ARM处理器、X86处理器和AI处理器的区别
- 2019 年 11 月 2 日
- 筆記
ARM处理器、X86处理器和AI处理器的区别
目前主要的处理器架构有:
- X86: Intel, AMD, 海光, 兆芯
- ARM: 华为,飞腾,华芯通,Cavium,Ampere,富士通,亚马逊
- POWER:IBM, 中晟宏芯
- MIPS:龙芯
- Alpha:申威
X86处理器
X86架构(The X86 architecture)是微处理器执行的计算机语言指令集,指一个intel通用计算机系列的标准编号缩写,也标识一套通用的计算机指令集合。

ARM处理器
ARM(Advanced RISC Machines)一个32位元精简指令集(RISC)处理器架构,ARM处理器广泛地使用在许多嵌入式系统设计。ARM处理器的特点有指令长度固定,执行效率高,低成本等。

ARM 架构是开放性的商业 IP 授权,x86 是封闭架构,美国 Intel 和 AMD 对知识产权处于垄断地位(PS:现在华为等国内公司研发多以ARM架构为主)
ARM 比 x86 架构的优势和劣势
- 1) 物理核心更多,适用于当前数据中心主流的分布式计算场景;例如大数据、分布式存储、HPC 等;
- 2) 能耗更能,节能环保;与同样性能的 x86 处理器相比,功耗低 20%以上;
- 1) 单核性能稍弱于 x86;
- 2) 相比于 Intel AVX512,向量指令运算能力偏弱,在 HPC 部分场景性能低于 x86;对通用场景无任何影响;
什么是异构?
- 1) 从计算单元角度来看,x86 处理器之外的计算单元,都可认为是异构单元,例如 GPU,FPGA 加速卡等;
- 2) 从软件系统集群角度来看,基于不同处理器的服务器可以认为是异构;例如基于 E5-2650v4 的大数据集群使用基于 Gold 5115 或者鲲鹏 916 的服务器来扩容,就属于扩容异构节点。
什么是众核?
AI处理器
所谓的AI芯片,一般是指针对AI算法的ASIC(专用芯片)。传统的CPU、GPU都可以拿来执行AI算法,但是速度慢,性能低,无法实际商用。
华为很早就开始布局AI芯片。2017年9月德国IFA电子消费展上,华为就率先推出了内置NPU(独立神经网络处理单元)的全球首款AI芯片麒麟970。
AI处理器的发展和设计目标
目前在图像识别、语音识别、自然语言处理等领域,精度最高的算法就是基于深度学习的,传统的机器学习的计算精度已经被超越,目前应用最广的算法,估计非深度学习莫属,而且,传统机器学习的计算量与 深度学习比起来少很多,所以,我讨论AI芯片时就针对计算量特别大的深度学习而言。毕竟,计算量小的算法,说实话,CPU已经很快了。而且,CPU适合执行调度复杂的算法,这一点是GPU与AI芯片都做不到的,所以他们三者只是针对不同的应用场景而已,都有各自的主场。
GPU本来是从CPU中分离出来专门处理图像计算的,也就是说,GPU是专门处理图像计算的。包括各种特效的显示。这也是GPU的天生的缺陷,GPU更加针对图像的渲染等计算算法。但是,这些算法,与深度学习的算法还是有比较大的区别,而我的回答里提到的AI芯片,比如TPU,这个是专门针对CNN等典型深度学习算法而开发的。另外,寒武纪的NPU,也是专门针对神经网络的,与TPU类似。
谷歌的TPU,寒武纪的DianNao,这些AI芯片刚出道的时候,就是用CPU/GPU来对比的。
AI芯片,比如大名鼎鼎的谷歌的TPU1。
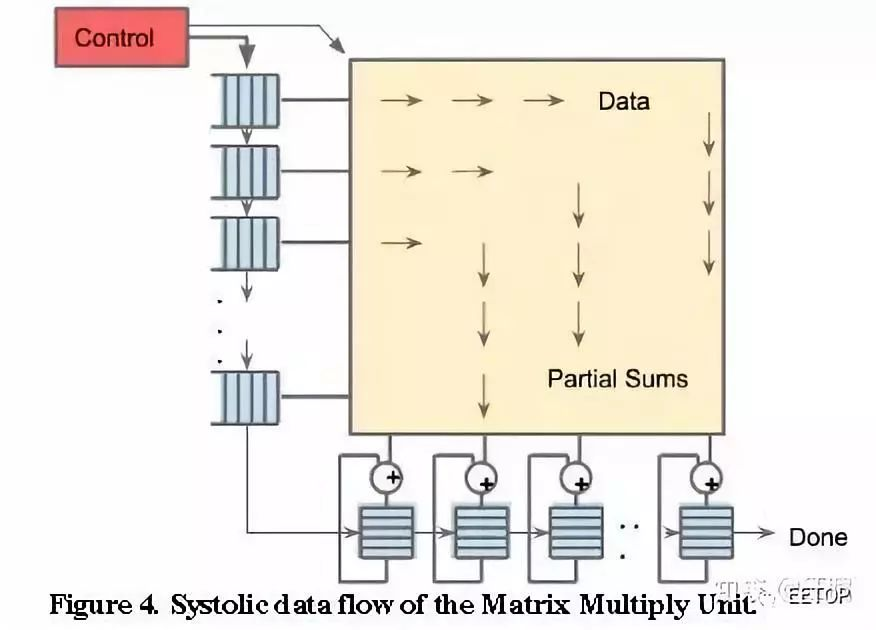
TPU1,大约700M Hz,有256X256尺寸的脉动阵列,如下图所示。一共256X256=64K个乘加单元,每个单元一次可执行一个乘法和一个加法。那就是128K个操作。(乘法算一个,加法再算一个)