARRAY_OVERHEAD];
TimeUnit.MILLISECONDS.sleep(100);
}
//测试多线程分配对象
Runnable runnable = () -> {
for (int i = 0; i < OBJECTS_TO_ALLOCATE; ++i) {
tmp = new byte[OBJECT_SIZE - BYTE_ARRAY_OVERHEAD];
try {
TimeUnit.MILLISECONDS.sleep(100);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
};
Thread thread = new Thread(runnable);
Runnable runnable2 = () -> {
for (int i = 0; i < OBJECTS_TO_ALLOCATE; ++i) {
tmp2 = new int[OBJECT_SIZE - BYTE_ARRAY_OVERHEAD];
try {
TimeUnit.MILLISECONDS.sleep(100);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
};
Thread thread2 = new Thread(runnable2);
thread.start();
thread2.start();
long threadId = thread.getId();
long threadId2 = thread2.getId();
thread.join();
thread2.join();
recording.stop();
Path path = new File(new File(".").getAbsolutePath(), "recording-" + recording.getId() + "-pid" + ProcessHandle.current().pid() + ".jfr").toPath();
recording.dump(path);
long size = 0;
for (RecordedEvent event : RecordingFile.readAllEvents(path)) {
if (!EVENT_NAME.equals(event.getEventType().getName())) {
continue;
}
String objectClassName = event.getString("objectClass.name");
boolean isMyEvent = (
Thread.currentThread().getId() == event.getThread().getJavaThreadId()
|| threadId == event.getThread().getJavaThreadId()
|| threadId2 == event.getThread().getJavaThreadId()
) && (
objectClassName.equals(BYTE_ARRAY_CLASS_NAME) ||
objectClassName.equals(INT_ARRAY_CLASS_NAME)
);
if (!isMyEvent) {
continue;
}
System.out.println(event);
}
}
}
输出示例:
//main线程在初始化 JVM 的时候,分配了一些其他对象,所以这里 weight 很大
jdk.ObjectAllocationSample {
startTime = 10:16:24.677
//触发本次事件的对象的类
objectClass = byte[] (classLoader = bootstrap)
//注意,这个不是对象大小,而是该线程距离上次被采集 jdk.ObjectAllocationSample 事件到这个事件的这段时间,线程分配的对象总大小
weight = 15.9 MB
eventThread = "main" (javaThreadId = 1)
stackTrace = [
com.github.hashjang.jfr.test.TestObjectAllocationSample.main(String[]) line: 42
]
}
jdk.ObjectAllocationSample {
startTime = 10:16:25.690
objectClass = byte[] (classLoader = bootstrap)
weight = 10.0 MB
eventThread = "main" (javaThreadId = 1)
stackTrace = [
com.github.hashjang.jfr.test.TestObjectAllocationSample.main(String[]) line: 42
]
}
jdk.ObjectAllocationSample {
startTime = 10:16:26.702
objectClass = byte[] (classLoader = bootstrap)
weight = 1.0 MB
eventThread = "Thread-0" (javaThreadId = 27)
stackTrace = [
com.github.hashjang.jfr.test.TestObjectAllocationSample.lambda$main$0() line: 48
java.lang.Thread.run() line: 831
]
}
jdk.ObjectAllocationSample {
startTime = 10:16:27.718
objectClass = byte[] (classLoader = bootstrap)
weight = 10.0 MB
eventThread = "Thread-0" (javaThreadId = 27)
stackTrace = [
com.github.hashjang.jfr.test.TestObjectAllocationSample.lambda$main$0() line: 48
java.lang.Thread.run() line: 831
]
}
各位读者可以将采集频率改成 “100/s”,就能看到基本所有代码里面的对象分配都被采集成为一个事件了。
底层原理与相关 JVM 源码
首先我们来看下 Java 对象分配的流程:
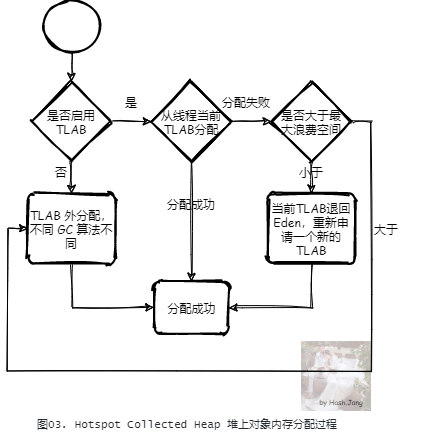
对于 HotSpot JVM 实现,所有的 GC 算法的实现都是一种对于堆内存的管理,也就是都实现了一种堆的抽象,它们都实现了接口 CollectedHeap。当分配一个对象堆内存空间时,在 CollectedHeap 上首先都会检查是否启用了 TLAB,如果启用了,则会尝试 TLAB 分配;如果当前线程的 TLAB 大小足够,那么从线程当前的 TLAB 中分配;如果不够,但是当前 TLAB 剩余空间小于最大浪费空间限制,则从堆上(一般是 Eden 区) 重新申请一个新的 TLAB 进行分配。否则,直接在 TLAB 外进行分配。TLAB 外的分配策略,不同的 GC 算法不同。例如G1:
- 如果是 Humongous 对象(对象在超过 Region 一半大小的时候),直接在 Humongous 区域分配(老年代的连续区域)。
- 根据 Mutator 状况在当前分配下标的 Region 内分配
jdk.ObjectAllocationSample 事件只关心 TLAB 外分配,因为这也是程序主要需要的优化点。throttle 配置,是限制在一段时间内只能采集这么多的事件。但是我们究竟怎么筛选采集哪些事件呢?假设我们配置的是 100/s,首先想到的是时间窗口,采集这一窗口内开头的 100 个事件。这样显然是不符合我们的要求的,我们并不能保证性能瓶颈的事件就在每秒的前 100 个,并且我们的程序可能每秒发生很多很多次 TLAB 外分配,仅凭前 100 个事件并不能很好的采集我们想看到的事件。所以,JDK 内部通过 EWMA(Exponential Weighted Moving Average)的算法估计何时的采集时间以及越大分配上报次数越多的这样的优化来实现更准确地采样。
如果是直接在 TLAB 外进行分配,才可能生成 jdk.ObjectAllocationSample 事件。
参考源码:
//在每次发生 TLAB 外分配的时候,调用这个方法上报
void AllocTracer::send_allocation_outside_tlab(Klass* klass, HeapWord* obj, size_t alloc_size, Thread* thread) {
JFR_ONLY(JfrAllocationTracer tracer(obj, alloc_size, thread);)
//立刻生成 jdk.ObjectAllocationOutsideTLAB 这个事件
EventObjectAllocationOutsideTLAB event;
if (event.should_commit()) {
event.set_objectClass(klass);
event.set_allocationSize(alloc_size);
event.commit();
}
//归一化分配数据并采样 jdk.ObjectAllocationSample 事件
normalize_as_tlab_and_send_allocation_samples(klass, static_cast<intptr_t>(alloc_size), thread);
}
再来看归一化分配数据并生成 jdk.ObjectAllocationSample 事件的具体内容:
static void normalize_as_tlab_and_send_allocation_samples(Klass* klass, intptr_t obj_alloc_size_bytes, Thread* thread) {
//读取当前线程分配过的字节大小
const int64_t allocated_bytes = load_allocated_bytes(thread);
assert(allocated_bytes > 0, "invariant"); // obj_alloc_size_bytes is already attributed to allocated_bytes at this point.
//如果没有使用 TLAB,那么不需要处理,allocated_bytes 肯定只包含 TLAB 外分配的字节大小
if (!UseTLAB) {
//采样 jdk.ObjectAllocationSample 事件
send_allocation_sample(klass, allocated_bytes);
return;
}
//获取当前线程的 TLAB 期望大小
const intptr_t tlab_size_bytes = estimate_tlab_size_bytes(thread);
//如果当前线程分配过的字节大小与上次读取的当前线程分配过的字节大小相差不超过 TLAB 期望大小,证明可能是由于 TLAB 快满了导致的 TLAB 外分配,并且大小不大,没必要上报。
if (allocated_bytes - _last_allocated_bytes < tlab_size_bytes) {
return;
}
assert(obj_alloc_size_bytes > 0, "invariant");
//利用这个循环,如果当前线程分配过的字节大小越大,则采样次数越多,越容易被采集到。
do {
if (send_allocation_sample_with_result(klass, allocated_bytes)) {
return;
}
obj_alloc_size_bytes -= tlab_size_bytes;
} while (obj_alloc_size_bytes > 0);
}
这里我们就观察到了 JDK 做的第一个上报优化算法:如果本次分配对象大小越大,那么这个循环次数就会越多,采样次数就越多,被采集到的概率也越大
接下来来看具体的采样方法:
inline bool send_allocation_sample_with_result(const Klass* klass, int64_t allocated_bytes) {
assert(allocated_bytes > 0, "invariant");
EventObjectAllocationSample event;
//判断事件是否应该 commit,只有 commit 的事件才会被采集
if (event.should_commit()) {
//weight 等于上次记录当前线程的 threadLocal 的 allocated_bytes 减去当前线程的 allocated_bytes
//由于不是每次线程发生 TLAB 外分配的时候上报都会被采集,所以需要记录上次被采集时候的线程分配的 allocated_bytes 大小,计算与当前的差值就是本次上报的事件中的线程距离上次上报分配的对象大小。
const size_t weight = allocated_bytes - _last_allocated_bytes;
assert(weight > 0, "invariant");
//objectClass 即触发上报的分配对象的 class
event.set_objectClass(klass);
//weight 并不代表 objectClass 的对象的大小,而是这个线程距离上次上报被采集分配的对象大小
event.set_weight(weight);
event.commit();
//只有事件 commit,也就是被采集,才会更新 _last_allocated_bytes 这个 threadLocal 变量
_last_allocated_bytes = allocated_bytes;
return true;
}
return false;
}
通过这里的代码我们明白了:
- ObjectClass 是 TLAB 外分配对象的 class,也是本次触发记录jdk.ObjectAllocationSample 事件的对象的 class
- weight 是线程距离上次记录 jdk.ObjectAllocationSample 事件到当前这个事件时间内,线程分配的对象大小。
这里通常会误以为 weight 就是本次事件 ObjectClass 的对象大小。这个需要着重注意下。
那么如何判断的事件是否应该 commit? 这里走的是 JFR 通用逻辑:
jfrEvent.hpp
bool should_commit() {
if (!_started) {
return false;
}
if (_untimed) {
return true;
}
if (_evaluated) {
return _should_commit;
}
_should_commit = evaluate();
_evaluated = true;
return _should_commit;
}
bool evaluate() {
assert(_started, "invariant");
if (_start_time == 0) {
set_starttime(JfrTicks::now());
} else if (_end_time == 0) {
set_endtime(JfrTicks::now());
}
if (T::isInstant || T::isRequestable) {
return T::hasThrottle ? JfrEventThrottler::accept(T::eventId, _untimed ? 0 : _start_time) : true;
}
if (_end_time - _start_time < JfrEventSetting::threshold(T::eventId)) {
return false;
}
//这里我们先只关心 Throttle
return T::hasThrottle ? JfrEventThrottler::accept(T::eventId, _untimed ? 0 : _end_time) : true;
}
这里涉及 JfrEventThrottler 控制实现 throttle 配置。主要通过 EWMA 算法实现对于下次合适的采集时间间隔的不断估算优化更新,来采集到最合适的 jdk.ObjectAllocationSample,同时这种算法并不像滑动窗口那样记录历史数据导致占用很大内存,指数移动平均(exponential moving average),或者叫做指数加权移动平均(exponentially weighted moving average),是以指数式递减加权的移动平均,各数值的加权影响力随时间呈指数式递减,可以用来估计变量的局部均值,使得变量的更新与一段时间内的历史取值有关。
假设每次采集数据为 P(n),权重衰减程度为 t,t 在 0~1 之间:
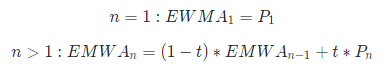
上面的公式,也可以写作:
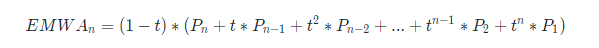
从这个公式可以看出,权重系数 t 以指数等比形式缩小,时间越靠近当前时刻的数据加权影响力越大。
这个 t 越小,过去过去累计值的权重越低,当前抽样值的权重越高,平均值的实时性就越强。反之 t 越大,吸收瞬时突发值的能力变强,平均值的平稳性更好。
对于 jdk.ObjectAllocationSample 这个事件,算法实现即 jfrEventThrottler.hpp。如果大家感兴趣,可以在运行实例程序的时候,增加如下的启动参数 -Xlog:jfr+system+throttle=debug 来查看这个 EWMA 采集窗口的相关信息,从而理解学习源码。日志示例:
[0.743s][debug][jfr,system,throttle] jdk.ObjectAllocationSample: avg.sample size: 0.0000, window set point: 0, sample size: 0, population size: 0, ratio: 0.0000, window duration: 0 ms
[1.761s][debug][jfr,system,throttle] jdk.ObjectAllocationSample: avg.sample size: 0.0400, window set point: 1, sample size: 1, population size: 19, ratio: 0.0526, window duration: 1000 ms
[2.775s][debug][jfr,system,throttle] jdk.ObjectAllocationSample: avg.sample size: 0.0784, window set point: 1, sample size: 1, population size: 19, ratio: 0.0526, window duration: 1000 ms
[3.794s][debug][jfr,system,throttle] jdk.ObjectAllocationSample: avg.sample size: 0.1153, window set point: 1, sample size: 1, population size: 118, ratio: 0.0085, window duration: 1000 ms
[4.815s][debug][jfr,system,throttle] jdk.ObjectAllocationSample: avg.sample size: 0.1507, window set point: 1, sample size: 1, population size: 107, ratio: 0.0093, window duration: 1000 ms
总结
- jdk.ObjectAllocationSample 是 Java 16 引入,用来优化对象分配不容易高效监控的事件。
- jdk.ObjectAllocationSample 事件里面的 ObjectClass 是触发事件的 class,weight 是线程分配的对象总大小。所以实际观察的时候,采集会与实际情况有些偏差。这是高效采集无法避免的。
- JVM 通过 EMWA 做了算法优化,采集到的事件随着程序运行会越来越是你的性能瓶颈或者热点代码相关的事件。
微信搜索“我的编程喵”关注公众号,加作者微信,每日一刷,轻松提升技术,斩获各种offer: