看YouTube学做广播体操?机器人即将掌握人类所有动作 | 一周AI最火论文
- 2019 年 12 月 2 日
- 筆記

大数据文摘专栏作品
作者:Christopher Dossman
编译:Olivia、Vicky、云舟
呜啦啦啦啦啦啦啦大家好,本周的AIScholar Weekly栏目又和大家见面啦!
AI ScholarWeekly是AI领域的学术专栏,致力于为你带来最新潮、最全面、最深度的AI学术概览,一网打尽每周AI学术的前沿资讯。
每周更新,做AI科研,每周从这一篇开始就够啦!
本周关键词: 智能机器人、姿态估计、沉浸式交互
本周最佳学术研究
能够“观看和学习”YouTube视频的机器人
机器人世界正在迅速地发展,很快我们就会目睹机器人掌握更多之前只有人类能够掌握的技能。在这篇论文中,研究人员提出了一个激动人心的课题——指导机器人复制视频中的动作。他们解决了机器人对协同动作计划学习的挑战。
研究的目标是让机器人在互联网上“观看”视频、提取视频中的动作序列并将其转换为可执行的计划,使其既可以自主执行、也可以作为机器人团队和人机团队中的一部分来执行。

为了演示该框架的适用性,研究人员输入了一个YouTube视频,该视频演示了一个完整的协作烹饪任务。该框架假定视频中的目标已被标记,并使用一个最新的目标检测模型为每个目标限定一个边界。
技术世界正处于一个令人兴奋的发展阶段,尤其是在机器人技术等机器学习技术不断进步的当下。更令人激动的是,互联网中包含的大量视频内容都可以被机器人用以执行人机团队和机器人团队中的协同任务。
在本文演示中,两个机械臂重现了一个简单的烹饪视频。这是朝着机器人通过在线观看视频来执行一系列操作计划的目标,迈出的重要一步。本文方法的局限性来自最新的目标检测技术需要满足的前提假设等。
原文:
https://arxiv.org/abs/1911.10686
用于六维姿态估计的多视图匹配网络
本文中,研究人员提出了一种新技术,用于估计单个RGB图像中的六维姿态。
该方法结合了目标检测和分割方法,通过将输入图像与渲染图像进行匹配来估计、优化和跟踪目标的姿态。
首先,研究人员使用Mask R-CNN来检测和分割输入图像中感兴趣的目标;然后,使用多视图匹配模型来估计该目标的6D姿态;最后,使用单视图匹配模型完善姿态估计。该方法获得的准确度可与常规RGB姿态估计的最新方法(如PoseCNN + DeepIM)得到的准确度相媲美。

本文为如何扩展独特的模型用于估计、改进和跟踪目标的姿态,提供了新的研究思路。
本项研究提出的方法展示了网络如何自动协助优化和跟踪过程。该方法扩展了一个用于姿态估计、改进和跟踪的姿态优化网络DeepIM,而无需使用外部的初始姿态估计方法。
因此,初始姿态估计网络(如PoseCNN)可能会被可用度高的目标检测网络所取代,而该目标检测网络已通过大型训练数据集进行了训练。
原文:
https://arxiv.org/abs/1911.12330
使用图像分析和检测社会关系
本文中,两名研究人员提出了一种可用于图像集中的面部图表示的方法。该方法根据面部表情、亲近程度、同时出现和头部朝向来分析在一个社交活动中有多少人被联系起来。为了实现这一目标,研究人员定义了集合中每对目标之间的“连通性”测量值,该值代表了他们之间的关联程度。
在下图中,节点表示集合中的主题,边缘表示节点之间的连接。节点越近,主题之间的联系就越紧密。
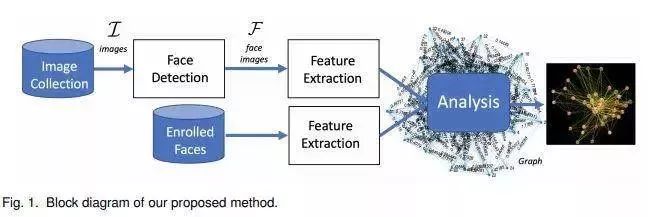
研究人员还开发了图形用户界面,用户可以在界面中单击节点或边缘来展示存在相连主题的图像集。
文中通过分析婚礼庆典、情景喜剧视频、排球比赛以及从Twitter提取的带有标签的图像提供了较为准确的结果。
的确,人脸识别和分析的最新技术还远远不够完美。因此,为了对社会关系进行更强有力地分析,任何有助于检测和衡量图像集中个人互动的贡献都很重要。
本文提供的工具对于检测图像集中现有的社会关系非常有帮助。未来,研究人员希望通过分析连通性矩阵,将检测目标增加到三人或更多。
原文:
https://arxiv.org/abs/1911.11970
以智能手机为触摸板在大型沉浸式显示器中进行多人交互
自诞生之日起,智能手机就完成了许多曾经被定义为Impossible Mission的任务。在这次的研究中,智能手机可以用作多人空间交互界面的触摸板了!
这项工作背后的研究人员提出了多种方法,合并了用户物理位置、输入设备(如智能手机和蓝牙麦克风)等信息,并将个人和共享屏幕区域进行自动情境化,使多个用户同时与一个大型的沉浸式屏幕进行交互。
个人互动区域出现在矩形封闭屏幕的两侧,用户可以在其中自由移动,选择空间,并操纵或生成相关图像。中间的共享屏幕区域可供多个用户同时使用,这一区域会基于用户选择的图像和预先定义的环境来生成布局。
该方法允许多个用户以自然的方式与较大的视觉沉浸式空间进行交互。
它可以将各种个人设备和语音与空间智能集成在一起,定义个人和共享交互区域,这为利用空间进行应用(包括课堂学习、协作、游戏等)提供了可能性。
视频演示:
https://arxiv.org/abs/1911.11751v1
实现有效的Mix-and-Match图像生成
在本文中,研究人员介绍了一个叫做MixNMatch的条件生成模型,它可以学习从真实图像中分离编码背景、对象姿态、形状和纹理因素等。MixNMatch提供了图像生成中的细粒度控制,其中每个因子都可被唯一地控制。

MixMatch在训练期间需要边界框来对背景建模,但不需要其它监督。它以实际参考图像、采样的潜在代码或两者的混合作为输入,以准确分离、编码和组合多个因素,以生成混合匹配图像。
自从生成对抗网络(GAN)发现以来,图像生成已经取得了长足的进步。这项工作演示了如何将来自四个不同图像的各种形状、姿势、纹理和背景进行组合,以创建全新的图像。
通过许多有趣的应用程序(包括sketch2color、cartoon2img和img2gif),图像生成在实现真实图像的最新细粒度对象类别聚类结果方面取得了显著成果。
这一研究目前还存在着一些限制,如MixNmatch未能生成良好的对象掩码,从而生成不完整的对象。
代码/模型/演示:
https://github.com/Yuheng-Li/MixNMatch
原文:
https://arxiv.org/abs/1911.11758v1
其他爆款论文
一种低成本、开源和模块化的软机器人设计和构造套件:
https://arxiv.org/abs/1911.10290
基于数字图像的AI诊断皮肤癌方案研究进展:
https://arxiv.org/abs/1911.11872
一种全新的结合自然语言、视觉和动作的端到端模仿学习方法:
https://arxiv.org/abs/1911.11744
有了这款Pixel Camera app ,妈妈再也不用担心美图秀秀拯救不了我黑灯瞎火拍的照片了:
https://ai.googleblog.com/2018/11/night-sight-seeing-in-dark-on-pixel.html
FBI,open up!新的端到端深度学习框架,可同时预测身份、活动和用户位置:
https://arxiv.org/abs/1911.11743
数据集
图像协调数据集:
https://github.com/bcmi/Image_Harmonization_Datasets
开放式多评分睡眠分期数据集:
https://arxiv.org/pdf/1911.03221v2.pdf
AI大事件
这个基于飞桨(Paddle Paddle)的新对象检测框架在2019谷歌物体识别–目标检测比赛中荣获第二名:
https://arxiv.org/abs/1911.07171
谷歌通过Explainable AI解决黑匣子问题:
https://www.bbc.com/news/technology-50506431
让AI来告诉你,今天你会进医院吗?
https://www.zdnet.com/article/ai-in-healthcare-using-algorithms-to-predict-your-risk-of-ending-up-in-hospital/
阿里巴巴在GitHub上分享了其机器学习算法平台Alink的核心代码:
https://www.zdnet.com/article/alibaba-cloud-publishes-machine-learning-algorithm-on-github/

专栏作者介绍
Christopher Dossman是Wonder Technologies的首席数据科学家,在北京生活5年。他是深度学习系统部署方面的专家,在开发新的AI产品方面拥有丰富的经验。除了卓越的工程经验,他还教授了1000名学生了解深度学习基础。
LinkedIn:
https://www.linkedin.com/in/christopherdossman/
志愿者介绍
后台回复“志愿者”加入我们





点「在看」的人都变好看了哦!


