大数据架构的简单概括
- 2019 年 10 月 3 日
- 筆記
一、大数据的发展史
2004年
Google前后发表三篇论文,也就是传说中的“三驾马车”
- 分页式文件系统GFS
- 大数据分布式计算框架MapReduce
- NoSQL数据库系统BigTable
2006年
Doug Cutting启动了一个赫赫有名的项目Hadoop,主要包括Hadoop分布式文件系统HDFS和大数据计算引擎MapReduce,分别实现了GFS和MapReduce其中两篇论文
2007年
HBase诞生,实现了Big Table最后一篇论文
2008年
出现 了Pig、Hive,支持使用SQL语法来进行大数据计算,极大的降低了Hadoopr的使用难度,数据分析师和工程师可以无门槛地舒不舒服和大数据进行数据分析和处理
2012年
Haddop将执行引擎和资源调度分离出来,成立了Yarn资源调度系统,这年Spark也开始崭露头角,逐步替代MapReduce在企业应用中的地位
…
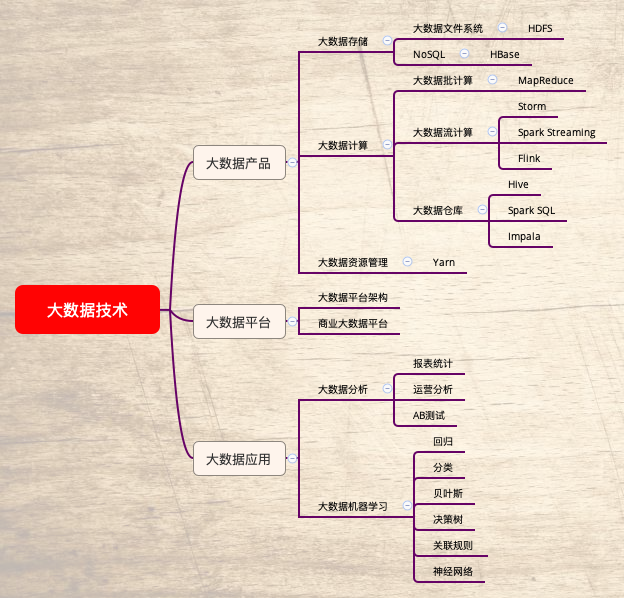
二、大数据架构
1. 数据分析与数据仓库
Hive、Spark SQL
2. 数据挖掘与机器学习
Mahout、MLib、TensorFlow
3. 批处理
MapReduce、Spark
4.NoSQL系统
HBase、Cassandra
5. 大数据存储
HDFS
三、大数据计算原理
- 在待处理的数据存储在服务器集群的所有服务器上,主要使用HDFS系统,将文件分成很多块(Block),以块为单位存储在集群的服务器上
- 大数据引擎根据集群里的不同服务器的计算能力,在每台服务器上启动若干分布式任务执行进程,这些进程会等待给它们分配执行任务
- 使用大数据计算框架支持的编程模型进行编程,比如Hadoop的MapReduce编程模型,或Spark的RDD编程模型,编写应用程序,例如python或java程序
- 用Haddop或Spark的启动命令执行这个应用程序,执行引擎会解析程序要处理的数据输入路径,根据输入数据量的大小,将数据分片,每个片分配给一个任务执行进程去处理
- 任务执行进收到任务后检查是否有任务对应的程序包,没有就去下载,下载后加载程序
- 加载程序后,任务根据分配的数据片的文件地址和数据在文件内的偏移量读取数据,并把数据输入给应用程序相应的方法去执行,从而实现分布式服务器集群中并行处理的计算目标
总结:大数据是庞大的,程序要比数据小得多,将数据输入给程序是不划算的,那么就反其道行之,将程序发到数据所在的地方进行计算,也就是所谓的移动计算比移动数据更划算
三、大数据应用
相应技术
数据分析、数据挖掘、机器学习
应用领域
医疗、教育、社交媒体、金融、新零售、交通
四、大数据平台集成
1.自建大数据平台
- 数据采集
将应用程序产生的数据和日志等同步到大数据系统中,由于数据源不同,这里的数据同步系统实际上是多个相关系统的组合。数据库同步通常用Sqoop,日志同步可以选择Flume,打点采集的数据经过格式化转换后通过kafka等消息队列进行传递
不同的数据源产生的数据质量可能差别很大,数据库中的数据也许可以直接导入大数据系统就可以使用了,而日志和爬虫产生的数据就需要进行大量的清洗、转化处理才能有效使用 - 数据处理
这部分是大数据存储与计算的核心,数据同步系统导入的数据存储在HDFS
MapReduce、Hive、Spark等计算任务读取HDFS上的数据进行计算,再将计算结果写入HDFS
MapReduce、Hive、Spark等计算处理被称为离线计算,HDFS存储的数据被称为离线数据
另外一些数据规模比较大,但是要求处理的时间却比较短,称为大数据流式计算,通过用Storm、Spark Streaming等流式大数据引擎来完成 - 数据输出与展示
大数据产生的数据还是写入到HDFS中,但应用程序不可能到HDFS中读取数据,所以必需要将HDFS的数据导出到数据库中。数据同步导出相对比较容易,计算产生的数据都比较规范,稍作处理就可以用Sqoop之类的系统导出到数据库
这时,应用程序就可以直接访问数据库中的数据,实时展示给用户,比如展示给用户关联推荐的商品
除了给用户访问提供数据,大数据还需要给运营和决策层提供各种统计报告,这些数据也写入数据库,被相应 的后台系统访问。
2. 商业大数据平台
- CDH
包含数据集成、大数据存储、统一服务、过程分析与计算 - 云计算厂商
阿里云、华为云都有相应的产品,可以自己去搜索一下
五、金字塔方式总结