Telegraf+Influxdb+Grafana自动化运维监控
概述:Telegraf收集信息,influxdb时序数据库存储数据,grafana平台展示数据,并进行监控告警,组成一个自动化运维监控平台。
一、influxdb
InfluxDB是一个由InfluxData开发的开源时序型数据。它由Go写成,着力于高性能地查询与存储时序型数据。InfluxDB被广泛应用于存储系统的监控数据,IoT行业的实时数据等场景。
1. 三大特性
- 时序性(Time Series):与时间相关的函数的灵活使用(诸如最大、最小、求和等);
- 度量(Metrics):对实时大量数据进行计算;
- 事件(Event):支持任意的事件数据,换句话说,任意事件的数据我们都可以做操作。
2. 数据模型
| 概念 | MySQL | InfluxDB |
|---|---|---|
| 数据库 | database | database |
| 表 | table | measurement |
| 列 | column | tags(带索引的,非必须)、fields(不带索引)、time(唯一主键,自动生成的时间列) |
| 行 | row | point |
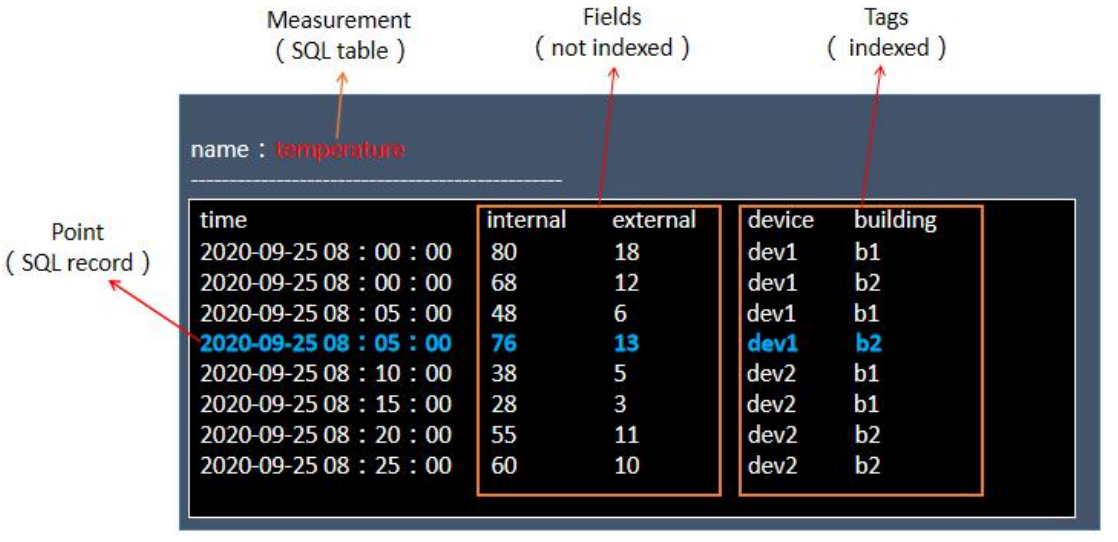
3. influxdb时间线
InfluxDB中的series是一种数据源的合的概念,在同一个database中,相同retention policy、相同measurement、相同tag的数据属于一个series集合,标识这条数据来自哪里,同一个series的数据在物理上按照时间顺序排列在一起;
使用命令 show series from tablename; 可以查看表的series。
4. 系统架构
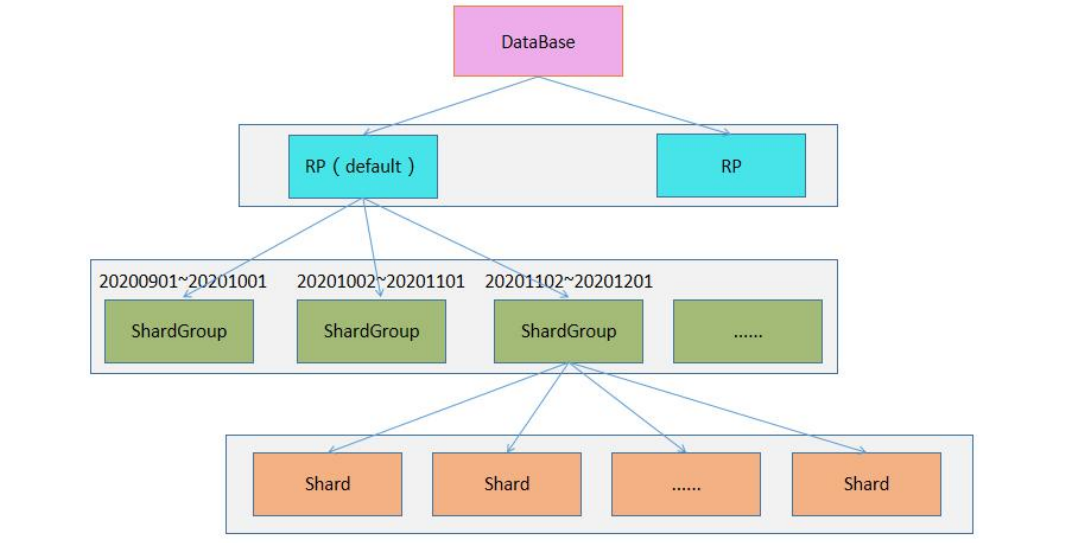
| 名称 | 概念 |
|---|---|
| database | 数据库 |
| RP(retention policy 数据保留策略) | 数据库级别,非表级别属性,每个数据库有多个保留策略,但是只能有一个默认策略 |
| shardgroup | 每个shardgroup只存储指定时间段的数据,不同的shardgroup对应的数据段不会重合;将数据按时间维度进行分区,减少数据查询扫描,提高查询效率;influxdb中数据过期删除的执行粒度就是shardgroup |
| shard | 真正存储数据 |
5. influxdb的安装
测试机器:10.121.x.x
5.1下载tar包,解压即可用,配置文件基本上不需要改
tar -xzvf influxdb-1.7.8_linux_amd64.tar.gz
得到以下目录结构

5.2 创建influxdb用户
useradd influxdb -s /sbin/nologin
5.3 创建几个目录,并授权
mkdir /var/lib/influxdb/ /var/log/influxdb/ /var/run/influxdb/
chown influxdb.influxdb /var/lib/influxdb/
chown influxdb.influxdb /var/log/influxdb/
chown influxdb.influxdb /var/run/influxdb/`
5.4 将配置文件复制到/etc/influxdb/influxdb.conf,使用默认配置即可
cp -r influxdb/etc/influxdb /etc/
默认配置:
[meta]
dir = "/var/lib/influxdb/meta"
[data]
dir = "/var/lib/influxdb/data"
wal-dir = "/var/lib/influxdb/wal"
series-id-set-cache-size = 100
5.5 将启动文件复制到/etc/init.d/
cp influxdb/usr/lib/influxdb/scripts/init.sh /etc/init.d/influxdb
chmod 755 /etc/init.d/influxdb
5.6 将二进制文件复制到/usr/bin
cp influxdb/usr/bin/* /usr/bin/
5.7 启动
service influxdb start

6、使用方法
6.1 数据库的基本操作
create database name1;
show databases;
use name1;
show measurements;
drop database name1;
show series from table1;
select * from table1 limit 10;
6.2 数据保留策略
Retention Policies – 数据保留策略是用来定义数据的存放时长,或者是保留某一时间段的数据。每个数据库可以有多个数据保留策略,但只能有一个默认策略。
创建保留策略语法:
create retention policy <retention_plocy_name> on <database_name> duration <duration> replication <n> [shard duration <duration>] [deafult]
<retention_plocy_name> 保留策略的名称
<database_name> 为哪个数据库创建的策略
<duration> 该保留策略对应的数据过期时间
replication 副本因子
shard duration 分片组的默认时长
[deafult] 是否为默认策略
查看保留策略语法
show retention policies on database_name;
修改保留期
alter retention policy "retention_plocy_name" on database_name duration 15d
删除保留期
drop retention policy "influx_retention_name" on database_name
6.3 表的增删改查
查看表
show measurements;
插入操作
insert weather,altitude=1000,area=北 tem=11,humi=-4
insert 表名(不存在则自动创建),tags1,tags2 fileds1,fileds
删除表
drop measurement table_name;
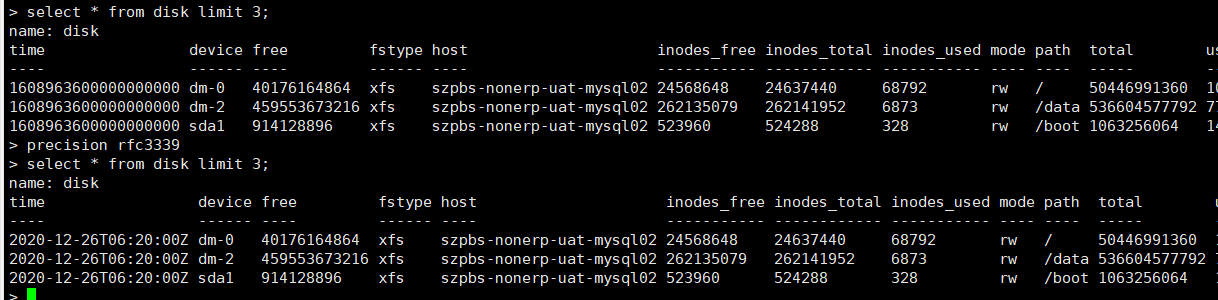
6.4 设置时间显示格式
precision rfc3339(Internet标准时间格式)
7. 用户操作
显示用户
show users;
创建用户
create user influx_user with passwrod 'xxxx';
管理员用户
create user "admin" with password "xxxx" with all privileges;
修改用户密码
set password for influx_user='xxxx';
删除用户
drop user influx_user;
8. 用户权限
授予所有库的权限
grant all privileges to influx_user;
针对某个库的所有权限
grant all privileges on influxdb to influx_user;
撤销权限
revoke all privileges from influx_user;
开启用户登录认证,需在配置文件的[http]模块中开启
[http]
auth-enabled=true
登录方法
bin/influx (无密码)
bin/influx -username influx_user -password xxxx (有密码)
二、Telegraf
telegraf是一个go编写的代理程序,可以收集系统和服务的统计数据,并写入到influxdb数据库。
1. telegraf metirc
是用于在处理期间对数据建模的内部表示。这些指标完全基于influxdb的数据模型,主要包含四个组件:
度量名称(measurement)
标签(tags)
字段(fields)
时间戳(time)
2. 为什么要用telegraf
-
可以采集多种组件,自动采集上报数据,降低数据获取难度
-
配置简单
-
按照时间序列采集数据,与influxdb完美结合
-
轻量级,占用内存小
3. telegraf 搭建
测试机器 10.121.x.x
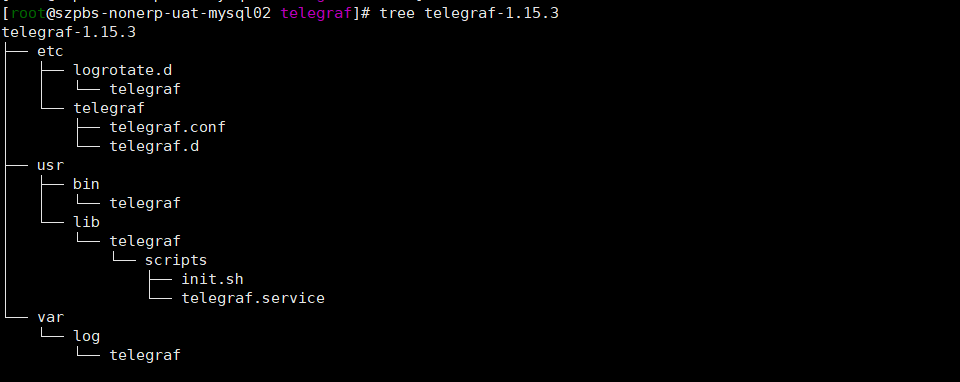
3.1 下载解压安装包
tar -xzvf telegraf-1.15.3_linux_amd64.tar.gz
目录结构
3.2 修改配置文件
找到配置文件中的以下模块,添加influxdb的连接配置信息:
[[outputs.influxdb]]
urls = ["//10.121.7.70:8086"]
database="telegraf" #influxdb创建的数据库
retention_policy="" #如果有的话
username="" #如果有的话
password="" #如果有的话
3.3 启动服务
bin/telegraf --config etc/telegraf/telegraf.conf
会自动收集信息并自动在influxdb的telegraf数据库中创建表,插入数据
3.4 可参考influxdb使用init.sh做成服务,配置开机自启动,也方便后续写脚本自动化部署。
创建用户和创建目录
useradd -s /sbin/nologin telegraf
mkdir /var/log/telegraf/ /var/run/telegraf
chown telegraf.telegraf /var/log/telegraf
chown telegraf.telegraf /var/run/telegraf
拷贝配置文件和可执行文件,启动脚本
cp /root/telegraf/telegraf-1.15.3/usr/bin/telegraf /usr/bin/
cp -r /root/telegraf/telegraf-1.15.3/etc/telegraf /etc/
cp /root/telegraf/telegraf-1.15.3/usr/lib/telegraf/scripts/init.sh /etc/init.d/telegraf
启动
service telegraf start
配置开机自启动
chkconfig telegraf on
启动默认收集的信息
Loaded inputs: kernel mem processes swap system cpu disk diskio
3.5 需要收集什么信息,input的配置可以参考以下链接
三、Grafana
Grafana是一个跨平台的开源的度量分析和可视化工具,可以通过将采集的数据查询然后可视化的展示,并及时通知。它主要有以下六大特点:
| 序号 | 项目 | 特性 |
|---|---|---|
| 1 | 展示方式 | 快速灵活的客户端图表,面板插件有许多不同方式的可视化指标和日志,官方库中具有丰富的仪表盘插件 |
| 2 | 数据源 | Graphite,InfluxDB,OpenTSDB,Prometheus,Elasticsearch,CloudWatch和KairosDB等 |
| 3 | 通知提醒 | 以可视方式定义指标的警报规则,Grafana将不断计算并发送通知,在数据达到阈值时通过邮件等方式通知 |
| 4 | 混合展示 | 在同一图表中混合使用不同的数据源,可以基于每个查询指定数据源,甚至自定义数据源 |
| 5 | 注释 | 使用来自不同数据源的丰富事件注释图表,将鼠标悬停在事件上会显示完整的事件元数据和标记 |
| 6 | 过滤器 | Ad-hoc过滤器允许动态创建新的键/值过滤器,这些过滤器会自动应用于使用该数据源的所有查询 |
1. tar包安装
1.1 下载安装包并解压
tar -xzvf grafana-7.2.0.linux-amd64.tar.gz
1.2 启动
./bin/grafana-server web &
2. rmp方式安装
grafana建议使用rpm安装,因grafana组件较多,使用rpm安装标准化,方便配置和管理,不存储数据,因此也不用担心会过多占用空间。
2.1 下载并安装
wget //dl.grafana.com/oss/release/grafana-7.3.6-1.x86_64.rpm
sudo yum install grafana-7.3.6-1.x86_64.rpm
2.2 设置开机自启动等启动命令
sudo systemctl daemon-reload
sudo systemctl start grafana-server
sudo systemctl status grafana-server
sudo systemctl enable grafana-server
2.3 安装信息
| 项目 | 详细信息 |
|---|---|
| 二进制文件 | /usr/sbin/grafana-server |
| init.d 脚本 | /etc/init.d/grafana-server |
| 环境变量文件 | /etc/sysconfig/grafana-server |
| 配置文件 | /etc/grafana/grafana.ini |
| 启动项 | grafana-server.service |
| 日志文件 | /var/log/grafana/grafana.log |
| 默认配置的sqlite3数据库 | /var/lib/grafana/grafana.db |
2.4 Grafana 访问
默认端口是3000,访问地址://IP:3000
默认账号/密码:admin/admin

