(在模仿中精进数据可视化05)疫情期间市值增长top25公司
本文完整代码及数据已上传至我的
Github仓库//github.com/CNFeffery/FefferyViz
1 简介
新冠疫情对很多实体经济带来冲击的同时,也给很多公司带来了新的增长点。前段时间我看到图1所示的数据可视化作品,针对2020年1月1日到6月16日之间,世界范围内市值增大最多的25家公司进行可视化:
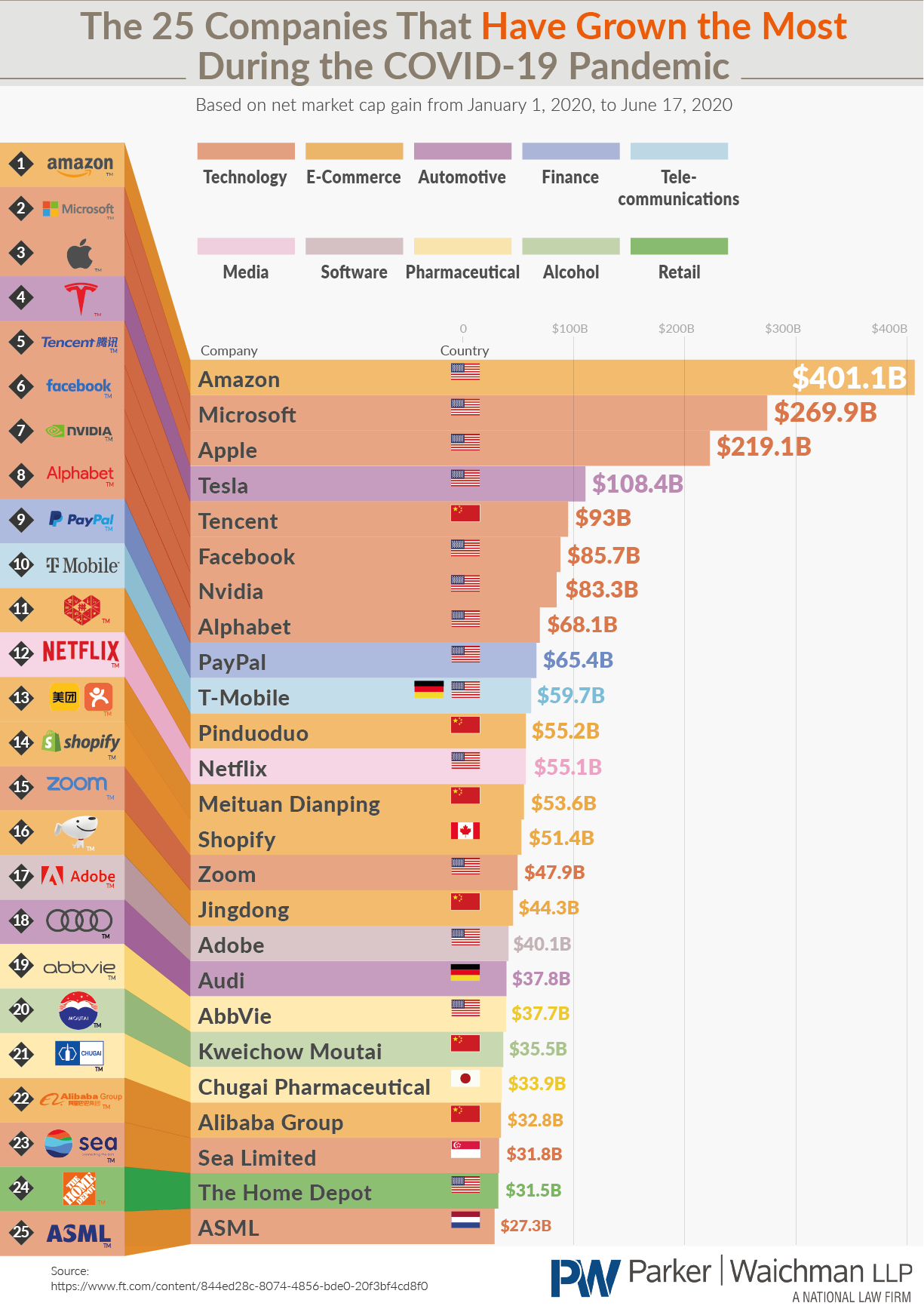
这样一张典型的商业图表,看起来形式巧妙,且表现出很多数据信息。而今天的文章,我就将带大家学习如何利用matplotlib来条理清楚地制作出这种类型的可视化作品。
2 模仿过程
首先我们还是像过往的文章中一样分析一下原作品的元素构成:
- 立体感的营造
其实原作品咋一看起来的立体感,只是玩了个花招,我们本质上只需要创建出最左列竖直方向上等分25份的填充区域,再向右偏移适合的距离后,缩小竖直方向上的总体范围再25等分,最后将这两部分等分的填充区域连接起来,最后再为中间的连接区域蒙上一层等大小的带透明度的暗色蒙版即可~
- logo与国旗图片的插入
原作品中众多图片,只要仔细观察就可以发现是手动PS上去的,存在着一些微小的瑕疵,而我们既然要用matplotlib来制作这张图,当然直接写循环控制图片的插入即可。
在matplotlib中向画板插入其他图片有很多方法,我们为了控制好众多logo之间的协调,可以使用matplotlib中的inset_axes()来插入指定位置和尺寸的子图。
- 数值标注的控制
原作品中不同公司市值增长的不同体现在不同长度柱体以及不同大小文字标注的映射之上的,我们可以配合简单的归一化变换,来约束字体和柱体长度的映射。
搞明白原作品中主要元素的实现方式之后,我们首先来读入原始数据(你可以在文章开头的Github仓库中找到原始数据及相关附件):
import matplotlib.pyplot as plt
import pandas as pd
# 设置默认字体
plt.rcParams['font.sans-serif'] = ['Times New Roman']
raw = pd.read_excel('data.xlsx')
raw.head()
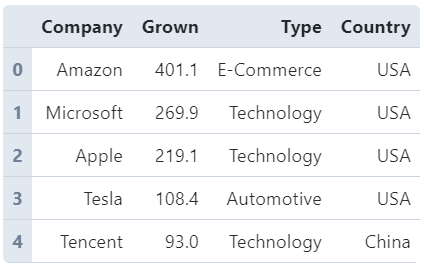
接着为了方便处理公司类型向指定配色的映射,我们先来创建一个映射字典:
type2color = {
'Technology': '#e2a080',
'E-Commerce': '#ebb66a',
'Automotive': '#c198ba',
'Finance': '#aab5d8',
'Tele-communications': '#bdd7e4',
'Media': '#efcfde',
'Software': '#d5c1c4',
'Pharmaceutical': '#f9e4ad',
'Alcohol': '#c3d3ac',
'Retail': '#88bb70'
}
而为了创建出原作品中最重要的不同条带,我们可以配合matplotlib中的fill_between()。
而为了处理好左侧与右侧的竖直方向25等分区域,我们可以在对原数据每一行循环的过程中,自定义下列函数来计算区域范围:
def create_fill_area(row, top_y=0.8, bottom_y=0.01):
# 初始化包围填充区域的上下线条y坐标
line1, line2 = [1 - 0.04*row, 1 - 0.04*row], [1- 0.04*(row+1), 1- 0.04*(row+1)]
# 追加阴影段y坐标
line1.append(0.01 + (25 - row) * (0.8 - 0.01) / 25)
line2.append(0.01 + (25 - row - 1) * (0.8 - 0.01) / 25)
# 追加最后一段平行段y坐标
line1.append(0.01 + (25 - row) * (0.8 - 0.01) / 25)
line2.append(0.01 + (25 - row - 1) * (0.8 - 0.01) / 25)
return line1, line2
做好这些准备工作之后,剩余的绘图过程就很简单了,最终得到的模仿作品如下:
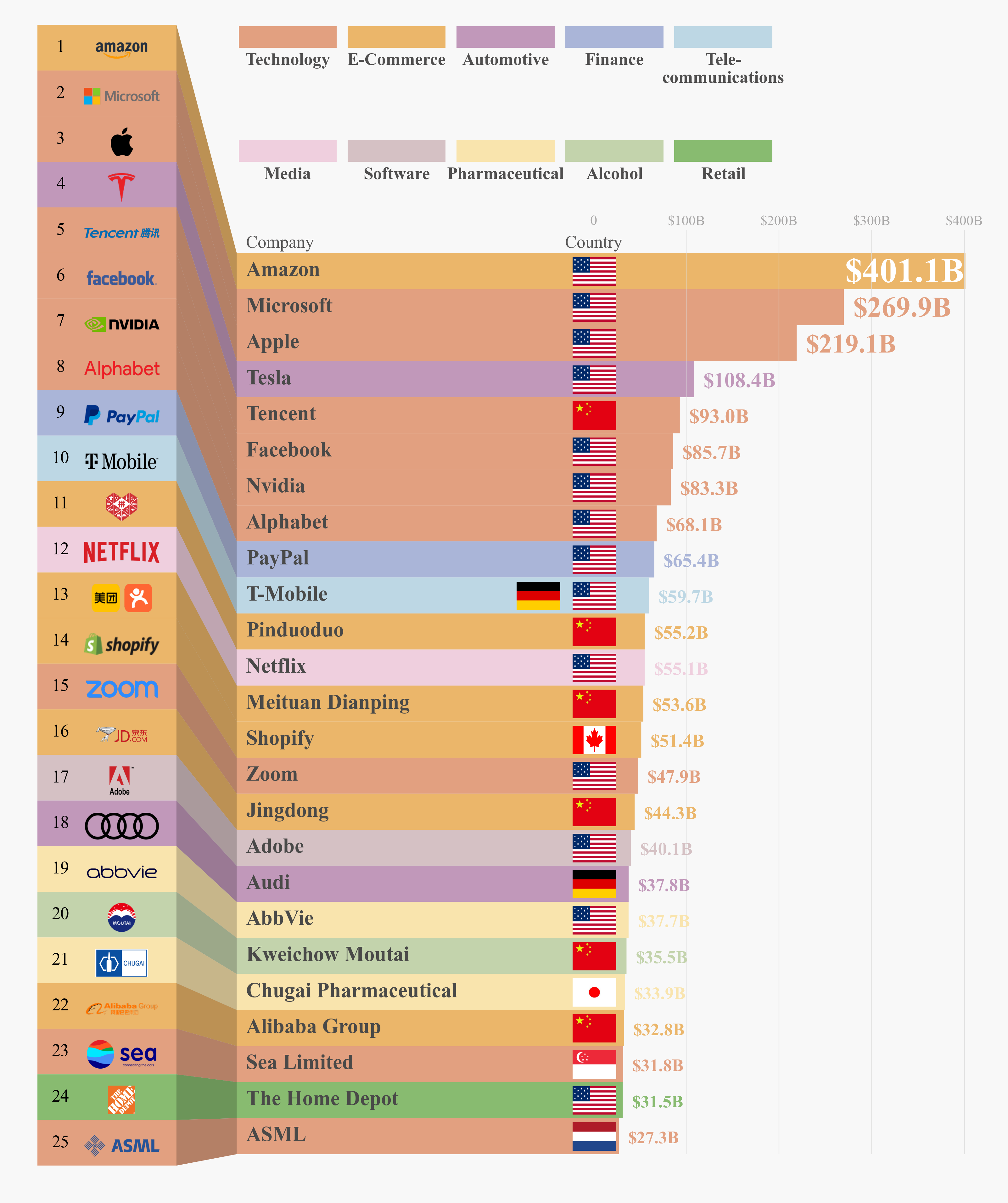
完整代码如下,虽然看起来略多,其实大部分都是重复的逻辑传入不同的参数而已,还是比较简单的:
fig, ax = plt.subplots(figsize=(4.8, 6))
ax.set_xlim(0, 1.01)
ax.set_ylim(0, 1)
for row in range(raw.shape[0]):
# 定义区域填充对应的x坐标
x = [0, 0.15, 0.215, 0.6+raw.at[row, 'Grown'] / 1000]
# 生成区域填充对应的y坐标
line1, line2 = create_fill_area(row)
# 对指定区域进行填充
ax.fill_between(x,
line1,
line2,
color=type2color[raw.at[row, 'Type']],
edgecolor='none')
# 从logo文件夹下读取对应logo图片
try:
logo = plt.imread(f'logo/{raw.at[row, "Company"]}.png')
except FileNotFoundError:
logo = plt.imread(f'logo/{raw.at[row, "Company"]}.jpg')
# 插入公司logo
ax_logo = ax.inset_axes((0.05, 1 - 0.04*(row+1)+0.005, 0.08, 0.025))
ax_logo.imshow(logo)
ax_logo.axis('off')
ax_logo.set_facecolor(type2color[raw.at[row, 'Type']])
# 处理单个及多个国家情况下的国旗绘制
for idx, country in enumerate(raw.at[row, 'Country'].split('&')[::-1]):
# 读取对应国旗图片
flag = plt.imread(f'flag/{country}.png')
# 插入国旗子图
ax_flag = ax.inset_axes((0.545-idx*0.06, 0.013+(25 - row - 1)*((0.8 - 0.01) / 25), 0.1, 0.025))
ax_flag.imshow(flag)
ax_flag.axis('off')
ax_flag.set_facecolor(type2color[raw.at[row, 'Type']])
# 绘制排名
ax.text(0.025, (1 - 0.04*row + 1 - 0.04*(row+1)) / 2, str(row+1),
ha='center', va='center',
fontsize=5, color='black')
# 绘制公司名称
ax.text(0.215+0.01, 0.5 * (0.01 + (25 - row - 1) * (0.8 - 0.01) / 25 + 0.01 + (25 - row) * (0.8 - 0.01) / 25),
raw.at[row, 'Company'],
ha='left', va='center',
fontsize=6, color='#494948',
weight='bold')
# 处理第一名文字在填充区域内部,其余文字在填充区域外的情况
if raw.at[row, 'Company'] == 'Amazon':
ax.text(1, 0.5 * (0.01 + (25 - row) * (0.8 - 0.01) / 25
+ 0.01 + (25 - row - 1) * (0.8 - 0.01) / 25)-0.0025,
'$'+str(raw.at[row, 'Grown'])+'B',
color='white',
fontsize=10,
ha='right',
va='center',
weight='bold')
else:
# 配合归一化对字体进行大小映射
ax.text(0.6+raw.at[row, 'Grown'] / 1000 + 0.01,
0.5 * (0.01 + (25 - row) * (0.8 - 0.01) / 25 + 0.01 + (25 - row - 1) * (0.8 - 0.01) / 25)-0.0025,
'$'+str(raw.at[row, 'Grown'])+'B',
color=type2color[raw.at[row, 'Type']],
fontsize=5+((raw.at[row, 'Grown'] - raw['Grown'].min())
/ (raw['Grown'].max() - raw['Grown'].min())) * 5,
ha='left',
va='center',
weight='bold')
# 对指定区域进行带透明度的黑色蒙版,以达到阴影效果
ax.fill_between([0.15, 0.215],
[0, 0.01],
[1, 0.8],
color='black',
alpha=0.2, # 设置透明度
edgecolor='none')
# 补充其余文字标注
ax.text(0.215+0.01, 0.805, 'Company',
color='#565555', fontsize=5,
ha='left')
ax.text(0.6, 0.805, 'Country',
color='#565555', fontsize=5,
ha='center')
# 补充上方数值刻度
ax.text(0.6, 0.825, '0',
color='#a9a8a8', fontsize=4,
ha='center')
for i in range(1, 5):
ax.text(0.6+0.1*i, 0.825, f'${i}00B',
color='#a9a8a8', fontsize=4,
ha='center')
ax.vlines(0.6+0.1*i, 0.01, 0.82,
color='#dcdcdb', linewidth=0.2)
ax.set_xticks([])
ax.set_yticks([])
ax.spines['left'].set_color('none')
ax.spines['right'].set_color('none')
ax.spines['top'].set_color('none')
ax.spines['bottom'].set_color('none')
# 补充下排图例
ax_bar1 = ax.inset_axes((0.215, 0.88, 0.57, 0.02), transform=ax.transAxes)
ax_bar1.set_xlim(-0.45, 4.45)
ax_bar1.bar(range(5), height=1, width=0.9,
color=['#efcfde', '#d5c1c4', '#f9e4ad', '#c3d3ac', '#88bb70'])
ax_bar1.set_xticks(range(5))
ax_bar1.set_xticklabels(['Media', 'Software', 'Pharmaceutical', 'Alcohol', 'Retail'],
fontsize=5, color='#4f4e4e', weight='bold')
ax_bar1.set_yticks([])
ax_bar1.spines['left'].set_color('none')
ax_bar1.spines['right'].set_color('none')
ax_bar1.spines['top'].set_color('none')
ax_bar1.spines['bottom'].set_color('none')
ax_bar1.tick_params(color='none', pad=-2)
ax_bar1.set_facecolor('#f8f8f8')
# 补充上排图例
ax_bar2 = ax.inset_axes((0.215, 0.98, 0.57, 0.02), transform=ax.transAxes)
ax_bar2.set_xlim(-0.45, 4.45)
ax_bar2.bar(range(5), height=1, width=0.9,
color=['#e2a080', '#ebb66a', '#c198ba', '#aab5d8', '#bdd7e4'])
ax_bar2.set_xticks(range(5))
ax_bar2.set_xticklabels(['Technology', 'E-Commerce', 'Automotive', 'Finance', 'Tele-\ncommunications'],
fontsize=5, color='#4f4e4e', weight='bold')
ax_bar2.set_yticks([])
ax_bar2.spines['left'].set_color('none')
ax_bar2.spines['right'].set_color('none')
ax_bar2.spines['top'].set_color('none')
ax_bar2.spines['bottom'].set_color('none')
ax_bar2.tick_params(color='none', pad=-2)
ax_bar2.set_facecolor('#f8f8f8')
ax.set_facecolor('#f8f8f8')
fig.set_facecolor('#f8f8f8')
fig.savefig('图3.png', dpi=800, bbox_inches='tight')
你可以自由尝试不同的配色方案,或者换成你的数据,快速制作出同样别致的可视化作品😎~
以上就是本文的全部内容,欢迎在评论区与我进行讨论~


