数据处理基础(二)
- 2019 年 11 月 28 日
- 筆記

参考:
- 概率论第四版
- 《实验设计与数据处理》化学工业出版社
误差的正态分布
正态分布
https://blog.csdn.net/weixin_44510615/article/details/103196607
补充概率论正态分布的知识:
设随机变量 具有概率密度

在这里插入图片描述
其中

为常数,则称

服从参数为
的正态分布,即

分布函数:

在这里插入图片描述
二、标准正态分布

密度函数

在这里插入图片描述
分布函数

在这里插入图片描述
三、性质、计算

- 若

在这里插入图片描述
- 若

在这里插入图片描述

在这里插入图片描述

在这里插入图片描述
置信区间 置信水平
置信区间是指由样本统计量所构造的总体参数的估计区间。在统计学中,一个概率样本的置信区间(Confidence interval)是对这个样本的某个总体参数的区间估计。
最常出现的对置信区间的错误理解:
在95%置信区间内,有95%的概率包括真实参数 (错误!!)


是显著性水平(例:0.05或0.10)

指置信水平(例:95%或90%)
看下面题

在这里插入图片描述
第一步:求一个样本的均值 第二步:计算出标准差。 第三步:查表,根据

查t分布数据表,代入正态分布公式求解

在这里插入图片描述

在这里插入图片描述
了解t分布
t分布
t-分布(t-distribution)用于根据小样本来估计呈正态分布且方差未知的总体的均值。如果总体方差已知(例如在样本数量足够多时)
假设X服从标准正态分布N(0,1),Y服从

卡方分布,那么

的分布称为自由度为n的t分布,记为 Z~t(n)
概率密度函数

在这里插入图片描述

在这里插入图片描述
参数估计
参数估计(parameter estimation),统计推断的一种。
根据从总体中抽取的随机样本来估计总体分布中未知参数的过程。
从估计形式看,区分为点估计与区间估计:从构造估计量的方法讲,有矩法估计、最小二乘估计、似然估计、贝叶斯估计等。
点估计
设总体 X 的分布函数形式已知, 但它的一个或多个参数为未知, 借助于总体 X 的一个样本来估计总体未知参数的值的问题称为点估计问题.
- 矩估计法
$mu$ 就是实验数据的均值$overline{x}$
$sigma^2$就是实验数据的方差$s^2$

在这里插入图片描述

在这里插入图片描述

在这里插入图片描述

在这里插入图片描述
矩估计法的区间估计

在这里插入图片描述

在这里插入图片描述

在这里插入图片描述
最大似然估计法
关于最大似然估计,有一个黑球和白球的栗子十分经典,初始来源已经很难考究。
设一个盒子里装有一定量的白球和黑球,试估计其中黑球比例 p 。假定进行 10 次有放回的抽取,抽到 3 个黑球。黑球个数

在这里插入图片描述
发生这一结果的概率

在这里插入图片描述
p=0.1时, P = 0.0574;p = 0.4 时, P = 0.215;p = 0.3时, P = 0.2668 。显然,取不同的p 得到的P有大有小,在我们已得到样本数据后,P为最大值时是最符合样本数据的。
极大似然估计方法的基本思想是以最大概率解释样本数据。
在数理统计学中,似然函数是一种关于统计模型中的参数的函数,表示模型参数中的似然性。

在这里插入图片描述 解法
- 构造似然函数L(θ),就是概率函数相加
- 取对数:
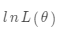
- 求导,计算极值
- 解方程,得到






