Database | 浅谈Query Optimization (2)
- 2021 年 4 月 10 日
- 筆記
为什么选择左深连接树
对于n个表的连接,数量为卡特兰数,近似\(4^n\),因此为了减少枚举空间,早期的优化器仅考虑左深连接树,将数量减少为\(n!\)
但为什么是左深连接树,而不是其他样式呢?
如果join算法为index join或者hash join,当两张表进行连接的时候,需要为左表建立哈希映射或者搜索索引,连接时直接寻找对应的元素:
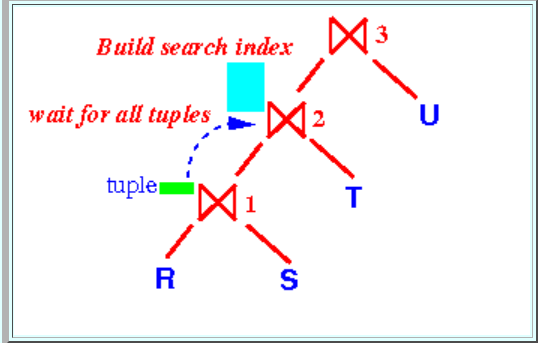
join ⋈2 必须等到⋈1 的全部元组输出之后才能生成它的映射表/索引。即只有⋈1 结束后,⋈2才能开始输出元组。而此时⋈3必须等待,直到⋈2完成。
对于多个表的连接,当⋈i正在执行时,⋈i+1处于半活跃的状态,它累积⋈i的输出到缓冲区并建立映射,而后面的⋈i+2到⋈n均处于空闲状态。
当执行连接⋈1时,需要为⋈1中的表分配内存,然后将输出的元组同样储存在内存中。而如前所述,只有⋈1结束时⋈2才能开始,因此⋈1结束时可以直接释放掉之前占用的内存空间。
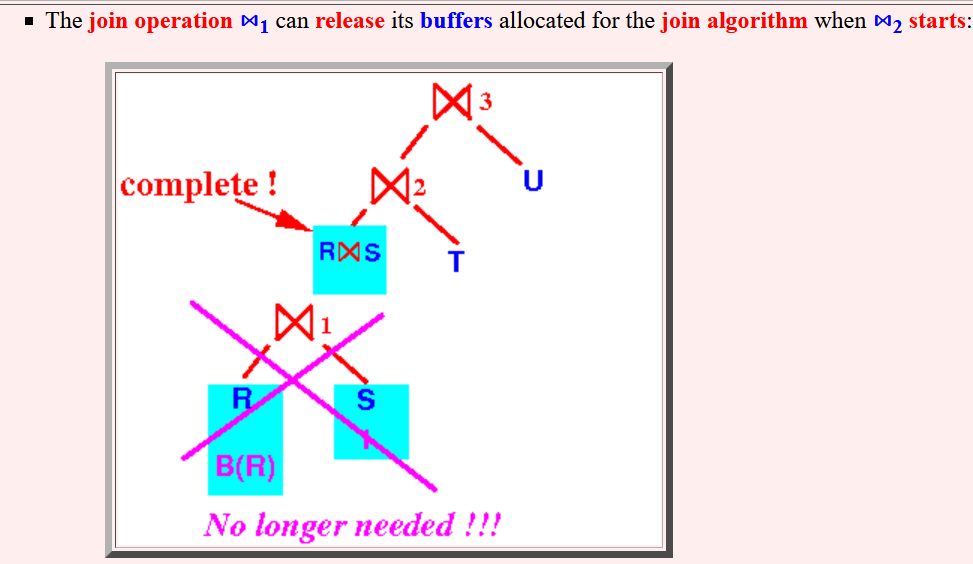
而对于其他形式的树,例如右深连接树,因为左侧的操作数都是一个关系,所有的join连接符都可以为左表建立映射表/索引,会占用大量的内存空间。
因此对于Hash Join,采用左深连接树可以减少执行计划对内存的需求。
当join算法为nested-loop join时,如果采用右深连接树,结果会更糟糕:
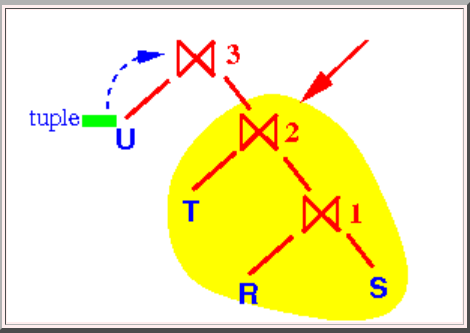
如图,执行⋈3时会导致多次访问⋈3的第二个操作数,使得该子查询多次执行,会多次访问表T、R、S增加读取磁盘的次数。
寻找最佳连接顺序
最佳的连接顺序即是中间结果中产生最少元组数量的连接顺序
因为不同的连接顺序都会访问每个表一次,而表连接的中间结果往往需要写入磁盘中暂时储存,因此中间结果元组数量越少,读取磁盘次数越少。
因此我们定义 cost for join 即是指连接后产生的中间结果的个数。
而不去连接怎么知道中间结果的个数呢?那就需要用到上一篇博客中提到的谓词的选择性和数据直方图,估算连接后产生的元组个数。
对于三个关系的连接,需要维护如下的数据图:
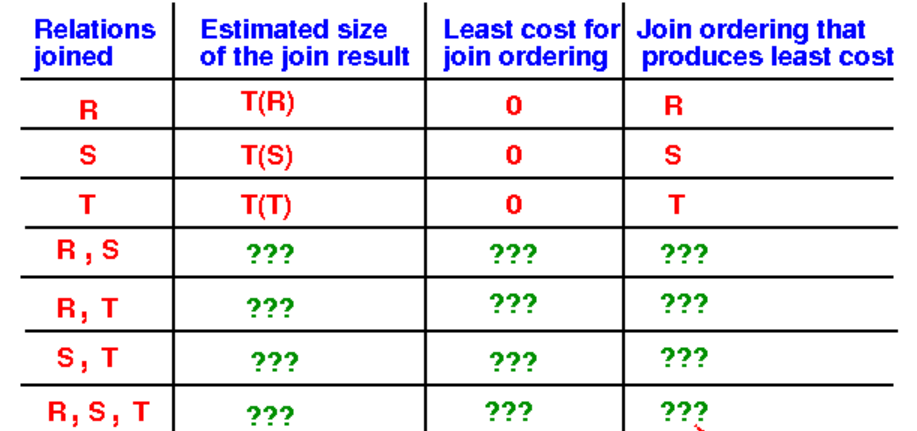
首先是相互连接关系的列表,然后是连接后的元组总数和连接的cost,以及这几个关系的最佳连接顺序。
然后对给定的n个表,将其分解成n个n-1的表的连接,再逐层分解,先求得两个关系的最佳连接方式。最优解即是这些子问题的组合。
算法的伪代码如下:
j = set of join nodes
for (i in 1...|j|): //一开始寻找单个join的最佳方案,再向上延伸
for s in {all length i subsets of j} //寻找s的最优连接
bestPlan = {}
//i-1的最优解都已经储存在optjoin中
//只需要考虑再加一个表的情况
for ss in {all length i-1 subsets of s}
subplan = optjoin(ss)
//optjoin 可以理解为一个哈希表,储存对应ss的最优连接
plan = best way to join (s-ss) to subplan
if (cost(plan) < cost(bestPlan))
bestPlan = plan
optjoin(s) = bestPlan
return optjoin(j)
具体而言,假设现在是R、S、T、U四个关系相连接,我们已经得出两个关系的最优解如下图所示:
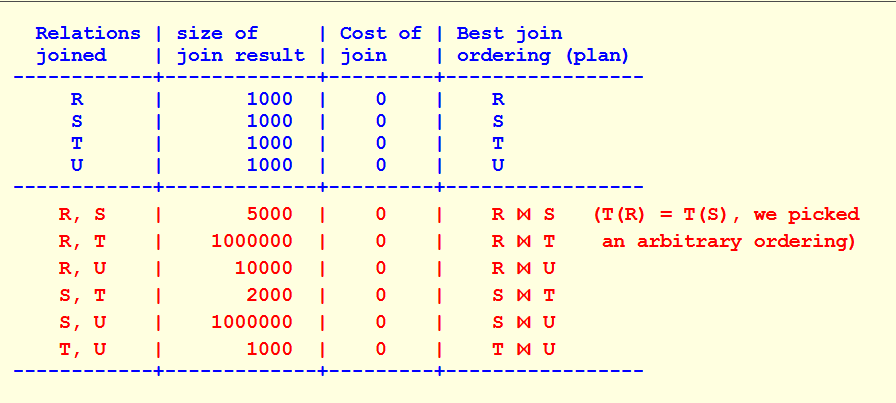
那么假设现在有
i=3, s=R,S,T
//那么对于ss
ss=R,S or R,T or S,T
计算出三种s的cost,找出bestplan,则
optjoin(R,S,T) = bestplan
我们先不考虑谓词选择性,直接将生成的元组个数作为cost,那么
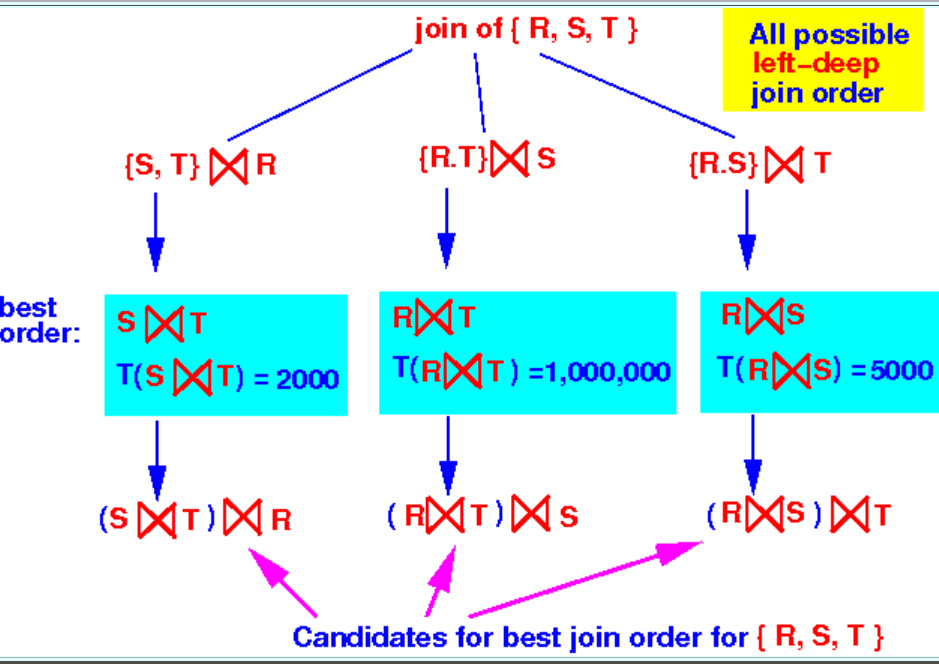
因为 T(S ⋈ T) = 2000, 因此 {S, T} ⋈ R 即为 s=R, S, T 的最优顺序。
将length(s)=3的四种情况依次计算,再求得四个关系相连接的最优顺序。
动态规划算法的缺点
- 缺乏扩展性:当需要加入新的join方法时,需要修改大量代码。如果增加新的operator,比如aggregation,那么修改就更加困难。
- 对Join顺序优化的问题非常适合,但是却不容易适用其他的优化方法,比如对GroupBy或者Union的优化。
动态规划的主要意义还是寻找次优的连接顺序,并且其搜索空间依然很大,需要\(O(n*2^{n-1})\),当表的数量为两位数时依然需要较长时间来响应。


