利用深度学习来给机器学习赋能(2)——label smooth
- 2021 年 4 月 9 日
- AI
When Does Label Smoothing Help?
关于label smooth的技术,可以将其看作和dropout,l1、l2正则化等一个label的针对分类问题使用的正则化技术。
label smooth的两个优点:
1、提高模型泛化能力;
2、降低迭代次数
关于label smooth的两篇讲的比较好的文章;
王峰:Label Smoothing分析 十块钱:简单的label smooth为什么能够涨点呢
十块钱:简单的label smooth为什么能够涨点呢
label smooth最初是用于cv问题的,关于cv中能够提升泛化能力的解释不是太清楚。我的理解来看,label smooth的思路很清晰简单。
label smooth做的事情很简单:
把hard label变为soft label,
原来是1的位置变为,其他的原来是0的位置变为
,
通常取0.1,K是类别的数量
假设一个6分类任务,之前的就变成了
,
首先从二点 降低迭代次数来说,


对于分类问题,无论是nn还是gbdt,抽象来看,就是一个model+一个softmax层,softmax公式如上,显然,在使用交叉熵的情况下,我们希望标签为1的样本的预测结果为无穷大,标签为0的样本的预测结果为负无穷大,这样softmax之后的结果才会分别无限趋近于0和1,所以在进入softmax之前,我们的预测结果得是一个非常大的值。
对于nn来说,这意味着输入不变的情况下,权重的绝对值需要变得比较大,对于gbdt来说,需要使用更多的tree。大量次数的迭代意味着模型的过拟合:

以上图的二分类问题为例,过多的迭代次数,更低的logloss,模型的分类超平面会过度考虑training data的信息,从而导致泛化能力差的问题。
而当我们施加了label smooth之后,模型不用预测那么大的预测结果了,比如原来我们的正类的预测结果要是99999,现在只要预测999就行了,那么这样我们就不需要那么多的迭代次数了,nn的权重不用那么大,gbdt的tree不用那么多。这样我们的model的分类超平面就能从上图的overfiting转化到just right上了。从而提高了模型的泛化能力,即第一点。
这样我们的交叉熵就变成了:
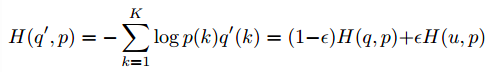
eps是超参数,常用0.1,可调;
剩下的事情就比较简单了,torch的smoothloss实现一大堆,再结合之前的方法:

可以比较容易的应用到lgb或者xgb中了。
个人感觉,smooth loss比较适用于噪声较多的问题,就是training data中存在一些错误标注的数据,通过引入smooth loss,使得模型的分类超平面不会那么地贴近原始的数据,对于噪声会更加的鲁棒一些。

