MIT 6.S081 Lab File System
- 2021 年 2 月 2 日
- 筆記
前言
打開自己的blog一看,居然三個月沒更新了…回想一下前幾個月,開題 + 實驗室雜活貌似也沒占非常多的時間,還是自己太懈怠了吧,掉線城和文明6真的是時間剎手(
不過好消息是把15445的所有lab都錘完了,最近一個月應該沒啥活干。立個flag,這個月更它個10篇blog,把15445的知識點、lab,以及6.S081想寫的東西都寫完。今天先做個復健,碼一下剛做完的lab8,以及xv6的file system的學習筆記。
壞消息是leetcode一道沒動,甚至主力啥語言啥框架還沒定下來,開學找實習可能要炸了orz…
這個lab不算難,總程式碼量也就幾十行,絕大多數時間拿來讀文件系統相關的程式碼了(兩三天吧),不過收穫也挺大,理清楚xv6文件系統的邏輯後,lab一個晚上就搞定了。因此這篇blog我會寫的簡單一些,大頭部分放在file system分析的blog中。
強烈推薦在做這個lab前把《xv6 book》中關於file system的章節全部看完,並詳細分析相關的程式碼。我的這篇關於xv6的file system的學習筆記可能對你有幫助:
TODO:(在碼了在碼了,但願今天能碼完)
Lab鏈接://pdos.csail.mit.edu/6.828/2019/labs/fs.html
都2021年了還在做2019的lab,這真的好嘛(
Part1 Large Files
xv6選擇的文件存儲介質是磁碟,通過 struct dinode 來描述一個文件在磁碟上存儲,並用 struct inode作為其對一個的struct dinode的拷貝,存儲在記憶體中:
// kernel/fs.h
struct dinode {
short type; // File type
short major; // T_DEVICE only
short minor; // T_DEVICE only
short nlink; // Number of links to inode in file system
uint size; // Size of file (bytes)
uint addrs[NDIRECT+1]; // Data block addresses
};
// kernel/file.h
// in-memory copy of an inode
struct inode {
uint dev; // Device number
uint inum; // Inode number
int ref; // Reference count
struct sleeplock lock; // protects everything below here
int valid; // inode has been read from disk?
short type; // copy of disk inode
short major;
short minor;
short nlink;
uint size;
uint addrs[NDIRECT + 1];
};
我們只關注其中的addrs。addrs記錄著文件所在磁碟的盤塊號,這個數組的容量為13,前12個地址是直接地址,即該文件的第 0 ~ 11 號盤塊,第13個地址是一個一級索引,用於索引文件的第 12 ~ 12 + 256 號盤塊,如下圖所示:
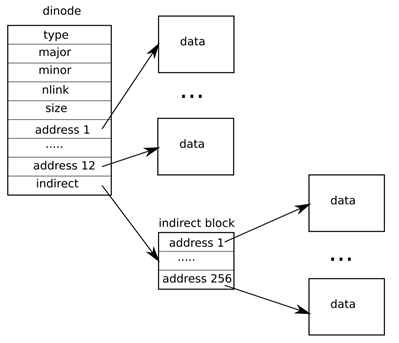
這樣,一個文件最多可以佔用 268 個盤塊。
bmap是xv6中非常重要的api,其返迴文件偏移量(bn * BSIZE)所對應的的磁碟盤塊號:
// kernel/fs.c
static uint
bmap(struct inode *ip, uint bn)
{
uint addr, *a;
struct buf *bp;
if(bn < NDIRECT){ // offset in in NDIRECT range
if((addr = ip->addrs[bn]) == 0)
ip->addrs[bn] = addr = balloc(ip->dev);
return addr;
}
bn -= NDIRECT;
if(bn < NINDIRECT){
// Load indirect block. If indirect block is not exist, allocate it.
if((addr = ip->addrs[NDIRECT]) == 0)
ip->addrs[NDIRECT] = addr = balloc(ip->dev);
bp = bread(ip->dev, addr);
a = (uint*)bp->data;
if((addr = a[bn]) == 0){
a[bn] = addr = balloc(ip->dev);
log_write(bp);
}
brelse(bp);
return addr;
}
當xv6刪除文件時,要將文件所對應的盤塊一一釋放。如果這個文件存在一級索引塊,那麼除了釋放間接索引塊的表項所對應的盤塊之外,還要將這塊一級索引塊一併釋放:
static void
itrunc(struct inode *ip)
{
int i, j;
struct buf *bp;
uint *a;
for(i = 0; i < NDIRECT; i++){ // free direct block
if(ip->addrs[i]){
bfree(ip->dev, ip->addrs[i]);
ip->addrs[i] = 0;
}
}
if(ip->addrs[NDIRECT]){
bp = bread(ip->dev, ip->addrs[NDIRECT]);
a = (uint*)bp->data;
for(j = 0; j < NINDIRECT; j++){ // free block indexed by indirect-block
if(a[j])
bfree(ip->dev, a[j]);
}
brelse(bp);
bfree(ip->dev, ip->addrs[NDIRECT]); // free indirect-block
ip->addrs[NDIRECT] = 0;
}
}
Part1要求我們為xv6的文件系統增添一個二級索引。一個二級索引佔據一個盤塊,共計有256個表項,每個表項都指向一個一級索引塊。由於addr的容量仍然是13,因此需要犧牲一個一級索引項,一個文件的盤塊索引項也變成了 11個直接索引 + 1個一級索引 + 1個二級索引,共計可以索引 11 + 256 + 256 *256 = 65803個盤塊,由此實現了最大文件大小的擴展。一個二級索引塊的例子如下:
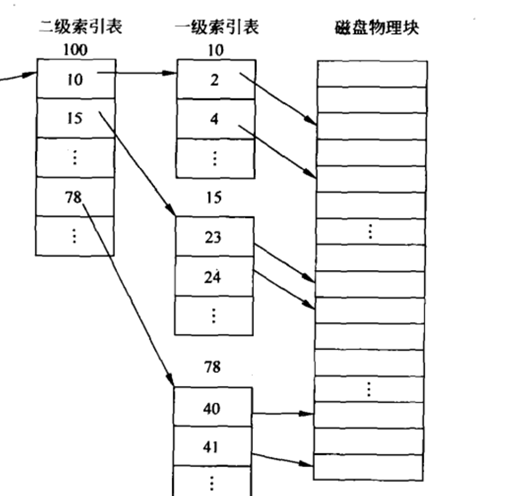
我們首先要修改一下宏 NINDIRECT,將其值改為11,並修改struct dinode和struct inode中addr的定義部分,以及有關文件大小的宏:
// kernel/fs.h
#define NDIRECT 11
#define NINDIRECT (BSIZE / sizeof(uint))
#define NDINDIRECT NINDIRECT * NINDIRECT
#define MAXFILE (NDIRECT + NINDIRECT + NDINDIRECT)
還有一些宏(NBLOCKS等)需要修改,在相應的實驗手冊中已經指出,因此不再贅述了。
隨後需要修改兩個api:bmap和itrunc。在bmap中添加計算二級索引的相關程式碼,以及對應的盤塊的分配程式碼:
static uint
bmap(struct inode *ip, uint bn)
{
uint addr, *a;
struct buf *bp;
// offset in direct-block range
if(bn < NDIRECT){
if((addr = ip->addrs[bn]) == 0)
ip->addrs[bn] = addr = balloc(ip->dev);
return addr;
}
bn -= NDIRECT;
// offset in primary-index range
if(bn < NINDIRECT){
// Load indirect block, allocating if necessary.
if((addr = ip->addrs[NDIRECT]) == 0)
ip->addrs[NDIRECT] = addr = balloc(ip->dev); // allocate a block on disk
bp = bread(ip->dev, addr);
a = (uint*)bp->data;
if((addr = a[bn]) == 0){
a[bn] = addr = balloc(ip->dev);
log_write(bp);
}
brelse(bp);
return addr;
}
bn -= NINDIRECT;
struct buf *dindbuf, *indbuf; // double-indirect block buffer, indirect block buffer
// offset in secondary-index range
if (bn < NDINDIRECT) {
// get the DIRECT index block. if it's not exist, allocate it.
if ((addr = ip->addrs[NDIRECT + 1]) == 0)
ip->addrs[NDIRECT + 1] = addr = balloc(ip->dev);
dindbuf = bread(ip->dev, addr); // map it into buffer
uint *dind = (uint *)dindbuf->data;
if(dind[bn / NINDIRECT] == 0) { // allocate a indirect block for double-indirect index and log it.
dind[bn / NINDIRECT] = balloc(ip->dev);
log_write(dindbuf);
}
indbuf = bread(ip->dev, dind[bn / NINDIRECT]);
uint *ind = (uint *)indbuf->data;
if (ind[bn % NINDIRECT] == 0) { // allocate file block if it's not exist.
ind[bn % NINDIRECT] = balloc(ip->dev);
log_write(indbuf);
}
brelse(dindbuf);
brelse(indbuf);
return ind[bn % NINDIRECT];
}
// out of range
panic("bmap: out of range");
}
此外,還要修改itrunc這個方法,添加從二級索引中釋放盤塊的支援程式碼:
static void
itrunc(struct inode *ip)
{
int i, j;
struct buf *bp;
uint *a;
// release DIRECT block
for(i = 0; i < NDIRECT; i++){
if(ip->addrs[i]){
bfree(ip->dev, ip->addrs[i]);
ip->addrs[i] = 0;
}
}
// release primary-index block
if(ip->addrs[NDIRECT]){
bp = bread(ip->dev, ip->addrs[NDIRECT]);
a = (uint*)bp->data;
for(j = 0; j < NINDIRECT; j++){
if(a[j])
bfree(ip->dev, a[j]);
}
brelse(bp);
bfree(ip->dev, ip->addrs[NDIRECT]);
ip->addrs[NDIRECT] = 0;
}
// release secondary-index block
if (ip->addrs[NDIRECT + 1]) {
struct buf *dinddbuf, *indbuf;
uint *dind, *ind;
dinddbuf = bread(ip->dev, ip->addrs[NDIRECT + 1]);
dind = (uint *)dinddbuf->data;
for (int k = 0; k < NINDIRECT; k++) {
if (dind[k]) {
indbuf = bread(ip->dev, dind[k]);
ind = (uint *)indbuf->data;
for (int l = 0; l < NINDIRECT; l++) {
bfree(ip->dev, ind[l]);
ind[l] = 0;
}
brelse(indbuf);
bfree(ip->dev, dind[k]);
}
}
brelse(dinddbuf);
bfree(ip->dev, ip->addrs[NINDIRECT + 1]);
}
ip->size = 0;
iupdate(ip);
}
這段程式碼里有兩個值得注意的地方:
1)一級索引塊、二級索引塊剛開始並沒有被分配,只有在需要使用的時候才會被分配
2)在xv6中使用了緩衝區來減少I/O次數,一切對盤塊的讀寫操作都首先在緩衝塊上進行,並且為了維持磁碟中元數據(super block)的一致性,一切寫盤塊的操作都需要調用log_write將寫操作添加到日誌中。在bmap中涉及到了兩種對盤塊的寫操作:對二級索引塊的寫操作(向其中添加表項,一個表項對應一個一級索引塊)和對一級索引塊的寫操作(向其中添加表項,一個表項對應一個文件內容盤塊)。雖然bmap也會分配指向文件內容的盤塊,但對這個盤塊的寫操作並不是在bmap中進行的,而是在其他api中進行的,因此無需將這個塊錄入到日誌中。
雖然struct dinode和struct inode中也包含了type、major、nlink、size等成員,但讀過相關的程式碼後你會發現,這些成員都無需修改,尤其是size這個成員很具有迷惑性,我們分配了盤塊後這個成員看起來應該要增加的,但實際上這是一個沒被用到的成員。畢竟xv6隻是一個教學系統,不應對其苛求太多。這部分的分析都在我的關於file system的blog中有詳細的說明。
Part1的相關程式碼也就這麼多了,只要認真讀下來file system相關的程式碼,並認真按照Hint來做,這就算是個白送的實驗。不過比較要命的是usertests中的writebig測試,它會寫一個MAXFILE大小的文件(添加大文件支援後,這個值從原來的2K變成了20W),會花費更長的測試時間。
xv6 kernel is booting
virtio disk init 0
init: starting sh
$ bigfile
..................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................
wrote 65803 blocks
bigfile done; ok
Part2 symlink
這部分實驗要求我們為文件系統增添對符號鏈接(symbolic link)(也被稱為軟鏈接)的支援。為此我們首先簡要了解一下xv6中的硬鏈接和軟鏈接的含義。
在xv6中,每個文件擁有唯一的struct dinode和struct inode,更好的一種理解方法是,struct inode是一個文件控制塊,存儲著這個文件相關的元數據,一切對文件的讀、寫、打開、關閉、刪除等操作都需要通過inode來完成。而很多時候,我們需要一個文件可以出現在多個目錄下的支援(例如說多用戶作業系統,每個用戶都擁有一個自己的目錄,它們希望共享某一文件)。如下圖所示,這些文件的路徑(鏈接)都導向了同一個inode:
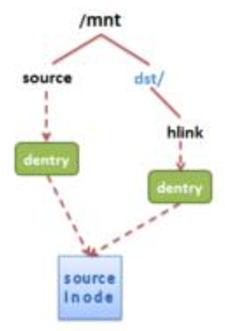
這種可以直接索引到inode的鏈接即是硬鏈接,本質上它是目錄文件中的一個條目,根據這個條目,可以(準確的說是必定)獲得該文件的inode。在xv6的api中,通過sys_link創建一個文件的硬鏈接,其中的核心api是 dirlink:
// Write a new directory entry (name, inum) into the directory dp.
int
dirlink(struct inode *dp, char *name, uint inum)
{
int off;
struct dirent de;
struct inode *ip;
// Check that name is not present.
if((ip = dirlookup(dp, name, 0)) != 0){
iput(ip);
return -1;
}
// Look for an empty dirent.
for(off = 0; off < dp->size; off += sizeof(de)){
if(readi(dp, 0, (uint64)&de, off, sizeof(de)) != sizeof(de))
panic("dirlink read");
if(de.inum == 0)
break;
}
strncpy(de.name, name, DIRSIZ);
de.inum = inum;
if(writei(dp, 0, (uint64)&de, off, sizeof(de)) != sizeof(de))
panic("dirlink");
return 0;
}
在sys_link中調用dirlink時,傳入的參數inum為目標文件的inode編號,該編號被添加到目錄表項中;這樣我們也可以理解為什麼調用ll時,會發現同一個文件的硬鏈接對應的inode號是相同的了;硬鏈接如果存在,那麼其對應的inode必須存在。inode通過維護一個nlink記錄著硬鏈接的數量。當該inode新增一個硬鏈接時,其值便增1;當某個路徑下的硬鏈接被刪除時,nlink要減1,當值減至0時,說明該文件已經無法通過路徑訪問到,這時才能釋放相應的文件。
軟鏈接的定義則不同,我們可以看一下symlink的man page中的部分內容:
symlink() creates a symbolic link named linkpath which contains the string target.
Symbolic links are interpreted at run time as if the contents of the link had been substituted into the path being followed to find a file or directory.
A symbolic link (also known as a soft link) may point to an existing file or to a nonexistent one; the latter case is known as a dangling link.
軟鏈接並不會增加nlink的數量,且可以指向一個不存在的路徑。軟鏈接也可以指向一個軟鏈接,遇到這種情況時將會遞歸,直至找到相應的硬鏈接(或者達到最大遞歸深度後返回錯誤)。
在本Part中,要求我們實現以下內容:
1)實現一個新的系統調用 sys_symlink,通過該系統調用可以創建一個軟鏈接;
2)為sys_open提供軟鏈接的打開支援(通過軟鏈接打開文件、O_NOFOLLOW);
只要理解了軟鏈接的作用後,實現這個lab的思路也比較容易了,這個Part實現的思路也很多,我使用的是最簡單最容易想到的:
1)將軟鏈接本身也看做是一個文件,即軟鏈接本身也有自己的dinode和inode,其文件內容也只是一行字元串,表徵著軟鏈接指向的文件的路徑。創建軟鏈接時,要為其分配一個inode
2)將軟鏈接的inode添加到目錄條目中,注意要避免命名衝突
uint64
sys_symlink(void)
{
char target[MAXPATH + 1], path[MAXPATH + 1], name[MAXPATH + 1];
memset((void *)target, 0, MAXPATH + 1);
memset((void *)path, 0, MAXPATH + 1);
if (argstr(0, target, MAXPATH) < 0 || argstr(1, path, MAXPATH) < 0) {
return -1;
}
begin_op(ROOTDEV);
// get parent inode
struct inode *iparent, *isym;
if ((iparent = nameiparent((char *)path, (char *)name)) == 0) {
end_op(ROOTDEV);
return -1;
}
// avoid name conflict
// do not hold ilock for iparent
uint off;
if ((isym = dirlookup(iparent, name, &off)) != 0) {
// printf("symlink name conflict with an existing file\n");
// iunlockput(iparent);
iput(iparent);
end_op(ROOTDEV);
return -1;
}
// allocate a dinode for symlink. isym is locked when it func create return
// after this operation, symlink entry is added under corresponding path
if ((isym = create(path, T_SYMLINK, 0, 0)) == 0) {
panic("create inode for symlink error"); // panic is not suitable, but simplify our situations.
}
// fill symlink file content with targetpath
int retval = 0;
uint pathlen = strlen((char *)target);
uint r, total;
r = total = 0;
while (total != pathlen) {
if ((r = writei(isym, 0, (uint64)(target + total), total, pathlen - total)) > 0) {
total += r;
} else {
retval = -1;
break;
}
}
// release
iunlockput(isym);
iput(iparent);
end_op(ROOTDEV);
return retval;
}
這樣我們也可以理解為什麼在一些文件系統上,同一個文件的軟鏈接和硬鏈接的inode可能不同,因為軟鏈接本身也是一個文件,有自己的inode,而硬鏈接只是一個目錄中的條目,該條目索引到了對應的inode。
然後修改sys_open,當發現打開的path對應的是一個軟鏈接時,調用divesymlink,獲得該軟鏈接指向的文件的inode。如果使用了O_NOFOLLOW,說明我們希望打開的是軟鏈接這個文件本身,一般fstate會使用這個flag:
uint64
sys_open(void)
{
char path[MAXPATH];
int fd, omode;
struct file *f;
struct inode *ip;
int n;
if((n = argstr(0, path, MAXPATH)) < 0 || argint(1, &omode) < 0)
return -1;
begin_op(ROOTDEV);
if(omode & O_CREATE){
ip = create(path, T_FILE, 0, 0);
if(ip == 0){
end_op(ROOTDEV);
return -1;
}
} else {
if((ip = namei(path)) == 0){
end_op(ROOTDEV);
return -1;
}
ilock(ip);
if(ip->type == T_DIR && omode != O_RDONLY){
iunlockput(ip);
end_op(ROOTDEV);
return -1;
}
}
/**************************
* SYMLINK *
*************************/
if (ip->type == T_SYMLINK && (omode & O_NOFOLLOW) == 0) {
ip = divesymlink(ip);
if (ip == 0) { // link target not exist
end_op(ROOTDEV);
return -1;
}
}
if(ip->type == T_DEVICE && (ip->major < 0 || ip->major >= NDEV)){
iunlockput(ip);
end_op(ROOTDEV);
return -1;
}
if((f = filealloc()) == 0 || (fd = fdalloc(f)) < 0){
if(f)
fileclose(f);
iunlockput(ip);
end_op(ROOTDEV);
return -1;
}
if(ip->type == T_DEVICE){
f->type = FD_DEVICE;
f->major = ip->major;
f->minor = ip->minor;
} else {
f->type = FD_INODE;
}
f->ip = ip; // ref is here, so this function doesn't call iput
f->off = 0;
f->readable = !(omode & O_WRONLY);
f->writable = (omode & O_WRONLY) || (omode & O_RDWR);
iunlock(ip);
end_op(ROOTDEV);
return fd;
}
divesymlink的實現如下,其的參數為軟鏈接文件的inode,返回軟鏈接最終指向的文件的inode,如果這個文件不存在則返回0。根據Hint,divesymlink還要解決軟鏈接之間的環路引用問題,這裡我們簡單的通過遞歸深度來判斷,當深度大於10時,認為軟鏈接最終指向的文件不存在:
static struct inode *
divesymlink(struct inode *isym)
{
struct inode *ip = isym;
char path[MAXPATH + 1];
uint len;
int deep = 0;
do {
// get linked target
// we don't know how long the file str is, so we expect once read could get fullpath.
len = readi(ip, 0, (uint64)path, 0, MAXPATH);
if (readi(ip, 0, (uint64)(path + len), len, MAXPATH + 1) != 0)
panic("divesymlink : short read");
iunlockput(ip);
if (++deep > 10) { // may cycle link
return 0;
}
if ((ip = namei((char *)path)) == 0) { // link target not exist
return 0;
}
ilock(ip);
} while (ip->type == T_SYMLINK);
return ip;
}
這樣Part2也解決了。比較棘手的是api的鎖獲取和鎖釋放,以及iput、iunlockput、iunlock這三個api的選擇。我在這裡簡單介紹一下:
1)iput會使ip->ref的數量減1(注意與ip->nlink區分開)。這個值記錄著外部所持有struct inode指針的總數量。當這個值減小到0時,說明沒有進程在訪問這個文件,此時要將icache中對應的struct inode釋放掉,但不會釋放對應的文件。
2)iunlock會釋放掉struct inode的鎖,這把鎖用來實現並發環境下的struct inode的原子訪問,即我們在查看struct inode中的成員(type、data等)時,必須持有這把鎖
3)iunlockput同時調用上述兩個函數;
即如果我們不需要訪問struct inode的成員時,應調用iunlock釋放掉inode的鎖,等需要訪問時再拿起這把鎖;當我們不再需要使用struct inode的指針時,要調用iput,棄用掉這個指針;
這樣symlinktest也可以Pass了,對應的usertests也可以全pass:
xv6 kernel is booting
virtio disk init 0
init: starting sh
$ symlinktest
Start: test symlinks
test symlinks: ok
Start: test concurrent symlinks
test concurrent symlinks: ok
$ usertests
usertests starting
test reparent2: OK
test pgbug: OK
test sbrkbugs: usertrap(): unexpected scause 0x000000000000000c pid=3210
sepc=0x00000000000044b2 stval=0x00000000000044b2
usertrap(): unexpected scause 0x000000000000000c pid=3211
sepc=0x00000000000044b2 stval=0x00000000000044b2
OK
test badarg: OK
test reparent: OK
test twochildren: OK
test forkfork: OK
test forkforkfork: OK
test argptest: OK
......
......
......
test opentest: OK
test writetest: OK
test writebig: OK
test createtest: OK
test openiput: OK
test exitiput: OK
test iput: OK
test mem: OK
test pipe1: OK
test preempt: kill... wait... OK
test exitwait: OK
test rmdot: OK
test fourteen: OK
test bigfile: OK
test dirfile: OK
test iref: OK
test forktest: OK
test bigdir: OK
ALL TESTS PASSED
後記
這個Lab不算難,絕大多數時間要花費在讀程式碼上。我這篇xv6 file system的學習筆記可能會比較幫助:
TODO: (在碼了在碼了,但願今天能碼完):

