以 Debug 形式,深入理解 Phoenix 全局索引
- 2019 年 11 月 21 日
- 筆記

图片来自网络,祝福发自内心^_^
文章作者:吴少杰
编辑整理:Hoh Xil
内容来源:作者授权
出品社区:DataFun
注:欢迎转载,转载请注明出处
导读:上一篇文章:从理解 Phoenix 索引源码开始,构建全局索引,采用静态分析源码的方式研究 Phoenix,后面会通过 debug 的形式深入研究,这样可以直观地观察 Phoenix 运行的过程和逻辑,也有利于理解各个类的具体作用及其内部逻辑。
第六章
Debug 之前,需要写一段简单代码,用以驱动调试过程。
- PhoenixConnection connection = (PhoenixConnection)DriverManager.getConnection( "jdbc:phoenix:local:2181", "test", "test"); PhoenixStatement statement = (PhoenixStatement)connection.createStatement();String sql = "select /*+ INDEX(test idx_test_email) */ * from test where email='[email protected]'";PhoenixResultSet explainRes = (PhoenixResultSet)statement.executeQuery("explain "+sql);while (explainRes.next()){ logger.info("explain: {}",explainRes.getString(1));} PhoenixResultSet resultSet = (PhoenixResultSet)statement.executeQuery(sql);while (resultSet.next()){ logger.info("id: {},name: {},email: {}", resultSet.getString("id"), resultSet.getString("name"), resultSet.getString("email"));}explainRes.close();resultSet.close();statement.close();connection.close();} catch (SQLException e) {e.printStackTrace();}
请注意上面的代码中:
connection/statement/resultSet 等类型已经被强制转换成了 Phoenix 对应的类型,这样方便IDEA直接跳转到具体的实现,否则就会跳转到 java 的 interface 中。这也算一个小技巧吧,调试其他源码的时候,最好转换成具体实现的类。
CLIENT 1-CHUNK PARALLEL 1-WAY ROUND ROBIN FULL SCAN OVER TEST SKIP-SCAN-JOIN TABLE 0 CLIENT 1-CHUNK PARALLEL 1-WAY ROUND ROBIN RANGE SCAN OVER IDX_TEST_EMAIL ['[email protected]'] SERVER FILTER BY FIRST KEY ONLY DYNAMIC SERVER FILTER BY "TEST.ID" IN ($2.$4)
上面是 explain 得到的 SQL 执行计划,很明显 Phoenix 使用了 idx_test_email 这个索引。
根据之前文章的分析,我们可以在 executeQuery 内部设置一个断点,看一下解析后的 statement 的数据。

SelectStatement 这个类的变量不算多,但涵盖了 select 查询的所有信息。此处我们只关注几个重要的变量:fromTable、hint、where。不过这里要特别注意 hint 变量,是一个 HintNode 类型,扩展全文索引的时候,会修改这个类的。
之前也分析过,SelectStatement 会被编译成 QueryPlan,下面是 QueryPlan 的具体字段值。
plan = {ScanPlan@3907} splits = null scans = null allowPageFilter = true isSerial = false isDataToScanWithinThreshold = false serialRowsEstimate = null serialBytesEstimate = null serialEstimateInfoTs = null tableRef = {TableRef@3910} tableRefs = {SingletonImmutableSet@3911} size = 1 context = {StatementContext@3912} resolver = {FromCompiler$ProjectedTableColumnResolver@3920} binds = {BindManager@3921} scan = {Scan@3922} "{"loadColumnFamiliesOnDemand":true,"filter":"EMAIL = '[email protected]'","startRow":"","stopRow":"","batch":-1,"cacheBlocks":true,"totalColumns":1,"maxResultSize":-1,"families":{"0":["ALL"]},"caching":2147483647,"maxVersions":1,"timeRange":[0,9223372036854775807]}" expressions = {ExpressionManager@3923} aggregates = {AggregationManager@3924} dateFormat = "yyyy-MM-dd HH:mm:ss.SSS" dateFormatter = {FastDateFormat@3926} "FastDateFormat[yyyy-MM-dd HH:mm:ss.SSS]" timeFormat = "yyyy-MM-dd HH:mm:ss.SSS" timeFormatter = {FastDateFormat@3926} "FastDateFormat[yyyy-MM-dd HH:mm:ss.SSS]" timestampFormat = "yyyy-MM-dd HH:mm:ss.SSS" timestampFormatter = {FastDateFormat@3926} "FastDateFormat[yyyy-MM-dd HH:mm:ss.SSS]" dateFormatTimeZone = {ZoneInfo@3927} "sun.util.calendar.ZoneInfo[id="GMT",offset=0,dstSavings=0,useDaylight=false,transitions=0,lastRule=null]" numberFormat = "#,##0.###" tempPtr = {ImmutableBytesWritable@3929} "" statement = {PhoenixStatement@3903} dataColumns = {LinkedHashMap@3930} size = 0 currentTime = -1 scanRanges = {ScanRanges@3931} "ScanRanges[[]]" sequences = {SequenceManager@3932} currentTable = {TableRef@3910} whereConditionColumns = {ArrayList@3933} size = 1 subqueryResults = {HashMap@3934} size = 0 readMetricsQueue = {ReadMetricQueue@3935} overAllQueryMetrics = {OverAllQueryMetrics@3936} queryLogger = null isClientSideUpsertSelect = false statement = {PhoenixStatement$ExecutableSelectStatement@3904} "SELECT /*+ INDEX(TEST IDX_TEST_EMAIL) */ * FROM TEST WHERE EMAIL = '[email protected]'" projection = {RowProjector@3913} "[ID,NAME,EMAIL]" paramMetaData = {PhoenixParameterMetaData@3914} limit = null offset = null orderBy = {OrderByCompiler$OrderBy@3915} groupBy = {GroupByCompiler$GroupBy$1@3916} parallelIteratorFactory = {ParallelIteratorFactory$1@3917} dynamicFilter = null dataPlan = null estimatedRows = null estimatedSize = null estimateInfoTimestamp = null getEstimatesCalled = false
大家可以重点查看 scan 字段的逻辑,简单来看就是对 TEST 表的全文检索,filter 是 EMAIL='[email protected]'。到这里还没有走索引,需要继续执行代码。
plan = connection.getQueryServices().getOptimizer().optimize(PhoenixStatement.this, plan);
上面代码是对 QueryPlan 进行优化,也就是执行计划优化。这里要具体看一下优化后的 plan 是怎么样的。
plan = {HashJoinPlan@3967} statement = {SelectStatement@3970} "SELECT /*+ NO_INDEX */ TEST.* FROM TEST Semi JOIN (SELECT /*+ INDEX(TEST IDX_TEST_EMAIL) */ 1 $3,":ID" $4 FROM "IDX_TEST_EMAIL" WHERE "0:EMAIL" = '[email protected]') ON ("ID" = $2.$4)" joinInfo = {HashJoinInfo@3971} subPlans = {HashJoinPlan$HashSubPlan[1]@3972} 0 = {HashJoinPlan$HashSubPlan@3978} index = 0 plan = {TupleProjectionPlan@3979} tupleProjector = {TupleProjector@3984} "TUPLE-PROJECTOR {[1, "ID"] ==> [INTEGER, VARCHAR]}" postFilter = null delegate = {ScanPlan@3985} splits = null scans = null allowPageFilter = true isSerial = false isDataToScanWithinThreshold = false serialRowsEstimate = null serialBytesEstimate = null serialEstimateInfoTs = null tableRef = {TableRef@3987} tableRefs = {SingletonImmutableSet@3988} size = 1 context = {StatementContext@3989} statement = {SelectStatement@3990} "SELECT /*+ INDEX(TEST IDX_TEST_EMAIL) */ 1 $3,":ID" $4 FROM "IDX_TEST_EMAIL" WHERE "0:EMAIL" = '[email protected]'" projection = {RowProjector@3991} "[1,"ID"]" paramMetaData = {PhoenixParameterMetaData@3992} limit = null offset = null orderBy = {OrderByCompiler$OrderBy@3993} groupBy = {GroupByCompiler$GroupBy$1@3994} parallelIteratorFactory = {ParallelIteratorFactory$1@3995} dynamicFilter = null dataPlan = null estimatedRows = null estimatedSize = null estimateInfoTimestamp = null getEstimatesCalled = false hashExpressions = null singleValueOnly = false keyRangeLhsExpression = {RowKeyColumnExpression@3980} ""TEST.ID"" keyRangeRhsExpression = {ProjectedColumnExpression@3981} "$2.$4" recompileWhereClause = false tableRefs = {HashSet@3974} size = 2 maxServerCacheTimeToLive = 30000 serverCacheLimit = 104857600 dependencies = {HashMap@3975} size = 0 hashClient = null firstJobEndTime = null keyRangeExpressions = null estimatedRows = null estimatedBytes = null estimateInfoTs = null getEstimatesCalled = false delegate = {ScanPlan@3976}
这是优化后的执行计划,SQL 语句被优化成 semi join 了。有没有很熟悉的感觉?作者在 HBase Meetup 中,有提到过这种优化方案,就是直接用 join 强制走索引。那么这里有必要简单介绍一下 semi joiin 的概念。
所谓的 semi-join 是指 semi-join 子查询。 当一张表在另一张表找到匹配的记录之后,半连接 ( semi-jion ) 返回第一张表中的记录。与条件连接相反,即使在右节点中找到几条匹配的记录,左节点 的表也只会返回一条记录。另外,右节点的表一条记录也不会返回。半连接通常使用 IN 或 EXISTS 作为连接条件。 https://blog.csdn.net/lppl010_/article/details/80301757
作者竟误打误撞,竟然猜出了 Phoenix 索引使用的原理。读者一定要深刻理解这个机制,有助于我们实现全文检索索引。也要注意优化后的 plan 类型是 HashJoinPlan。
/** * * Interface for an executable query plan * * * @since 0.1 */public interface QueryPlan extends StatementPlan ;/** * Get a result iterator to iterate over the results * @return result iterator for iterating over the results * @throws SQLException */public ResultIterator iterator() throws SQLException;/** * * @return whether underlying {@link ResultScanner} can be picked up in a round-robin * fashion. Generally, selecting scanners in such a fashion is possible if rows don't * have to be returned back in a certain order. * @throws SQLException */public boolean useRoundRobinIterator() throws SQLException;
在分析 HashJoinPlan 之前,先看一下 QueryPlan 接口的定义及其重要的函数。
iterator 返回一个 ResultIterator 用来迭代数据。那么 HashJoinPlan 的这个 iterator 方法就非常重要了,当然 iterator 有几种不同的重载形式,也需要关注下。
根据对 HashJoinPlan 的调试追踪,定位到了以下函数:
public ResultIterator iterator(ParallelScanGrouper scanGrouper, Scan scan) throws SQLException

这个函数的代码有点多,但仔细分析其逻辑,可以知道该函数前半段,将涉及到的子查询放到 Future 后台执行,所有子查询结束后其数据放到 ServerCache,dependencies 存放各个子查询对应的 ServerCache。最终用 dependencies 改写当前 QueryPlan 的 delegate。简单来说就是后台并行执行子查询,将结果用以改写当前执行计划的 scan 对象。
iterator = {RoundRobinResultIterator@4319} threshold = 2147483646 numScannersCacheExhausted = 0 resultIterators = {ParallelIterators@4325} "ResultIterators [name=PARALLEL,id=8f373aba-e360-94d0-ae67-3774e06c338e,scans=[[{"loadColumnFamiliesOnDemand":true,"startRow":"1","stopRow":"1\x00","batch":-1,"cacheBlocks":true,"totalColumns":3,"maxResultSize":-1,"families":{"0":["\x00\x00\x00\x00","\x80\x0B","\x80\x0C"]},"caching":2147483647,"maxVersions":1,"timeRange":[0,9223372036854775807]}]]]" iteratorFactory = {ParallelIteratorFactory$1@4328} initFirstScanOnly = false scans = {ArrayList@4329} size = 1 splits = {SingletonImmutableList@4330} size = 1 physicalTableName = {byte[4]@4331} plan = {ScanPlan@3968} scanId = "8f373aba-e360-94d0-ae67-3774e06c338e" mutationState = {MutationState@4333} scanGrouper = {DefaultParallelScanGrouper@3967} allFutures = {ArrayList@4334} size = 0 estimatedRows = {Long@4335} 1 estimatedSize = {Long@4336} 206 estimateInfoTimestamp = {Long@4337} 0 hasGuidePosts = false scan = {Scan@4249} "{"loadColumnFamiliesOnDemand":true,"startRow":"1","stopRow":"1\x00","batch":-1,"cacheBlocks":true,"totalColumns":3,"maxResultSize":-1,"families":{"0":["\x00\x00\x00\x00","\x80\x0B","\x80\x0C"]},"caching":2147483647,"maxVersions":1,"timeRange":[0,9223372036854775807]}" useStatsForParallelization = true caches = {HashMap@3974} size = 0 dataPlan = null context = {StatementContext@4269} tableRef = {TableRef@4338} groupBy = {GroupByCompiler$GroupBy$1@4339} orderBy = {OrderByCompiler$OrderBy@4340} hint = {HintNode@4341} "/*+ NO_INDEX */ " limit = null offset = null openIterators = {ArrayList@4326} size = 0 index = 0 closed = false plan = {ScanPlan@3968} numParallelFetches = 0
这是最终返回的 iterator 对象。可以看出 Scan 对象的 startRow/stopRow 已经被替换成了 email='[email protected]' 的 ID 值,也就是1。到此为止也就通过索引表改写了源 SQL 的执行计划。
debug 分析到这里就结束了,仍然还有很多细节没有探讨清楚,感兴趣的读者可以自行 debug。
semi join 生效条件 https://blog.csdn.net/lppl010_/article/details/80301699
第七章
经过前面的分析,我们知道 PhoenixSQL 会经过优化器改写、优化,索引会被翻译成对应的索引表。接下来会介绍 SQL 各种不同的形式及其优化后的共同特点,以便扩展全文索引。
考虑到 SQL 编译的复杂性,以及自身精力的有限性,Phoenix 自身的执行优化引擎的源码不再分析,我会设计一些 SQL,用以探测优化后的执行 SQL 形式,由此来观察 Phoenix 查询索引的方式。
通过前面的文章我们知道,在 PhoenixStatement.executeQuery 方法通过 QueryOptimizer 对初步生成的执行计划进行了优化。
plan = connection.getQueryServices().getOptimizer().optimize(PhoenixStatement.this, plan);
此处我们需要查看优化后的 plan 对应的 SQL,该如何查看呢?总不能下一个断点,每次都停到这里看一下吧。这里介绍一个小技巧,就是在不中断程序的情况下,打印调试代码的变量值。
在断点标志上面点击鼠标右键,会弹出会话框。可以看出居然还可以根据某个条件进行中断,不过这不是我们关注的点。

点击 “More” 出现下面的对话框:

上面有 “Evaluate and log” 可以填写我们要打印的内容,此处可以用上下文的变量,然后单击 done,然后 debug 执行我们的代码,可以看到执行的每个 SQL 都有对应的、优化后的 SQL。
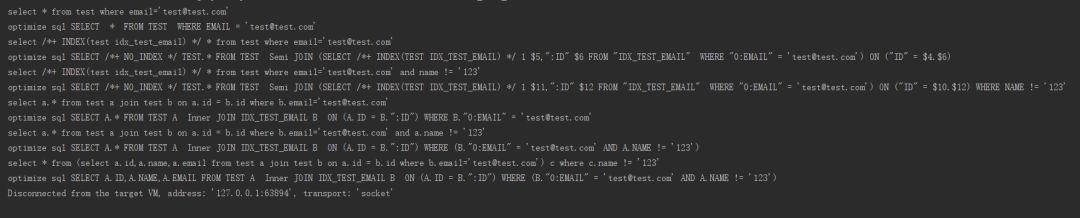
认真观察上面的输出,我们发现一个规律:所有能走索引的 SQL 都会用对应索引表的表名替代原表名,并且过滤条件也会透传给索引表。
可是这个规律说明什么呢?
这就意味着,查询外部索引时,所有的信息都已经有了!包括查询的字段,过滤条件,聚合条件等。我们只需要根据这些条件查询外部索引就行了。
总结
经过前面的分析,我们已经对 Phoenix 索引的创建、维护、使用有了简单的了解。接下来用思维导图为大家简单总结下:

上面的图画的比较简单,但可以用来帮助读者分析实现全文检索的基本过程。其实还是有很多细节没有讲解清楚的。比如字段如何投射、聚合如何实现、排序如何实现,索引表的 ROWKEY 如何编码、事务表有没有特殊的地方、如何做单元测试、索引字段如何与 ES(SOLR) 进行映射、Phoenix查询条件如何映射成 ES 查询代码、全文检索实现过程如何更加通用以便适配 ES 和 SOLR、如何度量全文检索的性能、创建索引时如何将属性透传给 ES。
具体实现的过程还是比较复杂的,另外 Phoenix 的代码质量并不是特别高,很多地方实现方式不统一,既要兼顾对源码的侵入性小,又要兼顾实现的通用型,作者还是着实下了一番功夫的。
作者介绍
吴少杰,爱好大数据生态的技术和框架,对数仓架构和实时计算比较熟悉,目前主要从事大数据开发和架构的工作
——END——
文章推荐:
关于 DataFun:
您的「在看」,我的动力!?


