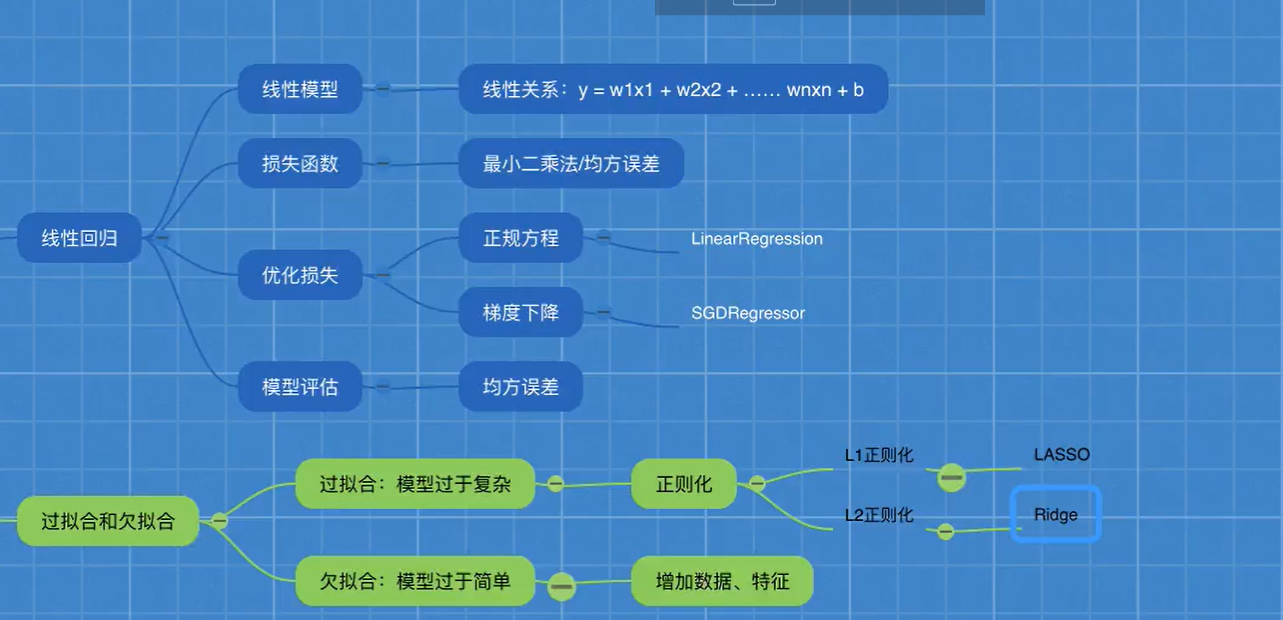
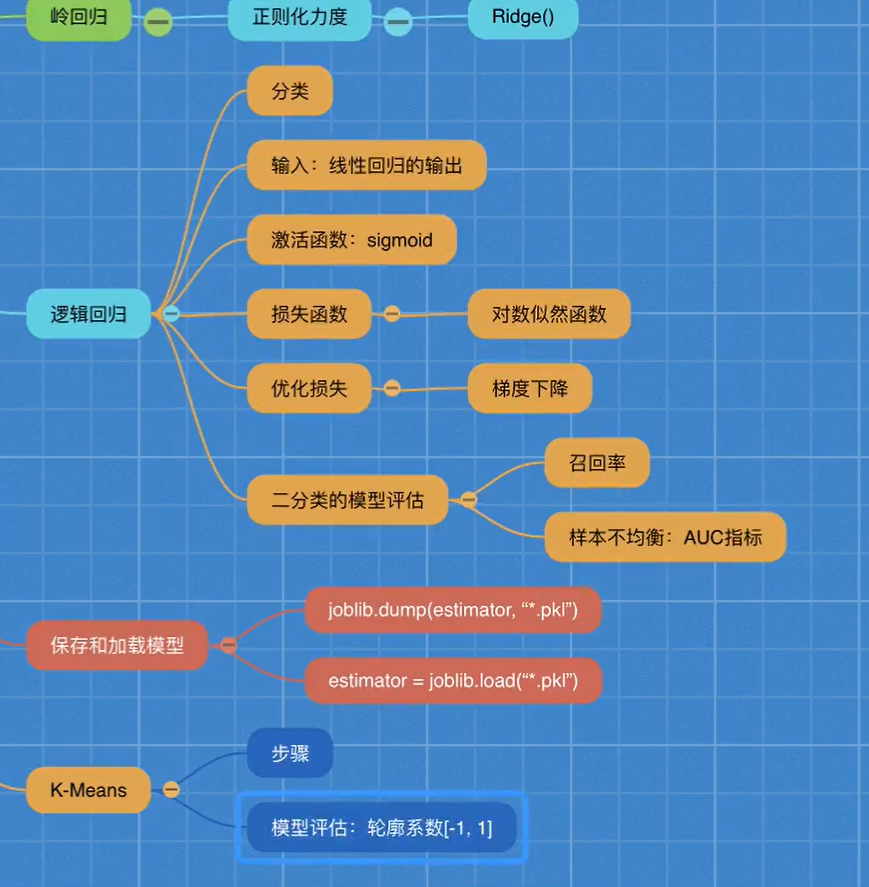
机器学习7-模型保存&无监督学习
模型保存和加载
sklearn模型的保存和加载API
- from sklearn.externals import joblib
- 保存:joblib.dump(rf, ‘test.pkl’)
- 加载:estimator = joblib.load(‘test.pkl’)
线性回归的模型保存加载案例
def linear3(): """ 岭回归的优化方法对波士顿房价预测 """ #获取数据 boston=load_boston() #划分数据集 x_train,x_test,y_train,y_test=train_test_split(boston.data,boston.target,random_state=22) #标准化 transfer=StandardScaler() x_train=transfer.fit_transform(x_train) x_test=transfer.transform(x_test) #预估器 # estimator=Ridge(alpha=0.0001, max_iter=100000) # estimator.fit(x_train,y_train) #保存模型 # joblib.dump(estimator,"my_ridge.pkl") #加载模型 estimator=joblib.load("my_ridge.pkl") #得出模型 print("岭回归-权重系数为:\n",estimator.coef_) print("岭回归-偏置为:\n",estimator.intercept_ ) #模型评估 y_predict = estimator.predict(x_test) print("预测房价:\n", y_predict) error = mean_squared_error(y_test, y_predict) print("岭回归-均方差误差:\n", error) return None if __name__ == '__main__': # linear1() # linear2() linear3()
保存:保存训练完结束的模型
加载:加载已有的模型,去进行预测结果和之前的模型一样
无监督学习-K-means算法
K-means原理
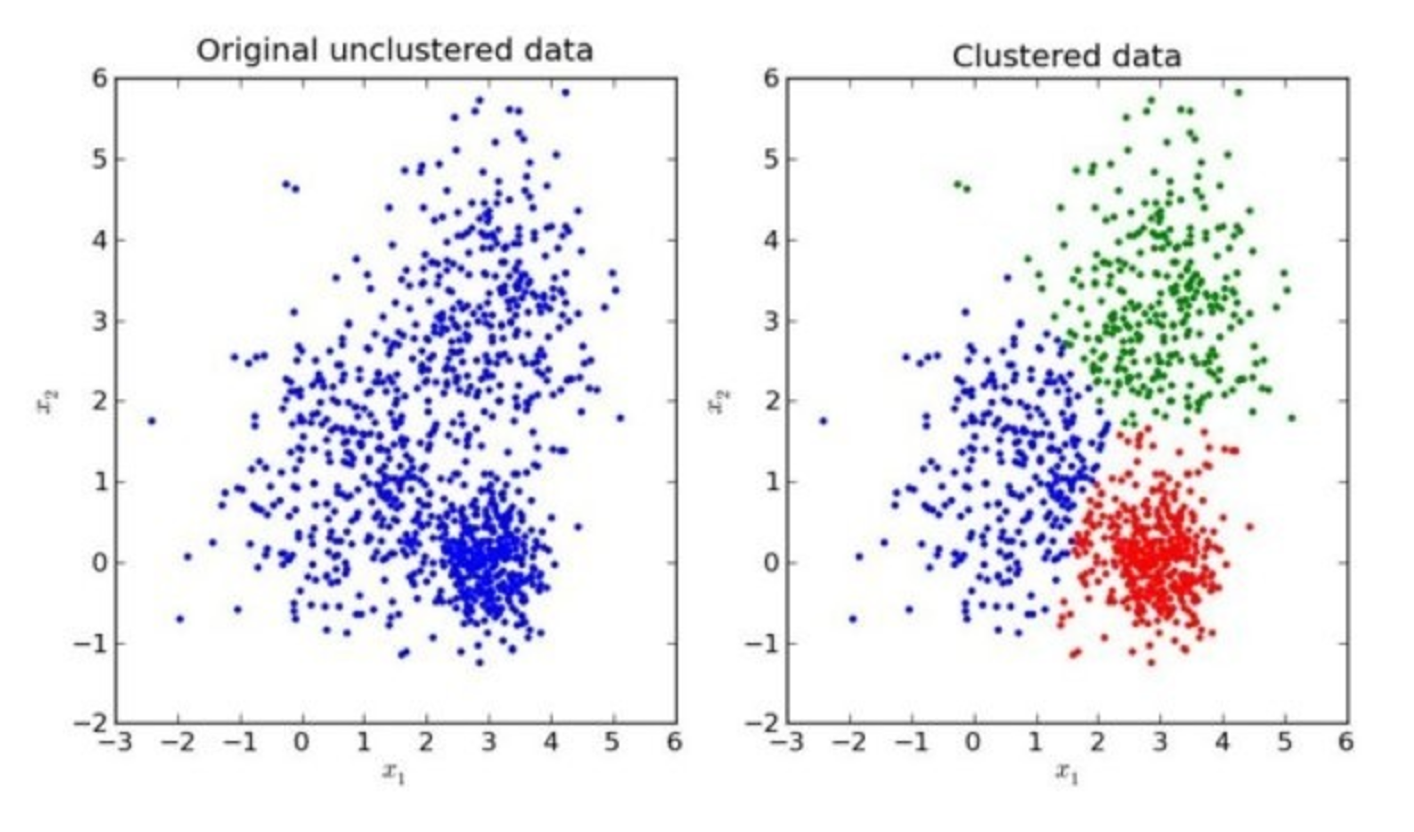
我们先来看一下一个K-means的聚类效果图
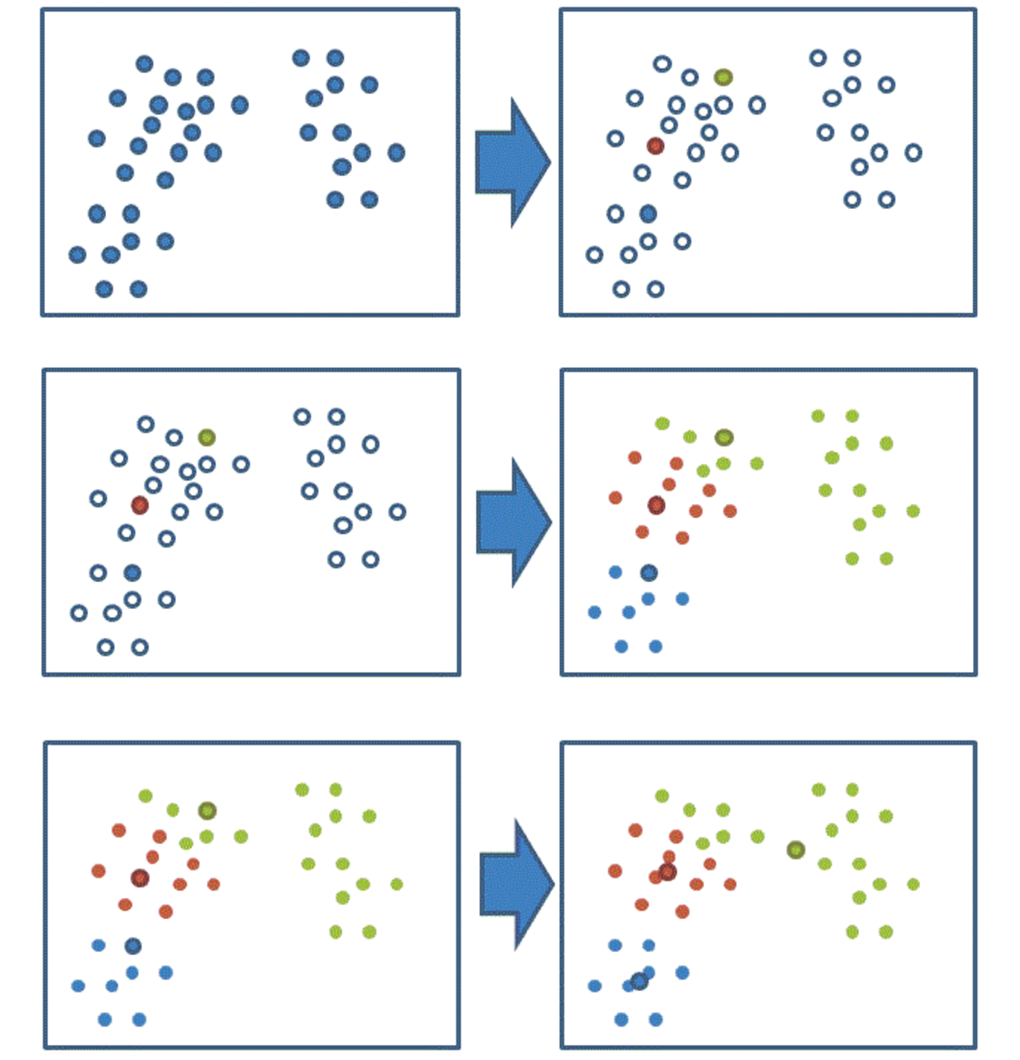
K-means聚类步骤
- 随机设置K个特征空间内的点作为初始的聚类中心
- 2、对于其他每个点计算到K个中心的距离,未知的点选择最近的一个聚类中心点作为标记类别
- 3、接着对着标记的聚类中心之后,重新计算出每个聚类的新中心点(平均值)
- 4、如果计算得出的新中心点与原中心点一样,那么结束,否则重新进行第二步过程
我们以一张图来解释效果
K-meansAPI
- sklearn.cluster.KMeans(n_clusters=8,init=‘k-means++’)
- k-means聚类
- n_clusters:开始的聚类中心数量
- init:初始化方法,默认为’k-means ++’
- labels_:默认标记的类型,可以和真实值比较(不是值比较)
案例:k-means对Instacart Market用户聚类
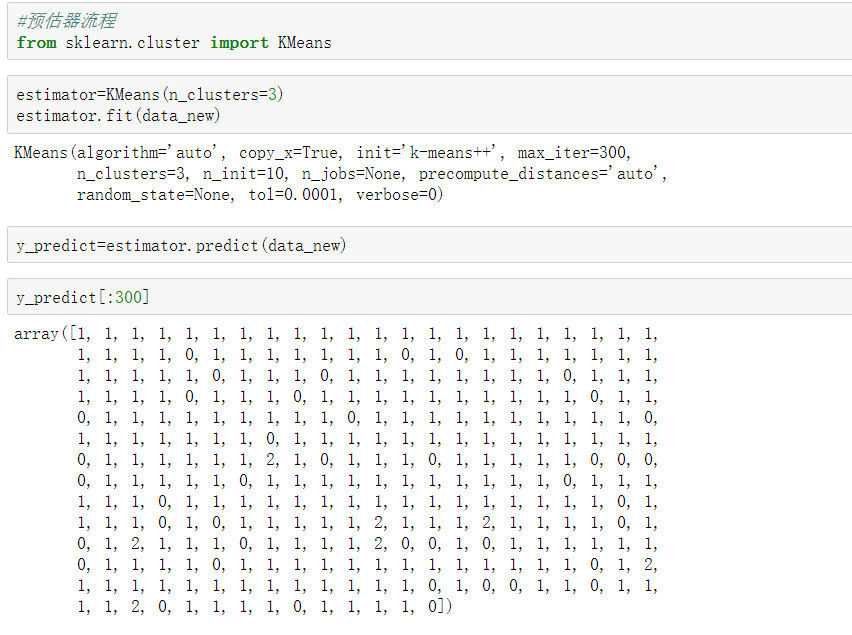
如何评估聚类的效果?
Kmeans性能评估指标
轮廓系数
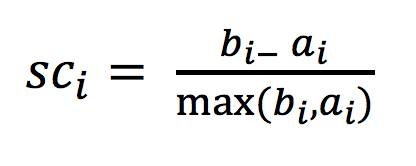
轮廓系数值分析
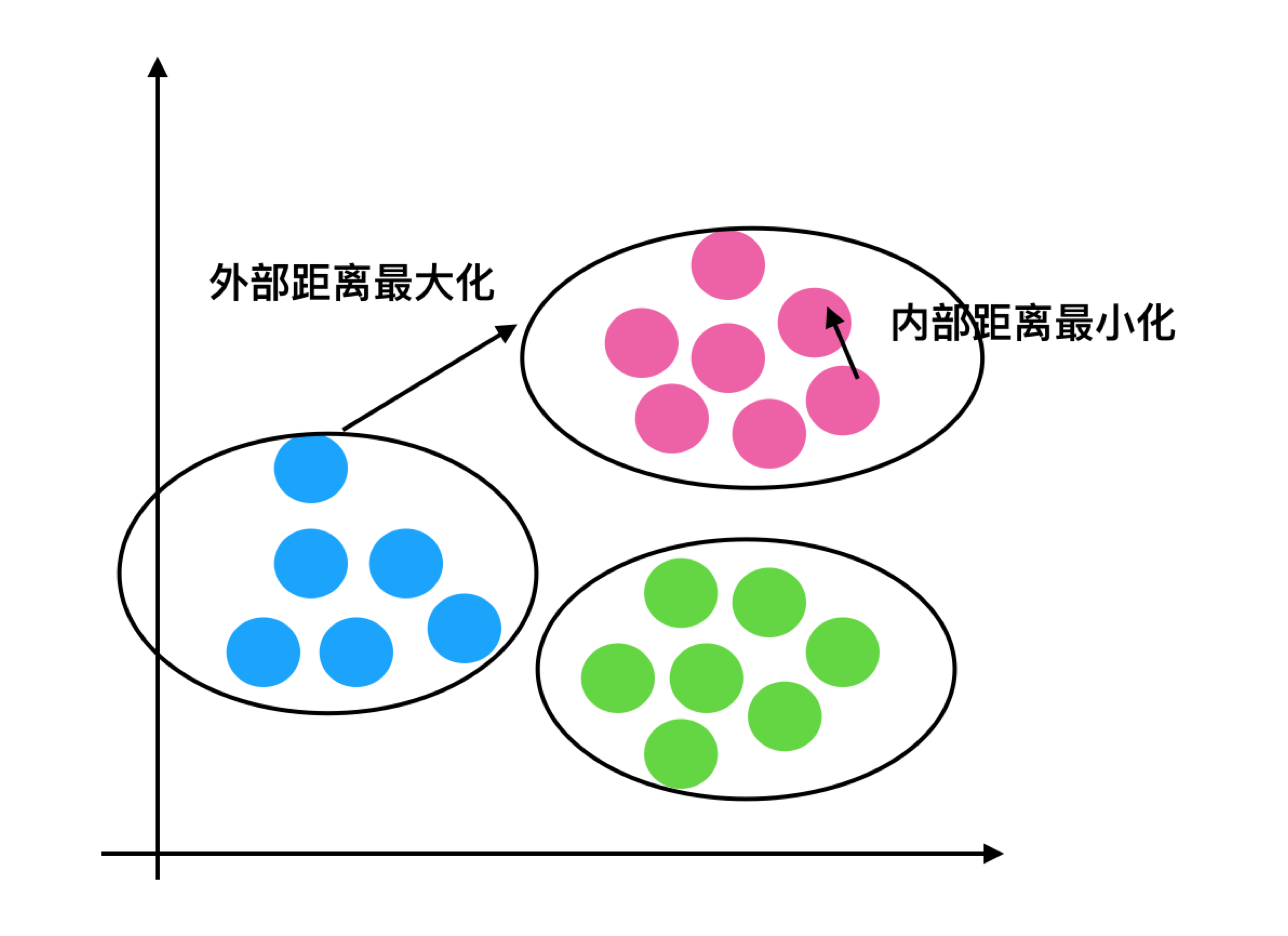
分析过程(我们以一个蓝1点为例)
-
1、计算出蓝1离本身族群所有点的距离的平均值a_i
-
2、蓝1到其它两个族群的距离计算出平均值红平均,绿平均,取最小的那个距离作为b_i
- 根据公式:极端值考虑:如果b_i >>a_i: 那么公式结果趋近于1;如果a_i>>>b_i: 那么公式结果趋近于-1
结论
如果b_i>>a_i:趋近于1效果越好, b_i<<a_i:趋近于-1,效果不好。轮廓系数的值是介于 [-1,1] ,越趋近于1代表内聚度和分离度都相对较优。
轮廓系数API
- sklearn.metrics.silhouette_score(X, labels)
- 计算所有样本的平均轮廓系数
- X:特征值
- labels:被聚类标记的目标值
案例-聚类评估

K-means总结
- 特点分析:采用迭代式算法,直观易懂并且非常实用
- 缺点:容易收敛到局部最优解(多次聚类)
回归与聚类整体算法总结