我是如何学习写一个操作系统(九):文件系统
- 2019 年 10 月 3 日
- 筆記
前言
这个应该是这个系列的尾声了,一个完整的操作系统可能最主要的也就是分成这几大模块:进程管理、内存管理和文件系统。计算机以进程为基本单位进行资源的调度和分配;而与用户的交互,基本单位则是文件
生磁盘
文件正是对生磁盘的抽象
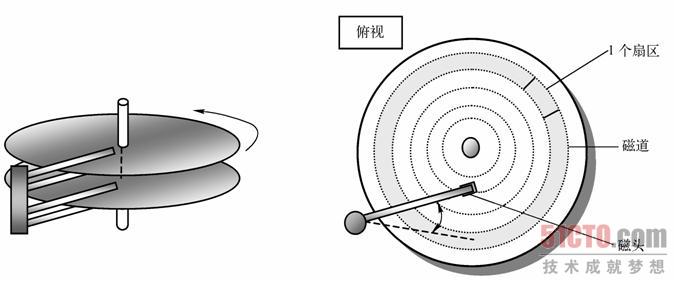
磁盘的组成
一个磁盘由多个盘面串联而成,而一个盘面又被分为磁道,磁道又由扇区组成。
磁盘的访问单元就是扇区,一个扇区为512字节
磁盘的使用
- CPU向磁盘的控制器发出一个指令
- 控制器开始进行寻道、旋转和传输
- 最后完成后向CPU发送一个中断
也就是向控制器发送柱面磁头扇区等信息,然后等待回应
盘块
盘块是对扇区的抽象
程序负责提高盘块block,而磁盘驱动负责从block计算出cyl,head,sec(CHS),最后传递到磁盘控制器上
磁盘访问时间 = 写入控制器时间 + 寻道时间 + 旋转时间 + 传输时间
其中主要的时间都在寻道时间和旋转时间,所以对扇区抽象成盘块就可以一次访问多个扇区来节省磁盘的访问时间
磁盘调度
既然有多进程交替执行,就有可能多个进程同时访问相同磁盘的情况,就需要一个请求队列来处理所有请求,就会涉及到调度算法了
FCFS调度
FCFS是最公平最直观的算法,也就是按照队列顺序来访问磁盘,但是效率也很低下,磁头会在不规律的磁道长途奔袭
SSTF调度
SSTF算法就类似短作业优先算法,先寻找更近距离的磁道,但是SSTF算法可能会产生饥饿问题,过长距离的磁道可能一直得不到处理
SCAN调度
SCAN算法就是SSTF算法的改良版,也就是进行SSTF,但是在中途不会折返去寻找更短距离的磁道,这样就避免了饥饿问题
C-SCAN调度(电梯算法)
把扫描限定在一个方向,当访问到某个方向的最后一个磁道时,磁道返回磁盘相反方向磁道的末端,并再次开始扫描。
文件和文件系统
文件是对磁盘的第三层抽象,扇区和盘块分别是前两层抽象。之所以有文件这层抽象是为了方便用户的使用,在用户的眼里,磁盘上的信息都可以看作是字符流。所以文件的抽象九可以看作是字符流到盘块集合的映射关系
文件的逻辑结构
从文件到盘块的映射来看,一般有这几种组织方式
-
顺序文件
记录是定长的且按关键字顺序排列。可以顺序存储或以链表形势存储,在访问时需要顺序搜索文件。顺序文件有以下两种结构:
-
第一种是串结构,各记录之间的顺序与关键字无关。通常的办法是由时间来决定,即按存入时间的先后排列,最先存入的记录作为第一个记录,其次存入的为第二个记录,以此类推。
-
第二种是顺序结构,指文件中所有记录按关键字顺序排列。
在对记录进行批量操作时,即每次要读或写一大批记录,对顺序文件的效率是所有逻辑文件中最高的;此外,也只有顺序文件才能存储在磁带上,并能有效的工作。但顺序文件对查找、修改、增加或删除单个记录的操作比较困难。
-
-
索引文件
对于可变长记录的文件只能顺序查找,系统开销较大,为此可以建立一张索引表以加快检索速度,索引表本身是顺序文件。在记录很多或是访问要求高的文件中,需要引入索引以提供有效的访问,实际中,通过索引可以成百上千倍的提高访问速度。
-
索引顺序表
索引顺序表是顺序和索引两种组织形势的结合。索引顺序文件将顺序文件中所有记录分为若干个组,为顺序文件建立一张索引表,在索引表中为每组中的第一个记录建立一个索引项,其中含有该记录的关键字值和指向该记录的指针。
在实际的操作系统实现中,一般是采用多级索引
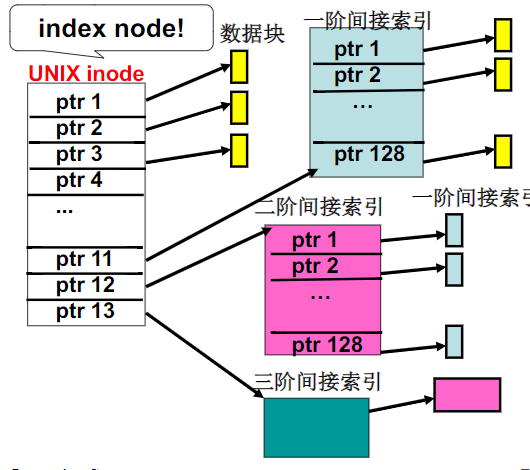
目录和文件系统
文件系统或者说目录是对磁盘的第四个抽象,也就是抽象了整个磁盘
操作系统为了实现文件目录,引入了称为文件控制块的数据结构。
文件控制块。
文件控制块(FCB)是用来存放控制文件需要的各种信息的数据结构,以实现“按名存取”。FCB的有序集合称为文件目录,一个FCB就是一个文件目录项。为了创建一个新文件,系统将分配一个FCB并存放在文件目录中,称为目录项。
FCB主要包含以下信息:
- 基本信息,如文件名、文件的物理位置、文件的逻辑结构、文件的物理结构等。
- 存取控制信息,如文件的存取权限等。
- 使用信息,如文件建立时间、修改时间等。
文件目录树
在多级目录下一般对磁盘就可以抽象为
-
FCB数组
FCB数组就是将所有盘块的FCB信息都集中到一个数组中
-
数据盘块集合
在每个数据盘块里都包含一些目录项用来找到子目录,目录项也就是文件名+对应的FCB的“地址”,也就是去之前的FCB数组中找到相应的FCB
在磁盘进行格式化的时候,会存放一些信息用来知道一些磁盘信息和找到根目录

-
inode位图: 哪些inode空闲,哪些被占用
-
超级块:记录两个位图有多大等信息
-
盘块位图: 哪些盘块是空闲的,硬盘大小不同这个位图的大小也不同
文件的实现
在我之前实现的FragileOS里文件系统非常简陋,基本没有什么好说的。这其实也是为什么之前把这个系列改了一个方向来结合的看Linux0.11的代码。所以来看一下Linux0.11里是怎么使用和实现文件系统的,
读取文件
- 这是读取文件的系统调用
- 函数首先对参数有效性进行判断
- 之后对文件的类型进行判断
- 如果是目录文件或者是常规文件就执行读取操作
int sys_read(unsigned int fd,char * buf,int count) { struct file * file; struct m_inode * inode; if (fd>=NR_OPEN || count<0 || !(file=current->filp[fd])) return -EINVAL; if (!count) return 0; verify_area(buf,count); inode = file->f_inode; if (inode->i_pipe) return (file->f_mode&1)?read_pipe(inode,buf,count):-EIO; if (S_ISCHR(inode->i_mode)) return rw_char(READ,inode->i_zone[0],buf,count,&file->f_pos); if (S_ISBLK(inode->i_mode)) return block_read(inode->i_zone[0],&file->f_pos,buf,count); if (S_ISDIR(inode->i_mode) || S_ISREG(inode->i_mode)) { if (count+file->f_pos > inode->i_size) count = inode->i_size - file->f_pos; if (count<=0) return 0; return file_read(inode,file,buf,count); } printk("(Read)inode->i_mode=%06onr",inode->i_mode); return -EINVAL; }- 根据i节点和文件结构,读取文件中数据。
- 首先判断参数的有效性
- 之后循环的调用bread来读取数据
- 之后复制chars字节到用户缓冲区buf中
- 最后是修改该i节点的访问时间为当前时间和返回读取的字节数
int file_read(struct m_inode * inode, struct file * filp, char * buf, int count) { int left,chars,nr; struct buffer_head * bh; if ((left=count)<=0) return 0; while (left) { if ((nr = bmap(inode,(filp->f_pos)/BLOCK_SIZE))) { if (!(bh=bread(inode->i_dev,nr))) break; } else bh = NULL; nr = filp->f_pos % BLOCK_SIZE; chars = MIN( BLOCK_SIZE-nr , left ); filp->f_pos += chars; left -= chars; if (bh) { char * p = nr + bh->b_data; while (chars-->0) put_fs_byte(*(p++),buf++); brelse(bh); } else { while (chars-->0) put_fs_byte(0,buf++); } } inode->i_atime = CURRENT_TIME; return (count-left)?(count-left):-ERROR; }文件写入
- 根据i节点和文件结构信息,将用户数据写入文件中
- 首先确定数据写入文件的位置
- 然后算出对应的盘块
- 然后用户缓冲区buf中复制c个字节到告诉缓冲块中p指向的开始位置处
- 最后是修改该i节点的访问时间为当前时间和返回读取的字节数
int file_write(struct m_inode * inode, struct file * filp, char * buf, int count) { off_t pos; int block,c; struct buffer_head * bh; char * p; int i=0; /* * ok, append may not work when many processes are writing at the same time * but so what. That way leads to madness anyway. */ if (filp->f_flags & O_APPEND) pos = inode->i_size; else pos = filp->f_pos; while (i<count) { if (!(block = create_block(inode,pos/BLOCK_SIZE))) break; if (!(bh=bread(inode->i_dev,block))) break; c = pos % BLOCK_SIZE; p = c + bh->b_data; bh->b_dirt = 1; c = BLOCK_SIZE-c; if (c > count-i) c = count-i; pos += c; if (pos > inode->i_size) { inode->i_size = pos; inode->i_dirt = 1; } i += c; while (c-->0) *(p++) = get_fs_byte(buf++); brelse(bh); } inode->i_mtime = CURRENT_TIME; if (!(filp->f_flags & O_APPEND)) { filp->f_pos = pos; inode->i_ctime = CURRENT_TIME; } return (i?i:-1); }文件目录的实现
打开创建文件
- 首先对参数进行处理,然后搜索进程结构中文件结构指针数组一个空闲的文件句柄
- 接着为打开文件在文件表中寻找一个空闲结构项
- 然后调用函数open_namei()执行打开操作,若返回值小于0,则说明出错,就释放刚申请到的文件结构
- 然后为不同的文件类型做一些特殊的处理
- 最后初始化打开文件的文件结构,然后返回文件句柄
int sys_open(const char * filename,int flag,int mode) { struct m_inode * inode; struct file * f; int i,fd; mode &= 0777 & ~current->umask; for(fd=0 ; fd<NR_OPEN ; fd++) if (!current->filp[fd]) break; if (fd>=NR_OPEN) return -EINVAL; current->close_on_exec &= ~(1<<fd); f=0+file_table; for (i=0 ; i<NR_FILE ; i++,f++) if (!f->f_count) break; if (i>=NR_FILE) return -EINVAL; (current->filp[fd]=f)->f_count++; if ((i=open_namei(filename,flag,mode,&inode))<0) { current->filp[fd]=NULL; f->f_count=0; return i; } /* ttys are somewhat special (ttyxx major==4, tty major==5) */ if (S_ISCHR(inode->i_mode)) { if (MAJOR(inode->i_zone[0])==4) { if (current->leader && current->tty<0) { current->tty = MINOR(inode->i_zone[0]); tty_table[current->tty].pgrp = current->pgrp; } } else if (MAJOR(inode->i_zone[0])==5) if (current->tty<0) { iput(inode); current->filp[fd]=NULL; f->f_count=0; return -EPERM; } } /* Likewise with block-devices: check for floppy_change */ if (S_ISBLK(inode->i_mode)) check_disk_change(inode->i_zone[0]); f->f_mode = inode->i_mode; f->f_flags = flag; f->f_count = 1; f->f_inode = inode; f->f_pos = 0; return (fd); }解析目录
- 先根据当前路径的第一个字符来判断当前路径是绝对路径还是相对路径
- 然后进循环处理过程,分割每个目录名
- 得到这个目录名后,调用查找目录项函数find_entry()在当前处理的目录中寻找指定名称的目录
- 如果找到这个目录,就设置一些信息,然后继续以该目录项为当前目录继续循环处理路径名中的下一目录名部分(或文件名)
static struct m_inode * get_dir(const char * pathname) { char c; const char * thisname; struct m_inode * inode; struct buffer_head * bh; int namelen,inr,idev; struct dir_entry * de; if (!current->root || !current->root->i_count) panic("No root inode"); if (!current->pwd || !current->pwd->i_count) panic("No cwd inode"); if ((c=get_fs_byte(pathname))=='/') { inode = current->root; pathname++; } else if (c) inode = current->pwd; else return NULL; /* empty name is bad */ inode->i_count++; while (1) { thisname = pathname; if (!S_ISDIR(inode->i_mode) || !permission(inode,MAY_EXEC)) { iput(inode); return NULL; } for(namelen=0;(c=get_fs_byte(pathname++))&&(c!='/');namelen++) /* nothing */ ; if (!c) return inode; if (!(bh = find_entry(&inode,thisname,namelen,&de))) { iput(inode); return NULL; } inr = de->inode; idev = inode->i_dev; brelse(bh); iput(inode); if (!(inode = iget(idev,inr))) return NULL; } }