knn算法,识别简单验证码图片
- 2019 年 11 月 27 日
- 筆記
引言:为什么学习这个呢?
这个算是机器学习,最入门的一点东东
这里介绍两种方法:
1.直接调用第三方库进行识别,缺点:存在部分图片无法识别
2.使用knn算法进行对图片的处理,以及运算进行识别
声明:本文均在pycharm上进行编辑操作,并本文所写代码均是python3进行编写,如果不能正常运行本文内的代码,请自己调试环境
另本文所识别的验证码类型为如下图片:

先介绍第一种比较简单的操作:
1.环境准备:
安装如下第三方库
from selenium import webdriver from PIL import Image import pytesseract
2.环境介绍
selenium 环境模仿鼠标点动,以及账号密码传递,等等
pytesseract 识别图片中字符借用的第三方库
PIL 对图片的一些处理的第三方库
3.具体实现
driver.find_element_by_xpath('地址').click()
点击网页中xpath为括号内的位置
driver.find_element_by_xpath('地址').send_keys(传递信息)
传递相应数据到xpath为括号内的相应位置
ele=driver.find_element_by_xpath('地址') ele.screenshot('图片名,以及格式')
找到xpath为括号内的地址,并截取相应位置图片
4.图片处理
在获取相应验证码图片后,往往图片为彩图,或者存在噪点,为了减少模型的复杂度,以及减少模型的训练强度,同时增加识别率,很有必要对图片进行预处理,使其对机器识别更友好。
具体步骤如下:
1.读取原始素材
2.将彩图转化为黑白图
3.去噪点
4.1二值化图片
图像二值化( Image Binarization)就是将图像上的像素点的灰度值设置为0或255,也就是将整个图像呈现出明显的黑白效果的过程。——来自百度百科
1.RGB彩图转为灰度图
2.将灰度图转化为二值图,即设定二值化阈值,转化为01图
image = Image.open('a.png') image = image.convert('L') #转化为灰度图 threshold = 127 #设定的二值化阈值 table = [] #table是设定的一个表,下面的for循环可以理解为一个规则,小于阈值的,就设定为0,大于阈值的,就设定为1 for i in range(256): if i < threshold: table.append(0) else: table.append(1) image = image.point(table,'1') #对灰度图进行二值化处理,按照table的规则(也就是上面的for循环)
如下图:
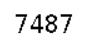
2.去除噪点
在转化为二值图片后,就需要清除噪点。本文选择的素材比较简单,大部分噪点也是最简单的那种 孤立点,所以可以通过检测这些孤立点就能移除大量的噪点。
关于如何去除更复杂的噪点甚至干扰线和色块,有比较成熟的算法: 洪水填充法 Flood Fill ,后面有兴趣的时间可以继续研究一下。
转载自 https://www.cnblogs.com/beer/p/5672678.htm
5.直接借助selenium和pytesseract实现
result = pytesseract.image_to_string(image) # 读取里面的内容
输出result,就是图片的结果.
上述方法的精确度,嗯……..
我没经过专业的测试,但是点着试试,试了二三十次,有那么五六次是错误的
所以呢为了提高模型的精确度,下面介绍knn算法
knn:从训练样本集中选择k个与测试样本“距离”最近的样本,这k个样本中出现频率最高的类别即作为测试样本的类别。
- KNN是属于有监督学习(因为训练集中每个数据都存在人工设置的标签——即类别)
- 那是如何进行分类的呢?其实是用数据之间的欧氏距离来衡量它们的相似程度,距离越短,表示两个数据越相似。
5.建立样本集—图片分割
既然是样本集,那么肯定要有样本呀,找相应网站,提交请求,爬取完事,在这不写这个了
而样本集的建立,可以数格子,没错就是数格子
打开ps,图片放大到最大,然后数格子,额,这个方法有点low,在线ps:https://www.uupoop.com/
找到左上点,右下点,间距,然后循环切割,保存
from PIL import Image def cut_image(image): box_list = [] # (left, upper, right, lower) for i in range(0, 4): box = (5+i*12+1,5,14+i*12,19+1) box_list.append(box) image_list = [image.crop(box) for box in box_list] return image_list # 保存 def save_images(image_list): index = 1 for image in image_list: image.save(str(index) + '.png', 'PNG') index += 1 if __name__ == '__main__': file_path = "地址" # 图片保存的地址 image = Image.open(file_path) image_list = cut_image(image) save_images(image_list)
效果图:

上面方法有点low
所以可以,通过图片黑色或白色的图片的连续性,来进行寻找左上点和右下点来确定一个矩形范围,即切割的图片的位置,循环切割保存
def cut_image(image): """ 字符切割,根据黑色的连续性,当某一列出现黑色为标志,当黑色消失为结束点 :param image: 完整的验证码图片 :return images: 切割好的图片列表 """ # inletter代表当前列是否出现黑点 inletter = False # foundletter为False时,未找到字符开始位置;否则,已找到字符开始位置 foundletter = False # 记录所有字符的开始点和结束点 letters = [] start = 0 end = 0 for x in range(image.size[0]): for y in range(image.size[1]): # 当前像素点的状态(0黑色或1白色) pix = image.getpixel((x,y)) # 出现黑色点时证明有字符出现 if pix == 0: inletter = True # 当前列出现黑色点,且未找到字符开始位置,则找当前列为字符开始位置 if foundletter == False and inletter ==True: foundletter = True start = x # 当前列为全白,且已有字符开始位置,则该字符结束,记录字符的范围 if foundletter == True and inletter == False: end = x letters.append((start,end)) foundletter = False inletter = False images = [] # 利用letter的信息切割验证码,得到单个字符 for letter in letters: img = image.crop((letter[0],0,letter[1],image.size[1])) #img.save(str(letter[0])+'.jpeg')#展示切割效果 images.append(img) return images
上面代码只写出连续黑的情况,所以在部分要进行修改
6.建立样本集—分组
将爬取的样本重复上述操作进行图片处理和切割
将切割好的图片,建立文件夹进行分组
7.识别
具体操作步骤如下: 1.预处理图片
2.将图片转化
3.cos求解相似度
1.预处理图片
上面的样本切割出是单独的数字,那么在识别的时候,要对图片进行处理以及切割,具体操作参考上面的介绍.
2.将图片转换
在将图片切割后,是一个图片的形式显示,这样不便于计算,所以将其转化为矢量,将二维形式转化为一维形式
def buildvector(image): """ 图片转换成矢量,将二维的图片转为一维 :param image: :return: """ result = {} count = 0 for i in image.getdata(): result[count] = i count += 1 return result
3.cos值求解相似度
求解方程:

即目标值与其中一个样本值的相似度.
m表示该样本组的数量,数组c表示目标图片,数组d表示样本组中的每一张图片
另外在此所用的目标图片和样本图片,均已经一维化处理
计算完目标图片与所有样本集后进行排序,去相似度最高即为目标图片所示数字
class CaptchaRecognize: def __init__(self): self.letters = ['0', '1', '2', '3', '4', '5', '6', '7', '8', '9'] self.loadSet() def loadSet(self): """ 将icon中预先准备好的图片,以向量的形式读出 ps: icon中图片为验证码切割完成后,人工标记的训练集 如果需要增加,只需把切割后的图片放到其所表示的文件夹下即可 :return: """ self.imgset = [] for letter in self.letters: temp = [] # 打开icon下的各个文件,icon文件下是一些已切割的字符图片 for img in os.listdir('./icon/%s'%(letter)): # 将图片转成一维向量,放入temp列表中 temp.append(buildvector(Image.open('./icon/%s/%s'%(letter,img)))) # 标签与对应图片转换成的向量,以字典形式存到imgset 如:letter为1,temp就是1文件夹下图片的向量 self.imgset.append({letter:temp}) def magnitude(self,concordance): """ 利用公式求计算矢量大小,详细公式见README.md :param concordance: :return: """ total = 0 for word, count in concordance.items(): # count 为向量各个单位的值 total += count ** 2 return math.sqrt(total) def relation(self, concordance1, concordance2): """ 计算矢量之间的 cos 值,详细公式见README.md :param concordance1: :param concordance2: :return: """ relevance = 0 topvalue = 0 # 遍历concordance1向量,word 当前位置的索引,count为值 for word, count in concordance1.items(): # 当concordance2有word才继续,防止索引超限 if word in concordance2: #print(type(topvalue), topvalue, count, concordance2[word]) topvalue += count * concordance2[word] #time.sleep(10) return topvalue / (self.magnitude(concordance1) * self.magnitude(concordance2)) def recognise(self,image): """ 识别验证码 :param image: 验证码图片 :return result: 返回验证码的值 """ # 二值化,将图片按灰度转为01矩阵 image = convert_image(image) # 对完整的验证码进行切割,得到字符图片 images = cut_image(image) vectors = [] for img in images: vectors.append(buildvector(img)) # 将字符图片转一维向量,如[0,1,0,1,1,....] result = [] for vector in vectors: guess=[] # 让字符图片和训练集中的 0-9 逐一比对 for image in self.imgset: for letter,temp in image.items(): relevance=0 num=0 # 遍历一个标签下的所有图片 for img in temp: # 计算相似度 relevance+=self.relation(vector,img) print (vector,img) num+=1 # 求出相似度平均值 relevance=relevance/num guess.append((relevance,letter)) # 对cos值进行排序,cos值代表相识度 guess.sort(reverse=True) result.append(guess[0]) #取最相似的letter,作为该字符图片的值 return result
8.主函数调用
if __name__ == '__main__': imageRecognize=CaptchaRecognize() # 设置图片路径 image = Image.open('3.png') # print(image.mode) result = imageRecognize.recognise(image) string = [''.join(item[1]) for item in result] print(result)
9.总结
本文主要是识别简单的验证码图片,要根据具体情况进行修改,主要提供一个框架,如果所给图片呈不规则显示,可能无法识别,这个算是机器学习简单的入门,对于以上仅为个人看法,如果有别的看法,欢迎私聊!!!
原创文章,转载请注明: 转载自URl-team
本文链接地址: knn算法,识别简单验证码图片
No related posts.
