「行知」Airbnb如何解决Embedding的数据稀疏问题?
- 2019 年 11 月 21 日
- 筆記

文章作者:王喆 Hulu Senior Research SDE 内容来源:王喆的机器学习笔记@知乎专栏 出品社区:DataFun
今天我们紧接上一篇文章从KDD 2018 Best Paper看Airbnb实时搜索排序中的Embedding技巧(https://zhuanlan.zhihu.com/p/55149901),聊一聊Airbnb如何利用embedding构建其搜索排序模型,以及其中最重要的工程经验,Aribnb如何使用工程手段解决生成embedding过程中的数据稀疏问题。
上篇文章中,我们介绍了Airbnb为了捕捉用户的短期兴趣,使用用户的点击数据构建了listing(也可称为item,即一个短租屋)的embedding,基于该embedding,可以很好的找出相似listing,但有所欠缺的是,该embedding并没有包含用户的长期兴趣信息。比如用户6个月前订了一个listing,其中包含了该用户对于房屋价格、房屋类型等属性的长期偏好,但由于之前的embedding只使用了session级别的点击数据,从而明显丢失了用户的长期兴趣信息。
为了捕捉用户的长期偏好,airbnb在这里使用了booking session序列。比如用户j在过去1年依次book过5个listing,那么其booking session就是

。既然有了booking session的集合,我们是否可以像之前对待click session一样拿直接应用w2v的方法得到embedding呢?答案是否定的,因为我们会遇到非常棘手的数据稀疏问题。
具体来讲booking session的数据稀疏问题表现在下面三点上:
1. book行为的总体数量本身就远远小于click的行为,所以booking session集合的大小是远远小于click session的;
2. 单一用户的book行为很少,大量用户在过去一年甚至只book过一个房源,这导致很多booking session sequence的长度为1;
3. 大部分listing被book的次数也少的可怜,大家知道w2v要训练出较稳定有意义的embedding,item最少需要出现5-10次,但大量listing的book次数少于5次,根本无法得到有效的embedding。
Airbnb如何解决如此严重的数据稀疏问题,训练出有意义的user embedding和listing embedding呢?他们给出的答案是基于某些属性规则做相似user和相似listing的聚合。
举例来说,listing的属性如下表所示:
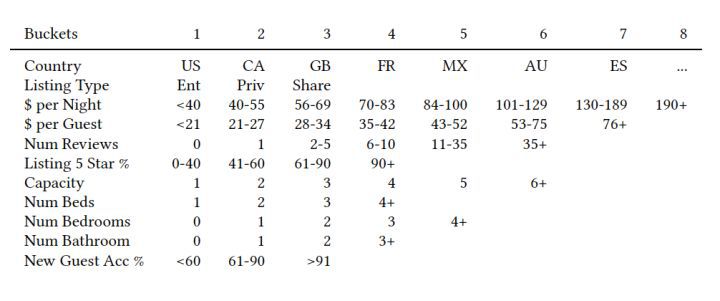
listing的属性
那么我们就可以用属性名和bucket id组成一个属性标识,比如说某个listing的国家是US,类型(listing type)是Ent(bucket 1),每晚的价格(per night)是56-59美金(bucket3),那么就可以用US_lt1_pn3来表示该listing的listing_type。

user type的属性及bucket
user_type的定义同理,我们可以看一下airbnb用了什么用户属性,从上表中我们看到有device type,是否填了简介,有没有头像照片,之前定过的平均价位等等,可以看出都是一些非常基础和通用的属性,这对于我们来说也有借鉴意义,因为任何网络服务都可以很容易的找出这些属性。
有了user type和listing type之后,一种直观的生成新的booking session sequence的方式是这样,直接把user type当作原来的user id,生成一个由listing type组成的booking session。这种方法能够解决数据稀疏性的问题,却无法直接得到user type embedding。为了让user type embedding和listing type embedding在同一个vector space中生成,airbnb采用了一种比较“反直觉”的方式。
针对某一user id按时间排序的booking session,

,我们用(user_type, listing_type)组成的元组替换掉原来的listing item,因此sequence变成了

,这里

指的就是listing l1对应的listing type,

指的是该user在book listing l1时的user type,由于某一user的user_type会随着时间变化,所以

不一定相同。
有了该sequence的定义,下面的问题就是如何训练embedding使得user type和listing type在一个空间内了。训练所用的objective完全沿用了上一篇文章的objective的形式,但由于我们用一个(user type,listing type)的元组替换掉了原来的listing,如何确定central item就成为了一个核心问题。针对该问题,文章的原话是这么说的:
instead of listing l , the center item that needs to be updated is either user_type (ut) or listing_type (lt) depending on which one is caught in the sliding window.
这个表述很有意思但也比较模糊,就是说在通过sliding window的形式计算objective的时候,central item可以是user type 也可以是listing type,这取决于我们在sliding window中“抓住”了哪个。
什么叫“抓住”?如何“抓住”,文章没有给出精确的定义,非常欢迎大家作出自己的解读。这里我先给出我的猜测。
因为文章之后列出了central item分别是user type和item type时的objective如下

user type objective

listing type objective
其中

是central item附近的user type和item type的集合。如果这样的话,这两个objective是完全一样的。
所以我推测airbnb应该是把所有元组扁平化了一下,把user type和item type当作完全相同的item去训练embedding了,如果是这样的话二者当然是在一个vector space中。虽然整个过程就很tricky,但也不失为一个好的工程解决办法。
这里我再次征求大家对于这个问题的见解,非常欢迎你的看法。
接下来为了引入“房主拒绝”(reject)这个action,airbnb又在objective中加入了reject这样一个negative signal,方法与上一篇文章中加入negative signal的方法相同,在此不再赘述。
其实除了计算user embedding外,airbnb在分享的slides中提到他们还直接把query embedding了,从最后的搜索效果来看,query embedding跟listing embedding也是处于一个vector space,大家可以从下图中看出embedding方法的神奇。

搜索“Greek Islands”引入Embedding前后的搜索结果

搜索“France Skiing”引入Embedding前后的搜索结果
可以看到,在引入embedding之前,搜索结果只能是文本上的关键词搜索,引入embedding之后,搜索结果甚至能够捕捉到搜索词的语义信息。比如输入France Skiing,虽然结果中没有一个listing带有Skiing这个关键词,但这个结果无一例外都是法国的滑雪胜地,这无疑是更接近用户动机的结果。
在这篇Slides中Airbnb并没有具体介绍是如何生成query embedding,大家可以思考一下query embedding的具体生成过程。
到此我介绍完了airbnb所有的embedding方法,这里我要强调的是,airbnb并没有直接把embedding similarity直接得到搜索结果,而是基于embedding得到不同的user-listing pair feature,然后输入搜索排序模型,得到最终的排序结果。下面我们来看一看airbnb的搜索排序模型和feature。
airbnb采用的搜索排序模型是一个pairwise的支持Lambda Rank的GBDT模型。该模型已经由airbnb的工程师开源,感兴趣的同学可以去学习一下(https://github.com/yarny/gbdt)。至于什么是pairwise,什么是Lambda Rank,不是本文的重点,不做过多介绍,感兴趣的同学可以自行学习。
我们关注的重点回到特征工程上来,airbnb基于embedding生成了哪些feature呢?这些feature又是如何驱动搜索结果的“实时”个性化呢?
下面列出了基于embedding的所有feature:

我们可以很清楚的看到,最后一个feature UserTypeListingTypeSim指的是 user type和listing type的similarity,该feature使用了我们这篇文章介绍的包含用户长期兴趣的embedding,除此之外的其他feature都是基于上篇文章介绍的listing embedding。比如EmbClickSim指的是candidate listing与用户最近点击过的listing的相似度。
这里我想我们可以回答这个问题了,为什么airbnb在文章题目中强调是real time personalization?原因就是由于在这些embedding相关的feature中,我们加入了“最近点击listing的相似度”,“最后点击listing的相似度”这类特征,由于这类特征的存在,用户在点击浏览的过程中就可以得到实时的反馈,搜索结果也是实时地根据用户的点击行为而改变,所以这无疑是一个real time个性化系统。
最后贴出引入embedding前后airbnb搜索排序模型的效果提升以及各feature的重要度,大家可以做参考。

效果提升

各feature重要度排名
至此我们介绍完了airbnb实时搜索排序这篇文章的所有内容,总结来说,这又是一篇极佳的工程实践和理论创新结合的文章,完美符合我们专栏的偏好,希望大家有所收获。
照例还是总结两个问题以供大家讨论:
1. 为了使user type和listing type在一个vector space中,airbnb到底是怎么处理booking session的?
2. airbnb是如何进行query embedding,使其能够捕捉到推荐地点的语义信息的?
最后:欢迎大家点击文末阅读原文,与王喆老师交流。
作者介绍:
王喆,Hulu Senior Research SDE,知乎专栏「王喆的机器学习笔记」作者。
专栏地址:https://zhuanlan.zhihu.com/wangzhenotes
参考资料:
1. Search Ranking and Personalization at Airbnb Slides
2. Real-time Personalization using Embeddings for Search Ranking at Airbnb
3. Recommender System Paper List
4. 王喆:从KDD 2018 Best Paper看Airbnb实时搜索排序中的Embedding技巧
——END——
|
|
|---|
关于社区:
DataFun定位于最实用的数据智能社区,主要形式为线下的深度沙龙、线上的内容整理。希望将工业界专家在各自场景下的实践经验,通过DataFun的平台传播和扩散,对即将或已经开始相关尝试的同学有启发和借鉴。
DataFun的愿景是:为大数据、人工智能从业者和爱好者打造一个分享、交流、学习、成长的平台,让数据科学领域的知识和经验更好的传播和落地产生价值。
DataFun社区成立至今,已经成功在全国范围内举办数十场线下技术沙龙,有近俩百位的业内专家参与分享,聚集了万余大数据、算法相关领域从业者。
看官点下「好看」再走呗!?

