梯度消失和梯度爆炸及解决方案
梯度在神经网络中的作用
在谈梯度消失和梯度爆炸的问题之前,我们先来考虑一下为什么我们要利用梯度,同时铺垫一些公式,以便于后面的理解。
存在梯度消失和梯度爆炸问题的根本原因就是我们在深度神网络中利用反向传播的思想来进行权重的更新。即根据损失函数计算出的误差,然后通过梯度反向传播来减小误差、更新权重。
我们假设,存在一个如图所示的简单神经网络,我们可以得到相关的公式如右侧所示:

其中函数 g 是激活函数,c 是偏置值,t 是目标值,E 是损失函数,这里利用的是平方误差损失函数。我们可以很清晰的看出,其实整个神经网络就是一个复合函数:
\]
带入到损失函数中,公式如下:
\]
为了便于讨论,我们对上面的神经网络进行简化,简化为每一层只有一个节点的网络,这样我们的公式也可以相应的简化:
\]
\]
这样我们的目的就变得更加明确,整个函数中需要调整的就是 \(c\) 和 \(b_1\) 这两个偏置值以及 \(v_1\) 和 \(w_{11}\) 这两个权重。
我们假设权重空间如图所示,其中 cost function 就是上面的 E, State Space 就是上面的 \(c\) 和 \(b_1\) 这两个偏置值以及 \(v_1\) 和 \(w_{11}\) 这两个权重:

因为我们知道我们的目的是找到最小的 E,所以需要通过调整 \(c\) 和 \(b_1\) 这两个偏置值以及 \(v_1\) 和 \(w_{11}\) 这两个权重的值,来找到图中的 Global Minimum,即 E 最小的点。这一类寻找最小值的问题,在数学上利用梯度下降算法可以有效的解决。
梯度消失的原因
我们利用上面提到的公式来说明梯度消失产生的原因,求代价函数对 \(w_{11}\) 的偏导数:
\]
假设,当我们的激活函数使用 Sigmoid 函数的时候,如果 Sigmoid 公式为:
\]
带入替换 g() 后,公式变为:
\]
根据上述公式,我们可以得出,Sigmoid函数的导数图像如下所示:

而我们神经网络中的初始权值也一般是小于 1 的数,所以相当于公式中是多个小于 1 的数在不断的相乘,导致乘积和还很小。这只是有两层的时候,如果层数不断增多,乘积和会越来越趋近于 0,以至于当层数过多的时候,最底层的梯度会趋近于 0,无法进行更新,并且 Sigmoid 函数也会因为初始权值过小而趋近于 0,导致斜率趋近于 0,也导致了无法更新。
除了这个情况以外,还有一个情况会产生梯度消失的问题,即当我们的权重设置的过大时候,较高的层的激活函数会产生饱和现象,如果利用 Sigmoid 函数可能会无限趋近于 1,这个时候斜率接近 0,最终计算的梯度一样也会接近 0, 最终导致无法更新。
可以参考如下图片,底层要比高层的学习速度低特别多。

梯度爆炸的原因
当我们取得的权重值为一个中间值的时候,如果这个中间值使 \(S'(s)w > 1\) ,那么会导致网络的底层会比高层的梯度变化更快,则就会导致梯度爆炸(激增)的问题。
避免梯度消失和梯度爆炸的方案
-
使用新的激活函数
- Sigmoid 函数 和 双曲正切函数都会导致梯度消失的问题。ReLU 函数当 x < 0,的时候一样会导致无法学习。
- 利用一些改进的 ReLU 可以在一定程度上避免梯度消失的问题。例如,ELU 和 Leaky ReLU,这些都是 ReLU 的变体。
-
权重初始化
在初始化权重的时候,使权重满足如下公式:
\]
其中 \(G_1\) 是估计的激活函数的平均值,\(n^{out}_i\) 是第 i 层神经网络上向外连接的平均值
-
批量规范化
我们要规范化一个特定层节点的激活,利用如下公式:
\[\hat{x}_k^{(i)} = \frac{x_k^{(i)} – Mean[x_k^{(i)}]}{\sqrt{Var[x_k^{(i)}]}}
\]然后我们利用自己的自定义平均值和方差来移动和调整它,并且用反向传播进行训练
\[y_k^{(i)} = \beta_k^{(i)} + \gamma_k^{(i)}\times \hat{x}_k^{(i)}
\] -
长短记忆网络(LSTM)
-
逐层无监督预训练(layer-wise unsupervised pre-training)
-
残差网络(Residual Network)
- 在传统网络的基础,在两个连续的堆叠层上增加一个到输出的直接连接,也叫跳过连接,使这些层分流。
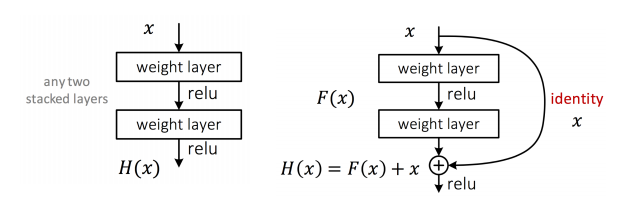
- \(F(x)\) 被称为一个 residual component,主要是纠正以前层的错误或者提供前一层计算不出的额外的细节
- 如果超过了 100 层需要在添加残差之前就使用 ReLU 而不是之后。这个过程被叫做 identity skip connection。
-
梯度截断



