【重复图识别】在茫茫图海中,怎么找到相同的它?
背景
在一些图像相关的项目中,重复图识别是很重要的。就比如热图排行榜(需要识别出重复图);涉及图像深度学习的项目(训练数据需要剔除重复图);图片原创&视频原创(需要识别出重复图)等等。
什么是相同图片
什么是相同图片?相信在不同场景下,这个答案是不一样。有些场景把肉眼看起来一样的图片当作相同图片,有些场景把用滤镜处理过的图片也当作相同图片,而有些场景下只把原图当作相同图片。
这里按照相同程度划分,相同程度从高到低,其实可以分为3个等级:
- 绝对原图
- 肉眼相同
- 抄袭原图
接下来我们逐一详细介绍下这3类。
绝对原图
这个等级,图片相同的程度是最高的,就如下面2张图片,1.png通过直接copy的方式产生的2.png

它们从图片内容已经无法判断是否是原图,只能从文件的角度识别,一般来说都是直接md5判断2个图片,如下所示:

它属于用图片文件进行hash处理。
PS:一般来说,所有场景都会先用md5来过滤一边,因为它算法复杂度很低,根本不用理解图片
肉眼相同
这个等级的场景最多,比如图片训练数据去重,热图排行榜等等。
就如下图所示,1.png经过压缩、resize、转码等图片处理的方式产生的3.jpg:

它们肉眼看起来是相同,但是绝对不是原图,md5无法识别这种情况,只能图像的感知hash处理。感知hash主要有3种(AHash、DHash、PHash),它们都是用图片内容进行hash处理,只是hash方式不同,下面逐一介绍一波:
AHash
这种感知hash最简单,算法复杂度也最低,它只需要处理2步 预处理 + 二值化。
- 具体流程图如下所示:
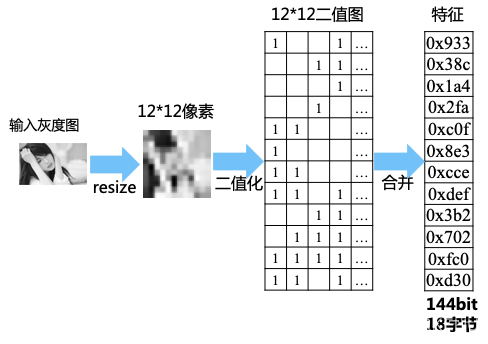

它的二值化方式比较简单,只是比较了像素点跟均值,所以效果一般般。
- python源码如下:
def ahash(image, hash_size=8):
image = image.convert("L").resize((hash_size, hash_size), Image.ANTIALIAS)// 1、【预处理】转灰度图,resize
pixels = numpy.asarray(image)
avg = np.mean(pixels)//2、计算均值,这里也可以用中值
diff = pixels > avg // 3、【二值化】大于均值为1,小于等于均值为0
return diff
DHash
这种感知hash的复杂度也很低,重点是它比AHash的效果好,主要原因它二值化方式考虑上了相邻像素的差值,算法更加鲁棒。(当然这只是一种思想,我们也可以比较固定的2个像素点的大小,每个像素点都有一个与之对应的像素点)。
算法流程图如下(跟AHash差不多,差别在于二值化方式不一样):

- python源码如下:
def dhash(image, hash_size=8):
image = image.convert("L").resize((hash_size + 1, hash_size), Image.ANTIALIAS)// 1、【预处理】转灰度图,resize
pixels = numpy.asarray(image)
diff = pixels[:, 1:] > pixels[:, :-1] //2、【二值化】相邻2个元素对比,右边大于左边为1,右边小于等于左边为0。(也可以改成上下2个元素的对比,或者固定2个元素之间的对比)
return diff
Phash
Phash是目前效果最好,它引入了DCT变换,去除图片中的高频信息,把注意力集中在低频信息中,这是由于人眼对于细节信息不是很敏感。具体算法原理见下一篇。
phash有很多种改版,下面只给出效果最好的一种,它的算法流程图如下:

- python 源码如下:
def phash(image, hash_size=8, highfreq_factor=4):
import scipy.fftpack
img_size = hash_size * highfreq_factor
image = image.convert("L").resize((img_size, img_size), Image.ANTIALIAS)// 1、【预处理】转灰度图,resize
pixels = numpy.asarray(image)
dct = scipy.fftpack.dct(scipy.fftpack.dct(pixels, axis=0), axis=1) //DCT变换
dctlowfreq = dct[:hash_size, :hash_size] //2、只留下直流&&低频变量
med = numpy.median(dctlowfreq) //取中值
diff = dctlowfreq > med //3、【二值化】大于中值为1,小于等于中值为0
return diff
抄袭原图
这种场景也挺多的,而且其中每个场景都有自己独特的要求。就比如一个视频平台,它的视频原创项目,把加滤镜、换音频、裁剪等方式也判定为相同图片的话,感知hash已经不适用,必须用上图像深度学习了。
一般来说也不需要很强的模型,但是必须针对性的训练特定场景,就比如滤镜,logo,黑边等场景。
滤镜就如下图所示,1.png经过一个滤镜产生了4.png:

还有一种场景是游戏领域的视频去重,由于游戏背景都一样,只有小小的一块人物或者名字不同,也是需要针对性的加数据训练的。
这里的话,深度学习 MoCo 可能会合适一些。
总结
重复图在图像相关的项目中基本都会用到,不同的场景用不同的算法。
| 复杂度 | 适用场景 | |
|---|---|---|
| MD5 | 超级低 | 绝对原图 |
| 感知Hash | 低 | 肉眼相同 |
| 深度学习 | 高 | 特定场景相同 |

