小白也能看懂的Redis教学基础篇——朋友面试被Skiplist跳跃表拦住了
各位看官大大们,双节快乐 !!!
这是本系列博客的第二篇,主要讲的是Redis基础数据结构中ZSet(有序集合)底层实现之一的Skiplist跳跃表。
不知道那些是Redis基础数据结构的看官们,可以翻阅我的上一篇文章:
小白也能看懂的REDIS教学基础篇——REDIS基础数据结构

今天我朋友突然找到我,说他面试被刷了。
我一脸吃惊,忙问到:怎么了,倒在什么题上了。
朋友说:面试官说,你说你了解Redis的基础数据结构,那我问问你,你知道什么是Skiplist跳跃表吗?讲讲它是一种什么样的数据结构。它有什么优势和缺陷,它是如何插入和删除的?
我:那你怎么回答的?
我朋友:我就说Redis不是只有五种基本数据结构 字符串(strings),列表(lists), 字典(dictht),集合(sets), 有序集合(ZSet)吗?然后人家就让我回家等通知了。
我:…
我朋友:怎么了,你怎么一副无语的表情。

我:哎,还是由我来给你科普一下吧。
Skiplist 跳跃表是跳表出自 William Pugh 于1989年发表的论文《Skip Lists: A Probabilistic Alternative toBalanced Trees 》。
在论文中 William Pugh 写到;

译文大意为:
跳跃表:平衡树的概率替代方案
跳跃列表是一种可以代替平衡树的数据结构。跳跃列表使用概率平衡,而不是严格的强制平衡,因此在跳跃列表中插入和删除的算法比平衡树的算法简单得多,速度也快得多。
注:平衡树(Balance Tree) 指的是,任意节点的子树的高度差都小于等于1。常见的符合平衡树的有,B树(多路平衡搜索树)、AVL树(二叉平衡搜索树)。
看到这里,看官们是不是一头雾水?先不要急,让我们来看看跳跃表的完整结构图。

看到这的看官是不有种想骂人的冲动?心里在想,这是个什么玩意,比平衡树还复杂。

//跳表 typedef struct zskiplist{ //头结点和尾节点的指针 struct skiplistNode *header, *tail; //表中节点的数量 unsigned long length; //表中层数最大的节点层数 int level; }; //跳表节点 typedef struct zskiplistNode{ //后退指针 struct zskiplistNode *backward; //分值 double score; //成员对象 robj *obj; //层 struct zskiplistLevel{ //前进指针 struct zskiplistNode *forward; //跨度 unsigned int span; } level[]; };
- skiplistNode *header, *tail 指向首尾节点的指针。
- long length 表中节点的总数。
- int level 所有节点中层数最高的节点的层数。
- zskiplistNode *backward 后退指针,用来从尾部开始遍历到首节点。
- double score 分值,元素的排位分值。
- robj *obj 元素的对象指针。
- zskiplistNode *forward 前进指针指向该层下一个元素的指针。
- int span 跨度,用于记录两个节点之间的距离,跨度越大证明两个节点离得越远,在查找某个节点的过程中,将跨度累加,就是这个节点在跳跃表中的排位rank。
层是跳跃表节点的精髓和核心所在,跳跃表节点的level数组可以包含多个层元素。每个层元素都包含一个指向其他节点的指针,程序可以通过这些层来快速查找其他节点。一般来说,层数量越多,查找其他元素的速度就越快。
但是一个元素在插入时,他的层是怎么获得的呢?我们来看下面这个方法(此方法是仿照论文中的描述,用java实现的)。
/** * 获取层级 * @param maxLevel 最大支持的层级数 * @return */ private int randomLevel(int maxLevel){ int lvl = 1; /** * 这里是关键 Math.random() > (0.5D) 等于true 的概率是 1/2 * 所以 lvl = 1 的概率是 1/2 lvl = 2 的概率 是 (1/2)*(1/2) = 1/4 * lvl = 3 的概率是 (1/2)*(1/2)*(1/2) = 1/8 从这里可以看出 lvl 越大概率越低 */ for(;Math.random() > (0.5D) && lvl < maxLevel;){ lvl += 1; } return lvl; }
从这个方法可以看出,对于每次新插入的元素,都要调用这个随机算法获得元素的层级。这里也正好对应了文章开头,论文中的话:跳跃列表使用概率平衡,而不是严格的强制平衡。
从概率上来说,期望的目标是分配到lv 1 是50%的概率,分配到lv 2 是百分之25%的概率,分配到lv 3 是12.5% 以此类推。Redis的跳跃表共有32层,可以容纳 2^32 个元素,在Redis标准源码中
元素的晋升几率只有25%,也就是上面代码中 0.5D 这个其实应该是 0.25D。所以Redis中的跳跃表更加扁平化,层高相对不高,这就带来一个问题,层高不高的话,跨度就小,查找元素需要遍历的次数也就相应的增加了。
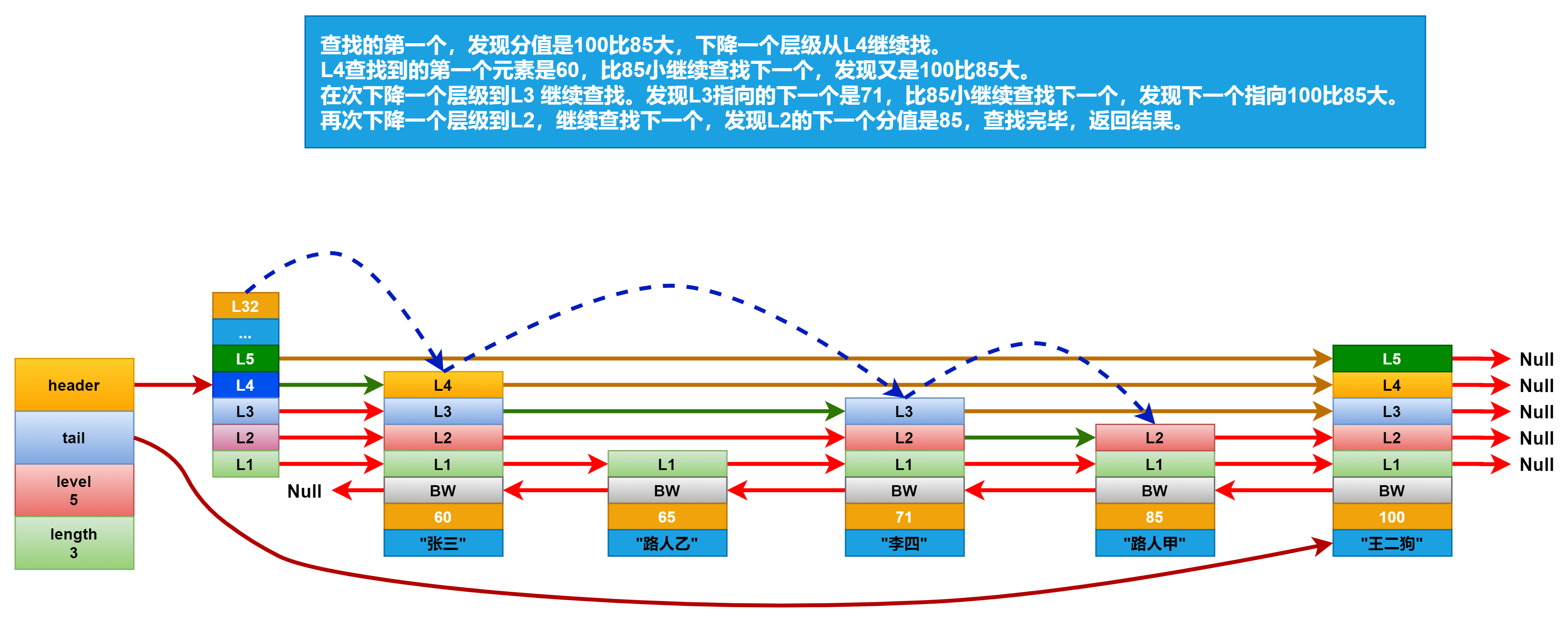
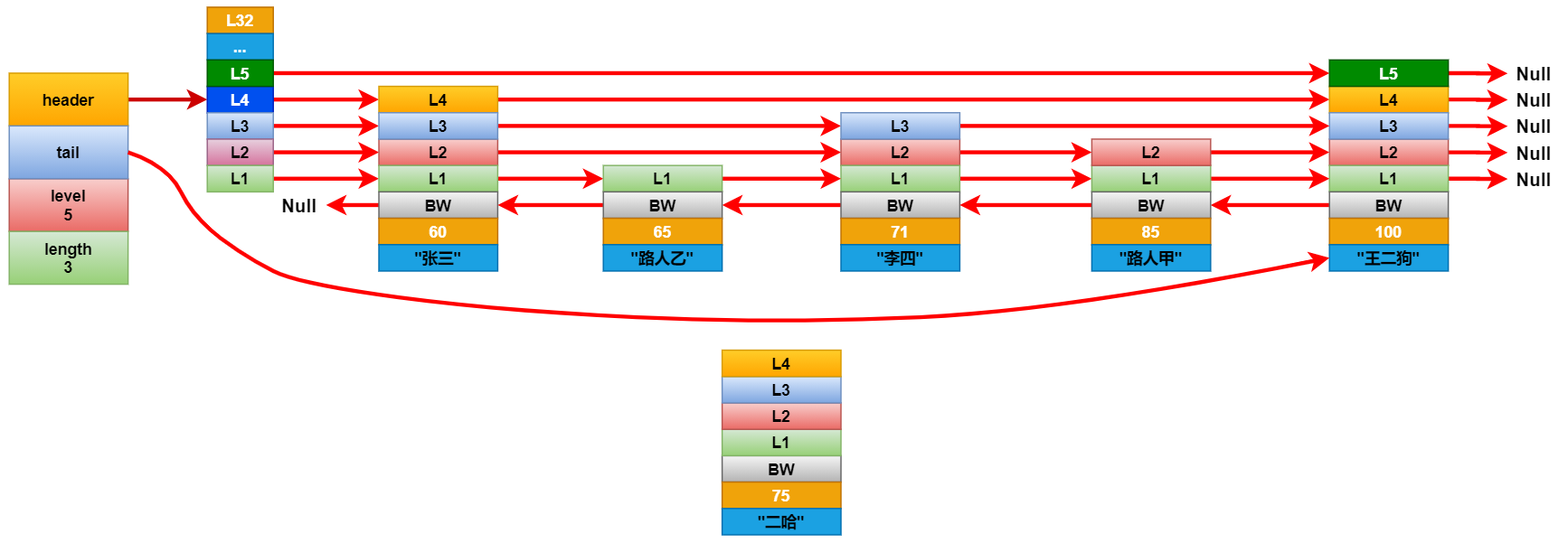
查找元素:
跳越表的元素查找是从header 的第 zskiplist.level(表中层数最大的节点层数) 层开始遍历的。他先会判断最高层指向的下一个元素,是否是要找的元素,如果不是,判断是不是比要找的元素小,
如果比要找的元素小,就继续查找下一个。如果比要找的元素大,就向下走一个层级,比如一开始是lv 5,如果找到的元素比要找的元素大,就下降一个层级,到lv 4 继续找。以此类推,直到找到期望的元素为止。
现在我们要查找分数为85分的学生,查找路径如下图所示
插入元素:
创建一个新的元素节点。然后在调用 randomLevel 获取节点层级。

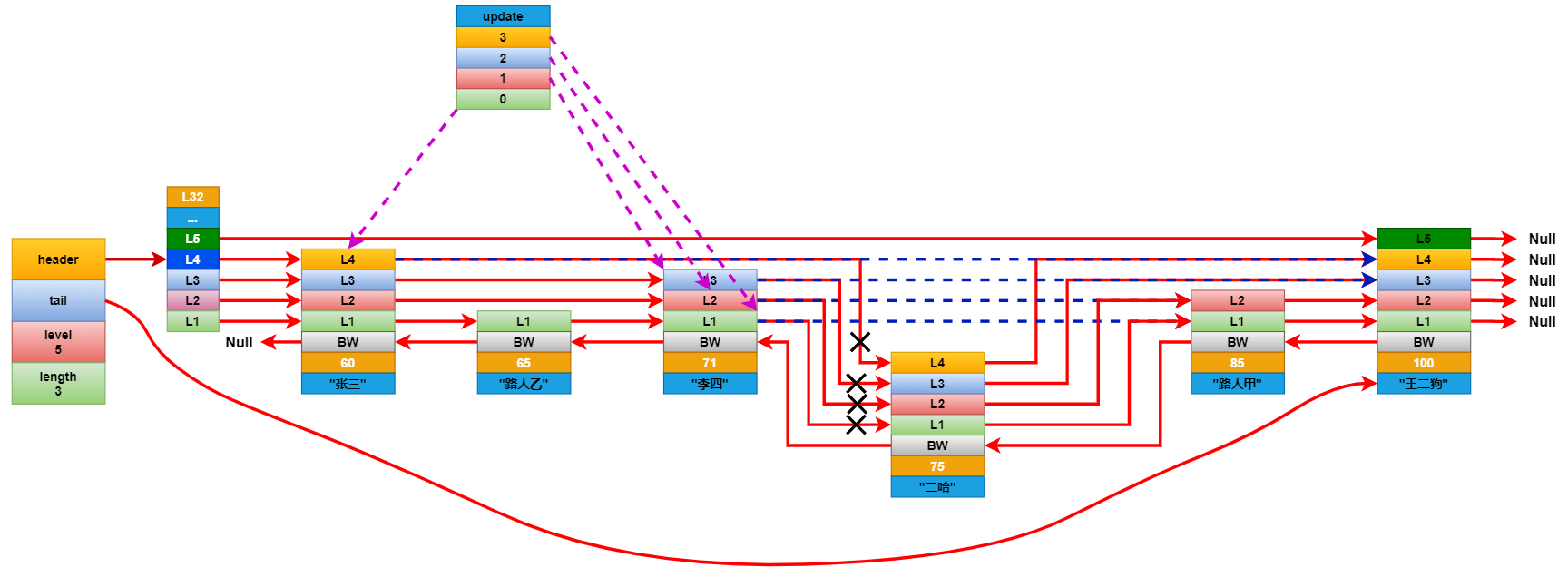
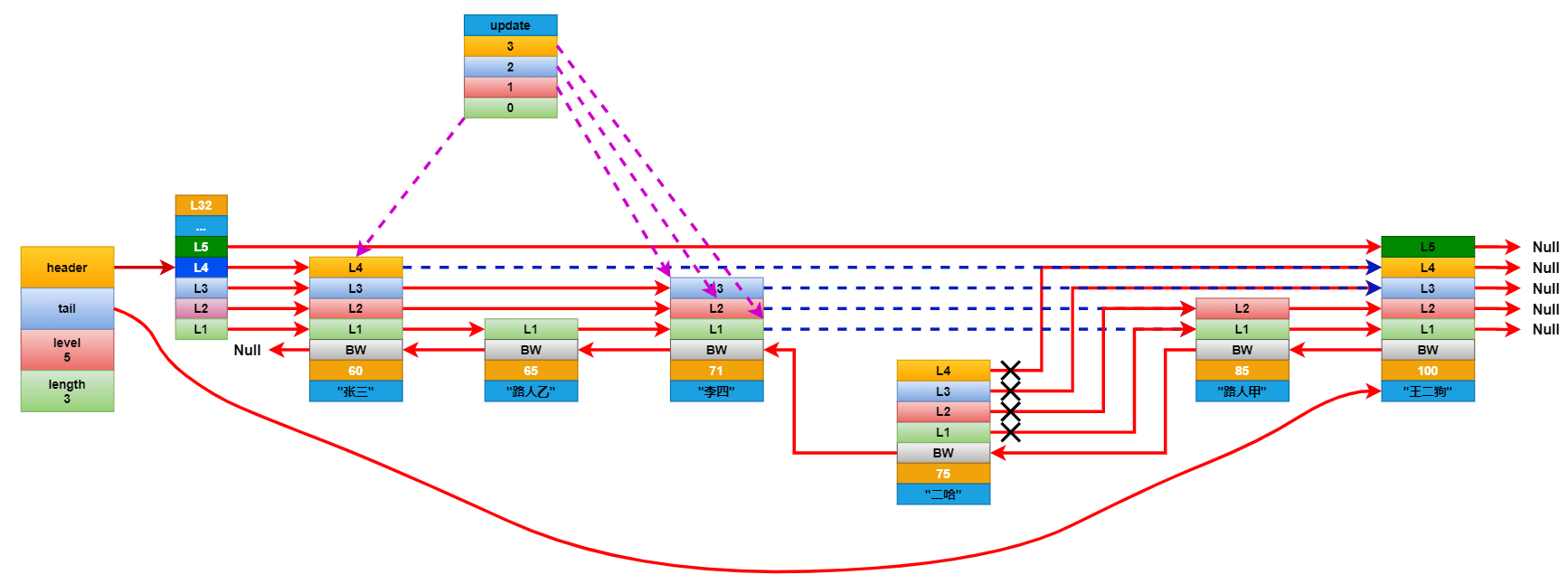
想要插入元素,就要先查找到所有元素中分值仅小于插入元素的分值的原数。比如要在上面的列表中插入一个分数为75分的学生二哈,就要先查找到分数仅小于75分的学生。在查找的时候还要记录下要更新的层级。如二哈这个节点拥有L4就要记录下据距他最近的L4,L3,L2,L1。

将新增节点每个层的前进指针连接到它对应的要更新层的前进指针指向的下一个节点。然后遍历要更新的层数组,断开这些层的前进指针,并将它连接到新增的几点上。这里基本和链表是一样的更新方式。最后更新后退节点。
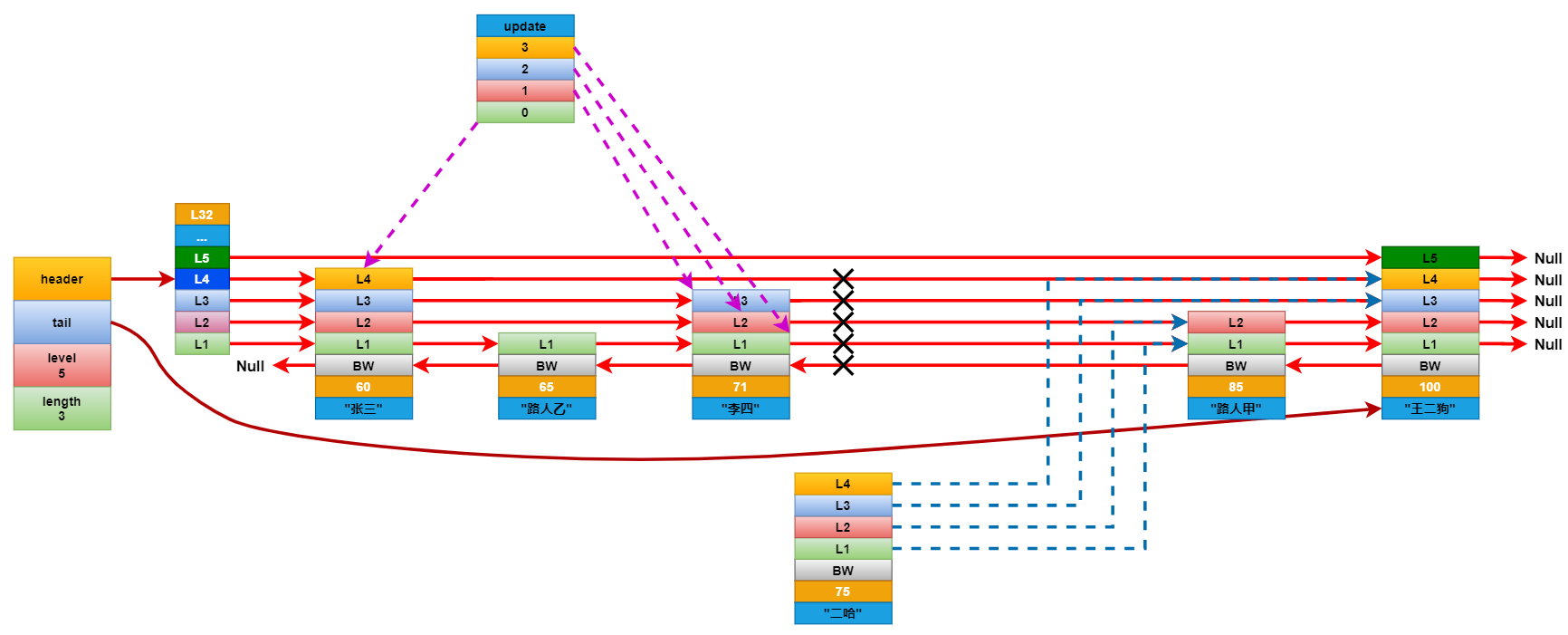
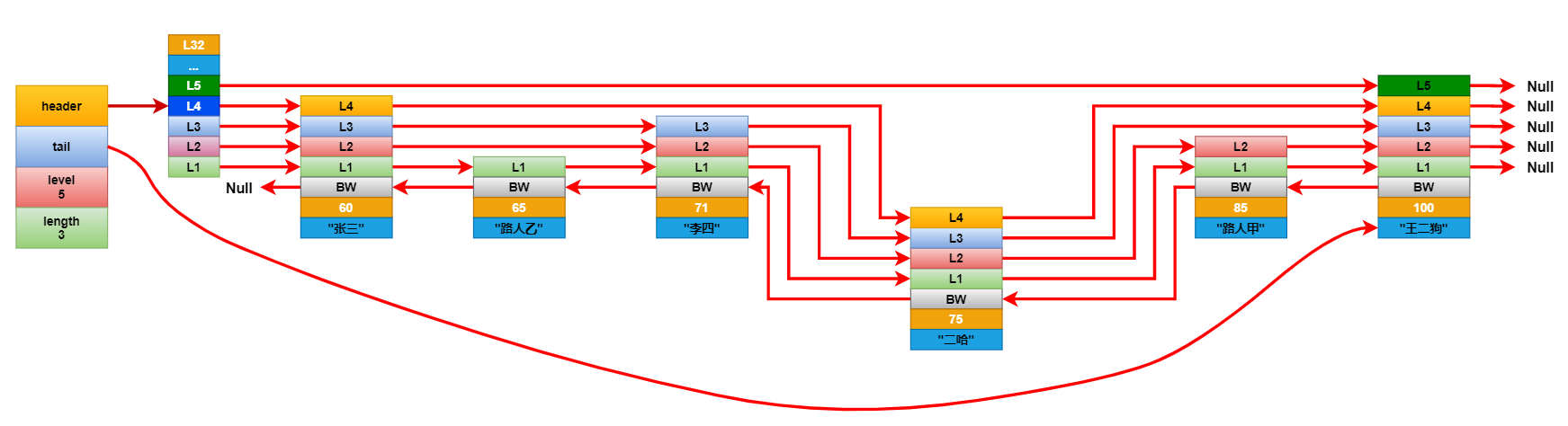
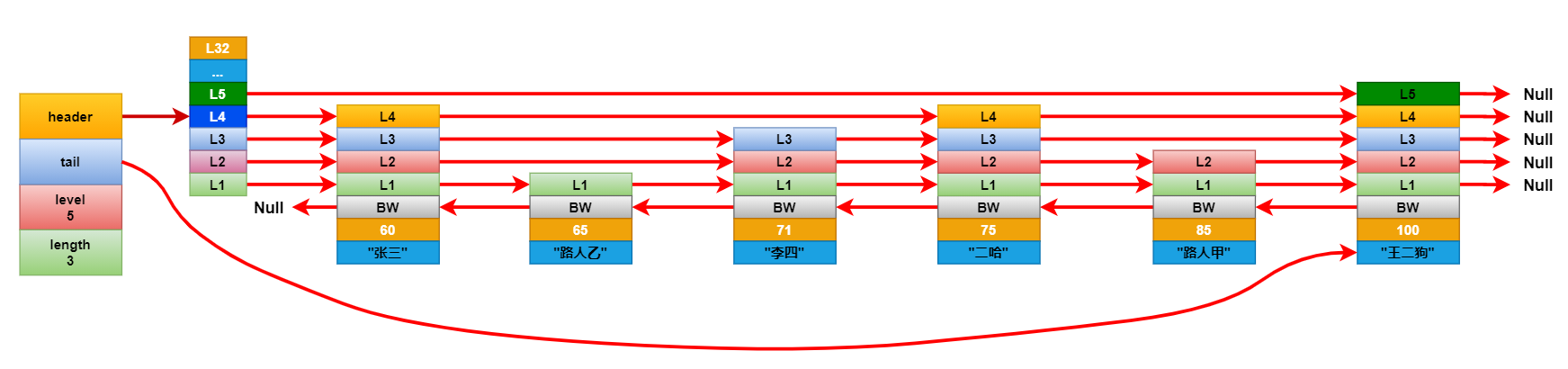
连接更新完成后,看看新增节点的层级是否大于跳跃表中记录的节点最大层级高度,如果大于就将跳跃表的最大层级高度更新成新节点的层级高度。
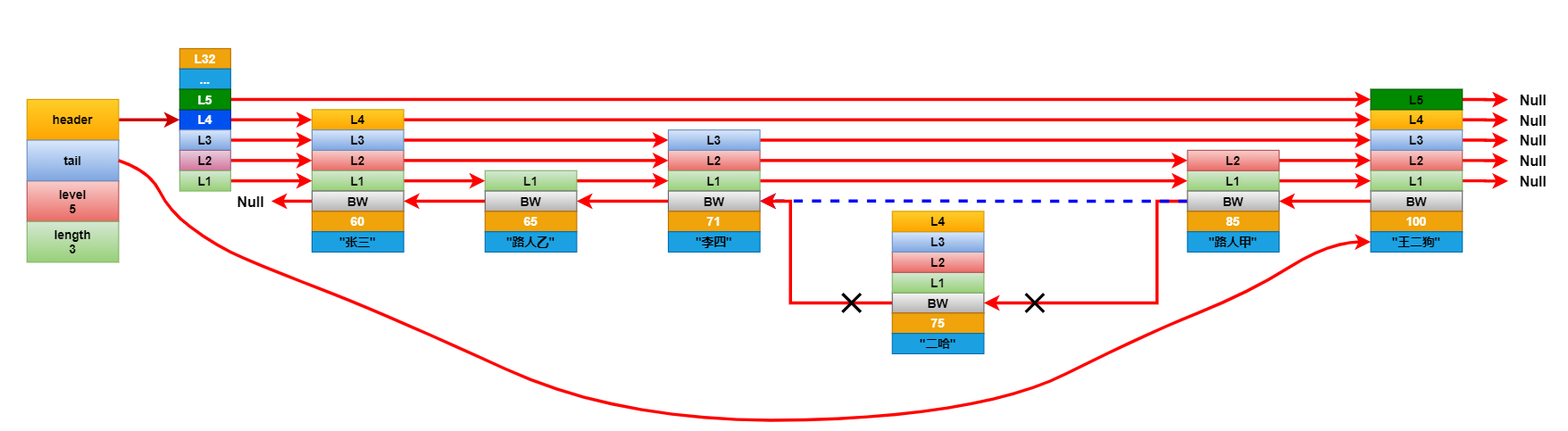
删除元素:
删除节点过程和插入类似,都需要先把这个节点找出,然后对于每个相关节点重排一下向前向后指针,同时还要注意更新下跳跃表中记录的最大层级高度。

更新元素:
当我们调用ZSet的zadd方法时,如果该元素不存在,就执行正常的插入过程。如果元素已经存在了,如果要更新分值,则Redis会先删除原先的元素,在插入新的元素。如果不用更新分值,Redis会直接更新节点上的元素数据(这是在5.0以后的改动,之前的是不论跟不跟新都直接先删除在插入)。
参考书籍:
《Reids设计与实现》
《Redis深度历险——核心原理与应用实践》
创作不易,如果转载请注明出处,小编在此感谢各位看官。


