请问你知道分布式系统设计模式的分割日志思想么?
分割日志(Segmented Log)
将大文件切分为更容易处理的多个更小的文件。
问题背景
单一的日志文件可能会增长到很大,并且在程序启动时读取从而成为性能瓶颈。老的日志需要定时清理,但是对于一个大文件进行清理操作很费劲。
解决方案
将单一日志切分为多个,日志在达到一定大小时,会切换到新文件继续写。
//写入日志
public Long writeEntry(WALEntry entry) {
//判断是否需要另起新文件
maybeRoll();
//写入文件
return openSegment.writeEntry(entry);
}
private void maybeRoll() {
//如果当前文件大小超过最大日志文件大小
if (openSegment.
size() >= config.getMaxLogSize()) {
//强制刷盘
openSegment.flush();
//存入保存好的排序好的老日志文件列表
sortedSavedSegments.add(openSegment);
//获取文件最后一个日志id
long lastId = openSegment.getLastLogEntryId();
//根据日志id,另起一个新文件,打开
openSegment = WALSegment.open(lastId, config.getWalDir());
}
}
如果日志做了切分,那么需要快速以某个日志位置(或者日志序列号)定位到某个文件的机制。可以通过两种方式实现:
- 每一个日志切分文件的名称都是包含特定开头以及日志位置偏移量(或者日志序列号)
- 每一个日志序列号包含文件名称以及 transaction 偏移。
//创建文件名称
public static String createFileName(Long startIndex) {
//特定日志前缀_起始位置_日志后缀
return logPrefix + "_" + startIndex + "_" + logSuffix;
}
//从文件名称中提取日志偏移量
public static Long getBaseOffsetFromFileName(String fileName) {
String[] nameAndSuffix = fileName.split(logSuffix);
String[] prefixAndOffset = nameAndSuffix[0].split("_");
if (prefixAndOffset[0].equals(logPrefix))
return Long.parseLong(prefixAndOffset[1]);
return -1l;
}
在文件名包含这种信息之后,读操作就分为两步:
- 给定一个偏移(或者 transaction id),获取到大于这个偏移日志所在文件
- 从文件中读取所有大于这个偏移的日志
//给定偏移量,读取所有日志
public List<WALEntry> readFrom(Long startIndex) {
List<WALSegment> segments = getAllSegmentsContainingLogGreaterThan(startIndex);
return readWalEntriesFrom(startIndex, segments);
}
//给定偏移量,获取所有包含大于这个偏移量的日志文件
private List<WALSegment> getAllSegmentsContainingLogGreaterThan(Long startIndex) {
List<WALSegment> segments = new ArrayList<>();
//Start from the last segment to the first segment with starting offset less than startIndex
//This will get all the segments which have log entries more than the startIndex
for (int i = sortedSavedSegments.size() - 1; i >= 0; i--) {
WALSegment walSegment = sortedSavedSegments.get(i);
segments.add(walSegment);
if (walSegment.getBaseOffset() <= startIndex) {
break; // break for the first segment with baseoffset less than startIndex
}
}
if (openSegment.getBaseOffset() <= startIndex) {
segments.add(openSegment);
}
return segments;
}
举例
基本所有主流 MQ 的存储,例如 RocketMQ,Kafka 还有 Pulsar 的底层存储 BookKeeper,都运用了分段日志。
RocketMQ:
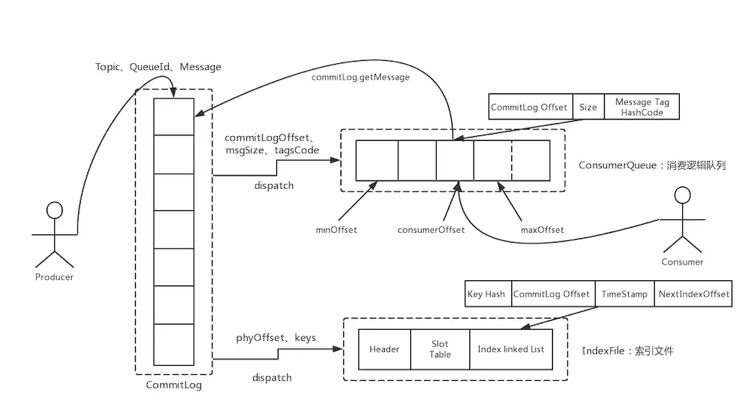
Kafka:

Pulsar存储实现BookKeeper:
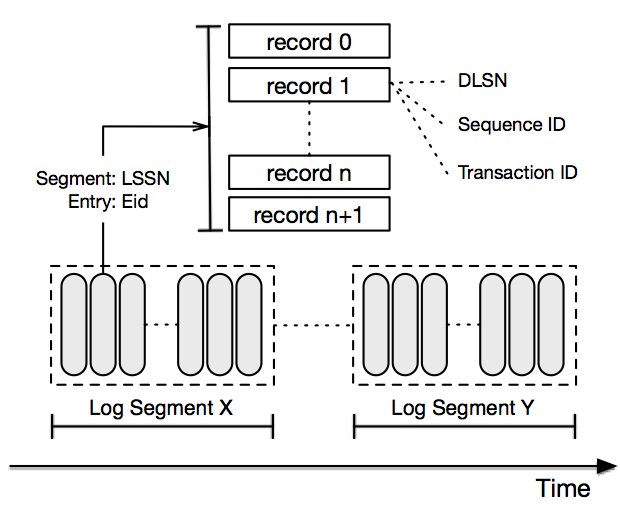
另外,基于一致性协议 Paxos 或者 Raft 的存储,一般会采用分段日志,例如 Zookeeper 以及 TiDB。
每日一刷,轻松提升技术,斩获各种offer:



