大数据平台Hadoop集群搭建
一、概念
Hadoop是由java语言编写的,在分布式服务器集群上存储海量数据并运行分布式分析应用的开源框架,其核心部件是HDFS与MapReduce。HDFS是一个分布式文件系统,类似mogilefs,但又不同于mogilefs,hdfs由存放文件元数据信息的namenode和存放数据的服务器datanode组成;hdfs它不同于mogilefs,hdfs把元数据信息放在内存中,而mogilefs把元数据放在数据库中;而对于hdfs的元数据信息持久化是依靠secondary name node(第二名称节点),第二名称节点并不是真正扮演名称节点角色,它的主要任务是周期性地将编辑日志合并至名称空间镜像文件中以免编辑日志变得过大;它可以独立运行在一个物理主机上,并需要同名称节点同样大小的内存资源来完成文件合并;另外它还保持一份名称空间镜像的副本,以防名称节点挂了,丢失数据;然而根据其工作机制,第二名称节点要滞后主节点,所以当主名称节点挂掉以后,丢失数据是在所难免的;所以snn(secondary name node)保存镜像副本的主要作用是尽可能的减少数据的丢失;MapReduce是一个计算框架,这种计算框架主要有两个阶段,第一阶段是map计算;第二阶段是Reduce计算;map计算的作用是把相同key的数据始终发送给同一个mapper进行计算;reduce就是把mapper计算的结果进行折叠计算(我们可以理解为合并),最终得到一个结果;在hadoop v1版本是这样的架构,v2就不是了,v2版本中把mapreduce框架拆分yarn框架和mapreduce,其计算任务可以跑在yarn框架上;所以hadoop v1核心就是hdfs+mapreduce两个集群;v2的架构就是hdfs+yarn+mapreduce;
HDFS架构
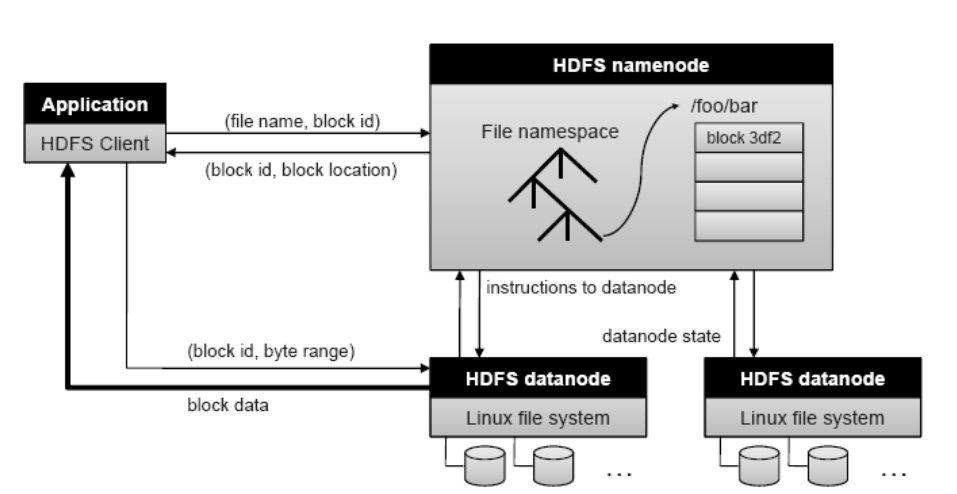
提示:从上图架构可以看到,客户端访问hdfs上的某一文件,首先要向namenode请求文件的元数据信息,然后nn就会告诉客户端,访问的文件在datanode上的位置,然后客户端再依次向datanode请求对应的数据,最后拼接成一个完整的文件;这里需要注意一个概念,datanode存放文件数据是按照文件大小和块大小来切分存放的,什么意思呢?比如一个文件100M大小,假设dn(datanode)上的块大小为10M一块,那么它存放在dn上是把100M切分为10M一块,共10块,然后把这10块数据分别存放在不同的dn上;同时这些块分别存放在不同的dn上,还会分别在不同的dn上存在副本,这样一来使得一个文件的数据块被多个dn分散冗余的存放;对于nn节点,它主要维护了那个文件的数据存放在那些节点,和那些dn存放了那些文件的数据块(这个数据是通过dn周期性的向nn发送);我们可以理解为nn内部有两张表分别记录了那些文件的数据块分别存放在那些dn上(以文件为中心),和那些dn存放了那些文件的数据块(以节点为中心);从上面的描述不难想象,当nn挂掉以后,整个存放在hdfs上的文件都将找不到,所以在生产中我们会使用zk(zookeeper)来对nn节点做高可用;对于hdfs来讲,它本质上不是内核文件系统,所以它依赖本地Linux文件系统;
mapreduce计算过程
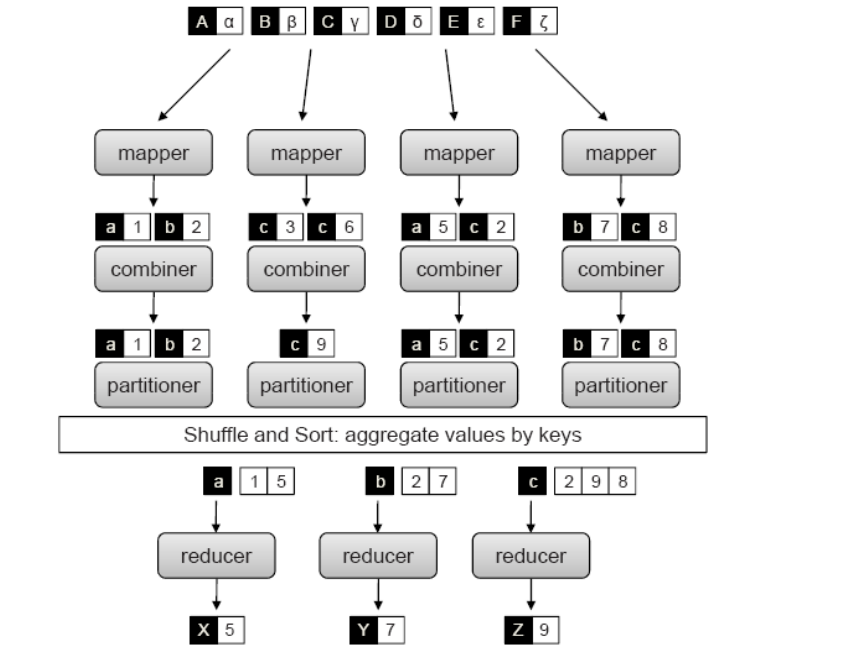
提示:如上图所示,首先mapreduce会把给定的数据切分为多个(切分之前通过程序员写程序实现把给定的数据切分为多分,并抽取成kv键值对),然后启动多个mapper对其进行map计算,多个mapper计算后的结果在通过combiner进行合并(combiner是有程序员编写程序实现,主要实现合并规则),把相同key的值根据某种计算规则合并在一起,然后把结果在通过partitoner(分区器,这个分区器是通过程序员写程序实现,主要实现对map后的结果和对应reducer进行关联)分别发送给不同的reducer进行计算,最终每个reducer会产生一个最终的唯一结果;简单讲mapper的作用是读入kv键值对,输出新的kv键值对,会有新的kv产生;combiner的作用是把当前mapper生成的新kv键值对进行相同key的键值对进行合并,至于怎么合并,合并规则是什么是由程序员定义,所以combiner就是程序员写的程序实现,本质上combiner是读入kv键值对,输出kv键值对,不会产生新的kv;partitioner的作用就是把combiner合并后的键值对进行调度至reducer,至于怎么调度,该发往那个reducer,以及由几个reducer进行处理,由程序员定义;最终reducer折叠计算以后生成新的kv键值对;
hadoop v1与v2架构
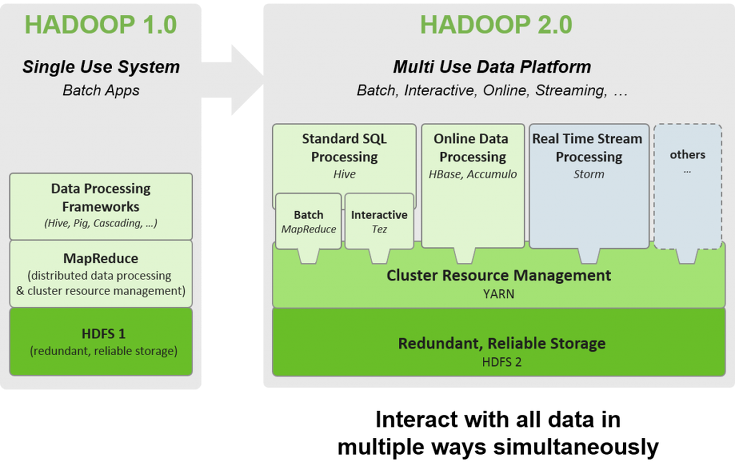
提示:在hadoop v1的架构中,所有计算任务都跑在mapreduce之上,mapreduce就主要担任了两个角色,第一个是集群资源管理器和数据处理;到了hadoop v2 其架构就为hdfs+yarn+一堆任务,其实我们可以把一堆任务理解为v1中的mapreduce,不同于v1中的mapreduce,v2中mapreduce只负责数据计算,不在负责集群资源管理,集群资源管理由yarn实现;对于v2来讲其计算任务都跑在了执yarn之上;对于hdfs来讲,v1和v2中的作用都是一样的,都是起存储文件作用;
hadoop v2 计算任务资源调度过程
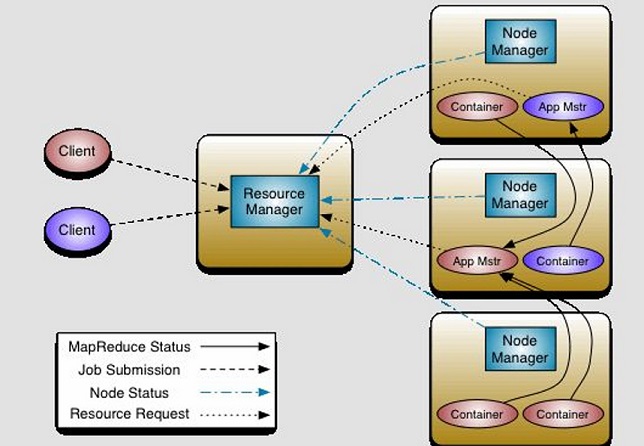
提示:rm(resource manager)收到客户端的任务请求,此时rm会根据各dn上运行的nm(node manager)周期性报告的状态信息来决定把客户端的任务调度给那个nm来执行;当rm选定好nm后,就把任务发送给对应nm,对应nm内部会起一个appmaster(am)的容器,负责本次任务的主控端,而appmaster需要启动container来运行任务,它会向rm请求,然后rm会根据am的请求在对应的nm上启动一个或多个container;最后各container运行后的结果会发送给am,然后再由am返回给rm,rm再返回给客户端;在这其中rm主要用来接收个nm发送的各节点状态信息和资源调度以及接收各am计算任务后的结果并反馈给各客户端;nm主要用来管理各node上的资源和上报状态信息给rm;am主要用来管理各任务的资源申请和各任务执行后端结果返回给rm;
hadoop生态圈
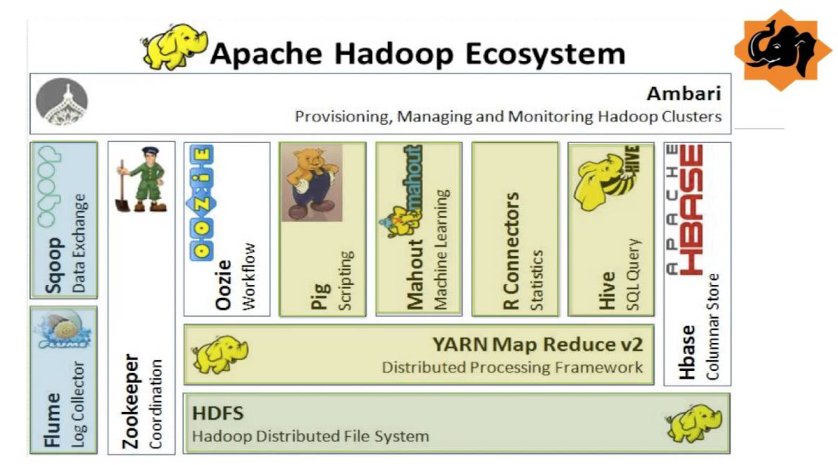
提示:上图是hadoop v2生态圈架构图,其中hdfs和yarn是hadoop的核心组件,对于运行在其上的各种任务都必须依赖hadoop,也必须支持调用mapreduce接口;
二、hadoop集群部署
环境说明
| 名称 | 角色 | ip |
| node01 | nn,snn,rm | 192.168.0.41 |
| node02 | dn,nm | 192.168.0.42 |
| node03 | dn,nm | 192.168.0.43 |
| node04 | dn,nm | 192.168.0.44 |
各节点同步时间

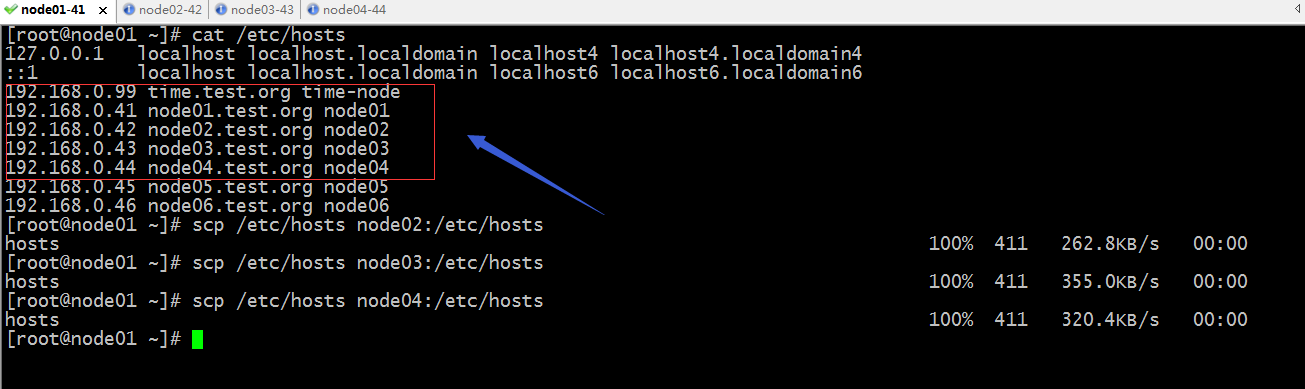
配置/etc/hosts解析个节点主机名
各节点安装jdk
yum install -y java-1.8.0-openjdk-devel
提示:安装devel包才会有jps命令
验证jdk是否安装完成,版本是否正确,确定java命令所在位置

添加JAVA_HOME环境变量

验证JAVA_HOME变量配置是否正确

创建目录,用于存放hadoop安装包
mkdir /bigdata
到此基础环境就准备OK,接下来下载hadoop二进制包
[root@node01 ~]# wget //mirror.bit.edu.cn/apache/hadoop/common/hadoop-2.9.2/hadoop-2.9.2.tar.gz --2020-09-27 22:50:16-- //mirror.bit.edu.cn/apache/hadoop/common/hadoop-2.9.2/hadoop-2.9.2.tar.gz Resolving mirror.bit.edu.cn (mirror.bit.edu.cn)... 202.204.80.77, 219.143.204.117, 2001:da8:204:1205::22 Connecting to mirror.bit.edu.cn (mirror.bit.edu.cn)|202.204.80.77|:443... connected. HTTP request sent, awaiting response... 200 OK Length: 366447449 (349M) [application/octet-stream] Saving to: ‘hadoop-2.9.2.tar.gz’ 100%[============================================================================>] 366,447,449 1.44MB/s in 2m 19s 2020-09-27 22:52:35 (2.51 MB/s) - ‘hadoop-2.9.2.tar.gz’ saved [366447449/366447449] [root@node01 ~]# ls hadoop-2.9.2.tar.gz [root@node01 ~]#
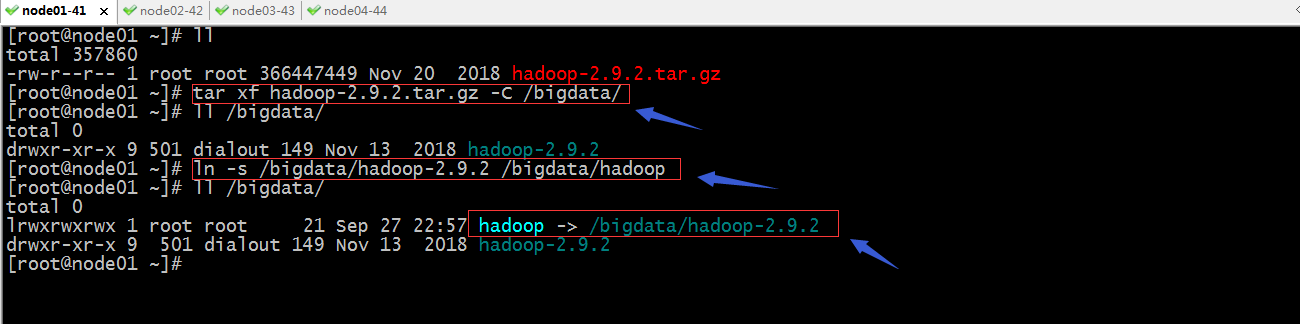
解压hadoop-2.9.3.tar.gz到/bigdata/目录,并将解压到目录链接至hadoop
导出hadoop环境变量配置
[root@node01 ~]# cat /etc/profile.d/hadoop.sh
export HADOOP_HOME=/bigdata/hadoop
export PATH=$PATH:${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin
export HADOOP_YARN_HOME=${HADOOP_HOME}
export HADOOP_MAPPERD_HOME=${HADOOP_HOME}
export HADOOP_COMMON_HOME=${HADOOP_HOME}
export HADOOP_HDFS_HOME=${HADOOP_HOME}
[root@node01 ~]#
创建hadoop用户,并设置其密码为admin
[root@node01 ~]# useradd hadoop [root@node01 ~]# echo "admin" |passwd --stdin hadoop Changing password for user hadoop. passwd: all authentication tokens updated successfully. [root@node01 ~]#
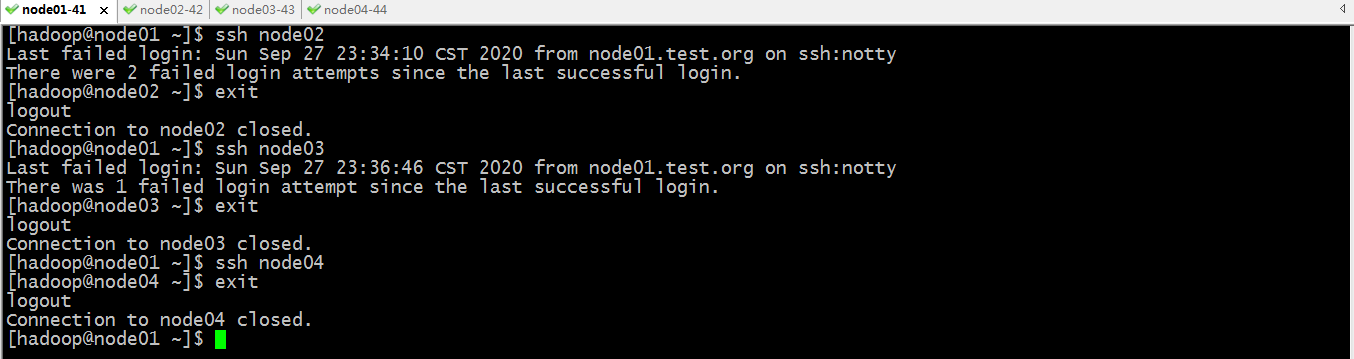
各节点间hadoop用户做免密登录
[hadoop@node01 ~]$ ssh-keygen Generating public/private rsa key pair. Enter file in which to save the key (/home/hadoop/.ssh/id_rsa): Created directory '/home/hadoop/.ssh'. Enter passphrase (empty for no passphrase): Enter same passphrase again: Your identification has been saved in /home/hadoop/.ssh/id_rsa. Your public key has been saved in /home/hadoop/.ssh/id_rsa.pub. The key fingerprint is: SHA256:6CNhqdagySJXc4iRBVSoLENddO7JLZMCsdjQzqSFnmw [email protected] The key's randomart image is: +---[RSA 2048]----+ | o*==o . | | o=Bo o | |=oX+ . | |+E =.oo.+ | |o.o B.oBS. | |.o * =. o | |=.+ o o | |oo . . | | | +----[SHA256]-----+ [hadoop@node01 ~]$ ssh-copy-id node01 /usr/bin/ssh-copy-id: INFO: Source of key(s) to be installed: "/home/hadoop/.ssh/id_rsa.pub" The authenticity of host 'node01 (192.168.0.41)' can't be established. ECDSA key fingerprint is SHA256:lE8/Vyni4z8hsXaa8OMMlDpu3yOIRh6dLcIr+oE57oE. ECDSA key fingerprint is MD5:14:59:02:30:c0:16:b8:6c:1a:84:c3:0f:a7:ac:67:b3. Are you sure you want to continue connecting (yes/no)? yes /usr/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed /usr/bin/ssh-copy-id: INFO: 1 key(s) remain to be installed -- if you are prompted now it is to install the new keys hadoop@node01's password: Number of key(s) added: 1 Now try logging into the machine, with: "ssh 'node01'" and check to make sure that only the key(s) you wanted were added. [hadoop@node01 ~]$ scp -r ./.ssh node02:/home/hadoop/ The authenticity of host 'node02 (192.168.0.42)' can't be established. ECDSA key fingerprint is SHA256:lE8/Vyni4z8hsXaa8OMMlDpu3yOIRh6dLcIr+oE57oE. ECDSA key fingerprint is MD5:14:59:02:30:c0:16:b8:6c:1a:84:c3:0f:a7:ac:67:b3. Are you sure you want to continue connecting (yes/no)? yes Warning: Permanently added 'node02,192.168.0.42' (ECDSA) to the list of known hosts. hadoop@node02's password: id_rsa 100% 1679 636.9KB/s 00:00 id_rsa.pub 100% 404 186.3KB/s 00:00 known_hosts 100% 362 153.4KB/s 00:00 authorized_keys 100% 404 203.9KB/s 00:00 [hadoop@node01 ~]$ scp -r ./.ssh node03:/home/hadoop/ The authenticity of host 'node03 (192.168.0.43)' can't be established. ECDSA key fingerprint is SHA256:lE8/Vyni4z8hsXaa8OMMlDpu3yOIRh6dLcIr+oE57oE. ECDSA key fingerprint is MD5:14:59:02:30:c0:16:b8:6c:1a:84:c3:0f:a7:ac:67:b3. Are you sure you want to continue connecting (yes/no)? yes Warning: Permanently added 'node03,192.168.0.43' (ECDSA) to the list of known hosts. hadoop@node03's password: id_rsa 100% 1679 755.1KB/s 00:00 id_rsa.pub 100% 404 165.7KB/s 00:00 known_hosts 100% 543 350.9KB/s 00:00 authorized_keys 100% 404 330.0KB/s 00:00 [hadoop@node01 ~]$ scp -r ./.ssh node04:/home/hadoop/ The authenticity of host 'node04 (192.168.0.44)' can't be established. ECDSA key fingerprint is SHA256:lE8/Vyni4z8hsXaa8OMMlDpu3yOIRh6dLcIr+oE57oE. ECDSA key fingerprint is MD5:14:59:02:30:c0:16:b8:6c:1a:84:c3:0f:a7:ac:67:b3. Are you sure you want to continue connecting (yes/no)? yes Warning: Permanently added 'node04,192.168.0.44' (ECDSA) to the list of known hosts. hadoop@node04's password: id_rsa 100% 1679 707.0KB/s 00:00 id_rsa.pub 100% 404 172.8KB/s 00:00 known_hosts 100% 724 437.7KB/s 00:00 authorized_keys 100% 404 165.2KB/s 00:00 [hadoop@node01 ~]$
验证:用node01去连接node02,node03,node04看看是否是免密登录了
创建数据目录/data/hadoop/hdfs/{nn,snn,dn},并将其属主属组更改为hadoop

进入到hadoop安装目录,创建其logs目录,并将其安装目录的属主和属组更改为hadoop
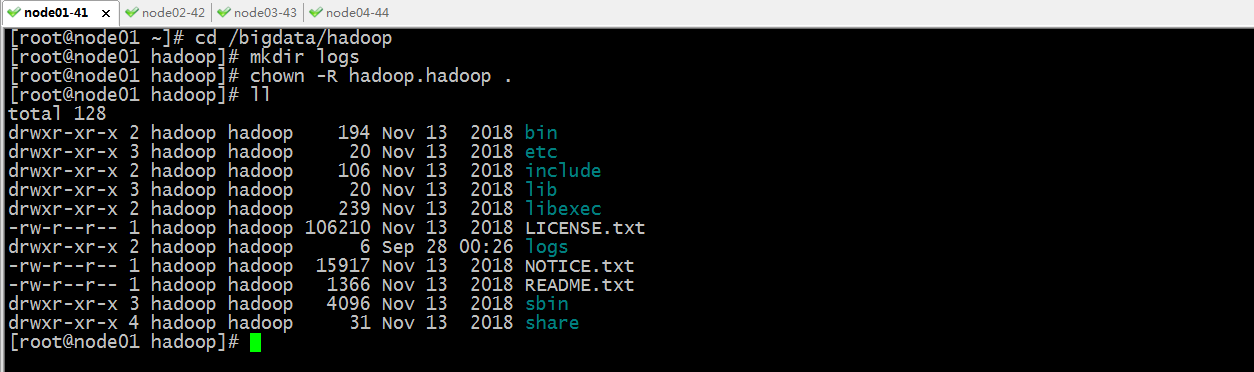
提示:以上所有步骤都需要在各节点挨着做一遍;
配置hadoop的core-site.xml
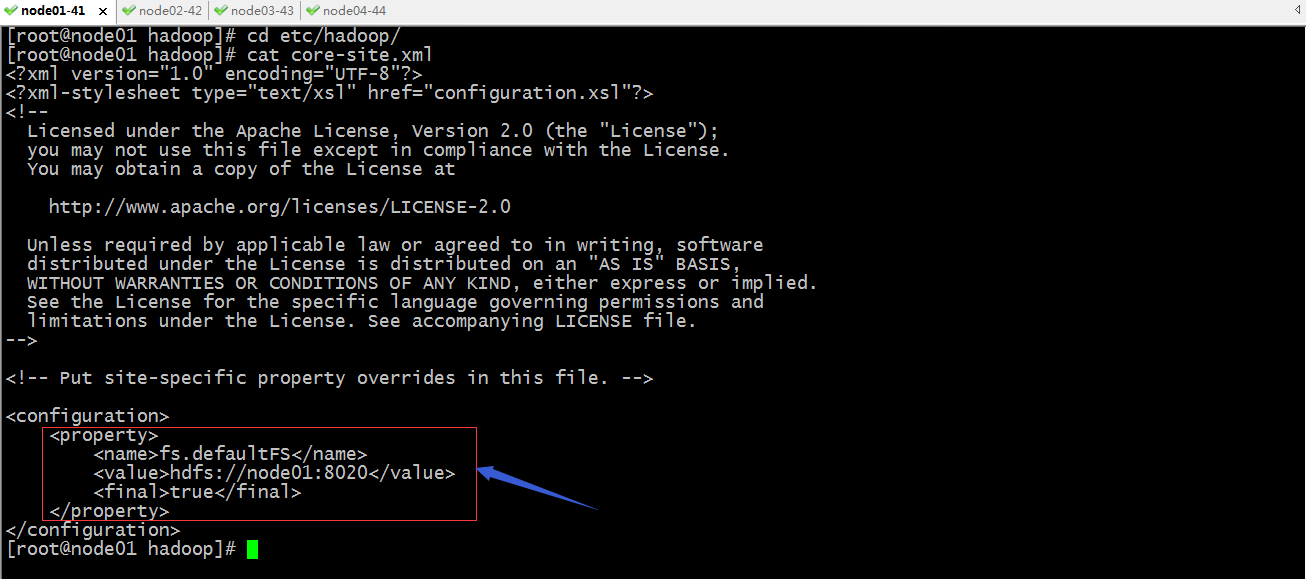
提示:hadoop的配置文件语法都是xml格式的配置文件,其中<property>和</property>是一对标签,里面用name标签来引用配置的选项的key的名称,其value标签用来配置对应key的值;上面配置表示配置默认的文件系统地址;hdfs://node01:8020是hdfs文件系统访问的地址;
完整的配置


[root@node01 hadoop]# cat core-site.xml <?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <!-- Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. See accompanying LICENSE file. --> <!-- Put site-specific property overrides in this file. --> <configuration> <property> <name>fs.defaultFS</name> <value>hdfs://node01:8020</value> <final>true</final> </property> </configuration> [root@node01 hadoop]#
View Code
配置hdfs-site.xml
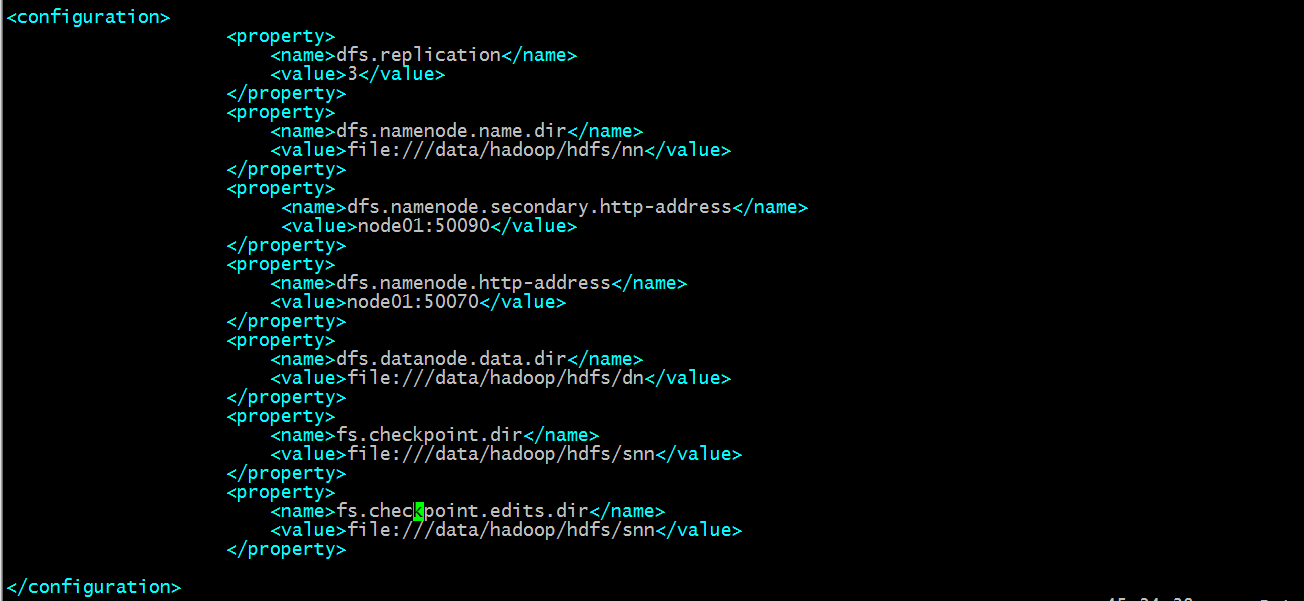
提示:以上配置主要指定hdfs相关目录以及访问web端口信息,副本数量;
完整的配置
[root@node01 hadoop]# cat hdfs-site.xml <?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <!-- Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. See accompanying LICENSE file. --> <!-- Put site-specific property overrides in this file. --> <configuration> <property> <name>dfs.replication</name> <value>3</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>file:///data/hadoop/hdfs/nn</value> </property> <property> <name>dfs.namenode.secondary.http-address</name> <value>node01:50090</value> </property> <property> <name>dfs.namenode.http-address</name> <value>node01:50070</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>file:///data/hadoop/hdfs/dn</value> </property> <property> <name>fs.checkpoint.dir</name> <value>file:///data/hadoop/hdfs/snn</value> </property> <property> <name>fs.checkpoint.edits.dir</name> <value>file:///data/hadoop/hdfs/snn</value> </property> </configuration> [root@node01 hadoop]#
View Code
配置mapred-site.xml
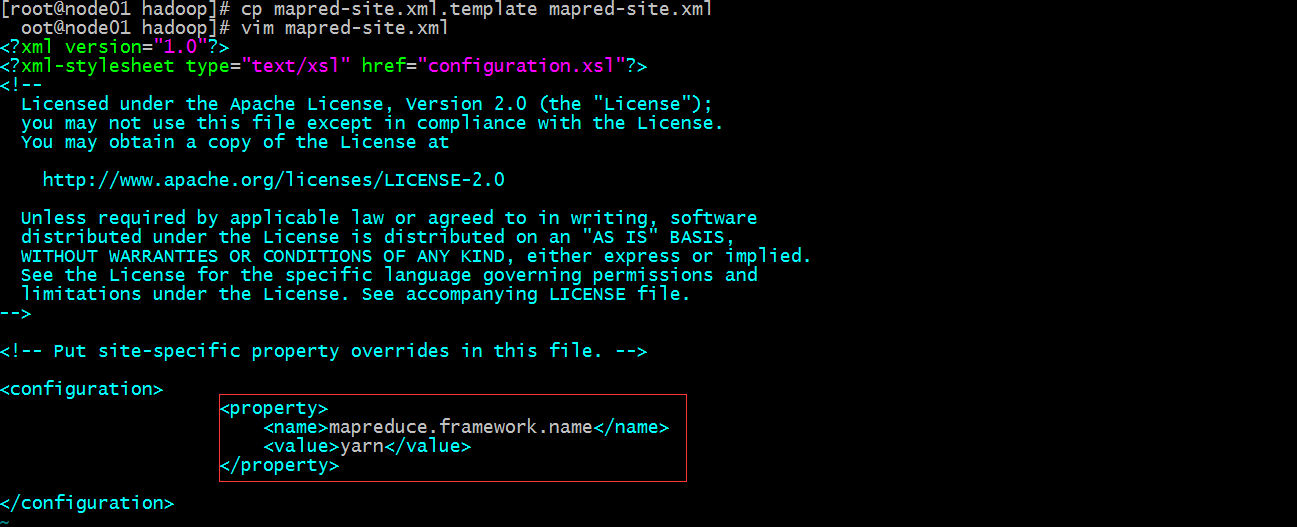
提示:以上配置主要指定了mapreduce的框架为yarn;默认没有mapred-site.xml,我们需要将mapred-site.xml.template修改成mapred.site.xml;这里需要注意我上面是通过复制修改文件名,当然属主信息都会变成root,不要忘记把属组信息修改成hadoop;
完整的配置
[root@node01 hadoop]# cat mapred-site.xml <?xml version="1.0"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <!-- Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. See accompanying LICENSE file. --> <!-- Put site-specific property overrides in this file. --> <configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration> [root@node01 hadoop]#
View Code
配置yarn-site.xml
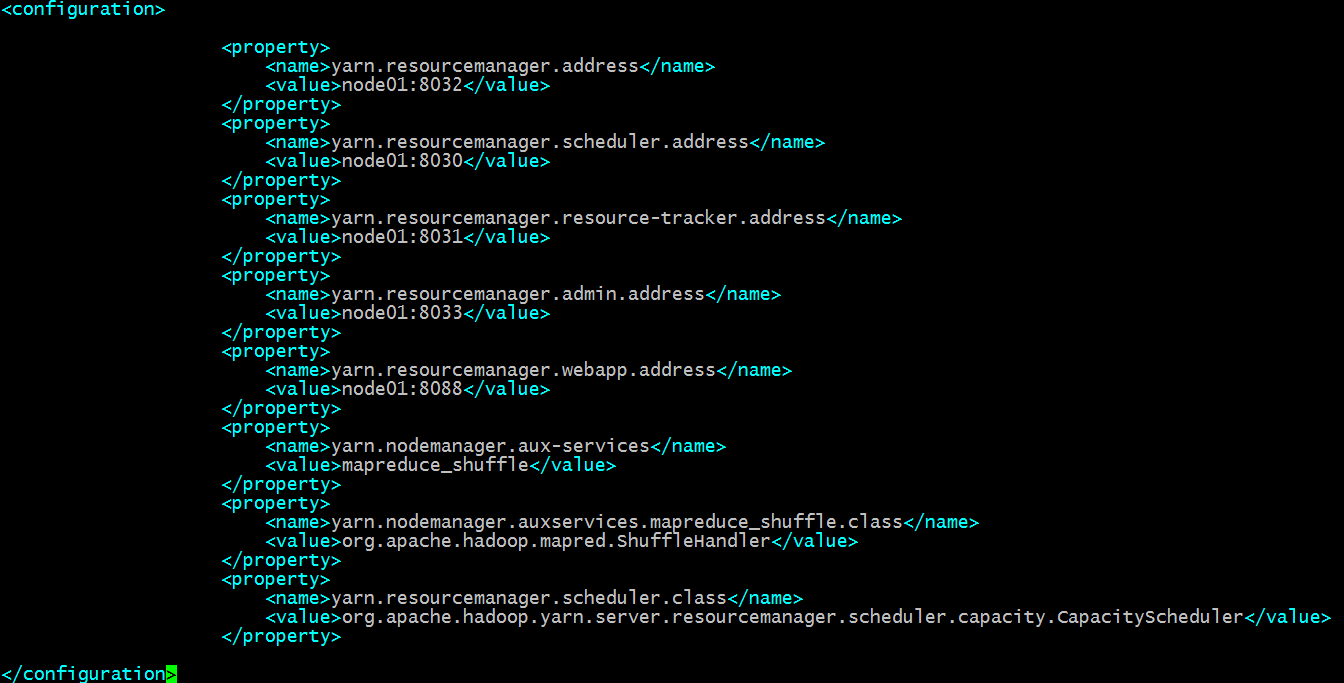
提示:以上配置主要配置了yarn框架rm和nm相关地址和指定相关类;
完整的配置
[root@node01 hadoop]# cat yarn-site.xml <?xml version="1.0"?> <!-- Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. See accompanying LICENSE file. --> <configuration> <property> <name>yarn.resourcemanager.address</name> <value>node01:8032</value> </property> <property> <name>yarn.resourcemanager.scheduler.address</name> <value>node01:8030</value> </property> <property> <name>yarn.resourcemanager.resource-tracker.address</name> <value>node01:8031</value> </property> <property> <name>yarn.resourcemanager.admin.address</name> <value>node01:8033</value> </property> <property> <name>yarn.resourcemanager.webapp.address</name> <value>node01:8088</value> </property> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.nodemanager.auxservices.mapreduce_shuffle.class</name> <value>org.apache.hadoop.mapred.ShuffleHandler</value> </property> <property> <name>yarn.resourcemanager.scheduler.class</name> <value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.CapacityScheduler</value> </property> </configuration> [root@node01 hadoop]#
View Code
配置slave.xml
[root@node01 hadoop]# cat slaves node02 node03 node04 [root@node01 hadoop]#
复制各配置文件到其他节点
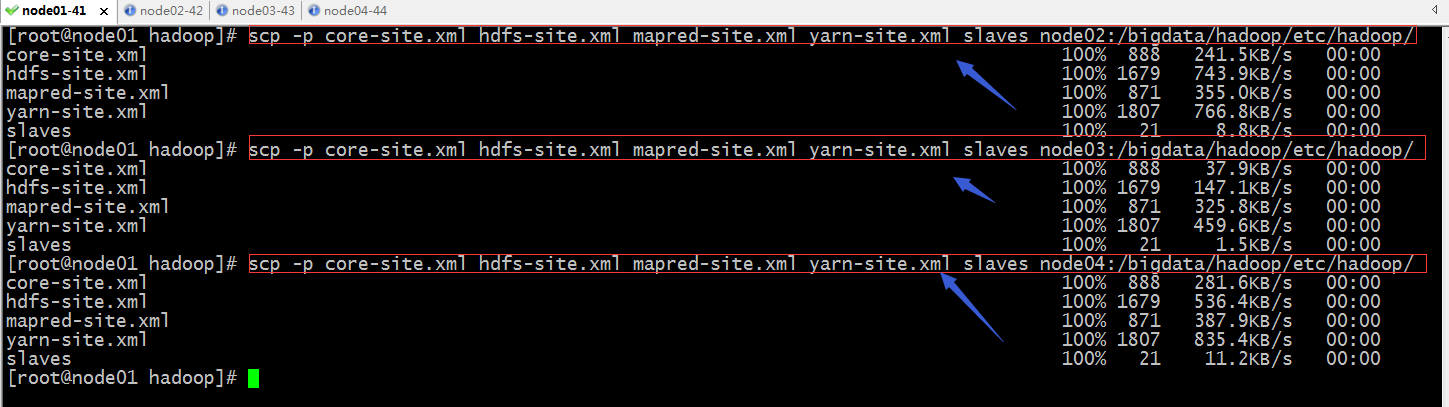
到此hadoop配置就完成了;
接下来切换到hadoop用户下,初始化hdfs
hdfs namenode -format
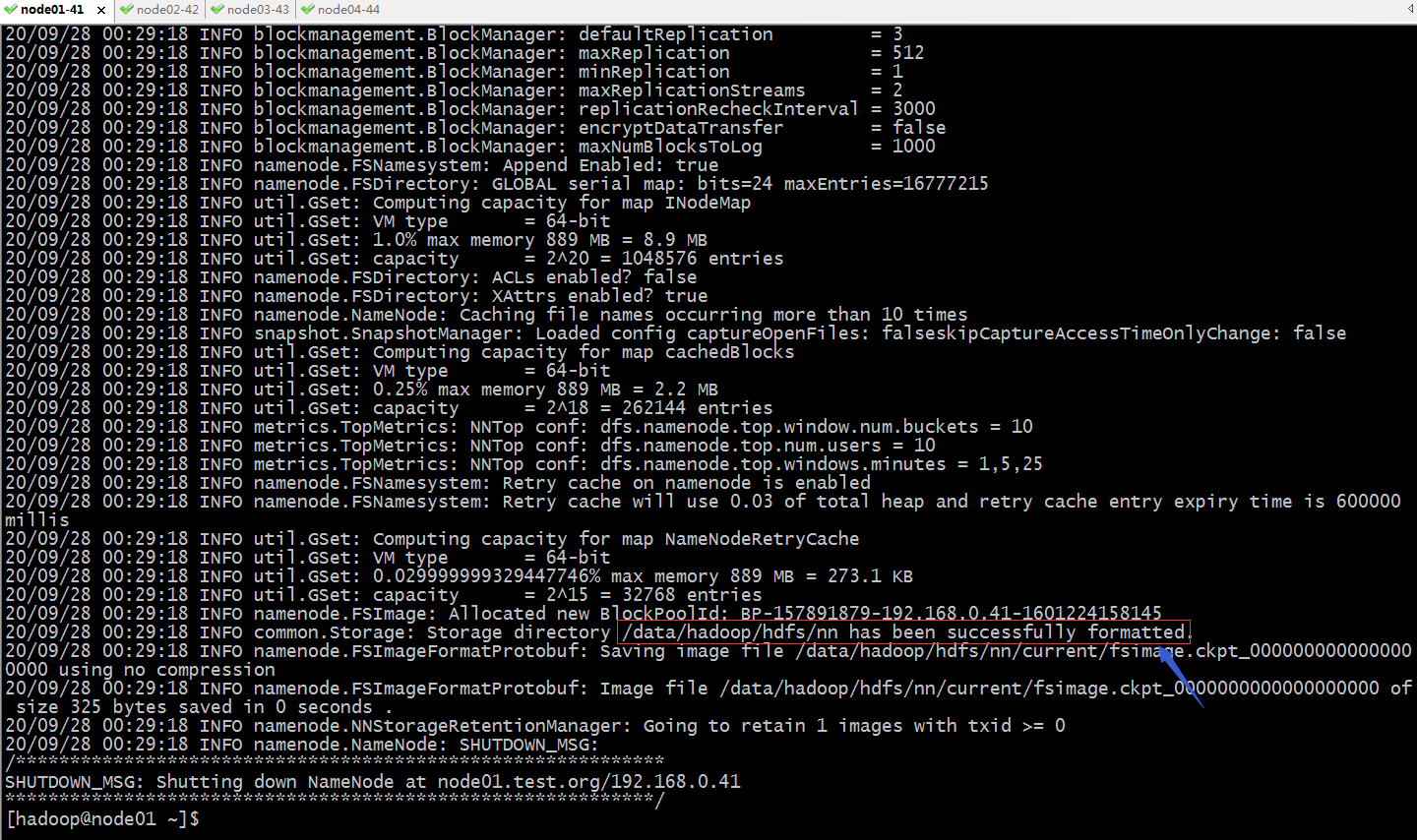
提示:如果执行hdfs namenode -format 出现红框中的提示,说明hdfs格式化就成功了;
启动hdfs集群
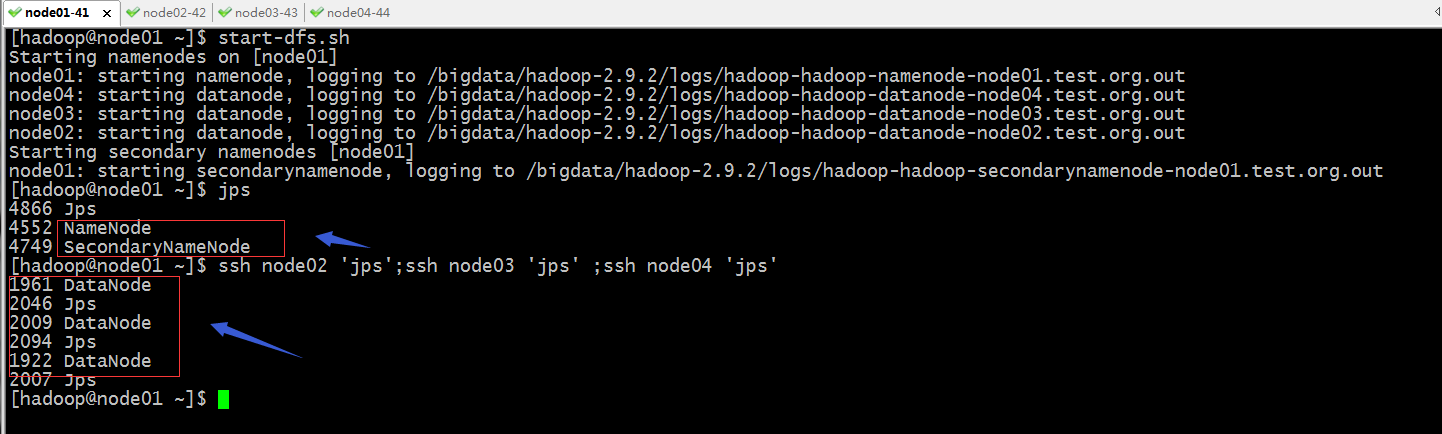
提示:hdfs主要由namenode、secondarynamenode和datanode组成,只要看到对应节点上的进程启动起来,就没有多大问题;
到此hdfs集群就正常启动了
验证:把/etc/passwd上传到hdfs的/test目录下,看看是否可以正常上传?

提示:可以看到/etc/passwd文件已经上传至hdfs的/test目录下了;
验证:查看hdfs /test目录下passwd文件,看看是否同/etc/passwd文件内容相同?
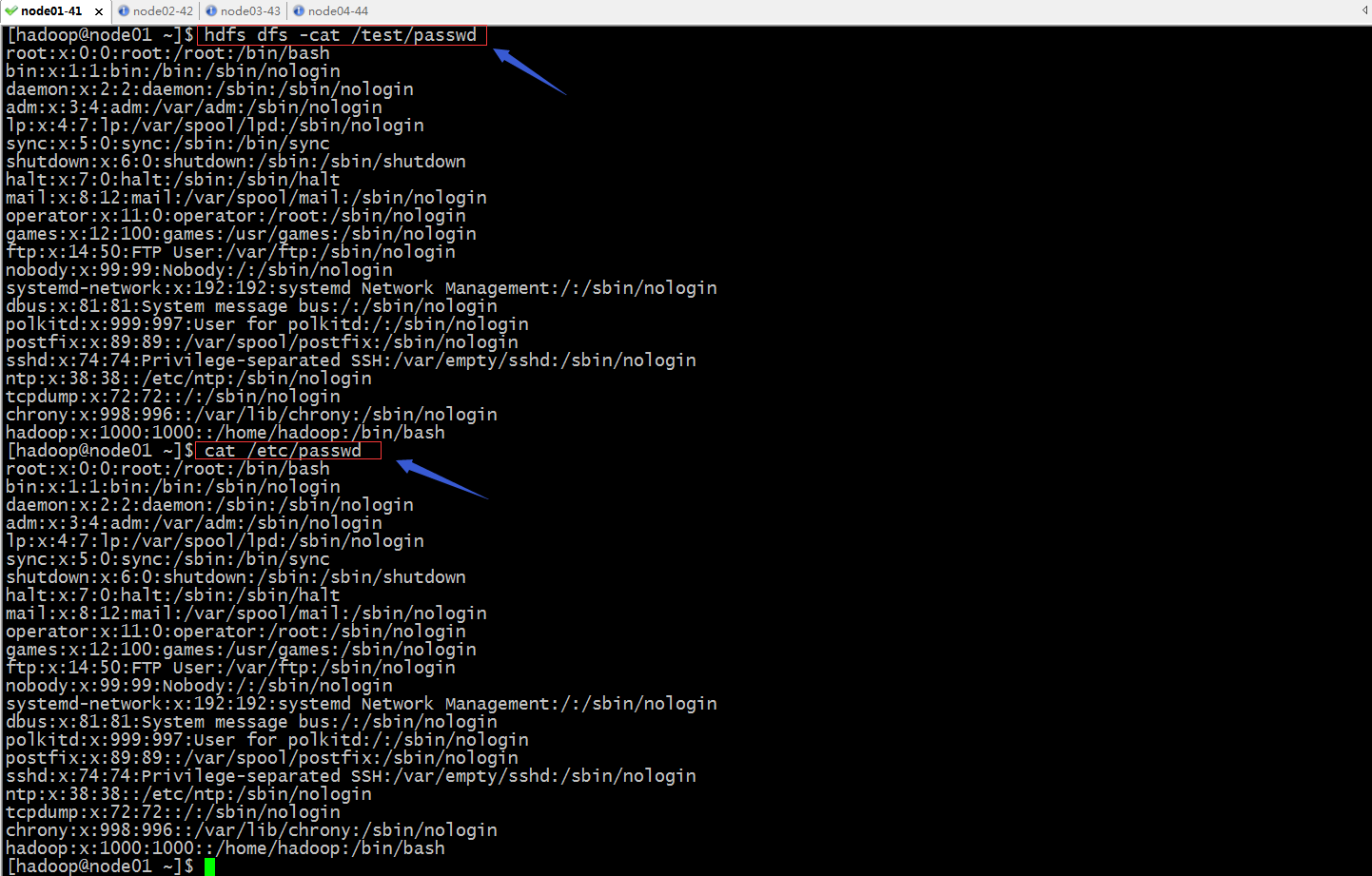
提示:可以看到hdfs上的/test/passwd文件内容同/etc/passwd文件内容相同;
验证:在dn节点查看对应目录下的文件内容,看看是否同/etc/passwd文件内容相同?
[root@node02 ~]# tree /data
/data
└── hadoop
└── hdfs
├── dn
│ ├── current
│ │ ├── BP-157891879-192.168.0.41-1601224158145
│ │ │ ├── current
│ │ │ │ ├── finalized
│ │ │ │ │ └── subdir0
│ │ │ │ │ └── subdir0
│ │ │ │ │ ├── blk_1073741825
│ │ │ │ │ └── blk_1073741825_1001.meta
│ │ │ │ ├── rbw
│ │ │ │ └── VERSION
│ │ │ ├── scanner.cursor
│ │ │ └── tmp
│ │ └── VERSION
│ └── in_use.lock
├── nn
└── snn
13 directories, 6 files
[root@node02 ~]# cat /data/hadoop/hdfs/dn/current/BP-157891879-192.168.0.41-1601224158145/
current/ scanner.cursor tmp/
[root@node02 ~]# cat /data/hadoop/hdfs/dn/current/BP-157891879-192.168.0.41-1601224158145/current/finalized/subdir0/subdir0/blk_1073741825
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
sync:x:5:0:sync:/sbin:/bin/sync
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
halt:x:7:0:halt:/sbin:/sbin/halt
mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
operator:x:11:0:operator:/root:/sbin/nologin
games:x:12:100:games:/usr/games:/sbin/nologin
ftp:x:14:50:FTP User:/var/ftp:/sbin/nologin
nobody:x:99:99:Nobody:/:/sbin/nologin
systemd-network:x:192:192:systemd Network Management:/:/sbin/nologin
dbus:x:81:81:System message bus:/:/sbin/nologin
polkitd:x:999:997:User for polkitd:/:/sbin/nologin
postfix:x:89:89::/var/spool/postfix:/sbin/nologin
sshd:x:74:74:Privilege-separated SSH:/var/empty/sshd:/sbin/nologin
ntp:x:38:38::/etc/ntp:/sbin/nologin
tcpdump:x:72:72::/:/sbin/nologin
chrony:x:998:996::/var/lib/chrony:/sbin/nologin
hadoop:x:1000:1000::/home/hadoop:/bin/bash
[root@node02 ~]#
提示:可以看到在dn节点上的dn目录下能够找到我们上传的passwd文件;
验证:查看其它节点是否有相同的文件?是否有我们指定数量的副本?

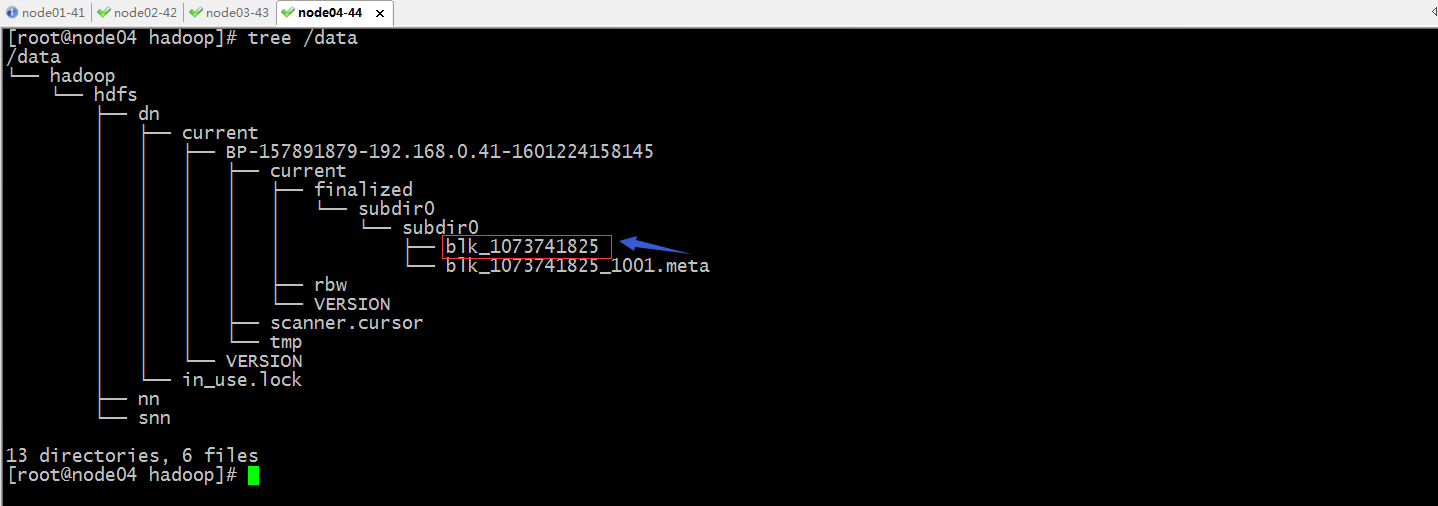
提示:在node03和node04上也有相同的目录和文件;说明我们设置的副本数量为3生效了;
启动yarn集群
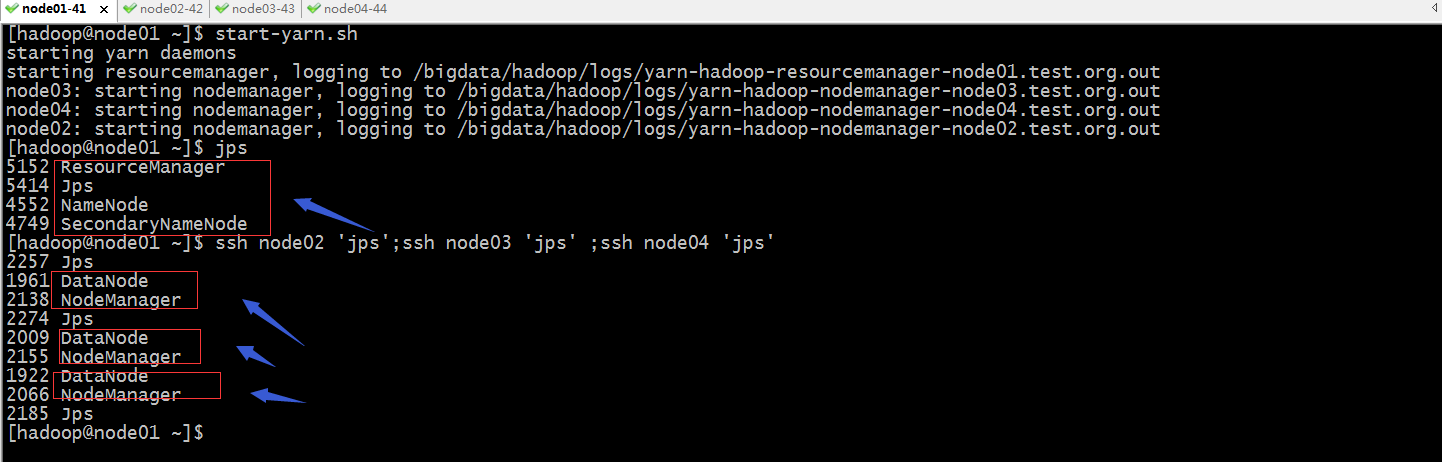
提示:可以看到对应节点上的nm启动了;主节点上的rm也正常启动了;
访问nn的50070和8088,看看对应的web地址是否能够访问到页面?
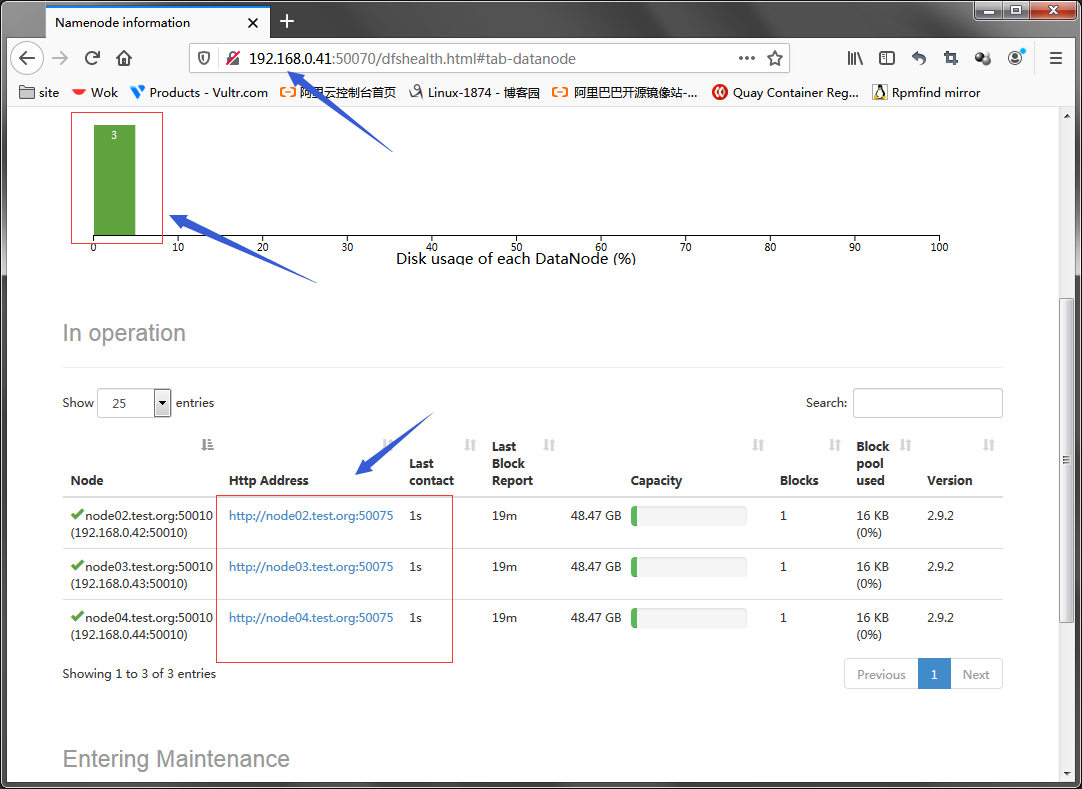
提示:这个地址是hdfs的web地址,在这个界面可以看到hdfs的存储状况,以及对hdfs上的文件做操作;
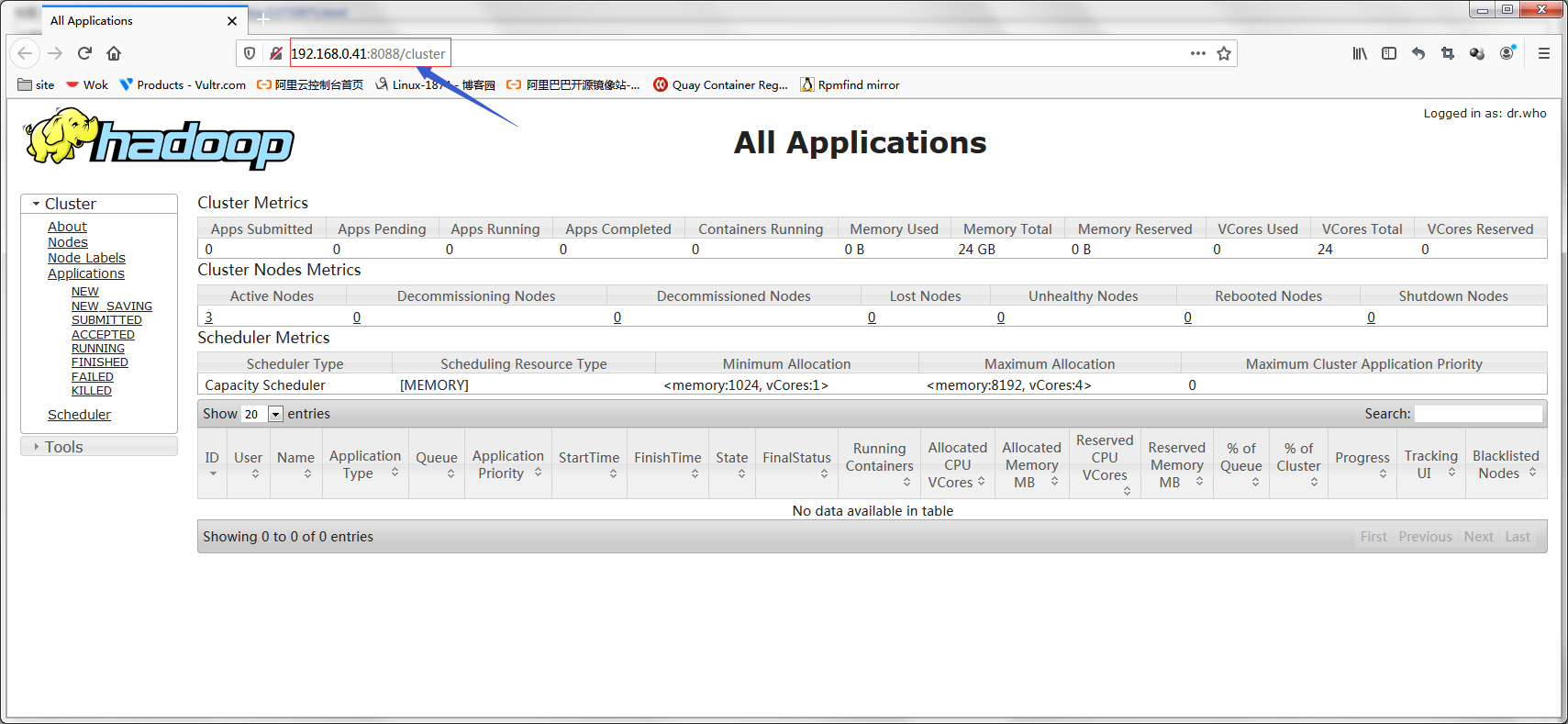
提示:8088是yarn集群的管理地址;在这个界面上能够看到运行的计算任务的状态信息,集群配置信息,日志等等;
验证:在yarn上跑一个计算任务,统计/test/passwd文件的单词数量,看看对应的计算任务是否能够跑起来?
[hadoop@node01 hadoop]$ yarn jar /bigdata/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.9.2.jar
An example program must be given as the first argument.
Valid program names are:
aggregatewordcount: An Aggregate based map/reduce program that counts the words in the input files.
aggregatewordhist: An Aggregate based map/reduce program that computes the histogram of the words in the input files.
bbp: A map/reduce program that uses Bailey-Borwein-Plouffe to compute exact digits of Pi.
dbcount: An example job that count the pageview counts from a database.
distbbp: A map/reduce program that uses a BBP-type formula to compute exact bits of Pi.
grep: A map/reduce program that counts the matches of a regex in the input.
join: A job that effects a join over sorted, equally partitioned datasets
multifilewc: A job that counts words from several files.
pentomino: A map/reduce tile laying program to find solutions to pentomino problems.
pi: A map/reduce program that estimates Pi using a quasi-Monte Carlo method.
randomtextwriter: A map/reduce program that writes 10GB of random textual data per node.
randomwriter: A map/reduce program that writes 10GB of random data per node.
secondarysort: An example defining a secondary sort to the reduce.
sort: A map/reduce program that sorts the data written by the random writer.
sudoku: A sudoku solver.
teragen: Generate data for the terasort
terasort: Run the terasort
teravalidate: Checking results of terasort
wordcount: A map/reduce program that counts the words in the input files.
wordmean: A map/reduce program that counts the average length of the words in the input files.
wordmedian: A map/reduce program that counts the median length of the words in the input files.
wordstandarddeviation: A map/reduce program that counts the standard deviation of the length of the words in the input files.
[hadoop@node01 hadoop]$ yarn jar /bigdata/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.9.2.jar wordcount
Usage: wordcount <in> [<in>...] <out>
[hadoop@node01 hadoop]$ yarn jar /bigdata/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.9.2.jar wordcount /test/passwd /test/passwd-word-count20/09/28 00:58:01 INFO client.RMProxy: Connecting to ResourceManager at node01/192.168.0.41:8032
20/09/28 00:58:01 INFO input.FileInputFormat: Total input files to process : 1
20/09/28 00:58:01 INFO mapreduce.JobSubmitter: number of splits:1
20/09/28 00:58:01 INFO Configuration.deprecation: yarn.resourcemanager.system-metrics-publisher.enabled is deprecated. Instead, use yarn.system-metrics-publisher.enabled
20/09/28 00:58:01 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1601224871685_0001
20/09/28 00:58:02 INFO impl.YarnClientImpl: Submitted application application_1601224871685_0001
20/09/28 00:58:02 INFO mapreduce.Job: The url to track the job: //node01:8088/proxy/application_1601224871685_0001/
20/09/28 00:58:02 INFO mapreduce.Job: Running job: job_1601224871685_0001
20/09/28 00:58:08 INFO mapreduce.Job: Job job_1601224871685_0001 running in uber mode : false
20/09/28 00:58:08 INFO mapreduce.Job: map 0% reduce 0%
20/09/28 00:58:14 INFO mapreduce.Job: map 100% reduce 0%
20/09/28 00:58:20 INFO mapreduce.Job: map 100% reduce 100%
20/09/28 00:58:20 INFO mapreduce.Job: Job job_1601224871685_0001 completed successfully
20/09/28 00:58:20 INFO mapreduce.Job: Counters: 49
File System Counters
FILE: Number of bytes read=1144
FILE: Number of bytes written=399079
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=1053
HDFS: Number of bytes written=1018
HDFS: Number of read operations=6
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
Job Counters
Launched map tasks=1
Launched reduce tasks=1
Data-local map tasks=1
Total time spent by all maps in occupied slots (ms)=2753
Total time spent by all reduces in occupied slots (ms)=2779
Total time spent by all map tasks (ms)=2753
Total time spent by all reduce tasks (ms)=2779
Total vcore-milliseconds taken by all map tasks=2753
Total vcore-milliseconds taken by all reduce tasks=2779
Total megabyte-milliseconds taken by all map tasks=2819072
Total megabyte-milliseconds taken by all reduce tasks=2845696
Map-Reduce Framework
Map input records=22
Map output records=30
Map output bytes=1078
Map output materialized bytes=1144
Input split bytes=95
Combine input records=30
Combine output records=30
Reduce input groups=30
Reduce shuffle bytes=1144
Reduce input records=30
Reduce output records=30
Spilled Records=60
Shuffled Maps =1
Failed Shuffles=0
Merged Map outputs=1
GC time elapsed (ms)=87
CPU time spent (ms)=620
Physical memory (bytes) snapshot=444997632
Virtual memory (bytes) snapshot=4242403328
Total committed heap usage (bytes)=285212672
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=958
File Output Format Counters
Bytes Written=1018
[hadoop@node01 hadoop]$
查看计算后生成的报告
[hadoop@node01 hadoop]$ hdfs dfs -ls -R /test -rw-r--r-- 3 hadoop supergroup 958 2020-09-28 00:32 /test/passwd drwxr-xr-x - hadoop supergroup 0 2020-09-28 00:58 /test/passwd-word-count -rw-r--r-- 3 hadoop supergroup 0 2020-09-28 00:58 /test/passwd-word-count/_SUCCESS -rw-r--r-- 3 hadoop supergroup 1018 2020-09-28 00:58 /test/passwd-word-count/part-r-00000 [hadoop@node01 hadoop]$ hdfs dfs -cat /test/passwd-word-count/part-r-00000 Management:/:/sbin/nologin 1 Network 1 SSH:/var/empty/sshd:/sbin/nologin 1 User:/var/ftp:/sbin/nologin 1 adm:x:3:4:adm:/var/adm:/sbin/nologin 1 bin:x:1:1:bin:/bin:/sbin/nologin 1 bus:/:/sbin/nologin 1 chrony:x:998:996::/var/lib/chrony:/sbin/nologin 1 daemon:x:2:2:daemon:/sbin:/sbin/nologin 1 dbus:x:81:81:System 1 for 1 ftp:x:14:50:FTP 1 games:x:12:100:games:/usr/games:/sbin/nologin 1 hadoop:x:1000:1000::/home/hadoop:/bin/bash 1 halt:x:7:0:halt:/sbin:/sbin/halt 1 lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin 1 mail:x:8:12:mail:/var/spool/mail:/sbin/nologin 1 message 1 nobody:x:99:99:Nobody:/:/sbin/nologin 1 ntp:x:38:38::/etc/ntp:/sbin/nologin 1 operator:x:11:0:operator:/root:/sbin/nologin 1 polkitd:/:/sbin/nologin 1 polkitd:x:999:997:User 1 postfix:x:89:89::/var/spool/postfix:/sbin/nologin 1 root:x:0:0:root:/root:/bin/bash 1 shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown 1 sshd:x:74:74:Privilege-separated 1 sync:x:5:0:sync:/sbin:/bin/sync 1 systemd-network:x:192:192:systemd 1 tcpdump:x:72:72::/:/sbin/nologin 1 [hadoop@node01 hadoop]$
在8088页面上查看任务的状态信息
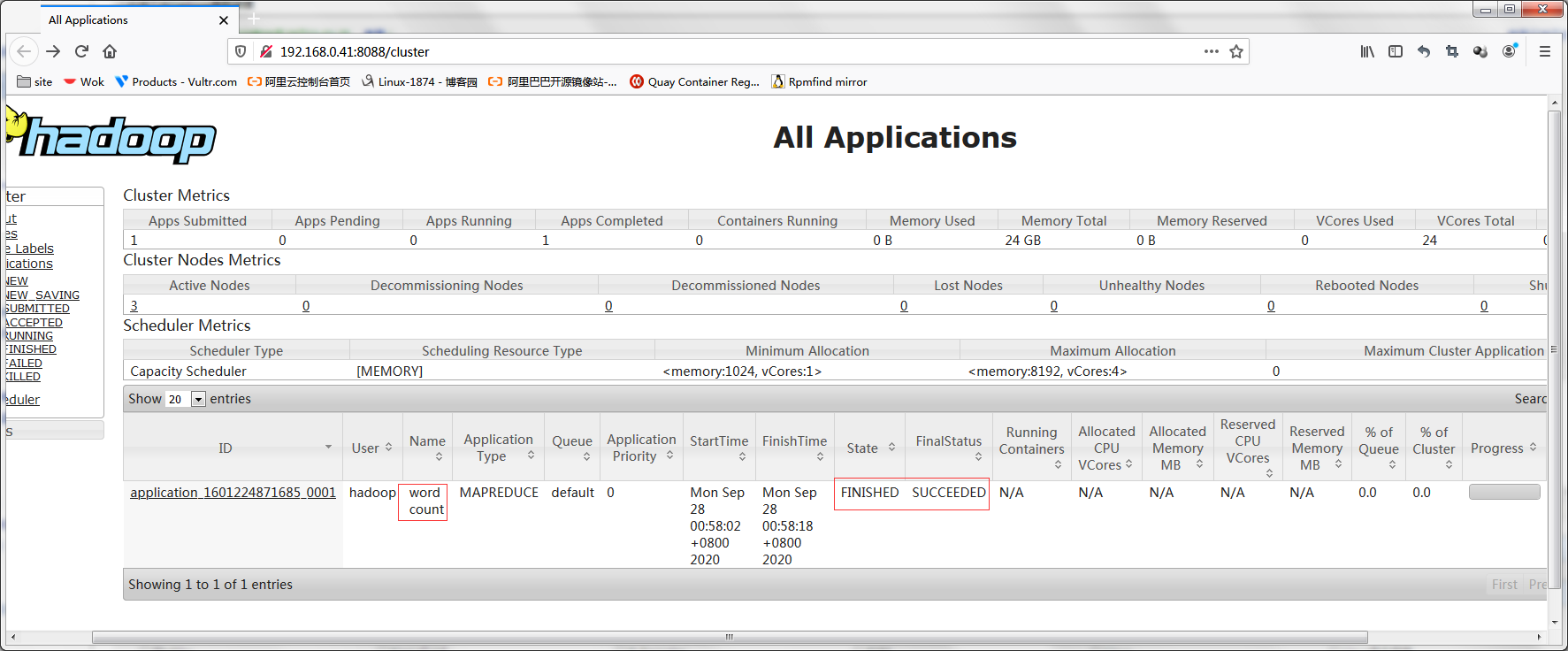
到此hadoop v2集群就搭建完毕了;

