Document-level Neural Relation Extraction with Edge-oriented Graphs 论文阅读
Background
-
论文动机
-
Entity relations can be better expressed through ==unique edge representations== formed as paths between nodes.(没有依据啊…)
许多graph-based model 都是基于node, 文章发现entity 之间的relation,可以通过节点之间的路径形成唯一的edge representation
entity之间的关系不唯一,为什么要规定representation要唯一呢?
-
每一个target entity的mentions对于entity之间的relation是非常重要的
-
-
论文贡献
- 本文提出了一种新颖的图神经模型(==面向边而非节点==),与现有的模型不同的是它专注于构造一种 unique 的节点和边,将信息encode到边表示(edge representation)而不是节点表示(node representation);
- 基于多实例学习(multi-instance learning,MIL)学习句子内和句子间的关系;
- 模型**==完全不依赖句法依赖工具==**(也就不会带来因为工具的误差带来的噪音问题),可以有效编码文档级别的关系依赖;
- 实验发现,inter-sentence 关系检测的结果对 intra-sentence 关系检测任务是有益的;
-
背景
异质网络:根据不同的边来区分网络的类型;
同质网络:虽节点不同,边的类型不同,但是把所有的节点当作同质关系进行处理,利用attention或者其他的方式自动进行区分。
Model
TASK definition: 给定标注好的document(entity与mentions),目标是抽取出所有entity pair的relation。

-
Sentence Encoding Layer
BiLSTM: The output of the encoder results in contextualized representations for each word of the input sentence.
-
Graph Layer
The contextualized word representations from encoder are used to construct a document-level graph structure. 来自编码器的context表示被用来构建文档级图结构。
-
Node construction (三种不同类型的节点构造)
在EoG模型中,有三种node: mention node、entity node、sentence node。
mention node:所有entity的mentions的集合。每一个mention node的representation是此mention的所有word embedding的平均;entity node:所有entity的集合,每一个entity node的representation是该entity所有的mentions的平均;sentence node:所有sentence的集合,每一个sentence node是该sentence中所有word embedding的平均。
除此之外,我们为了区别不同类型的node,还给每一个node的representation上concat对应类型的node embedding t。
-
mention node
\mathbf{n}_{m}=\left[\operatorname{avg}_{w_{i} \in m}\left(\mathbf{w}_{i}\right) ; \mathbf{t}_{m}\right]
-
entity node
\mathbf{n}_{e}=\left[\operatorname{avg}_{w_{i} \in e}\left(\mathbf{w}_{i}\right) ; \mathbf{t}_{e}\right]
-
sentence node
\mathbf{n}_{s}=\left[\operatorname{avg}_{w_{i} \in s}\left(\mathbf{w}_{i}\right) ; \mathbf{t}_{s}\right]
-
-
Edge construction 不同的节点根据不同的性质生成不同种类的边
上文的三种节点类型 边的类型有
种 即 [MM, MS, ME, SS, ES, EE ] 六种, mention-mention(MM)、mention-entity(ME)、mention-sentence(MS)、entity-sentence(ES)、sentence-sentence(SS)。
==Using heuristic rules (启发式规则)that stem from(源自) the natural associations between the elements of a document==(这个是怎么做到呢?)
其中,The elements of a document: mentions, entities, and sentence.
Connections between nodes are based on Pre-defined document-level interactions:
-
MM :更好表达共指信息,还有mention之间的交互,除了基本信息之外还加入了 上下文信息 context 和 距离信息 (distance embedding associated with the distance between the two mentions):
x_{MM}=[n_{m_i};n_{m_j};c_{m_i,m_j};d_{m_i,m_j}]
x_{MM}表示的是对于mention pair (m_i,m_j)的 MM edge,;
当i=1,j=2,有x_{MM}=[n_{m_1};n_{m_2};c_{m_1,m_2};d_{m_1,m_2}];
上下文信息:主要是应对类似it这种指代方法,否则不好推断此类节点的表达;其中 a_i表示sentence的第i个word对此mention pair的重要性程度,也就是attention weight.
\alpha_{k,i}=n^T_{m_k}w_i \\ a_{k,i}=\frac{exp(\alpha_{k,i})}{\sum_{j\in[1,n],j\not\in m_k}exp(\alpha_{k,j})} \\ a_i=(a_{1,i}+ a_{2,i})/2 \\ c_{m_1,m_2}=H^Ta \\ k=\{1,2\}
-
MS: 将mention与此mention所在的sentence node进行连接;
-
**ME: **连接所有的mention与其对应的entity;
-
SS: 将所有的sentence node进行连接,以获得non-local information.更好的表达在长距离上的依赖关系,相比mention,句子的数目少很多,在整体上寻找相关性;
\mathrm{x}_{\mathrm{SS}}=\left[\mathrm{n}_{s_i} ; \mathrm{n}_{s_j}; \mathrm{d}_{s_i,s_j}\right]
We connect all sentence nodes in the graph.
-
ES: 如果一个sentence中至少存在一个entity的mention,那么我们将sentence node与entity node进行连接;
\mathrm{x}_{\mathrm{MS}}=\left[\mathrm{n}_{e} ; \mathrm{n}_{s}\right]
-
EE:
无论我们建立什么类型的边节点关系 最终的目的都是寻找 EE 之间是否存在关系;异构的边应该统一到相同的表达中: 我们最终目的是提取出entity pair的relation,所以我们对所有的edge representation都做一个线性变换,从而让其维度一致
\mathbf{e}_{z}^{(1)}=\mathbf{W}_{z} \mathbf{x}_{z}
其中,z \in[\mathrm{MM}, \mathrm{MS}, \mathrm{ME}, \mathrm{SS}, \mathrm{ES}], \mathbf{e}_{z}^{(1)} is an edge representation of length 1;
把不同边的类型根据不同的矩阵转换映射到相同的空间当中来进行后续的推导;
-
-
-
Inference Layer
由于我们没有直接的EE edge,所以我们需要得到entity之间的唯一路径的表示,来产生EE edge的representation。这里使用了two-step inference mechanism来实现这一点。
-
The first step: 利用中间节点 k 在两个节点 i 和 j 之间产生一条路径,如下:
f\left(\mathbf{e}_{i k}^{(l)}, \mathbf{e}_{k j}^{(l)}\right)=\sigma\left(\mathbf{e}_{i k}^{(l)} \odot\left(\mathbf{W} \mathbf{e}_{k j}^{(l)}\right)\right)
-
The second step: 将原始edge(如果存在的话)与新产生的edge进行聚合,如下:
e^{(2l)}_{ij}=\beta e^{(2l)}_{ij}+(1-\beta)\sum_{k\not=i,j}f(e^{(l)}_{ik},e^{(l)}_{kj})
重复上述两步N次,我们就可以得到比较充分混合的EE edge。通常情况下,\beta
==实际上,这一步就是为了解决logical reasoning。==
-
-
Classification Layer
这里使用softmax进行分类,因为实验所使用的两个数据集其实都是每一个entity pair都只有一个relation。具体公式:
y=softmax(W_ce_{EE}+b_c)
Experiment
-
数据集: CDR、GDA
-
实验结果:
EoG(Full): 全连接;
The graph node all connected each other, including the E node.
EoG(NoInf): 取消推理模块;
No inference model, where the iterative algorithm is ignored.
EoG(Sen): 单句内训练,而非文档;
Trained on sentence instead of document.
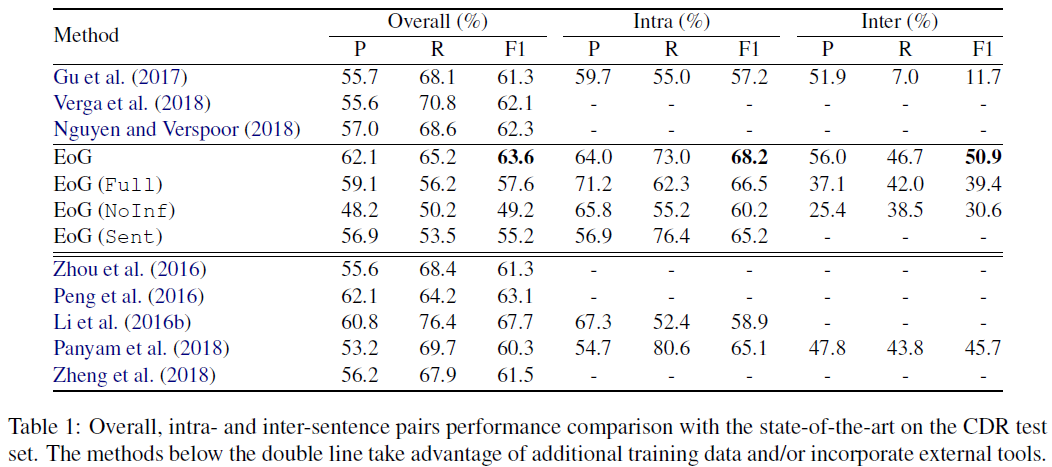


- 分析与讨论

SS_{direct}:只连接相接的sentence node(顺序连接)
SS_{direct} 只能捕获到局部的信息,收敛速度慢,同时也证明了句子间信息抽取的有效性;
结论:SS 仅需要更少的推理环节就可以达到收敛的效果;

当entity pair之间相差4句以上时,EoG(full)结果明显要好,这说明原始的EoG忽略了一些重要节点之间的交互信息,那么能不能让模型自动选择哪些节点要交互,哪些节点不要交互呢?(在LSR就是这么做的)除此之外,作者还对不同的component进行了消融实验。如下:

去掉SS对结果影响巨大,这说明对于document-level RE,提取inter-sentence之间的交互信息是非常重要的,另外,MM似乎对结果影响最小,但是我认为MM对于entity pair的relation identification是非常重要的,只是EoG里面构造的方式不对,在之后的GAIN模型里面,可以看到MM对结果提升巨大,当然构建方式不一样。


