Real-time Personalization using Embeddings for Search Ranking at Airbnb(休息)
- 2021 年 2 月 26 日
- AI
最近要做feed 流推荐,找了一些很不错的课程。
我不太喜欢看视频,因为太慢,极客时间还是非常不错的,课程有录音版和文字版(非广告。。。),看起来很快,不过目前专门讲推荐的就两门课,但都是精品:

王喆大佬的课讲解了非常多的精品论文和系统架构,

无刀大佬的课讲了Netflix的推荐系统架构,不过找来找去没有看到airbnb的embedding推荐的内容,所以这里补上。
考虑到这篇论文网上已经有非常多经典的解读,这里的工作就是把整个论文面向的业务场景,解决思路,技巧等做一个总结;
Ning Lee:推荐系统从零单排系列(七)–Airbnb实时个性化推荐之Embedding真的好用吗?
Airbnb的业务场景:
作为全球最大的短租平台,每天都有上百万的用户通过Airbnb找到自己心仪的短租屋。一个典型的用户操作流程如下:

用户输入地点、日期、人数进行搜索,系统会根据你的需求推荐你可能会感兴趣的房源,这就是Airbnb的第一大业务:搜索推荐。如下图所示:

浏览滑动选择一个你感兴趣的,点击查看,新页面中除了该短租屋具体信息,在页面底部会有一个更多房源,这就是Airbnb的第二大推荐业务场景:相似房源推荐。

与其他公司业务不同的地方在于,host可以拒绝user的预定。论文就是从这两大类业务场景出发,通过Embedding技术来提高推荐质量。具体包括:
问题1、 使用Embedding来建模用户long-term偏好,提高搜索推荐的质量 ;
问题2、 使用Embedding来学习listing的低维表达,提高相似房源推荐的质量;
王喆:从KDD 2018 Best Paper看Airbnb实时搜索排序中的Embedding技巧
针对于问题1,通过booking session生成user-type和listing-type的embedding,目的是捕捉不同user-type的long term喜好。由于booking signal过于稀疏,Airbnb对同属性的user和listing进行了聚合,形成了user-type和listing-type这两个embedding的对象。(就是你去了一个新地方,打开airbnb搜索的时候给你推荐的功能)
针对于问题2,airbnb地工程团队 通过click session数据生成listing的embedding,(翻译过来就是通过用户在选择短租屋的时候的点击序列数据来生成listing——也就是短租屋的embedding向量)生成这个embedding的目的是为了进行listing(短租屋)的相似推荐,以及对用户进行session内的实时个性化推荐。(就是你点击了某个房源之后,airbnb底下的给你其它相似房源的那个功能)
listing embedding
首先来看相对简单的listing embedding的部分,
数据预处理:
Airbnb使用了click session数据对listing进行embedding,其中click session指的是一个用户在一次搜索过程中,点击的listing的序列,这个序列需要满足两个条件,一个是只有停留时间超过30s的listing page才被算作序列中的一个数据点,二是如果用户超过30分钟没有动作,那么这个序列会断掉,不再是一个序列。

(比较好奇,这些阈值是怎么确定下来的)
这么做的目的无可厚非,一是清洗噪声点和负反馈信号,二是避免非相关序列的产生。
模型:
魔改了目标函数的skip-gram版的word2vec

word2vec的skip-gram model的目标函数如下:

使用nce之后得到:

对应到airbnb中的论文公式:
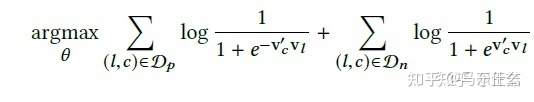
(sigmoid自带负号,这里没有问题的)
这里做的改进也不复杂,airbnb的工程师认为,用户booking成功的listing意义重大,这个其实不难理解,比如我今天比较喜欢 装修性冷淡风+价格便宜+有投影的listing,我肯定是在相似风格的listing里面找,那么我最终booking的listing大概率也是这种风格的,但是如果我选完了但是女朋友不同意,她想住现代风格的listing,那么我们可能会争论一段时间,大概争论个半小时,我妥协,重新booking,此时我重新点击的listing序列可能就完全不同了(不过说实话这个半小时airbnb到底是怎么统计出来的。。。论文也没写)
因此,最终的目标函数成为这样:

其中Db代表了所有booked session中所有滑动窗口中central listing和booked listing的pair集合。
下面这一项就比较容易理解了,为了更好的发现同一市场(marketplace)内部listing的差异性,Airbnb加入了另一组negative sample,就是在central listing同一地区的listing集合中进行随机抽样,获得一组新的negative samples。同理,我们可以用跟之前negative sample同样的形式加入到objective中。

其中Dmn就是新的同一地区的negative samples的集合。
至此,lisitng embedding的objective就定义完成了,embedding的训练过程就是word2vec negative sampling模型的标准训练过程,这里不再详述
从这里看来有两个需要注意的地方:
1、

根据原文的描述,这里应该是把booked listing也强制作为windows中的一部分了,也就是实际上上面公式的第一项

其实可以和
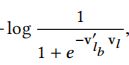
直接进行合并了。
2、关于目标函数的修改,我一开始以为这里的魔改是目标函数公式层面的修改,就类似于app2vec:

中引入app之间的使用时间作为权重,但是其实上面所描述的目标函数的修改其实是在样本层面进行的,换句话说,我们其实可以通过样本构造方式的实现上述的目标函数的改变,而模型本身仍旧是使用原本的skip-gram+nce版的word2vec的方法即可。
所以整体上实现起来难度就会低一些,我们可以使用tf版的word2vec的api,然后样本构造的时候按照上文的逻辑进行样本改在,这篇论文的价值倒不是这里的对booked listing的处理或者是同地区的负采样样本的扩充,而是提供了一个很好地将业务目标融合到模型训练过程中的思路;
为了对embedding的效果进行检验,Airbnb还实现了一个tool,我们简单贴一个相似embedding listing的结果。

从中可以看到,embedding不仅encode了price,listing-type等信息,甚至连listing的风格信息都能抓住,说明即使我们不利用图片信息,也能从用户的click session中挖掘出相似风格的listing。
这里的描述很有意思,这也是一种很好的解决问题的思路,就是遇到难以解决的问题换一个角度切入也许有意想不到的效果,graph algorithms之所以横空出世一炮而红,很大程度上其实是因为给我们解决问题的思路提供了一个全新的角度,例如反欺诈的应用,我们以往可能会从用户的交易序列数据层面入手去做时间序列异常检测,或者是从直接根据欺诈用户的标签,使用有监督学习,特征工程+lgb一把梭的方式,或者是根据用户的一些关键特征做一些无监督异常检测的工作,而图算法提供给了我们一种全新的视角,从社交网络关系的层面出发去尝试解决问题,这是一种非常好的思考问题的方式。这也是为什么要在知识方面有一定广度的原因,更广泛的知识能够提供更多的可能的问题的解决方案。


